Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Une opération de clonage de bloc indique au système de fichiers de copier une plage d’octets de fichier pour le compte d’une application. Le fichier de destination peut être identique ou différent du fichier source.
Un système de fichiers gère les mappages de clusters et d’étendues, et peut être en mesure d’effectuer la copie en modifiant le numéro de cluster virtuel (VCN) en mappages de numéro de cluster logique (LCN) en tant qu’opération de métadonnées à faible coût, plutôt que de lire et d’écrire les données de fichier sous-jacentes. Cela permet à la copie de se terminer plus rapidement et de générer moins d’E/S dans le stockage sous-jacent. De plus, plusieurs fichiers peuvent désormais partager des clusters logiques après le clone de bloc, ce qui permet d’économiser de la capacité en ne stockant pas plusieurs fois des clusters identiques sur le disque.
Une opération de clonage de bloc n’interrompt pas l’isolation fournie entre les fichiers. Une fois qu’un clone de bloc est terminé, les écritures dans le fichier source n’apparaissent pas dans la destination, ou inversement.
Le clonage de bloc est disponible uniquement sur le type de système de fichiers ReFS à partir de Windows Server 2016. À compter de la mise à jour de Windows 11 Moment 5 (KB5034848) et des versions ultérieures des builds windows client et Windows Server, le clonage de bloc se produit en mode natif dans les opérations de copie Windows prises en charge.
Bloquer le clonage sur ReFS
À compter de Windows Server 2016, ReFS implémente le clonage de bloc en remappant des clusters logiques (c’est-à-dire des emplacements physiques sur un volume) de la région source à la région de destination. Il utilise ensuite un mécanisme d’allocation en écriture pour garantir l’isolation entre ces régions. Les régions source et de destination peuvent se trouver dans les fichiers identiques ou différents.
Cette implémentation nécessite que les décalages de fichier de début et de fin soient alignés sur les limites du cluster. Dans ReFS à partir de Windows Server 2016, les clusters sont de 4 Ko par défaut, mais peuvent éventuellement être définis sur 64 Ko. La taille du cluster est un paramètre à l’échelle du volume défini au moment du format.
Implications en termes de performances et de taille de cluster
La taille du cluster d’un volume ReFS affecte directement le comportement de clonage de bloc et les caractéristiques de performances :
- Taille du cluster par défaut : 4 Ko (recommandé pour la plupart des charges de travail)
- Taille de cluster alternative : 64 Ko (approprié pour les charges de travail d’E/S volumineuses et séquentielles)
La taille du cluster détermine la granularité à laquelle les opérations de clonage de bloc et de copie en écriture se produisent. Lorsqu’une écriture est effectuée dans une région de fichier qui partage des clusters avec un autre fichier (après un clone de bloc), ReFS utilise un mécanisme d’allocation en écriture qui fonctionne au niveau du cluster :
- Seul le cluster modifié est dupliqué et écrit dans un nouvel emplacement physique
- Les clusters non modifiés dans la même région restent partagés
- Ce comportement s’applique, que le clonage de bloc ait été lancé explicitement via FSCTL_DUPLICATE_EXTENTS_TO_FILE ou automatiquement par le système (Windows 11 Moment 5 et versions ultérieures)
Considérations relatives aux performances
Le choix de la taille du cluster a des implications importantes pour les performances et la consommation d’espace :
- Clusters de 4 Ko : améliorez l’efficacité de l’espace pour les charges de travail avec de petites écritures aléatoires (plage de Ko en Mo), car seules 4 Ko sont dupliquées par cluster modifié. Toutefois, cela peut entraîner des opérations de copie sur écriture plus fréquentes.
- Clusters 64 Ko : réduisez la surcharge des métadonnées et améliorez les performances d’E/S séquentielles, mais cela peut entraîner un doublon jusqu’à 64 Ko pour chaque écriture dans une région partagée, même si l’écriture est inférieure à 64 Ko.
La taille du cluster est déterminée au moment du format et ne peut pas être modifiée sans reformatage du volume. Pour vérifier la taille actuelle du cluster d’un volume ReFS, utilisez la commande suivante :
fsutil fsinfo refsinfo <volume>
Pour les volumes mis en forme automatiquement par Windows (par exemple, lorsque le clonage de bloc est activé par défaut), le système utilise la taille de cluster par défaut de 4 Ko, sauf configuration explicite lors de la création du volume.
Restrictions et remarques
- Les régions source et de destination doivent commencer et se terminer à une limite de cluster.
- La taille de la région clonée doit être inférieure à 4 Go.
- La région de destination ne doit pas s’étendre au-delà de la fin du fichier. Si l’application souhaite étendre la destination avec des données clonées, elle doit d’abord appeler SetEndOfFile.
- Si les régions source et de destination se trouvent dans le même fichier, elles ne doivent pas se chevaucher. (L’application peut pouvoir continuer en fractionnant l’opération de clonage de bloc en plusieurs clones de bloc qui ne se chevauchent plus.)
- Les fichiers source et de destination doivent se trouver sur le même volume ReFS.
- Les fichiers source et de destination doivent avoir le même paramètre De flux d’intégrité (autrement dit, les flux d’intégrité doivent être activés dans les deux fichiers ou désactivés dans les deux fichiers).
- Si le fichier source est partiellement alloué, le fichier de destination doit l’être également.
- L’opération de clonage de bloc interrompt les verrous opportunistes partagés (également appelés verrous opportunistes de niveau 2).
- Le volume ReFS doit avoir été formaté avec Windows Server 2016 ou une version ultérieure, et si le clustering de basculement Windows est en cours d’utilisation, le niveau fonctionnel de clustering doit avoir été Windows Server 2016 ou une version ultérieure au moment du formatage.
Exemple
Supposons que nous avons deux fichiers, X et Y, où chaque fichier est composé de 3 régions distinctes. Chaque région de fichier est stockée dans une région distincte du volume. Le système de fichiers stocke les connaissances que chacune de ces régions de volume est référencée dans une région de fichier :
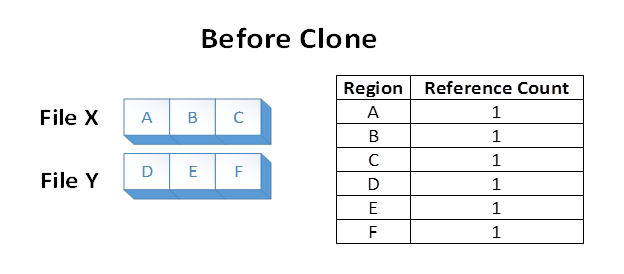
Supposons maintenant qu’une application émet une opération de clonage de bloc de File X, sur les régions de fichiers A et B, vers le fichier Y au décalage où E est actuellement. L’état du système de fichiers suivant se traduit par :
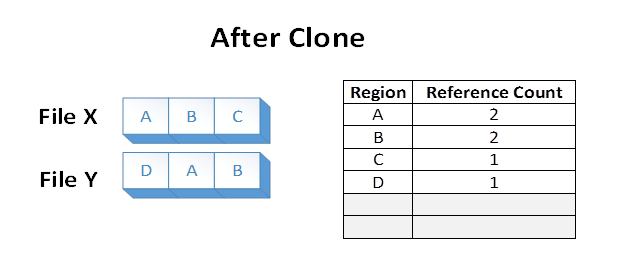
Les données des régions A et B ont été dupliquées efficacement du fichier X au fichier Y en modifiant les mappages VCN vers LCN au sein du volume ReFS. Les étendues de disque des régions de stockage A et B n’ont pas été lues, ni les étendues de disque qui sauvegardent les anciennes régions E et F remplacées pendant l’opération.
Les fichiers X et Y partagent désormais des clusters logiques sur le disque. Cela est reflété dans les nombres de références indiqués dans le tableau. Le partage entraîne une consommation inférieure de capacité de volume que si les régions A et B ont été dupliquées sur le volume sous-jacent.
À présent, supposons que l’application remplace la région A dans Le fichier X. ReFS effectue une copie en double d’A, que nous allons maintenant appeler G. ReFS puis mappe G dans le fichier X et applique la modification. Cela permet de préserver l’isolation entre les fichiers. Les nombres de références sont mis à jour de manière appropriée :
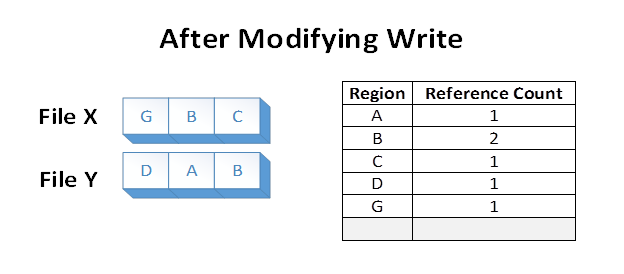
Après la modification de l’écriture, la région B est toujours partagée sur le disque. Notez que si la région A avait été plus grande qu’un cluster, seul le cluster modifié aurait été dupliqué, et la partie restante aurait continué à être partagée.
Comportement de copie en écriture
Le mécanisme d’allocation en écriture fonctionne au niveau du cluster, ce qui a des implications importantes pour les performances et la consommation d’espace :
- Écrit plus petite que la taille du cluster : une écriture de n’importe quelle taille dans un cluster partagé (même 1 octet) entraîne le doublon de l’ensemble du cluster. Avec la taille de cluster par défaut de 4 Ko, une écriture de 1 Ko dans une région partagée entraîne la copie de 4 Ko.
- Écritures couvrant plusieurs clusters : si une écriture s’étend sur plusieurs clusters, seuls les clusters modifiés sont dupliqués. Par exemple, une écriture de 8 Ko de données avec des clusters de 4 Ko duplique 2 clusters pour un total de 8 Ko, tandis que la même écriture 8 Ko avec des clusters de 64 Ko duplique 1 cluster pour un total de 64 Ko.
- Écritures séquentielles volumineuses : pour les charges de travail qui modifient fréquemment de grandes régions contiguës après le clonage, des tailles de cluster plus importantes (64 Ko) peuvent réduire la surcharge en réduisant le nombre d’opérations de copie en écriture.
Cette granularité au niveau du cluster s’applique à toutes les écritures après le clonage de bloc, y compris les scénarios où Windows 11 Moment 5 et ultérieur effectuent automatiquement le clonage de bloc pendant les opérations de copie.