이 페이지에서는 AI/BI 대시보드에서 사용할 수 있는 시각화 유형을 간략하게 설명하고 각 시각화 유형의 예제를 만드는 방법을 보여 줍니다. 대시보드 빌드에 대한 지침은 대시보드 만들기를 참조하세요. 자연어를 사용하여 도우미에게 가로 막대형, 선, 점 맵, 분산형, 원형 및 카운터 차트를 만들라는 메시지를 표시할 수 있습니다. Databricks Assistant을 사용하여 시각화 만들기를 참조하세요.
중요합니다
이 페이지에서는 AI/BI 대시보드에 대한 시각화를 다룹니다. Azure Databricks Notebook 및 SQL 편집기에서 시각화는 Notebook 및 SQL 편집기 시각화 유형을 참조하세요.
시각화 렌더링 제한에 대한 자세한 내용은 대시보드 제한을 참조하세요.
영역 시각화
영역 시각화는 선과 막대 시각화를 결합하여 두 번째 변수의 진행률(일반적으로 해당 시간)에 대해 하나 이상의 그룹의 숫자 값이 변경되는 방식을 보여 줍니다. 구매 과정의 시간별 변화를 표시하는 데 자주 사용됩니다.
레이아웃을 조정하려면 다음을 수행합니다.
-
 을 클릭합니다. 시각화 편집 패널의 Y축 섹션에 있는 kebab 메뉴입니다.
을 클릭합니다. 시각화 편집 패널의 Y축 섹션에 있는 kebab 메뉴입니다. - 레이아웃 섹션에서 스택 또는 100% 스택을 선택합니다.
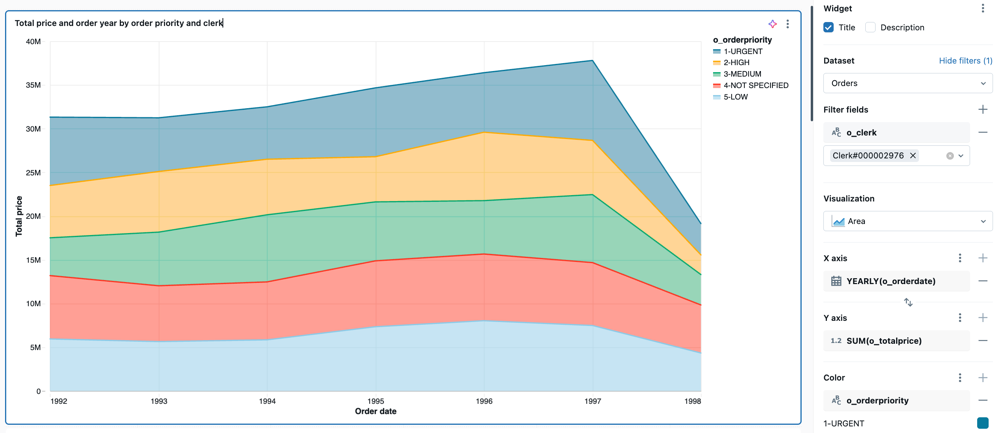
구성 값: 제공된 영역 시각화 예제의 경우 다음 값이 설정되었습니다.
- 데이터 세트: samples.tpch.orders
- 시각화: 영역
- 타이틀:
Total price and order year by order priority and clerk - X축:
- 필드:
o_orderdate - 변환하다:
Yearly - 배율 유형:
Continuous - 축 제목:
Order year
- 필드:
- Y축:
- 필드:
o_totalprice - 축 제목:
Total price - 배율 유형:
Continuous - 변환하다:
Sum
- 필드:
- 색:
- 필드:
o_orderpriority - 범례 제목:
Order priority
- 필드:
- 필터
- 필드:
TPCH orders.o_clerk
- 필드:
SQL 쿼리: 이 영역 시각화의 경우 다음 SQL 쿼리를 사용하여 명명 TPCH orders된 데이터 집합을 생성했습니다.
SELECT * FROM samples.tpch.orders;
막대형 차트
가로 막대형 차트는 시간 또는 범주 간 메트릭의 변화를 나타내며 원형 시각화와 유사하게 비례성을 표시합니다.

레이아웃을 조정하려면 다음을 수행합니다.
-
을 클릭합니다. 시각화 편집 패널의 Y축 섹션에 있는 kebab 메뉴입니다.
- 레이아웃 섹션에서 스택 또는 100% 스택 또는 그룹을 선택합니다.
구성 값: 제공된 가로 막대형 차트 예제의 경우 다음 값이 설정되었습니다.
- 데이터 세트: samples.tpch.orders
- 시각화: 막대
- 타이틀:
Total price and order month by order priority and clerk - X축:
- 필드:
o_orderdate - 변환하다:
Monthly - 배율 유형:
Continuous - 축 제목:
Order month
- 필드:
- Y축:
- 필드:
o_totalprice - 배율 유형:
Continuous - 변환하다:
Sum - 축 제목:
Total price
- 필드:
- 색:
- 필드:
o_orderpriority - 범례 제목:
Order priority
- 필드:
- 필터
- 필드:
TPCH orders.o_clerk
- 필드:
SQL 쿼리: 다음 SQL 쿼리는 이 막대 시각화에 대한 데이터 집합 TPCH orders 을 생성했습니다.
SELECT * FROM samples.tpch.orders;
상자형 차트
상자 차트 시각화는 범주별로 선택적으로 그룹화된 숫자 데이터의 분포 요약을 보여줍니다. 상자 차트 시각화를 사용하여 범주 간 값 범위를 빠르게 비교하고 해당 사분위수로 값의 지역성, 분산 및 기울이기 그룹을 시각화할 수 있습니다. 각 상자에서 어두운 선은 사분위수 범위를 나타냅니다. 상자 그림 시각화 해석에 대한 자세한 내용은 Wikipedia의 상자 차트 문서를 참조하세요.

제공된 상자 차트 예제의 경우 다음 값이 설정되었습니다.
- X 열(데이터 세트 열):
l-returnflag - Y 열(데이터셋 열):
l_extendedprice - X축 제목:
Return flag1 - Y축 제목:
Extended price
SQL 쿼리: 이 상자 차트 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
SELECT * FROM samples.tpch.lineitem;
거품형 차트
거품형 차트는 각 점 표식의 크기가 관련 메트릭을 반영하는 분산형 차트입니다. 거품형 차트를 만들려면 시각화 유형으로 분산 형을 선택합니다. 크기 설정에서 표식의 크기로 표시할 메트릭을 선택합니다.

구성 값: 제공된 거품형 차트 예제의 경우 다음 값이 설정되었습니다.
- 데이터 세트: NYC 택시 여행
- 시각화: 분산형
- 타이틀:
Trip distance, fares, and trip duration - X축:
- 필드:
trip_distance - 배율 유형:
Continuous - 변환하다:
None
- 필드:
- Y축:
- 필드:
fare_amount - 배율 유형:
Continuous - 변환하다:
None
- 필드:
- 색 기준:
- 필드:
pickup_zip
- 필드:
- 크기:
- 필드:
minutes_in_taxi - 변환하다:
None
- 필드:
SQL 쿼리: 이 거품형 차트 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
SELECT
*,
TIMESTAMPDIFF(MINUTE, tpep_pickup_datetime, tpep_dropoff_datetime) AS minutes_in_taxi
FROM samples.nyctaxi.trips
LIMIT 500;
색도 지도
초로프 시각화에서 국가 또는 주와 같은 지리적 지역은 각 키 열의 집계 값에 따라 색이 지정됩니다. 쿼리는 지리적 위치를 이름으로 반환해야 합니다. 사용자는 국가, 주 또는 지방, 카운티 또는 지구 수준에서 관리 경계를 표시하는 지도를 만들 수 있습니다.

구성 값: 이 초로프 시각화의 경우 다음 값이 설정되었습니다.
- 데이터 세트: samples.tpch.customer
- 나라:
Country - 컬러: 합계(c_acct_bal)
SQL 쿼리: 이 초로플스 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
SELECT
INITCAP(n_name) AS Country,
SUM(c_acctbal)
FROM samples.tpch.customer
JOIN samples.tpch.nation WHERE n_nationkey = c_nationkey
GROUP BY 1;
코호트 차트
코호트 차트는 공유 특성(예: 등록 날짜)에 따라 사용자를 그룹화하고 이후 기간 동안 활동을 추적하여 시간 경과에 따른 사용자 보존 및 동작 패턴을 시각화합니다. 이 시각화는 사용자의 다양한 코호트가 시간이 지남에 따라 제품 또는 서비스에 참여하는 방식을 이해하는 데 도움이 됩니다.

코호트 차트를 만들려면 보존 데이터와 함께 피벗 시각화를 사용합니다. 다음 예제에서는 고객이 처음 주문한 시점(코호트 날짜)을 계산하고 이후 몇 년 동안 활성 상태로 유지되는 각 코호트의 고객 수를 측정하여 고객 보존을 추적합니다. 색 눈금은 보존율을 나타내며 더 어두운 색은 더 높은 보존 기간을 표시합니다.
구성 값: 이 코호트 차트 예제의 경우 다음 값이 설정되었습니다.
- 데이터 세트: samples.tpch.orders
- 시각화: 피벗
- 타이틀:
Customer retention by cohort year - 행:
- 필드:
Cohort - 변환하다:
Yearly
- 필드:
- 열:
- 필드:
Active Period
- 필드:
- 세포:
- 필드:
Retention - 스타일:
Color Scale
- 필드:
SQL 쿼리: 이 코호트 차트 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합 Orders cohort analysis을 생성했습니다.
-- get the list of customers and when they were active
WITH history AS (
SELECT o_orderdate, o_custkey -- replace with the right columns representing date and id
FROM samples.tpch.orders -- replace with desired table
GROUP BY ALL
),
-- find the date of the first order for each customer
cohort AS (
SELECT o_custkey, MIN(o_orderdate) AS first_date
FROM history
GROUP BY 1
),
-- combine the customer activity table with the date of first activity, and choose a granularity (e.g. YEAR)
joined AS (
SELECT
DATE_TRUNC("YEAR", first_date) AS cohort,
CAST(DATE_DIFF(YEAR, cohort, o_orderdate) AS STRING) AS active,
o_custkey
FROM history LEFT JOIN cohort USING(o_custkey)
),
-- calculate the number of distinct customers by cohort and date active
grouped AS (
SELECT cohort, active, COUNT(DISTINCT o_custkey) AS customers
FROM joined
GROUP BY 1, 2
),
-- calculate the number of initial customers for each cohort
initial_customers AS (
SELECT cohort, customers AS t0_customers
FROM grouped
WHERE active = 0
)
-- calculate the retention by cohort and date active
SELECT
cohort AS Cohort,
active AS Active,
CASE WHEN active = 1 THEN CONCAT(active, " year")
ELSE CONCAT(active, " years") END AS `Active Period`,
customers AS Customers,
t0_customers AS `Initial Customers`,
TRY_DIVIDE(customers, t0_customers) AS Retention
FROM grouped LEFT JOIN initial_customers USING (cohort)
WHERE active > 0;
콤보 차트
콤보 차트는 선 차트와 가로 막대형 차트를 결합하여 시간에 따른 변경 내용을 비례적으로 표시합니다.

구성 값: 이 콤보 차트 시각화의 경우 다음 값이 설정되었습니다.
- 데이터 세트: samples.tpch.partsupp
- 시각화: 콤보
- X축:
ps_partkey- 배율 유형:
Continuous
- 배율 유형:
- Y축:
- 술집:
ps_availqty - 집계 유형:
SUM - 줄:
ps_supplycost - 집계 유형:
AVG
- 술집:
- Y 시리즈별 색:
Sum of ps_availqtyAverage ps_supplycost
SQL 쿼리: 이 콤보 차트 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
SELECT * FROM samples.tpch.partsupp;
이중 축 콤보 차트
콤보 차트를 사용하여 두 개의 서로 다른 y축을 표시할 수 있습니다. 콤보 차트 위젯을 선택한 상태에서 ![]() 을 클릭합니다. 차트 구성 패널의 Y축 설정에 있는 kebab 메뉴입니다.
이중 축 사용 옵션을 켭니다.
을 클릭합니다. 차트 구성 패널의 Y축 설정에 있는 kebab 메뉴입니다.
이중 축 사용 옵션을 켭니다.

구성 값: 이 콤보 차트의 경우 이중 축 사용 옵션이 설정됩니다. 다른 구성은 다음과 같이 설정됩니다.
- 데이터 세트: samples.nyctaxi.trips
- 시각화: 콤보
- X축:
tpep_pickup_datetime- 변환하다:
Weekly - 배율 유형:
Continuous
- 변환하다:
- Y축:
- 왼쪽 Y축(막대):
trip_distance- 변환하다:
AVG
- 변환하다:
- 오른쪽 Y축(선):
fare_amount- 변환하다:
AVG
- 변환하다:
- 왼쪽 Y축(막대):
Y 시리즈별 색:
Average trip_distanceAverage fare_amount
SQL 쿼리: 데이터 집합을 생성하는 데 사용된 SQL 쿼리는 다음과 같습니다.
SELECT * FROM samples.nyctaxi.trips;
카운터 시각화
카운터는 오프셋 값과 비교하는 옵션을 사용하여 단일 값을 눈에 띄게 표시합니다. 카운터를 사용하려면 값 및 비교 열의 카운터 시각화에 표시할 데이터를 지정합니다. 필요에 따라 날짜 열과 집계를 선택하여 차트에 스파크라인을 표시합니다.

조건부 서식을 설정하고 값 구성 세부 정보에서 텍스트 스타일을 사용자 지정할 수 있습니다.

구성 값: 이 카운터 시각화 예제의 경우 다음 값이 설정되었습니다.
- 데이터 세트:
samples.tpch.orders - 시각화: 카운터
- 타이틀:
Orders: Total price by date (compared to the previous day) - 값:
- 날짜:
DAILY(o_orderdate) - 값:
total price
- 날짜:
- 비교:
- 필드:
o_orderdate - 며칠 전 오프셋: -1
- 필드:
SQL 쿼리: 이 카운터 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 세트를 생성했습니다.
SELECT
SUM(o_totalprice) AS `total price`,
o_orderdate
FROM
samples.tpch.orders
GROUP BY o_orderdate
ORDER BY o_orderdate DESC;
깔때기형 차트
깔때기형 차트는 다양한 단계에서 메트릭의 변화를 분석하는 데 도움이 됩니다. 깔때기를 사용하려면 열과 step 열을 value 지정합니다.
예를 들어 다음 깔때기형 차트는 사용자가 등록 흐름의 단계를 진행하는 방법을 보여 줍니다. 각 단계는 해당 단계에 도달한 사용자 수를 반영하는 크기로 프로세스의 단계를 나타냅니다.

구성 값: 이 깔때기형 차트의 경우 다음 값이 설정되었습니다.
- 데이터 세트: 사용자 참여 깔때기 단계
- 시각화: 깔때기형
- X축:
stage - Y축:
count- 집계 유형:
SUM
- 집계 유형:
- 색 열:
- 데이터 세트 열:
count
- 데이터 세트 열:
SQL 쿼리: 다음 SQL 쿼리는 이 깔때기형 차트 시각화에 대한 데이터 집합을 생성했습니다.
SELECT *
FROM VALUES
('Visited Website', 10000),
('Signed Up', 4000),
('Activated Account', 2500),
('Added First Item', 1500),
('Completed Purchase', 800)
AS funnel(stage, count);
히트맵 차트
열 지도 차트는 가로 막대형 차트, 누적 차트 및 거품형 차트의 기능을 혼합하여 색을 사용하여 숫자 데이터를 시각화할 수 있습니다.
예를 들어 다음 열 지도는 우선 순위 및 배송 방법에 따라 주문 수를 시각화합니다. x축은 다양한 순서 우선 순위를 나타내고 y축은 다양한 배송 방법을 나타냅니다. 색 강도는 주문 개수의 합계를 나타내며, 범례는 주문 개수 배율을 보여 줍니다.
비고
열 지도는 최대 64K 행 또는 10MB까지 표시할 수 있습니다.
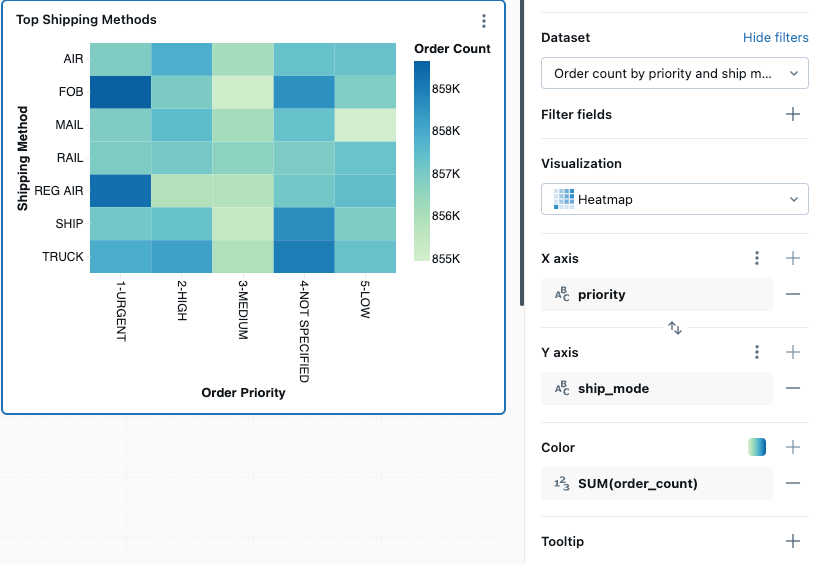
구성 값: 이 열 지도 차트 시각화의 경우 다음 값이 설정되었습니다.
- 데이터 세트: samples.tpch.orders
- 시각화: 히트맵
- X축:
priority - Y축:
ship_mode - 색 열:
- 데이터 세트 열:
order_count - 집계 유형:
SUM
- 데이터 세트 열:
- X축 이름(기본값 재정의):
Order Priority - Y축 이름(기본값 재정의):
Shipping method - 색 램프:
Green Blue
SQL 쿼리: 이 열 지도 차트 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
SELECT
o.o_orderpriority AS priority,
l.l_shipmode AS ship_mode,
COUNT(*) AS order_count,
o.o_orderdate
FROM
samples.tpch.orders AS o
JOIN
samples.tpch.lineitem AS l
ON
o.o_orderkey = l.l_orderkey
GROUP BY
o.o_orderpriority,
l.l_shipmode,
o.o_orderdate
ORDER BY
priority,
ship_mode;
히스토그램 차트
히스토그램은 지정된 값이 데이터 세트에서 발생하는 빈도를 그립니다. 히스토그램을 사용하면 데이터 세트에 적은 수의 범위 주위에 클러스터된 값이 있는지 아니면 더 많이 분산되어 있는지를 이해할 수 있습니다. 히스토그램은 고유 막대(bin이라고도 함)의 수를 제어하는 가로 막대형 차트로 표시됩니다.
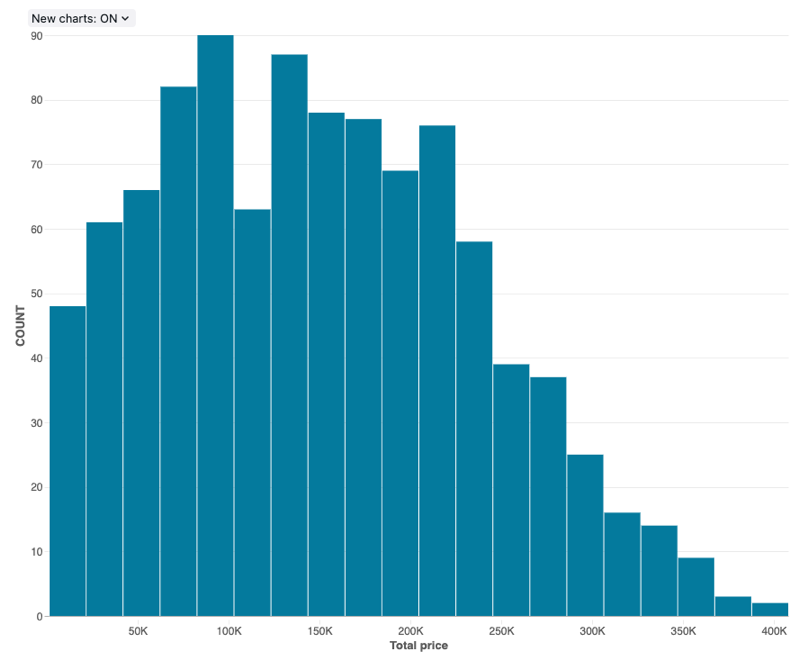
구성 값: 이 히스토그램 차트 시각화의 경우 다음 값이 설정되었습니다.
- 데이터 세트: samples.tpch.orders
- 시각화: 히스토그램
- X 열(데이터 세트 열):
o_totalprice - Bin 수: 20
- X축 이름(기본값 재정의):
Total price
구성 옵션: 히스토그램 차트 구성 옵션은 히스토그램 차트 구성 옵션을 참조하세요.
SQL 쿼리: 이 히스토그램 차트 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
SELECT * FROM samples.tpch.orders;
선 시각화
줄 시각화는 시간이 지남에 따라 하나 이상의 메트릭에 변경 내용을 표시합니다.

구성 값: 이 줄 시각화 예제의 경우 다음 값이 설정되었습니다.
- 데이터 세트: samples.tpch.orders
- 시각화: 선
- 타이틀:
Average price and order year by order priority and clerk - X축:
- 필드:
o_orderdate - 변환하다:
Yearly - 배율 유형:
Continuous - 축 제목:
Order year
- 필드:
- Y축:
- 필드:
o_totalprice - 변환하다:
Average - 배율 유형:
Continuous - 축 제목:
Average price
- 필드:
- 색:
- 필드:
o_orderpriority - 범례 제목:
Order priority
- 필드:
SQL 쿼리: 이 꺾은선형 차트 시각화의 경우 다음 SQL 쿼리를 사용하여 명명 Orders data된 데이터 집합을 생성했습니다.
SELECT * FROM samples.tpch.orders;
원형 시각화
원형 시각화는 메트릭 간의 비례성을 표시합니다. 시계열 데이터를 전달하기 위한 것이 아닙니다.

구성 값: 이 원형 시각화 예제의 경우 다음 값이 설정되었습니다.
- 데이터 세트: samples.tpch.orders
- 시각화: 원형 시각화
- 타이틀:
Total price by order priority and clerk - 각:
- 필드:
o_totalprice - 변환하다:
Sum - 축 제목:
Total price
- 필드:
- 색:
- 필드:
o_orderpriority - 범례 제목:
Order priority
- 필드:
- 필터
- 필드:
TPCH orders.o_clerk
- 필드:
SQL 쿼리: 이 원형 시각화의 경우 다음 SQL 쿼리를 사용하여 명명 TPCH orders된 데이터 집합을 생성했습니다.
SELECT * FROM samples.tpch.orders;
피벗 시각화
피벗 시각화는 쿼리 결과의 레코드를 테이블 형식 표시로 집계합니다. SQL의 PIVOT 또는 GROUP BY 명령문과 유사합니다. 끌어서 놓기 필드를 사용하여 피벗 시각화를 구성합니다.
고정 헤더, 조건부 서식 지정 및 링크 추가를 비롯한 피벗 테이블 구성 옵션에 대한 자세한 내용은 피벗 테이블 구성을 참조하세요.

구성 값: 이 피벗 시각화 예제의 경우 다음 값이 설정되었습니다.
- 데이터 세트: samples.tpch.lineitem
- 시각화: 피벗
- 타이틀:
Line item quantity by return flag and ship mode by supplier - 행:
- 필드:
l_returnflag - 표시 합계: 체크됨
- 필드:
- 열:
- 필드:
l_shipmode - 표시 합계: 체크됨
- 필드:
- 값
- 필드:
l_quantity - 변환: 합계
- 필드:
SQL 쿼리: 이 피벗 시각화의 경우 다음 SQL 쿼리를 사용하여 명명 TPCH lineitem된 데이터 집합을 생성했습니다.
SELECT * FROM samples.tpch.lineitem;
포인트 지도
점 맵은 정량적 데이터를 특정 지도 위치에 배치된 기호로 표시합니다. 표식은 위도 및 경도 좌표를 사용하여 배치되며 이 차트 종류에 대한 결과 집합의 일부로 포함되어야 합니다. 다음 예제에서는 뉴욕주 뉴욕에서 발생한 자동차 충돌 데이터를 사용합니다.

구성 값: 이 점 맵 시각화의 경우 다음 값이 설정되었습니다.
- 데이터 세트: 시애틀 주택 가격 분석
- 시각화: 점 맵
- 좌표:
- 위도:
LATITUDE - 경도:
LONGITUDE
- 위도:
- 색:
- 필드:
avg(bedrooms)- 배율 유형: 범주형
- 필드:
- 크기:
- 필드:
avg(price)
- 필드:
비고
Databricks 데이터 세트에는 위도 또는 경도 데이터가 포함되지 않으므로 이 예제에서는 샘플 SQL 쿼리가 제공되지 않습니다.
Sankey 다이어그램
sankey 다이어그램은 값 집합에서 다른 값 집합으로의 흐름을 시각화합니다.

구성 값: 이 sankey 다이어그램의 경우 다음 값이 설정되었습니다.
- 데이터 세트: samples.nyctaxi.trips
- 시각화: Sankey
- 단계
stage1stage2
- 값
- 합계(값)
SQL 쿼리: 이 Sankey 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
SELECT pickup_zip AS stage1, dropoff_zip AS stage2, SUM(fare_amount) AS value
FROM samples.nyctaxi.trips
GROUP BY 1, 2
ORDER BY 3 DESC
LIMIT 10;
분산 시각화
분산 시각화는 일반적으로 두 숫자 변수 간의 관계를 표시하는 데 사용됩니다. 세 번째 차원을 색으로 인코딩하여 숫자 변수가 그룹 간에 어떻게 다른지 표시할 수 있습니다.

구성 값: 이 분산 시각화 예제의 경우 다음 값이 설정되었습니다.
- 데이터 세트: samples.tpch.lineitem
- 시각화: 분산형
- 타이틀:
Total price and quantity by ship mode and supplier - X축:
- 필드:
l_quantity - 축 제목:
Quantity - 배율 유형:
Continuous - 변환하다:
None
- 필드:
- Y축:
- 필드:
l_extendedprice - 배율 유형:
Continuous - 변환하다:
None - 축 제목:
Price
- 필드:
- 색:
- 필드:
l_shipmode - 범례 제목:
Ship mode
- 필드:
- 필터
- 필드:
TPCH lineitem.l_supplierkey
- 필드:
SQL 쿼리: 이 분산 시각화의 경우 다음 SQL 쿼리를 사용하여 명명 TPCH lineitem된 데이터 집합을 생성했습니다.
SELECT * FROM samples.tpch.lineitem
테이블 시각화
테이블 시각화는 표준 테이블의 데이터를 표시하지만 데이터를 수동으로 다시 정렬, 숨기기 및 서식을 지정할 수 있습니다.
비고
테이블은 최대 64K 행 또는 10MB까지 표시할 수 있습니다.
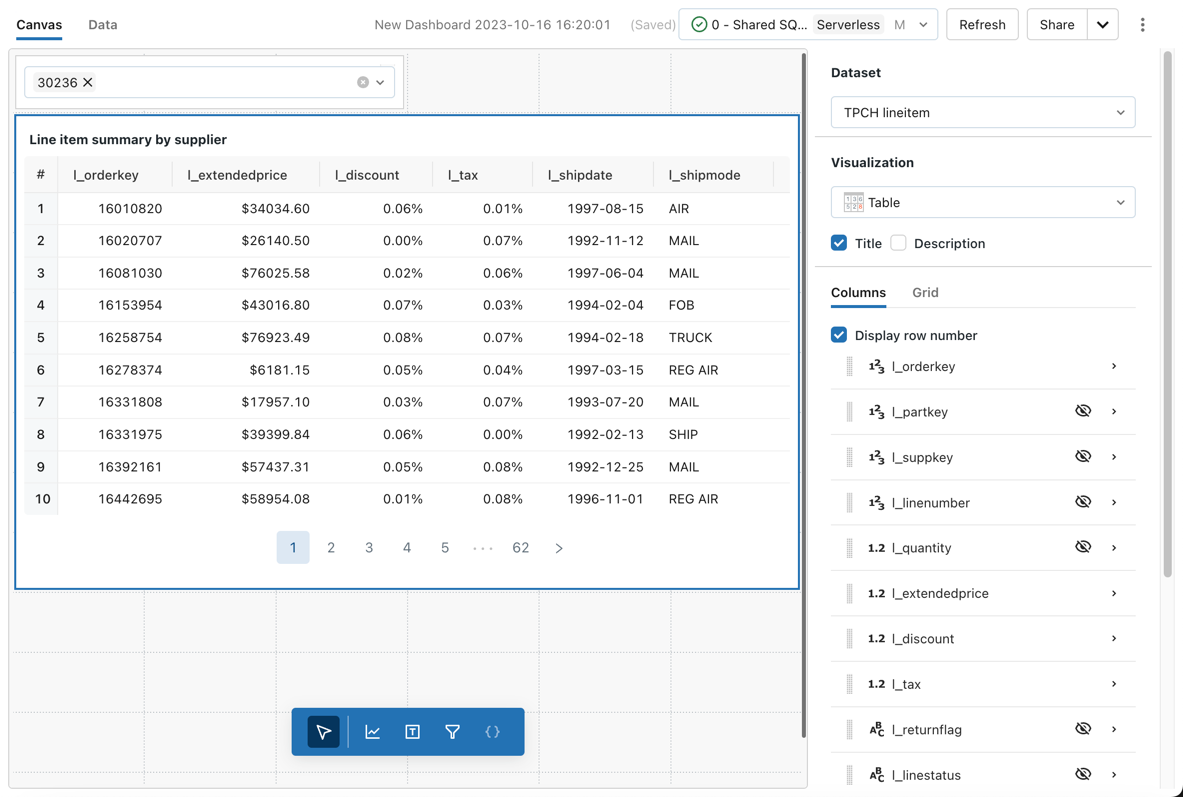
구성 값: 이 테이블 시각화 예제의 경우 다음 값이 설정되었습니다.
- 데이터 세트: samples.tpch.lineitem
- 시각화: 테이블
- 타이틀:
Line item summary by supplier - 열:
- 행 번호 표시: 사용함
- 필드:
l_orderkey - 필드:
l_extendedprice- 다음으로 표시:
Number - 숫자 형식: $0.00
- 다음으로 표시:
- 필드:
l_discount- 다음으로 표시:
Number - 숫자 형식: %0.00
- 다음으로 표시:
- 필드:
l_tax- 다음으로 표시:
Number - 숫자 형식: %0.00
- 다음으로 표시:
- 필드:
l_shipdate - 필드:
l_shipmode
- 필터
- 필드:
TPCH lineitem.l_supplierkey
- 필드:
구성 옵션: 테이블 시각화 구성 옵션은 테이블 옵션을 참조하세요.
SQL 쿼리: 이 테이블 시각화의 경우 다음 SQL 쿼리를 사용하여 명명 TPCH lineitem된 데이터 집합을 생성했습니다.
SELECT * FROM samples.tpch.lineitem
폭포 차트
폭포 차트는 순차적 양수 및 음수 값의 누적 효과를 표시하며, 초기 값이 일련의 중간 양수 및 음수 값에 의해 어떻게 영향을 받는지 보여줍니다. 일반적으로 수익 및 손실 명세서와 같은 재무 데이터를 시각화하거나 다양한 요인이 전체 변화에 어떻게 기여하는지를 표시하는 데 사용됩니다.

구성 값: 이 폭포 차트 예제의 경우 다음 값이 설정되었습니다.
- 데이터 세트: 쿼리에 의해 생성됨
- 시각화: 폭포
- X축: MONTHLY(date_col)
- Y축: SUM(amount)
SQL 쿼리: 이 테이블 시각화의 경우 다음 SQL 쿼리를 사용하여 데이터 집합을 생성했습니다.
with base as (
SELECT
*
FROM
VALUES
(2535, '2025-01-01'),
(-853, '2025-02-01'),
(3229, '2025-03-01'),
(1820, '2025-04-01'),
(3195, '2025-05-01'),
(-1800, '2025-06-01'),
(-562, '2025-07-01'),
(-332, '2025-08-01'),
(1750, '2025-09-01'),
(-330, '2025-10-01'),
(3300, '2025-11-01'),
(4400, '2025-12-01') AS t (amount, date_str)
)
SELECT
amount,
cast(date_str as date) as date_col
from
base