Spark について知る
Spark の中核となる のはデータ処理エンジンです。つまり、データ エンジニアは分散システム全体で大量のデータセットを効率的に抽出、変換、分析できます。 その違いは、1 つのフレームワークでさまざまな種類のデータ ワークロードを統合できることです。 Spark では、リアルタイム ストリーミング、バッチ処理、SQL クエリ、機械学習に個別のシステムは必要ありません。 すべての処理は、一貫した API セットを使用して Spark で実行できます。
もう 1 つの強みは、使いやすさにあります。 Spark では、Python、Java、Scala、R など、複数のプログラミング言語がサポートされています。Python に慣れている場合は、Spark 用の Python インターフェイスである PySpark を使用して、データの分析をすぐに開始できます。
おそらく最も重要なのは、Spark がスケーラビリティを念頭に置いて構築されたことです。 ローカル コンピューターで実験を開始し、コードを変更せずに、数百または数千台のマシンのクラスターで同じアプリケーションを実行できます。
Spark のエコシステム
多くの場合、Spark は単一のものとして話されますが、実際にはコア エンジンの上に構築されたライブラリのエコシステムです。
Spark Core は、タスクのスケジュール設定、メモリ管理、障害復旧など、分散コンピューティングの基盤を提供します。
Spark SQL では、ほとんどのアナリストが既に知っている言語である SQL を使用して構造化データを操作できます。 また、Hive、Parquet、JSON などの外部データ ソースとも統合されます。
Spark Streaming を使用すると、ほぼリアルタイムでデータを処理できます。これは、不正行為の検出やシステム ログの監視などのアプリケーションに役立ちます。
MLlib は Spark の機械学習ライブラリです。 分類、クラスタリング、回帰、および推奨事項のためのアルゴリズムのスケーラブルな実装が提供されます。
GraphX は、ソーシャル ネットワークの分析やエンティティ間のリレーションシップのモデリングなど、グラフ計算に使用されます。
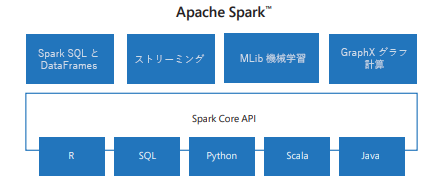
これらのコンポーネントを組み合わせることで、Spark はほとんどのビッグ データの問題に対するワンストップ ソリューションになります。
Spark のしくみ
あなたは疑問に思うかもしれません: なぜ私は最初にSparkプログラムを書くのですか? 答えはスケールです。 データセットが大きすぎて 1 台のコンピューターのメモリに収まらない場合や、Pandas や Excel などの従来のツールが管理できるよりも速く計算を完了する必要がある場合は、Spark ステップインします。 Spark を使用すると、ローカル データの操作と非常によく似たコードを記述できますが、クラスター内の多くのマシンに自動的に分散されます。 その結果、データセットが拡大するたびにロジックを書き換えることなく、ギガバイト、テラバイト、またはペタバイト単位のデータを分析できます。
会社が Web サイトのクリックストリーム データを Azure Data Lake Storage に格納するとします。 過去 24 時間のすべてのクリックをフィルター処理し、それをユーザー プロファイル テーブルと結合し、最もアクセスされた上位 5 つの製品カテゴリを計算することで、顧客の行動を理解したいと考えています。
Databricks でこれを実装すると、次のようになります。
ノートブックには Python (PySpark) で記述したコードが含まれており、これはドライバー プログラムで実行されます。 ドライバーは、高レベルのコマンド (行のフィルター処理やデータのグループ化など) を小さなタスクの計画に変換する役割を担います。
クラスター マネージャー は、これらのタスクを別の Executor に割り当てます。 各 Executor は、クラスター内のマシンで実行されているワーカー プロセスです。 Apache Spark クラスターは、1 つのコンピューティング エンジンとして扱われ、ノートブックから発行されたコマンドの実行を処理する、相互接続されたサーバーのグループです。 1 つの Executor は、昨日のクリックをユーザー ID 1 から 100,000 に対してフィルターをかけ、別の Executor (同じサーバー上または別のサーバー上) が ID 100,001 から 200,000 に対してフィルターをかけることができます。
すべての Executor が作業の一部を完了すると、Spark は結果を収集して結合し、上位の製品カテゴリを示すクリーンな DataFrame を返します。

データ エンジニアとしての観点からは、Databricks ノートブックで使い慣れた DataFrame コードを記述するだけです。 Spark は、データの分散、計算の並列化、クラスターで何かが失敗した場合のタスクの再試行を処理します。 この設計により、Spark は利用しやすく感じられます。ほぼローカルデータツールを扱っているかのように感じるでしょうが、実際には内部で数百台のコンピューターにわたり、非常に並列で耐障害性の高い計算を管理しています。
遅延評価とDAG(有向非循環グラフ)
Spark の最も重要な設計の選択肢の 1 つは、 遅延評価です。 各操作がすぐに実行される Pandas などのツールとは異なり、Spark はコマンドを記述するとすぐには実行されません。 代わりに、行のフィルター処理、テーブルの結合、列の選択などの変換を適用すると、Spark は単純にこれらの操作をプランに記録します。 実際には、まだ何も計算されていません。 このアプローチにより、Spark は、最も効率的な実行方法を決定する前に、一連の操作を完全に確認できます。
バックグラウンドで、Spark は操作の 有向非巡回グラフ (DAG) を構築します。 グラフ内の各ノードはデータセットを表し、各エッジはそのデータセットに適用される変換を表します。 グラフは非循環であるため、生の入力データから最終的な結果まで、それ自体をループすることなく一方向に流れます。 Spark のオプティマイザーは、この DAG を分析して、手順を組み合わせ、データ移動を最小限に抑え、クラスター全体で最適な実行戦略を決定します。

実行は、ドライバーへの結果の収集、ストレージへのデータの書き込み、行のカウントなどの アクションを実行した場合にのみ開始されます。 その時点で、Spark は最適化された DAG を一連のタスクとしてクラスター マネージャーに送信し、それらを Executor に分散します。 この設計は、Spark が高いパフォーマンスを実現するのに役立ちます。不要な計算を回避し、ノード間のデータのシャッフルを減らし、クラスター リソースを可能な限り効率的に使用できるようにします。
実際の使用事例
多くの業界の組織は、大規模または高速に移動するデータセットを処理および分析する必要がある場合は常に Spark を使用します。 たとえば、 ビデオ ストリーミング サービス では、Spark を使用して、表示履歴に基づいて新しいコンテンツを提案するレコメンデーション エンジンを構築できます。 金融機関は、Spark Streaming を利用してトランザクションをリアルタイムで監視し、疑わしいアクティビティにフラグを設定できます。 医療部門では、研究者は Spark を使用して大規模な遺伝子データを分析し、病気に関連するパターンを特定する可能性があります。 従来のビジネス設定でも、Spark は多くの場合、ダッシュボードやレポートに使用できるように生の運用データを準備および変換する役割を果たします。
その他の一般的なアプリケーションには、大量の Web サーバー ログの分析、モノのインターネット (IoT) デバイス用の リアルタイム ダッシュボード の機能の提供、非常に大規模なデータセットでの 機械学習モデル のトレーニング、複数のソースから生データを抽出、クリーンアップ、結合する ETL パイプライン の構築などがあります。
互換性と展開のオプション
Spark の長所の 1 つは、単一のインフラストラクチャにロックされないことです。 代わりに、さまざまな分散システム上で実行するように設計されているため、展開方法と展開場所に柔軟性が提供されます。 最も簡単なレベルでは、Spark は自分のコンピューター上でローカルで実行できるため、クラスターを設定せずに小さなデータセットを簡単に試したり、基本を学習したりできます。 より多くの電力が必要な場合は、マシンのスタンドアロン クラスターで Spark を実行してスケールアウトするか、スケジュールとリソース割り当てを処理する Hadoop YARN や Apache Mesos などのリソース マネージャーと統合できます。
クラウドでは、Spark はプロバイダー間で広くサポートされています。 たとえば、 Azure Databricks、 Azure Synapse Analytics 、 Microsoft Fabric などのサービスでは、クラスターのセットアップと管理の詳細を気にせずに Spark クラスターを簡単に起動できます。 また、Spark は Kubernetes にますますデプロイされています。これにより、組織は Spark アプリケーションをコンテナー化し、最新のクラウドネイティブ環境で実行できます。 この柔軟性は、ニーズがローカル開発からオンプレミス クラスター、大規模なクラウド デプロイに進化するにつれて、異なるプラットフォーム用に書き換えることなく、同じ Spark アプリケーションを引き続き使用できることを意味します。