データ品質は、organization内のデータの整合性を測定します。 データ品質スコアを使用して、データ品質を評価します。 Microsoft Purview 統合カタログは、定義したルールに対するデータの評価に基づいてスコアを生成します。
データ品質ルールは、組織がデータの正確性、一貫性、完全性を確保するために確立する重要なガイドラインです。 これらのルールは、データの整合性と信頼性を維持するのに役立ちます。
データ品質ルールの主な側面を次に示します。
精度: データは実際のエンティティを正確に表す必要があります。 コンテキストが重要です。 たとえば、顧客アドレスを格納する場合は、実際の場所と一致していることを確認します。
完全性: このルールは、空、null、または不足しているデータを識別します。 必ずしも正しいとは限りませんが、すべての値が存在することを検証します。
適合性: この規則により、データが日付、住所、許可値の表現などのデータ書式設定標準に従うことが保証されます。
整合性: このルールは、同じレコードの異なる値が特定のルールに準拠していること、および矛盾がないことを確認します。 データの整合性により、同じ情報が異なるレコード間で一様に表現されます。 たとえば、製品カタログがある場合は、一貫性のある製品名と説明が重要です。
タイムライン: このルールは、データにできるだけ短時間でアクセスできるようにすることを目的としています。 これにより、データが最新の状態になります。
一意性: このルールは、値が重複していないことを確認します。 たとえば、顧客ごとに 1 つのレコードしか存在しないはずの場合、同じ顧客に対して複数のレコードはありません。 各顧客、製品、またはトランザクションには、一意の識別子が必要です。
データ品質のライフ サイクル
データ品質ルールの作成は、データ品質ライフサイクルの 6 番目 の手順です。 前の手順は次のとおりです。
- すべてのデータ品質機能を使用するために、統合カタログでユーザーにデータ品質スチュワードのアクセス許可を割り当てます。
- Microsoft Purview データ マップでデータ ソースを登録してスキャンします。
- データ製品にデータ資産を追加します。
- データ品質評価のためにソースを準備するために、データ ソース接続を設定します。
- データ ソース内の資産のデータ プロファイルを構成して実行します。
必要な役割
- データ品質ルールを作成および管理するには、ユーザーには データ品質スチュワード ロールが必要です。
- 既存の品質ルールを表示するには、データ 品質閲覧者ロールが必要です。
既存のデータ品質ルールを表示する
統合カタログで、[正常性管理] を選択し、[データ品質] を選択します。
ガバナンス ドメインを選択し、データ製品を選択します。
[データ資産] の一覧から データ資産を 選択します。
[ ルール ] タブを選択すると、資産に適用されている既存のルールが表示されます。
ルールを選択して、選択したデータ資産に適用されたルールのパフォーマンス履歴を参照します。


使用可能なデータ品質ルール
Microsoft Purview データ品質では、次の規則の構成が有効になります。 これらのルールはすぐに使用でき、低コードからコードなしの方法でデータの品質を測定できます。
| Rule | 定義 |
|---|---|
| Freshness | すべての値が最新であることを確認します。 |
| 一意の値 | 列の値が一意であることを確認します。 |
| 文字列形式の一致 | 列の値が特定の形式またはその他の条件と一致することを確認します。 |
| データ型の一致 | 列の値がデータ型の要件と一致することを確認します。 |
| 重複する行 | 2 つ以上の列で同じ値を持つ重複する行をチェックします。 |
| 空/空白フィールド | 値が必要な列で空白フィールドと空のフィールドを検索します。 |
| テーブル参照 | あるテーブルの値が別のテーブルの特定の列に存在することを確認します。 |
| Custom | ビジュアル式ビルダーを使用してカスタム ルールを作成します。 |
Freshness
鮮度ルールは、資産が予想時間内に更新されたかどうかを確認します。 鮮度は、 最終変更日の選択によって決まります。

注:
鮮度ルール スコアは、100 (合格) または 0 (失敗) です。 更新ルールは、Snowflake、Databricks Unity Catalog、Google BigQuery、Synapse、Microsoft Azure SQL Azureではサポートされていません。
一意の値
[Unique values]\(一意の値\) ルールは、指定した列のすべての値が一意である必要があることを示します。 一意の値はすべてパスとして扱われ、一意でない値は失敗として扱われます。 列に 空/空白フィールド ルールが定義されていない場合、このルールの目的で null または空の値は無視されます。

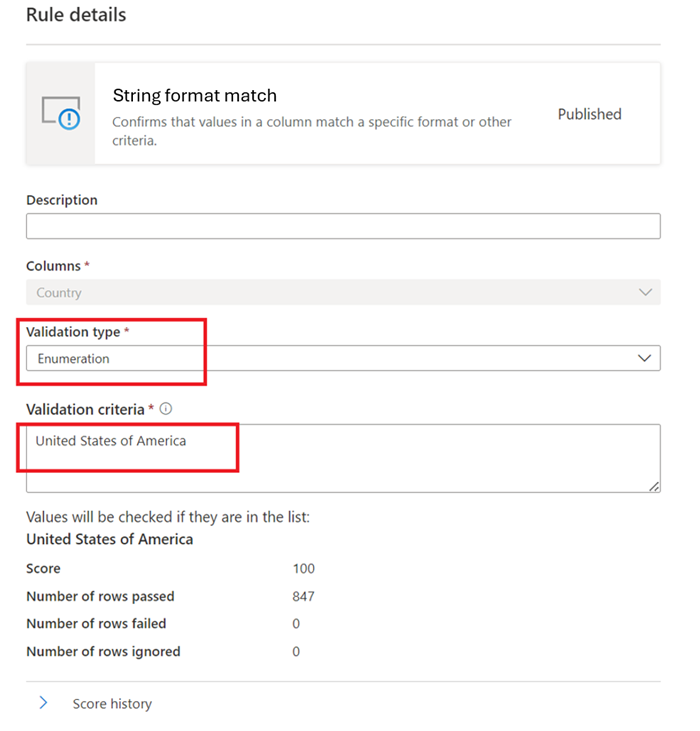
文字列形式の一致
[書式] 一致ルールでは、列内のすべての値が有効かどうかを確認します。 列に 空または空白フィールド ルールを定義しない場合、ルールは null または空の値を無視します。
この規則では、次の 3 つの異なる方法を使用して、列の各値を検証できます。
-
列挙: この方法では、値のコンマ区切りリストを使用します。 評価する値が一覧に示されている値の 1 つと一致しない場合は、チェックに失敗します。 円記号 (
\) を使用して、コンマと円記号をエスケープできます。 そのため、a \, b, cには 2 つの値が含まれています。1 つ目はa , b、2 つ目はcです。
Pattern:
like(<i><string></i> : string, <i><pattern match></i> : string) => booleanパターンは、ルールがリテラルに一致する文字列です。 例外は、次の特殊な記号です。 _ は、入力内の任意の 1 文字に一致します (posix正規表現の.に似ています) % は、入力の 0 個以上の文字と一致します (posix正規表現の.に似ています)。 エスケープ文字が.エスケープ文字が特別な記号または別のエスケープ文字の前にある場合、次の文字は文字どおり一致します。 他の文字をエスケープすることは無効です。like('icecream', 'ice%') -> true

正規表現:
regexMatch(<i><string></i> : string, <i><regex to match></i> : string) => boolean文字列が指定された正規表現パターンと一致するかどうかを確認します。 エスケープせずに文字列を照合するには、
<regex>(バッククォート) を使用します。regexMatch('200.50', '(\\d+).(\\d+)') -> trueregexMatch('200.50', `(\d+).(\d+)`) -> true

データ型の一致
データ型の一致規則は、関連付けられている列に対して予期されるデータ型を指定します。 ルール エンジンはさまざまなデータ ソースで実行されるため、BIGINT や VARCHAR などのネイティブ型を使用することはできません。 代わりに、独自の型システムを使用し、ネイティブ型をこのシステムに変換します。 このルールは、ネイティブ型に使用する組み込み型の品質スキャン エンジンを示します。 データ型システムは、Azure Data Factoryで使用される Microsoft Azure Data Flow 型システムから取得されます。
品質スキャン中に、エンジンはすべてのネイティブ型をデータ型の一致型に対してテストします。 ネイティブ型をデータ型の一致型に変換できない場合、その行はエラーとして扱われます。

重複する行
[行の重複] ルールは、列内の値の組み合わせがテーブル内のすべての行に対して一意であるかどうかをチェックします。
次の例では、CompanyName、CustomerID、EmailAddress、FirstName、LastName を連結すると、テーブル内のすべての行に対して一意の値が生成されます。
各資産には、この規則のインスタンスを 0 個または 1 個使用できます。

空/空白フィールド
空/空白フィールド ルールは、識別された列に null 値を含めてはならないことをアサートします。 文字列の場合、ルールは空または空白のみの値も禁止します。 データ品質スキャン中に、エンジンはこの列の null ではない値を正しい値として扱います。 このルールは、 一意の値 や 書式の一致 ルールなどの他のルールに影響します。 列に対してこのルールを定義しない場合、それらのルールは、その列で実行されるときに null 値を自動的に無視します。 列に対してこの規則を定義する場合、それらのルールは、その列の null 値または空の値を調べ、スコアのためにそれらを考慮します。

テーブル参照
テーブル参照ルールは、ルールを定義する列の各値を調べ、参照テーブルと比較します。 たとえば、プライマリ テーブルには "location" という名前の列があり、都市、州、郵便番号が "city, state zip" という形式で含まれています。 "citystate" と呼ばれる参照テーブルには、米国でサポートされている都市、州、郵便番号のすべての法的な組み合わせが含まれています。 目標は、現在の列のすべての場所をその参照リストと比較して、法的な組み合わせのみが使用されていることを確認することです。
このルールを設定するには、検索資産ダイアログに "citystatezip" 名を入力します。 次に、目的の資産と比較する列を選択します。

注:
参照テーブルまたはデータ資産は、同じガバナンス ドメインに属している必要があります。 異なるガバナンス ドメイン間でデータ資産を比較することはできません。
カスタム ルール
カスタム ルールを使用すると、その行の 1 つ以上の値に基づいて行を検証するルールを指定できます。 正規表現言語、Azure Data Factory式、および SQL 式言語を使用して、カスタム規則を作成できます。
カスタム ルールには、次の 3 つの部分があります。
行式: このブール式は、フィルター式が承認する各行に適用されます。 この式が true を返す場合、行は渡されます。 false が返された場合、行は失敗します。
フィルター式: このオプションの条件は、行条件が評価されるデータセットを絞り込みます。 アクティブ化するには、[ フィルター式を使用 する] チェック ボックスをオンにします。 この式はブール値を返します。 フィルター式は行に適用され、true が返された場合、その行はルールと見なされます。 フィルター式がその行に対して false を返す場合は、この規則の目的で行が無視されることを意味します。 フィルター式の既定の動作は、すべての行を渡すことであるため、フィルター式を指定しない場合は、すべての行が考慮されます。
Null 式: NULL 値の処理方法を確認します。 この式は、データが欠落しているケースを処理するブール型 (Boolean) の値を返します。 式が true を返す場合、行式は適用されません。
ルールの各部分は、既存のMicrosoft Purview データ品質条件と同様に機能します。 ルールは、フィルター式に一致し、null 式で指定された欠損値を処理するデータセットに対して行式が TRUE と評価された場合にのみ渡されます。
例: "fareAmount" が正であり、"tripDistance" が有効であることを確認する規則:
- 行式: tripDistance > 0 AND fareAmount > 0
- フィルター式: paymentType = 'CRD'
- Null 式: tripDistance IS NULL
カスタム ルールを作成する
- 統合カタログで、[正常性管理>データ品質] に移動します。
- ガバナンス ドメインを選択し、データ製品を選択してから、データ資産を選択します。
- [ ルール ] タブで、[ 新しいルール] を選択します。
Azure Data Factory (ADF) 式を使用してカスタム規則を作成する
正規表現または ADF 式を使用してルールを作成するには、オプションの規則の一覧から [カスタム ] を選択し、[ 次へ] を選択します。
[ルール名] と [説明] を追加し、[作成] を選択します。

カスタム ルールの例
| シナリオ | 式 |
|---|---|
| state_idがカリフォルニアと等しく、aba_Routing_Numberが特定の正規表現パターンと一致し、生年月日が特定の範囲に収まるかどうかを検証します | state_id=='California' && regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| VendorID が 124 に等しいかどうかを確認する | {VendorID}=='124' |
| fare_amountが 100 以上かどうかを確認する | {fare_amount} >= "100" |
| fare_amountが 100 より大きく、tolls_amountが 100 に等しくないかどうかを検証します | {fare_amount} >= "100"||{tolls_amount} != "400" |
| レーティングが 5 未満かどうかを確認する | Rating < 5 |
| 年の桁数が 4 であるかどうかを確認する | length(toString(year)) == 4 |
| 2 つの列 bbToLoanRatio と bankBalance を比較し、値が等しい場合はチェックします | compare(variance(toLong(bbToLoanRatio)),variance(toLong(bankBalance)))<0 |
| firstName、lastName、LoanID、uuid のトリミングおよび連結された文字数が 20 を超えるかどうかを確認する | length(trim(concat(firstName,lastName,LoanID,uuid())))>20 |
| aba_Routing_Numberが特定 の 正規表現パターンと一致し、最初のトランザクション日付が 2022-11-12 より大きく、 Disallow-Listed が false で、平均 bankBalance が 50000 を超え、 state_id が 'マサチューセッツ'、'テネシー'、'North Dakota'、または 'アラバマ' と等しいことを確認します | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && toDate(addDays(toTimestamp(initialTransaction, 'yyyy-MM-dd\'T\'HH:mm:ss'),15))>toDate('2022-11-12') && ({Disallow-Listed}=='false') && avg(toLong(bankBalance))>50000 && (state_id=='Massachusetts' || state_id=='Tennessee ' || state_id=='North Dakota' || state_id=='Alabama') |
| aba_Routing_Numberが特定 の 正規表現パターンと一致し、 dateOfBirth が 1968-12-13 から 2020-12-13 の間にあるかどうかを検証します | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| aba_Routing_Numberの一意の値の数が 1,000,000 に等しく、EMAIL_ADDRの一意の値の数が 1,000,000 に等しいかどうかを確認します | approxDistinctCount({aba_Routing_Number})==1000000 && approxDistinctCount({EMAIL_ADDR})==1000000 |
フィルター式と行式はどちらも、Azure Data Factory式言語を使用して定義され、言語はここで定義されます。 ただし、ジェネリック ADF 式言語に対して定義されているすべての関数が使用できるわけではありません。 使用可能な関数の完全な一覧は、式ダイアログで使用できる関数の一覧にあります。 ここで定義されている次の関数はサポートされていません。isDelete、isError、isIgnore、isInsert、isMatch、isUpdate、isUpsert、partitionId、cached lookup、Window 関数。
注:
<regex> (バッククォート) は、特殊文字をエスケープせずに文字列を一致させるために、カスタム ルールに含まれる正規表現で使用できます。 正規表現言語は Java に基づいています。
正規表現と Java について学習し、エスケープする必要がある文字を理解します。
SQL 式を使用してカスタム 規則を作成する
Microsoft Purview データ品質のカスタム SQL ルールを使用すると、Spark SQL 述語を使用してデータ品質チェックを柔軟に定義できます。 この機能を使用すると、高度な検証シナリオのために Spark SQL でルールを直接作成できます。 行式のみが必要です。さらにカスタマイズするには、filter 式と null 式は省略可能です。 Spark SQL の完全な機能を活用して、複雑なビジネス要件に対処し、データ品質を向上させるためにカスタム SQL ルールを使用します。 カスタム SQL ルールを使用すると、ADF 式だけでは不可能な複雑なデータ検証が可能になります。 Spark SQL 述語を記述することで、独自のビジネス ニーズを満たし、高いデータ品質基準を維持できます。
SQL 式言語を使用してルールを作成するには、オプションの規則の一覧から [カスタム (SQL)] を選択し、[ 次へ] を選択します。
[ルール名] と [説明] を追加し、[作成] を選択します。
シナリオ 式 正しい文字列パターン (たとえば、'1' および数値で始まる rateCodeId) と、有効な支払いタイプによるフィルターを検証します。 Row: rateCodeId RLIKE '^1[0-9]+$'Filter: paymentType IN ('CRD', 'CSH')Null: rateCodeId IS NULLpuLocationId と doLocationId の間の正しい列の比較と、乗車距離と比較した料金を確認します。 Row: puLocationId > doLocationId AND fareAmount > tripDistance * 10'Filter: paymentType <> 'CSH''Null: tripDistance IS NULLpaymentType が特定のリスト (カード、現金) に含まれているかどうかを確認し、料金に基づいて行をフィルター処理します。 Row: paymentType IN ('CRD', 'CSH')'Filter: fareAmount >= 50Null: paymentType IS NULLNULL を処理し、有効な支払いタイプのフィルター処理を行いながら、距離が包括範囲内 (5 ~ 10 マイル) 内にあることを確認します。 Row: tripDistance BETWEEN 5 AND 10Filter: paymentType <> 'CRD'Null: tripDistance IS NULLデータセットが fareAmount の 20% NULL 値を超えないようにします。 Row: (SELECT avg(CASE WHEN fareAmount IS NULL THEN 1 ELSE 0 END) FROM nycyellowtaxidelta1BillionPartitioned) < 0.20'Filter: vendorID IN ('VTS', 'CMT')データセットに少なくとも 2 つの個別の paymentType 値があることを確認します。 Row: (SELECT count(DISTINCT paymentType) FROM nycyellowtaxidelta1BillionPartitioned) >= 2Filter: vendorID IN ('1', '2')データセットの平均料金額が指定された範囲内 (80 <= avg <= 140) 内にあることを確認します。 Row: (SELECT avg(fareAmount) FROM nycyellowtaxidelta1BillionPartitioned) BETWEEN 80 AND 140 'Filter: paymentType IN ('CRD', 'CSH')データセット内の最大 tripDistance が <= 10 マイルであることを確認します。 Row: (SELECT max(tripDistance) FROM nycyellowtaxidelta1BillionPartitioned) <= 10.0Filter: vendorID IN ('VTS', 'CMT')fareAmount の標準偏差が特定のしきい値 (< 30) を下回っていることを確認します。 Row: (SELECT stddev_samp(fareAmount) FROM nycyellowtaxidelta1BillionPartitioned) < 30.0Filter: vendorID IN ('VTS', 'CMT')データセットの中央値の料金が指定されたしきい値 (<= 15) 内にあることを確認します。 Row: (SELECT percentile_approx(fareAmount, 0.5) FROM nycyellowtaxidelta1BillionPartitioned) <= 15.0Filter: vendorID IN ('VTS', 'CMT')特定の paymentType 内のデータセットで vendorId が一意であることを確認します。 Row: COUNT(1) OVER (PARTITION BY vendorID) = 1Filter: paymentType IN ('CRD', 'CSH','1', '2')Null: vendorID IS NULLpuLocationId と doLocationId の組み合わせがデータセット内で一意であることを確認します。 Row: COUNT(1) OVER (PARTITION BY puLocationId, doLocationId) = 1Filter: paymentType IN ('CRD', 'CSH')Null: puLocationId IS NULL OR doLocationId IS NULLvendorId が paymentType ごとに一意であることを確認します。 Row: COUNT(1) OVER (PARTITION BY paymentType, vendorID) = 1 ,Filter: rateCodeId < 25, Null: vendorID IS NULL行の tpepPickupDateTime が特定のカットオフ タイムスタンプより大きいことが確認されます。 Row: tpepPickupDateTime >= TIMESTAMP '2014-01-03 00:00:00'Filter: paymentType IN ('CRD', 'CSG', '1', '2')Null: tpepPickupDateTime IS NULL各旅行は1時間以内に完了する必要があります Row: (unix_timestamp(tpepDropoffDateTime) - unix_timestamp(tpepPickupDateTime)) <= 3600Filter: paymentType IN ('CRD', 'CSH', '1', '2')Null: tpepPickupDateTime IS NULL OR tpepDropoffDateTime IS NULL乗車場所ごとに最も高い料金の乗車のみを保持します。 Row: row_number() OVER (PARTITION BY puLocationId ORDER BY fareAmount DESC) = 1, Filter: paymentType IN ('CRD', 'CSH','1','2') AND tripDistance > 0, Null: fareAmount IS NULL OR puLocationId IS NULLピックアップ場所パスごとに結ばれたすべての最高運賃(row_numberによる最初の運賃ではありません)。 Row: rank() OVER (PARTITION BY puLocationId ORDER BY fareAmount DESC) = 1Filter: paymentType IN ('CRD', 'CSH','1','2') AND tripDistance > 0Null: fareAmount IS NULL OR puLocationId IS NULL料金は、支払いタイプごとに時間の経過に伴って減らしてはなりません。 Row: fareAmount >= lag(fareAmount) OVER (PARTITION BY paymentType ORDER BY tpepPickupDateTime)Null: tpepPickupDateTime IS NULL OR fareAmount IS NULL支払いの種類別のグループ平均の 10 以内の各行の運賃。 Row: abs(fareAmount - avg(fareAmount) OVER (PARTITION BY paymentType)) <= 10Filter: paymentType IN ('CRD', 'CSH','1','2')Null: fareAmount IS NULL走行距離の合計が20マイルを超えてはなりません。 Row: sum(tripDistance) OVER (ORDER BY tpepPickupDateTime ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) <= 20Filter: paymentType = '1'Null: tripDistance IS NULL各旅行の運賃が、対象となるベンダーのグローバル平均を上回っているかどうかを確認します。 Row: fareAmount > (SELECT avg(fareAmount) FROM nycyellowtaxidelta1BillionPartitioned)Filter: vendorID IN ('VTS', 'CMT')Null: fareAmount IS NULL各行の tripDistance が paymentType の最小値 (カード/現金) を超えるかどうかを確認します。 Row: tripDistance > (SELECT min(u.tripDistance) FROM (SELECT tripDistance, paymentType AS pt FROM nycyellowtaxidelta1BillionPartitioned) u WHERE u.pt = paymentType)Filter: paymentType IN ('CRD', 'CSH')Null: tripDistance IS NULL各旅行について、料金が支払いタイプの平均を上回るかどうかを確認します Row: fareAmount > (SELECT avg(u.fareAmount) FROM (SELECT fareAmount, paymentType AS pt FROM nycyellowtaxidelta1BillionPartitioned) u WHERE u.pt = paymentType)Filter: paymentType IN ('CRD','CSH','1','2') AND vendorID IN ('VTS','CMT')Null: fareAmount IS NULLfareAmount 列 (数値) が数値パターン (省略可能な 10 進数の正の数値) と一致する文字列として正しく表すことができるかどうかを検証します。 これは、fareAmount が数値列であるため、キャストを使用します。 Row: CAST(fareAmount AS STRING) RLIKE '^[0-9]+(\.[0-9]+)?$'Filter: paymentType IN ('CRD', 'CSH')Null: fareAmount IS NULLtpepPickupDateTime が yyyy-MM-dd HH:mm:ss 形式の有効なタイムスタンプであることを確認します。 この列は既に DATETIME 形式です Row: to_timestamp(tpepPickupDateTime, 'yyyy-MM-dd HH:mm:ss') IS NOT NULLFilter: paymentType IN ('CRD','CSH')Null: tpepPickupDateTime IS NULLpaymentType 値が小文字に正規化され、先頭または末尾のスペースがないことを確認します。 Row: lower(trim(paymentType)) IN ('card','cash') AND length(trim(paymentType)) > 0Null: paymentType IS NULL OR trim(paymentType) = ''tripDistance に対する fareAmount の比率を安全に計算し、最初に tripDistance > が 0 であるかどうかを確認することで 0 による除算が発生しないようにします。 Row: CASE WHEN tripDistance > 0 THEN fareAmount / tripDistance ELSE NULL END >= 10Filter: tripDistance > 0 AND vendorID IN ('VTS', 'CMT')結合によって null 値を既定値 (0.0 など) に置き換え、有効な行のみが返されるようにする方法を示します。 Row: coalesce(fareAmount, 0.0) >= 5Filter: paymentType IN ('CRD','CSH')
カスタム SQL ルールを記述するためのベスト プラクティス
- 式は単純にしてください。 維持しやすい明確で簡単な式を記述することを目指します。
- 組み込みの Spark SQL 関数を使用します。 文字列操作、日付処理、数値演算に Spark SQL の豊富な関数ライブラリを使用して、エラーを最小限に抑え、パフォーマンスを向上させます。
- 最初に小さなデータセットを使用してテストします。 小規模なデータセットのルールを大規模に適用する前に検証し、潜在的な問題を早期に特定します。
SQL 式ルールに関する既知の制限事項と考慮事項
あいまいな列参照と列のシャドウ
問題: 同じ名前の外部クエリとサブクエリ (またはクエリの異なる部分) の両方に列が表示されると、Spark SQL で使用する列を解決できない可能性があります。 この問題により、論理エラーが発生したり、クエリが正しく実行されたりします。 この問題は、入れ子になったクエリ、サブクエリ、または結合で発生し、あいまいさや影付けにつながる可能性があります。
あいまいさ: 外部クエリとサブクエリの両方に列名が明確な修飾なしで存在し、Spark SQL が参照する列が不明な場合に発生します。
シャドウ: 外部クエリの列がサブクエリ内の同じ列によって "オーバーライド" または "シャドウ" され、外部参照が無視される場合を指します。
式の例:
distance_km > ( SELECT min(distance_km) FROM Tripdata t WHERE t.payment_type = payment_type -- ambiguous outer reference )問題: 修飾されていないpayment_typeは、その名前の列を持つ最も近いスコープ (つまり、外側の行のpayment_typeではなく、内部t.payment_type) に解決されます。 そうすると、述語は t.payment_type = t.payment_type (常に TRUE) になります。そのため、サブクエリはグループ分ではなくグローバル最小になります。
解決策: このあいまいさを解決し、列のシャドウを回避するには、サブクエリ内の内部列の名前を変更して、外部クエリのpayment_typeが明確なままになるようにします。
修正された式:
distance_km >
(
SELECT min(u.distance_km)
FROM (
SELECT distance_km, payment_type AS pt
FROM Tripdata
) u
WHERE u.pt = payment_type -- this `payment_type` now binds to OUTER row
)
- サブクエリでは、列payment_typeは pt (つまり AS pt payment_type) としてエイリアス化され、条件で you.pt が使用されます。
- 外部クエリでは、元のpayment_typeを明確に参照できるようになり、Spark SQL によって外部payment_typeとして正しく解決されます。
ウィンドウ操作 (パフォーマンスの考慮事項)
- ROW_NUMBER() や RANK() などのウィンドウ操作は、特に大規模なデータセットではコストがかかる場合があります。 大規模に適用する前に、それらを慎重に使用し、小規模なデータセットでパフォーマンスをテストします。 PARTITION BY を使用してデータ スコープを減らすことを検討してください。
Spark SQL での列名のエスケープ
- 列名に特殊文字 (スペース、ハイフン、その他の英数字以外の文字など) が含まれている場合は、バックティックを使用してエスケープする必要があります。
- 列名が order-id で、ルールが 10 より大きい必要がある場合の例。
- 式が正しくありません: order-id > 10
- 正しい式:
`order-id`> 10
式で参照するデータ資産名
SQL 式でデータ資産を参照する場合は、特定のサニタイズ規則に従う必要があります。 元のデータ資産名を更新する必要はありませんが、SQL 式で参照されるデータ資産名は、次の条件を満たすためにサニタイズする必要があります。
| Rule | 説明 | 例 - 元の名前 | 例 - サニタイズされた名前 |
|---|---|---|---|
| 許容される文字 | 文字 (A-Z、a-z)、数値 (0 から 9)、アンダースコア (_) のみが許可されます。 特殊文字 (スペース、ハイフン、ピリオドなど) は削除する必要があります。 | my-dataset_v1+2023 | mydataset_v12023 |
| アンダースコアのトリミング | 名前の先頭または末尾のアンダースコアは削除する必要があります。 | my_dataset_ | my_dataset |
| 文字数制限 | 最後にサニタイズされた名前は、64 文字を超えてはなりません。 | [64 文字を超える長い名前] | [サニタイズされた名前の最初の 64 文字] |
データ資産名が既にこれらのガイドラインに従っている場合 (つまり、特殊文字、先頭/末尾のアンダースコアが含まれていないため、64 文字の制限内にある場合)、SQL 式では変更を加えずにそのまま使用できます。
データセット名をサニタイズする方法
データセット名が SQL 式に対して有効であることを確認するには、次の手順に従います。
- 特殊文字を削除する: 文字、数字、アンダースコアを除くすべての文字を取り除きます。
- アンダースコアをトリミングする: 先頭または末尾のアンダースコアを削除します。
- 切り捨て: 結果の名前が 64 文字を超える場合は、64 文字の制限内に収まるように切り捨てます。
例: データ資産名 f07d724d-82c9-4c75-97c4-c5baf2cd12a4.parquet
- 特殊文字を削除する: f07d724d82c94c7597c4c5baf2cd12a4parquet
- 下線のトリミング: (先頭または末尾のアンダースコアがないため、この場合は N/A)。
- 切り捨て: 結果の名前の長さは 54 文字で、64 文字の制限の下にあります。
最後の SQL 参照名: f07d724d82c94c7597c4c5baf2cd12a4parquet
注:
元のデータ資産名は変更されません。 これらの規則に従う必要があるのは、SQL 式で使用されるデータ資産名だけです。 スペースやハイフンなどの特殊文字を含む列名の場合は、SQL 式でバッククォートを使用してエスケープできます。
結合はサポートされていません
Microsoft Purview データ品質のカスタム SQL ルールでは、結合はサポートされていません。 ルールは 1 つのデータセットで動作する必要があります。 これらのカスタム ルールを記述するときに、複数のテーブルまたはデータセットを結合することはできません。
サポートされていない SQL 操作 (DML、DCL、有害な SQL)
カスタム SQL ルールでは、INSERT、UPDATE、DELETE、GRANT などのデータ操作言語 (DML) またはデータ制御言語 (DCL) 操作、および TRUNCATE、DROP、ALTER などの他の有害な SQL 操作はサポートされていません。 これらの操作は、データまたはデータベースの状態を変更するためサポートされていません。
AI 支援の自動生成ルール
データ品質測定のための AI 支援の自動ルール生成では、人工知能 (AI) 手法を使用して、データの品質を評価および改善するためのルールを自動的に作成します。 自動生成されたルールはコンテンツ固有です。 一般的なルールのほとんどは自動的に生成されるため、カスタム ルールの作成に多くの労力を要する必要はありません。
自動生成されたルールを参照して適用するには:
データ資産の [ ルール ] タブで、[ ルールの提案] を選択します。
推奨されるルールの一覧を参照します。
![[ルールの提案] ボタンが強調表示されている資産の [ルール] タブのスクリーンショット。](media/concept-data-quality-rules/suggest-rule-main-inline.png)
推奨されるルールの一覧からルールを選択して、データ資産に適用します。

![[ルールの提案] ボタンが強調表示されている資産の [ルール] タブのスクリーンショット。](media/concept-data-quality-rules/suggest-rule-main.png#lightbox)

次の手順
- データ製品でデータ品質スキャンを構成して実行 し、データ製品でサポートされているすべての資産の品質を評価します。
- スキャン結果を確認 して、データ製品の現在のデータ品質を評価します。