適用対象: ✅Microsoft Fabric✅Azure データ エクスプローラー✅Azure Monitor✅Microsoft Sentinel
Kusto クエリ言語 (KQL) には、異常な動作を確認するための異常 検出および予測 関数が組み込まれています。 このようなパターンが検出されたら、根本原因分析 (RCA) を実行して、異常を軽減または解決できます。
診断プロセスは複雑で長く、ドメインの専門家によって行われます。 このプロセスには次のものが含まれます。
- 異なる期間に複数のソースからより多くのデータを取得して結合する
- 複数のディメンションでの値の分布の変更を探す
- その他の変数のグラフ化
- ドメインの知識と直感に基づくその他の手法
これらの診断シナリオは一般的であるため、機械学習プラグインを使用して診断フェーズを容易にし、RCA の期間を短縮できます。
次の 3 つの Machine Learning プラグインはすべて、クラスタリング アルゴリズム ( autocluster、 basket、 diffpatterns) を実装しています。
autoclusterプラグインとbasket プラグインは 1 つのレコード セットをクラスター化し、diffpatterns プラグインは 2 つのレコード セットの違いをクラスター化します。
1 つのレコード セットをクラスタリングする
一般的なシナリオには、次のような特定の条件によって選択されたデータセットが含まれます。
- 異常な動作を示す時間枠
- 高温デバイスの測定値
- 長時間のコマンド
- 支出の多いユーザー
データ内の一般的なパターン (セグメント) を迅速かつ簡単に見つける方法が必要です。 パターンは、複数のディメンション (カテゴリ列) で同じ値を共有するレコードを持つデータセットのサブセットです。
次のクエリは、1 週間にわたるサービス例外の時系列を 10 分のビンで構築して示しています。
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m
| render timechart with(title="Service exceptions over a week, 10 minutes resolution")

サービス例外の数は、サービス トラフィック全体に関連付けられます。 月曜日から金曜日の営業日の毎日のパターンを明確に確認できます。 サービスの例外数が日中に増加し、夜間にカウントが減少しています。 週末にはフラットな低カウントが表示されます。 例外の急増は、 時系列の異常検出を使用して検出できます。
データの2番目のピークは、火曜日の午後に発生します。 次のクエリは、急激なスパイクであるかどうかをさらに診断して確認するために使用されます。 このクエリは、1分間のビンで8時間という高解像度でスパイク周辺のグラフを再描画します。その後、その境界を調査することができます。
let min_t=datetime(2016-08-23 11:00);
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to min_t+8h step 1m
| render timechart with(title="Zoom on the 2nd spike, 1 minute resolution")

15:00から15:02までの間に狭い2分間のピークが確認できます。 次のクエリでは、この 2 分間のウィンドウで例外をカウントします。
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| count
| 数える |
|---|
| 972 |
次のクエリでは、972 個のうち 20 個の例外をサンプルします。
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| take 20
| 精密タイムスタンプ | リージョン | ScaleUnit | デプロイメントID | トレースポイント | サービスホスト |
|---|---|---|---|---|---|
| 2016-08-23 15:00:08.7302460 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:09.9496584 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 8d257da1-7a1c-44f5-9acd-f9e02ff507fd |
| 2016-08-23 15:00:10.5911748 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:12.2957912 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | f855fcef-ebfe-405d-aaf8-9c5e2e43d862 |
| 2016-08-23 15:00:18.5955357 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 9d390e07-417d-42eb-bebd-793965189a28 |
| 2016-08-23 15:00:20.7444854 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 6e54c1c8-42d3-4e4e-8b79-9bb076ca71f1 |
| 2016-08-23 15:00:23.8694999 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 36109 | 19422243-19b9-4d85-9ca6-bc961861d287 |
| 2016-08-23 15:00:26.4271786 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 36109 | 3271bae4-1c5b-4f73-98ef-cc117e9be914 |
| 2016-08-23 15:00:27.8958124 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 904498 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:32.9884969 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007007 | d5c7c825-9d46-4ab7-a0c1-8e2ac1d83ddb |
| 2016-08-23 15:00:34.5061623 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:37.4490273 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | f2ee8254-173c-477d-a1de-4902150ea50d |
| 2016-08-23 15:00:41.2431223 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 103200 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:47.2983975 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 423690590 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:50.5932834 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 2a41b552-aa19-4987-8cdd-410a3af016ac |
| 2016-08-23 15:00:50.8259021 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 0d56b8e3-470d-4213-91da-97405f8d005e |
| 2016-08-23 15:00:53.2490731 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 36109 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:57.0000946 | eus2 | su2 | 89e2f62a73bb4efd8f545aeae40d7e51 | 64038 | cb55739e-4afe-46a3-970f-1b49d8ee7564 |
| 2016-08-23 15:00:58.2222707 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | 8215dcf6-2de0-42bd-9c90-181c70486c9c |
| 2016-08-23 15:00:59.9382620 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | 451e3c4c-0808-4566-a64d-84d85cf30978 |
1,000 個未満の例外があっても、各列に複数の値があるため、共通のセグメントを見つけることは困難です。 次のクエリに示すように、 autocluster() プラグインを使用して、一般的なセグメントの短いリストを即座に抽出し、スパイクの 2 分以内に興味深いクラスターを見つけることができます。
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate autocluster()
| セグメントID | 数える | パーセント | リージョン | ScaleUnit | デプロイメントID | サービスホスト |
|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | 水 | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 1 | 94 | 9.67078189300411 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | |
| 2 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 3 | 68 | 6.99588477366255 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | |
| 4 | 55 | 5.65843621399177 | weu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc |
上記の結果から、最も優先度の高いセグメントには、例外レコード全体の 65.74% が含まれており、4 つのディメンションを共有していることがわかります。 次のセグメントはあまり一般的ではありません。 レコードの% は 9.67% のみを占めており、3 つの次元を共有した。 他のセグメントはさらに珍しいです。
Autocluster は、複数のディメンションをマイニングし、興味深いセグメントを抽出するために独自のアルゴリズムを使用します。 "興味深い" とは、各セグメントがレコード セットと特徴セットの両方を大きくカバーしていることを意味します。 セグメントも分岐し、それぞれが他のセグメントと異なっていることを意味します。 これらのセグメントの 1 つ以上が RCA プロセスに関連している可能性があります。 セグメントのレビューと評価を最小限に抑えるために、自動クラスターは小さなセグメント リストのみを抽出します。
次のクエリに示すように、 basket() プラグインを使用することもできます。
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate basket()
| セグメントID | 数える | パーセント | リージョン | ScaleUnit | デプロイメントID | トレースポイント | サービスホスト |
|---|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | 水 | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec | |
| 1 | 642 | 66.0493827160494 | 水 | su7 | b5d1d4df547d4a04ac15885617edba57 | ||
| 2 | 324 | 33.3333333333333 | 水 | su7 | b5d1d4df547d4a04ac15885617edba57 | 0 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 3 | 315 | 32.4074074074074 | 水 | su7 | b5d1d4df547d4a04ac15885617edba57 | 16108 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 4 | 328 | 33.7448559670782 | 0 | ||||
| 5 | 94 | 9.67078189300411 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | ||
| 6 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | ||
| 7 | 68 | 6.99588477366255 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | ||
| 8 | 167 | 17.1810699588477 | scus | ||||
| 9 | 55 | 5.65843621399177 | weu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | ||
| 10 | 92 | 9.46502057613169 | 10007007 | ||||
| 11 | 90 | 9.25925925925926 | 10007006 | ||||
| 12 | 五十七 | 5.8641975308642 | 00000000-0000-0000-0000-000000000000 |
Basket は、アイテム セット マイニング用の "Apriori" アルゴリズムを実装します。 しきい値を超えるレコード セットの範囲に含まれるすべてのセグメントが抽出されます(既定値は 5%)。 セグメント 0、1、2、3 など、類似したセグメントで抽出されたセグメントが増えたことがわかります。
どちらのプラグインも強力で使いやすいです。 それらの限界は、ラベルなしで1つのレコードセットを教師なしの方法でクラスター化することです。 抽出されたパターンが、選択したレコード セット、異常なレコード、またはグローバル レコード セットを特徴付けしているかどうかは不明です。
2 つのレコード セットの違いをクラスタリングする
diffpatterns()プラグインは、autoclusterとbasketの制限を克服します。
Diffpatterns は 2 つのレコード セットを受け取り、異なるメイン セグメントを抽出します。 通常、1 つのセットには、調査中の異常なレコード セットが含まれています。 1 つは、 autocluster と basketによって分析されます。 もう 1 つのセットには、基準となる参照レコード セットが含まれています。
次のクエリでは、 diffpatterns は、ベースライン内のクラスターとは異なる、スパイクの 2 分以内に興味深いクラスターを見つけます。 ベースライン ウィンドウは、15:00に発生した急上昇が始まる前の8分間として定義されます。 バイナリ列 (AB) で拡張し、特定のレコードがベースラインに属しているか、異常なセットに属しているかを指定します。
Diffpatterns は教師あり学習アルゴリズムを実装します。このアルゴリズムでは、異常フラグとベースラインフラグ (AB) に基づいて2つのクラスラベルが生成されました。
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
let min_baseline_t=datetime(2016-08-23 14:50);
let max_baseline_t=datetime(2016-08-23 14:58); // Leave a gap between the baseline and the spike to avoid the transition zone.
let splitime=(max_baseline_t+min_peak_t)/2.0;
demo_clustering1
| where (PreciseTimeStamp between(min_baseline_t..max_baseline_t)) or
(PreciseTimeStamp between(min_peak_t..max_peak_t))
| extend AB=iff(PreciseTimeStamp > splitime, 'Anomaly', 'Baseline')
| evaluate diffpatterns(AB, 'Anomaly', 'Baseline')
| セグメントID | カウントA | CountB | パーセントA | パーセントB | ABの差の割合 | リージョン | ScaleUnit | デプロイメントID | トレースポイント |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 639 | 21 (二十一) | 65.74 | 1.7 | 64.04 | 水 | su7 | b5d1d4df547d4a04ac15885617edba57 | |
| 1 | 167 | 544 | 17.18 | 44.16 | 26.97 | scus | |||
| 2 | 92 | 356 | 9.47 | 28.9 | 19.43 | 10007007 | |||
| 3 | 90 | 336 | 9.26 | 27.27 | 18.01 | 10007006 | |||
| 4 | 82 | 318 | 8.44 | 25.81 | 17.38 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 5 | 55 | 252 | 5.66 | 20.45 | 14.8 | weu | su4 | be1d6d7ac9574cbc9a22cb8ee20f16fc | |
| 6 | 五十七 | 204 | 5.86 | 16.56 | 10.69 |
最も優勢なセグメントは、 autoclusterによって抽出されたのと同じセグメントです。 2 分間の異常ウィンドウでのカバレッジも 65.74%です。 ただし、8分間の基準ウィンドウにおけるカバー範囲は、わずか1.7%です。 違いは 64.04%です。 この違いは、突発的な異常増加に関連しているようです。 この前提条件を確認するために、次のクエリでは、元のグラフを、この問題のあるセグメントに属するレコードと、他のセグメントのレコードに分割します。
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| extend seg = iff(Region == "eau" and ScaleUnit == "su7" and DeploymentId == "b5d1d4df547d4a04ac15885617edba57"
and ServiceHost == "e7f60c5d-4944-42b3-922a-92e98a8e7dec", "Problem", "Normal")
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m by seg
| render timechart
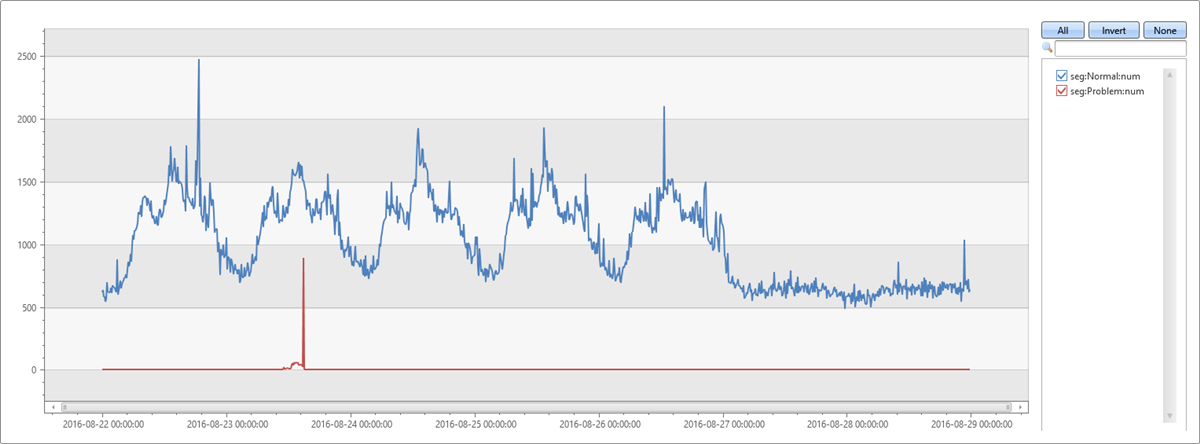
このグラフを使用すると、火曜日の午後のスパイクは、この特定のセグメントからの例外が原因で、 diffpatterns プラグインを使用して検出されたことを確認できます。
概要
Machine Learning プラグインは、多くのシナリオで役立ちます。
autoclusterとbasketは教師なし学習アルゴリズムを実装し、使いやすいです。
Diffpatterns は教師あり学習アルゴリズムを実装しますが、より複雑ですが、RCA の差別化セグメントを抽出する方が強力です。
これらのプラグインは、アドホック シナリオや、ほぼリアルタイムの自動監視サービスで対話形式で使用されます。 時系列の異常検出の後に、診断プロセスが続きます。 このプロセスは、必要なパフォーマンス標準を満たすように高度に最適化されています。