Microsoft Azure Synapse Analytics は、データ ウェアハウスとビッグ データ システム間で分析情報を得る時間を短縮するエンタープライズ分析サービスです。 エンタープライズ データ ウェアハウスで使用される最高の SQL テクノロジ、ビッグ データ用の Apache Spark テクノロジ、ログと時系列分析用の Azure Data Explorerが組み合わさっています。 詳細については、Azure Synapse Analytics のドキュメントを参照してください。
次の例は、専用 Synapse Data Warehouse (DWH) テーブル EMPLOYEE のインスタンスと、SynapseSalesDelta テーブルを含むサーバーレス データベース (SQL_ON_DEMAND) を含む Synapse ワークスペースを示しています。
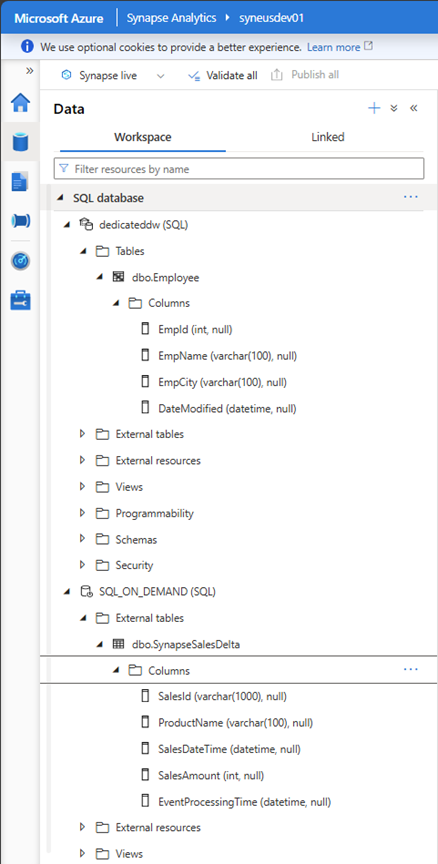
資産をスキャンすると、Microsoft Purview で使用できるようになります。 次の例は、Synapse Analytics Dedicated インスタンスの Employee Table を示しています。
Azure Synapse Analytics Dedicated (Data Warehouse)
データ マップ スキャンを設定する
Azure Synapse Analytics Dedicated (Data Warehouse) をスキャンするには、次の手順に従います。 専用 DWH インスタンスに必要なマネージド ID アクセス許可を付与するには、 次の手順に従います。

アセットをスキャンすると、Microsoft Purview 統合カタログで使用できるようになります。 次の例は、Synapse Analytics Dedicated インスタンスの Employee Table を示しています。

Synapse 専用データ ウェアハウスへの接続を設定する
この時点で、スキャンされた資産をカタログ化およびガバナンスの準備が整いました。 スキャンされた資産をガバナンス ドメインのデータ製品に関連付けます。 [データ品質] タブで、新しいAzure SQLデータベース接続を追加します。手動で入力したデータベース名を取得します。
統合カタログで、正常性管理>[データ品質] に移動し、ガバナンス ドメインを選択します。
ガバナンス ドメインの詳細ページで、[管理] を選択し、[Connections] を選択します。
[Connections] ページで、[新規] を選択し、次の情報を使用して接続を構成します (次の例を参照)。
- 接続名と説明を追加します。
- [ソースの種類] Azure Synapse [Analytics] を選択します。
- [ Azure サブスクリプション] を選択します。
- [ ワークスペース名] を選択します。
- [ 専用 SQL エンドポイント] を選択します。
- サーバーレス SQL エンドポイントを選択します。
- [ エンドポイントの種類] を選択します。
- [ データベース] を選択します。
- 資格情報として MSI を追加します。

接続をテストします。 データ ソース接続を構成し、正常にテストしたら、データ プロファイルとデータ品質スキャンの構成と実行に進むことができます。
Synapse データ ソースがプライベート エンドポイントの背後にある場合は、マネージド仮想ネットワークを有効にする必要があります。 「 マネージド仮想ネットワークを設定する」の手順に従います。

重要
データ品質スチュワードは、データ品質接続を設定するために synapse 専用データ ウェアハウスへの読み取り専用アクセス権が必要です。 マネージド仮想ネットワークのセットアップでは、接続をテストできません。
Synapse 専用データ ウェアハウス内のデータのプロファイリングとデータ品質スキャン
接続を設定したら、データのプロファイリング、ルールの作成と適用、Synapse ウェアハウスでのデータのデータ品質スキャンの実行を行うことができます。 次の記事で説明されている手順のガイドラインに従ってください。
重要
- クエリのパフォーマンスと実行の成功は、専用データベース インスタンスの DW 構成によって異なります。
- それぞれのデータ品質評価ジョブまたはその他のデータ品質ジョブは、専用 DW 上の接続を誘導し、インスタンスがプロビジョニングされていないか、コンカレンシー制限で失敗した場合に失敗する可能性があります。 DW 構成に注意する必要があります。 そのコンカレンシーには、任意のインスタンスのハード制限があります。
- コンカレンシーの制限により、ジョブが終了する可能性があります。 DW 制限 (1000 DW など) は、クエリを実行する機能を提供します。
Azure Synapse Analytics Serverless
データ マップ スキャンを設定する
Analytics サーバーレスAzure Synapseスキャンするには、次の手順に従います。 専用 DWH インスタンスに必要なマネージド ID アクセス許可を付与するには、 次の手順に従います。 スキャンされると、サーバーレス資産は統合カタログで使用できます。

synapse Serverless への接続を設定する
この時点で、スキャンされた資産をカタログ化およびガバナンスの準備が整いました。 スキャンされた資産をガバナンス ドメインのデータ製品に関連付けます。 [データ品質] で、新しいSQL Database接続を追加します。手動で入力したデータベース名を取得します。
統合カタログで、正常性管理>[データ品質] に移動し、ガバナンス ドメインを選択します。
ガバナンス ドメインの詳細ページで、[管理] を選択し、[Connections] を選択します。
[Connections] ページで、[新規] を選択し、次の情報を使用して接続を構成します (次の例を参照)。
- 接続名と説明を追加します。
- [ソースの種類] Azure Synapse [Analytics] を選択します。
- [ Azure サブスクリプション] を選択します。
- [ ワークスペース名] を選択します。
- [ 専用 SQL エンドポイント] を選択します。
- サーバーレス SQL エンドポイントを選択します。
- [ エンドポイントの種類] を選択します。
- [ データベース] を選択します。
- 資格情報として MSI を追加します。
接続をテストします。 データ ソース接続を構成し、正常にテストしたら、データ プロファイルとデータ品質スキャンの構成と実行に進むことができます。
Synapse データ ソースがプライベート エンドポイントの背後にある場合は、マネージド仮想ネットワークを有効にする必要があります。 「 マネージド仮想ネットワークを設定する」の手順に従います。
重要
- データ品質スチュワードは、データ品質接続を設定するために synapse 専用データ ウェアハウスへの読み取り専用アクセス権が必要です。
- Synapse サーバーレスセットアップでは、外部テーブルは ADLS Gen2 に格納されている Delta 形式のデータを指します。
- Synapse Connector は、 sql.azuresynapse.net のみを検出してサポートします。 Data Map スキャンによって生成された完全修飾名 (FQN) に database.windows.net が含まれている場合、データ品質スキャンの Synapse 接続は失敗します。
Synapse サーバーレスでのデータのプロファイリングとデータ品質スキャン
接続を設定したら、データのプロファイリング、ルールの作成と適用、Synapse ウェアハウスでのデータのデータ品質スキャンの実行を行うことができます。 これらの記事で説明されているステップバイステップのガイドラインに従ってください。
重要
- データ品質評価とプロファイリングは、バックグラウンドで Spark で実行されます。 各 Spark ノードに接続 SPID がある複数の接続があります。 そのため、Data Warehouse制限を超えて使用またはスケジュールすると、Data Warehouseが現在のクエリ制限に達し、エラーが発生する可能性があります。 ただし、サーバーレス SQL テーブルAzure Synapseの場合、このようなコンカレンシー制限は適用されません。 これは、ADLS Gen2 インスタンスに対するサーバーレス Delta Parquet の最適化によって異なります。 エンジンは Databricks Serverless Data Warehouseと密接に連携します。 どちらも DELTA 形式テーブルなどの外部の Lakehouse ソースで動作します。