데이터 엔지니어링에서 백필은 현재 또는 스트리밍 데이터를 처리하도록 설계된 데이터 파이프라인을 통해 기록 데이터를 소급하여 처리하는 프로세스를 나타냅니다.
일반적으로 기존 테이블로 데이터를 보내는 별도의 흐름입니다. 다음 그림에서는 파이프라인의 브론즈 테이블에 과거 데이터를 보내는 백필 흐름을 보여 줍니다.
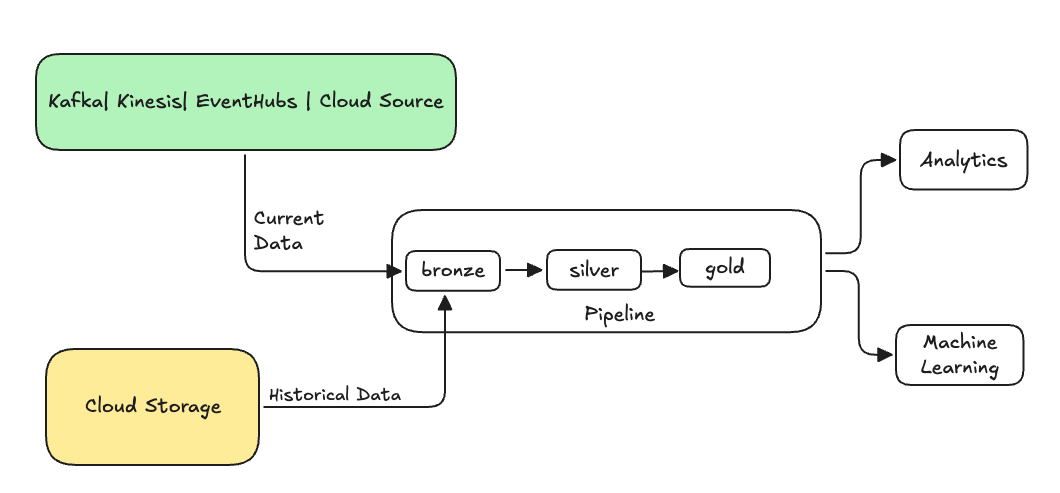
백필이 필요할 수 있는 몇 가지 시나리오:
- 레거시 시스템에서 기록 데이터를 처리하여 ML(기계 학습) 모델을 학습하거나 기록 추세 분석 대시보드를 빌드합니다.
- 업스트림 데이터 원본의 데이터 품질 문제로 인해 데이터의 하위 집합을 다시 처리합니다.
- 비즈니스 요구 사항이 변경되었으며 초기 파이프라인에서 다루지 않은 다른 기간 동안 데이터를 백필해야 합니다.
- 비즈니스 논리가 변경되었으며 기록 데이터와 현재 데이터를 모두 다시 처리해야 합니다.
Lakeflow Spark 선언적 파이프라인에서는 ONCE 옵션을 사용하는 특수 추가 흐름으로 백필이 지원됩니다. 옵션에 대한 자세한 내용은 append_flow 또는 CREATE FLOW(파이프라인) 를 ONCE 참조하세요.
기록 데이터를 스트리밍 테이블에 백필할 때 고려 사항
- 일반적으로 브론즈 스트리밍 테이블에 데이터를 추가합니다. 브론즈 계층의 데이터를 다운스트림 실버 및 골드 계층이 가져옵니다.
- 동일한 데이터가 여러 번 추가되는 경우 파이프라인에서 중복 데이터를 정상적으로 처리할 수 있는지 확인합니다.
- 기록 데이터 스키마가 현재 데이터 스키마와 호환되는지 확인합니다.
- 데이터 볼륨 크기 및 필요한 처리 시간 SLA를 고려하고 그에 따라 클러스터 및 일괄 처리 크기를 구성합니다.
예: 기존 파이프라인에 백필 작업 추가
이 예제에서는 2025년 1월 1일부터 클라우드 스토리지 원본에서 원시 이벤트 등록 데이터를 수집하는 파이프라인이 있다고 가정합니다. 나중에 다운스트림 보고 및 분석 사용 사례를 위해 이전 3년간의 기록 데이터를 백필하려고 한다는 것을 알게 됩니다. 모든 데이터는 JSON 형식으로 연도, 월 및 일별로 분할된 한 위치에 있습니다.
초기 파이프라인
클라우드 스토리지에서 원시 이벤트 등록 데이터를 증분 방식으로 수집하는 시작 파이프라인 코드는 다음과 같습니다.
파이썬
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
incremental_load_path = f"{source_root_path}/*/*/*"
# create a streaming table and the default flow to ingest streaming events
@dp.table(name="registration_events_raw", comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2025-01-01T00:00:00.000+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}") # safeguard to not process data before begin_year
)
SQL
-- create a streaming table and the default flow to ingest streaming events
CREATE OR REFRESH STREAMING LIVE TABLE registration_events_raw AS
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025'; -- safeguard to not process data before begin_year
여기서는 modifiedAfter 자동 로더 옵션을 사용하여 클라우드 스토리지 경로의 모든 데이터를 처리하지 않도록 합니다. 증분 처리는 해당 경계에서 차단됩니다.
팁 (조언)
Kafka, Kinesis 및 Azure Event Hubs와 같은 다른 데이터 원본에는 동일한 동작을 달성하기 위한 동일한 판독기 옵션이 있습니다.
이전 3년의 데이터 채우기
이제 하나 이상의 흐름을 추가하여 이전 데이터를 백필하려고 합니다. 이 예제에서는 다음 단계를 수행합니다.
-
append once흐름을 사용하세요. 첫 번째 백필 이후에 계속 실행하지 않고 일회성 백필을 수행합니다. 코드는 파이프라인에 남아 있으며 파이프라인이 완전히 새로 고쳐지면 백필이 다시 실행됩니다. - 매년 하나씩 세 개의 백필 흐름을 만듭니다(이 경우 데이터는 경로에서 연도별로 분할됨). Python의 경우 흐름 생성을 매개 변수화하지만 SQL에서는 각 흐름에 대해 한 번씩 코드를 세 번 반복합니다.
서버리스 컴퓨팅을 사용하지 않고 자체 프로젝트에서 작업하는 경우 파이프라인에 대한 최대 작업자를 업데이트할 수 있습니다. 최대 작업자를 늘리면 예상 SLA 내에서 현재 스트리밍 데이터를 계속 처리하면서 기록 데이터를 처리할 리소스가 있어야 합니다.
팁 (조언)
향상된 자동 크기 조정(기본값)과 함께 서버리스 컴퓨팅을 사용하는 경우 부하가 증가할 때 클러스터의 크기가 자동으로 증가합니다.
파이썬
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
backfill_years = spark.conf.get("backfill_years") # e.g. "2024,2023,2022"
incremental_load_path = f"{source_root_path}/*/*/*"
# meta programming to create append once flow for a given year (called later)
def setup_backfill_flow(year):
backfill_path = f"{source_root_path}/year={year}/*/*"
@dp.append_flow(
target="registration_events_raw",
once=True,
name=f"flow_registration_events_raw_backfill_{year}",
comment=f"Backfill {year} Raw registration events")
def backfill():
return (
spark
.read
.format("json")
.option("inferSchema", "true")
.load(backfill_path)
)
# create the streaming table
dp.create_streaming_table(name="registration_events_raw", comment="Raw registration events")
# append the original incremental, streaming flow
@dp.append_flow(
target="registration_events_raw",
name="flow_registration_events_raw_incremental",
comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2024-12-31T23:59:59.999+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}")
)
# parallelize one time multi years backfill for faster processing
# split backfill_years into array
for year in backfill_years.split(","):
setup_backfill_flow(year) # call the previously defined append_flow for each year
SQL
-- create the streaming table
CREATE OR REFRESH STREAMING TABLE registration_events_raw;
-- append the original incremental, streaming flow
CREATE FLOW
registration_events_raw_incremental
AS INSERT INTO
registration_events_raw BY NAME
SELECT * FROM STREAM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025';
-- one time backfill 2024
CREATE FLOW
registration_events_raw_backfill_2024
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2024/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2023
CREATE FLOW
registration_events_raw_backfill_2023
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2023/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2022
CREATE FLOW
registration_events_raw_backfill_2022
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2022/*/*",
format => "json",
inferColumnTypes => true
);
이 구현은 몇 가지 중요한 패턴을 강조 표시합니다.
우려 사항 분리
- 증분 처리는 백필 작업과 독립적으로 실행됩니다.
- 각 흐름에는 고유한 구성 및 최적화 설정이 있습니다.
- 증분 작업과 백필 작업은 명확하게 구분됩니다.
제어된 실행
- 이
ONCE옵션을 사용하면 각 백필이 정확히 한 번 실행됩니다. - 백필 흐름은 파이프라인 그래프에 남아 있지만 완료되면 유휴 상태가 됩니다. 전체 새로 고침에서 자동으로 사용할 준비가 된 것입니다.
- 파이프라인 정의에는 백필 작업에 대한 명확한 감사 추적 기록이 있습니다.
처리 최적화
- 더 빠른 처리 또는 처리를 제어하기 위해 큰 백필을 여러 개의 작은 백필로 분할할 수 있습니다.
- 향상된 자동 크기 조정을 사용하면 현재 클러스터 부하에 따라 클러스터 크기가 동적으로 조정됩니다.
스키마 진화
-
schemaEvolutionMode="addNewColumns"핸들을 사용하면 스키마 변경이 원활하게 처리됩니다. - 기록 및 현재 데이터 간에 일관된 스키마 유추가 있습니다.
- 새 데이터의 새 열은 안전하게 처리됩니다.