適用対象:✅Microsoft Fabric の倉庫
この記事では、パフォーマンス、スケーラビリティ、およびコスト効率を強化する Fabric Data Warehouse のアーキテクチャの機能とイノベーションについて説明します。
Fabric Data Warehouse は、コンバージド データ プラットフォームの将来対応アーキテクチャで実行されます。 オープンな Delta ストレージ形式と OneLake 統合により、Fabric Data Warehouse 内のデータを分析する準備が整います。
高レベルのアーキテクチャ

Fabric Data Warehouse は、次の構成要素を備えた大規模な分析用に構築されています。
| ビルディングブロック | 説明 |
|---|---|
| 統合クエリ オプティマイザー | ユーザーが作成した SQL クエリの品質に関係なく、分散クラウド環境に最適な実行プランを生成します。 |
| 分散クエリ処理 | クラウド インフラストラクチャの迅速な自動スケーリングにより、大規模な並列クエリ実行をサポートし、クエリに必要なコンピューティング リソースを即座に提供します。 個別の SELECT ワークロードと DML ワークロードでは、効率的で分離された実行のために個別のプールが使用されます。 |
| クエリ実行エンジン | 高速なパフォーマンスと高いコンカレンシーを備えた大量のデータに対して分析クエリを実行するための SQL ベースのエンジン。 |
| メタデータとトランザクションの管理 | メタデータは、フロントエンド、バックエンド、およびローカル SSD キャッシュとリモート OneLake ストレージの両方に存在します。 同時実行トランザクションをサポートし、ACID コンプライアンスを保証します。 |
| OneLake のストレージ | オープン Delta テーブル形式を使用して実装されたログ構造化テーブル。これは、セキュリティで保護されたオープン ストレージを備えたレイクハウス モデルです。 |
| Fabric Platform | Fabric Platform には、 統合された認証とセキュリティ モデル、 監視、 監査が用意されています。 Fabric Data Warehouse は、Power BI、Data Factory のデータ パイプライン、Real-Time インテリジェンスなどのビジネス ニーズを満たすために、他の Fabric プラットフォーム サービスで自動的に使用できます。 |
統合クエリ オプティマイザー エンジン
Fabric Data Warehouse の統合クエリ オプティマイザーは、SQL クエリを実行する最もスマートな方法を決定するエンジンです。
クエリを送信すると、統合クエリ オプティマイザーは、テーブルを結合する方法、データを移動する場所、CPU、メモリ、ネットワークなどのリソースを使用する方法など、可能な実行方法を確認します。 統合クエリ オプティマイザーは、最初のオプションを選択するだけでなく、これらの要因と使用可能なメタデータと統計のコストを評価することで、許容される時間内に最適なプランを選択します。

クエリの実行プランを最適化する場合、統合クエリ オプティマイザーでは、クエリの形状、テーブルのデータ分散、データの移動とローカルでの処理のコストなど、すべてを一度に考慮します。 統合クエリ オプティマイザーは、小さなテーブルをブロードキャストする方が大きなテーブルをシャッフルするよりも安価かどうかを判断するようなスマートなトレードオフを実現できます。 つまり、複雑な T-SQL クエリや不適切に記述された T-SQL クエリでも、不要なデータ シャッフルが少なく、コンピューティングの使用が向上し、パフォーマンスが向上します。
一貫性のあるパフォーマンスでは、開発者が T-SQL クエリの手動チューニングに時間を費やす必要はありません。 たとえば、クエリで最適な JOIN 順序を手動で決定する必要はありません。 SQL で大きなテーブルが最初に一覧表示され、2 番目に小さい、選択性の高いデータ テーブルが一覧表示される場合、オプティマイザーは自動的に位置を切り替えてパフォーマンスを向上させることができます。 一致する行の開始点として小さいテーブル ("ビルド" 側) を使用し、大きなテーブルを検索するテーブルとして使用します ("プローブ" 側では、一致がチェックされます)。 この方法では、メモリ使用量を最小限に抑え、データ移動を減らし、並列処理を改善しながら、正確な結果を得ることができます。
統合クエリ オプティマイザーは、ワークロードの進化に伴い、過去のクエリ実行から継続的に学習し、最適化アルゴリズムを改良して、可能な限り最高のパフォーマンスを実現します。 複雑さに関係なく、介入しなくても、ユーザーはクエリの高速実行を自動的に利用できます。
分散クエリ処理エンジン
Fabric Data Warehouse では、分散クエリ処理エンジンはコンピューティング リソースをクエリ プランのタスクに割り当てます。 分散クエリ処理エンジンでは、コンピューティング ノード間でタスクをスケジュールできるため、各ノードがクエリ プランの一部を実行し、並列実行を有効にしてパフォーマンスを向上させることができます。 大規模なデータセットに関する複雑なレポートは、分散クエリ処理の恩恵を受けることができます。
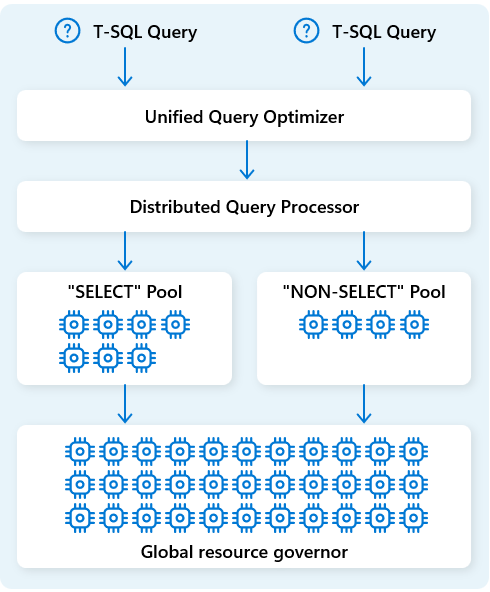
リソースをさらに最適化するために、分散クエリ処理エンジンは、 SELECT クエリとデータ インジェスト タスク (NON-SELECT クエリ) の 2 つのプールにコンピューティング リソースを分離します。 各ワークロードは、必要に応じて専用のリソースを受け取ります。 これは、たとえば、夜間の ETL ジョブが朝のダッシュボードを遅らせないことを意味します。
クラウドでの迅速なノード プロビジョニングにより、分散クエリ処理エンジンは、クエリの量、データ サイズ、クエリの複雑さの変化に応じて、コンピューティング リソースを自動的にスケールアップまたはスケールダウンします。 Fabric Data Warehouse には、マルチペタバイト規模の小規模なデータセットまたはデータに対する並列処理機能があります。
クエリ実行エンジン
クエリ実行エンジンは、個々のコンピューティング ノードに割り当てられている分散実行プランの一部を実行するプロセスです。 クエリ実行エンジンは、最適なコストでビッグ データを効率的に分析するために バッチ モード の実行と 列形式 のデータ形式を使用するために SQL Server と Azure SQL Database によって使用されるのと同じエンジンに基づいています。
クエリ実行エンジンは、Fabric OneLake に格納されている Delta Parquet ファイルから直接データを読み取り、複数のキャッシュ レイヤー (メモリと SSD) を利用してクエリのパフォーマンスを向上させ、クエリが最適な速度で実行されるようにします。 クエリ実行エンジンはメモリ内のデータを処理し、必要に応じて SSD キャッシュまたは OneLake ストレージから追加のデータを取得します。

データを処理する場合、クエリ実行エンジンは列と行グループの削除を実行して、クエリに関連しないセグメントをスキップします。 この最適化により、ファイルとメモリ キャッシュからスキャンされるデータの量が減り、リソースの使用量を最小限に抑え、全体的な実行時間を短縮できます。
クエリ実行エンジンは、数十億行のフィルター処理と集計に優れており、最新のデータ ウェアハウス ソリューションで使用される一般的なデータ分析パターンをサポートします。 バッチ モードの実行では、複数の行を並列に処理する最新の CPU 機能が利用され、従来の行ごとの実行に比べてオーバーヘッドが大幅に削減され、クエリの実行速度が数百倍向上します。
メタデータとトランザクションの管理
ウェアハウス エンジンは、メタデータを使用して、テーブル スキーマ、ファイル編成、バージョン履歴、トランザクション状態を記述します。 このメタデータにより、ウェアハウス エンジンはデータを効率的に管理および照会できます。 Fabric Data Warehouse は、堅牢で包括的なメタデータとトランザクション管理アーキテクチャを提供し、OLTP トランザクション マネージャーを拡張して、高度に同時実行されるメタデータ操作を調整し、ACID コンプライアンスを確保します。

この設計により、トランザクション状態の高速で信頼性の高いナビゲーションが可能になり、一貫性を確保しながら、高いコンカレンシーでワークロードをサポートできます。
ストレージとデータインジェスト
Fabric Data Warehouse では、オープンソースの Delta 形式を使用したレイクハウス アーキテクチャを使用して、スケーラブルでセキュリティで保護された高パフォーマンスのストレージを実現します。 Delta テーブル形式では、データのバージョン管理がサポートされており、 タイム トラベル と ゼロ コピー複製 を使用して履歴スナップショットにすぐにアクセスして、安全なテストおよびロールバック操作を行えます。 ユーザー データは OneLake 内に格納されるため、すべての Fabric エンジンが冗長性なしで共有データに効率的にアクセスできます。
この基盤の上に構築された Fabric Data Warehouse は、シンプルさと柔軟性に重点を置いて、最適なデータ インジェスト パフォーマンスを実現するように設計されています。 エンジンは、不要なデータスキャンを減らすためにバックグラウンドで断片化されたファイルを統合する 自動データ圧縮によってテーブルデータストレージを効率的に管理します。 そのインテリジェントなデータ分散方法は、並列処理を促進し、クエリ結果を強化するために、マイクロパーティション分割されたセルにデータを分割および整理します。 これらの機能は自律的に機能し、手動で調整する必要はありません。