GDPR(일반 데이터 보호 규정) 및 캘리포니아 소비자 개인 정보 보호법(CCPA)은 회사가 명시적 요청에 따라 고객에 대해 수집된 모든 PII(개인 식별 정보)를 영구적으로 완전히 삭제하도록 요구하는 개인 정보 보호 및 데이터 보안 규정입니다. RTBF("잊혀질 권리" 또는 "데이터 삭제 권한")라고도 하는 삭제 요청은 지정된 기간(예: 한 달 이내)에 실행되어야 합니다.
이 문서에서는 Databricks에 저장된 데이터에 RTBF를 구현하는 방법을 안내합니다. 이 문서에 포함된 예제는 전자 상거래 회사의 데이터 세트를 모델로 하고 원본 테이블에서 데이터를 삭제하고 이러한 변경 내용을 다운스트림 테이블에 전파하는 방법을 보여 줍니다.
"잊혀질 권리"를 구현하기 위한 청사진
다음 다이어그램에서는 "잊혀질 권리"를 구현하는 방법을 보여 줍니다.
GDPR 규정 준수를 구현하는 방법을 보여 주는 
Delta Lake를 사용하여 지점 삭제
Delta Lake는 ACID 트랜잭션을 통해 대규모 데이터 레이크에서 포인트 삭제 속도를 높여 소비자 GDPR 또는 CCPA 요청에 대한 응답으로 PII(개인 식별 정보)를 찾고 제거할 수 있습니다.
Delta Lake는 테이블 기록을 유지하고 지정 시간 쿼리 및 롤백에 사용할 수 있도록 합니다. VACUUM 함수는 델타 테이블에서 더 이상 참조되지 않고 지정된 보존 임계값보다 오래된 데이터 파일을 제거하여 데이터를 영구적으로 삭제합니다. 기본값 및 권장 사항에 대한 자세한 내용은 Delta Lake 테이블 기록 작업을 참조하세요.
삭제 벡터를 사용할 때 데이터가 삭제되었는지 확인
삭제 벡터가 활성화된 테이블의 경우 레코드를 삭제한 후 기본 레코드를 영구적으로 삭제하려면 실행 REORG TABLE ... APPLY (PURGE) 해야 합니다. 여기에는 Delta Lake 테이블, 구체화된 뷰 및 스트리밍 테이블이 포함됩니다. Parquet 데이터 파일에 변경 내용 적용을 참조하세요.
업스트림 원본에서 데이터 삭제
GDPR 및 CCPA는 Kafka, 파일 및 데이터베이스와 같이 Delta Lake 외부의 원본에 있는 데이터를 포함하여 모든 데이터에 적용됩니다. Databricks에서 데이터를 삭제하는 것 외에도 큐 및 클라우드 스토리지와 같은 업스트림 원본에서 데이터를 삭제해야 합니다.
비고
데이터 삭제 워크플로를 구현하기 전에 준수 또는 백업을 위해 작업 영역 데이터를 내보내야 할 수 있습니다. 작업 영역 데이터 내보내기 참조
전체 삭제는 난독 처리보다 더 낫습니다.
데이터를 삭제할지 난독 처리할지 선택해야 합니다. 난독화는 가명화, 데이터 마스킹 등을 사용하여 구현할 수 있습니다. 그러나 가장 안전한 옵션은 완전한 삭제입니다. 실제로 재식별 위험을 제거하려면 개인 식별 정보(PII) 데이터를 완전히 삭제해야 하는 경우가 많기 때문입니다.
브론즈 계층에서 데이터를 삭제한 다음 삭제를 은색 및 금색 계층으로 전파
삭제 요청 테이블을 쿼리하는 예약된 작업에 따라 먼저 브론즈 계층에서 데이터를 삭제하여 GDPR 및 CCPA 규정 준수를 시작하는 것이 좋습니다. 브론즈 계층에서 데이터를 삭제한 후에는 변경 내용을 은색 및 금색 계층으로 전파할 수 있습니다.
기록 파일에서 데이터를 제거하기 위해 테이블을 정기적으로 유지 관리
기본적으로 Delta Lake는 삭제된 레코드를 포함하여 테이블 기록을 30일 동안 유지하고 시간 이동 및 롤백에 사용할 수 있도록 합니다. 그러나 이전 버전의 데이터가 제거되더라도 데이터는 여전히 클라우드 스토리지에 유지됩니다. 따라서 데이터 세트를 정기적으로 유지 관리하여 이전 버전의 데이터를 제거해야 합니다. 권장되는 방법은 Unity 카탈로그 관리 테이블 대한 예측 최적화으로, 스트리밍 테이블과 구체화된 뷰를 지능적으로 유지합니다.
- 예측 최적화를 통해 관리되는 테이블의 경우 Lakeflow Spark 선언적 파이프라인은 사용 패턴에 따라 스트리밍 테이블과 구체화된 뷰를 지능적으로 유지 관리합니다.
- 예측 최적화를 사용하도록 설정하지 않은 테이블의 경우 Lakeflow Spark 선언적 파이프라인은 스트리밍 테이블 및 구체화된 뷰가 업데이트된 후 24시간 이내에 유지 관리 작업을 자동으로 수행합니다.
예측 최적화 또는 Lakeflow Spark 선언적 파이프라인을 사용하지 않는 경우 델타 테이블에서 명령을 실행 VACUUM 하여 이전 버전의 데이터를 영구적으로 제거해야 합니다. 기본적으로 시간 이동 기능은 구성 가능한
브론즈 계층에서 PII 데이터 삭제
Lakehouse의 디자인에 따라 PII와 PII가 아닌 사용자 데이터 간의 연결을 끊을 수 있습니다. 예를 들어 전자 메일과 같은 자연 키 대신 user_id 같은 자연적이지 않은 키를 사용하는 경우 PII 데이터를 삭제하여 PII가 아닌 데이터를 그대로 둘 수 있습니다.
이 문서의 나머지 내용은 모든 브론즈 테이블에서 사용자 레코드를 완전히 삭제하여 RTBF를 처리합니다. 다음 코드와 같이 DELETE 명령을 실행하여 데이터를 삭제할 수 있습니다.
spark.sql("DELETE FROM bronze.users WHERE user_id = 5")
한 번에 많은 수의 레코드를 함께 삭제하는 경우 MERGE 명령을 사용하는 것이 좋습니다. 아래 코드에서는 gdpr_control_table 열을 포함하는 user_id 컨트롤 테이블이 있다고 가정합니다. "잊혀질 권리"를 요청한 모든 사용자를 위해 이 테이블에 레코드를 삽입합니다.
MERGE 명령은 일치하는 행에 대한 조건을 지정합니다. 이 경우에는 target_table기준으로 gdpr_control_table 레코드를 user_id 레코드와 일치시키는 것입니다. 일치 항목(예: user_id 및 target_table모두에 gdpr_control_table)이 있는 경우 target_table 행이 삭제됩니다. 이 MERGE 명령이 성공하면 제어 테이블을 업데이트하여 요청이 처리되었는지 확인합니다.
spark.sql("""
MERGE INTO target
USING (
SELECT user_id
FROM gdpr_control_table
) AS source
ON target.user_id = source.user_id
WHEN MATCHED THEN DELETE
""")
브론즈 레이어의 변경 내용을 실버 및 골드 레이어로 전파하기
브론즈 계층에서 데이터를 삭제한 후에는 변경 내용을 은색 및 금색 계층의 테이블에 전파해야 합니다.
구체화된 뷰: 자동으로 삭제 처리
구체화된 뷰는 원본에서 삭제를 자동으로 처리합니다. 따라서 구체화된 뷰에 원본에서 삭제된 데이터가 포함되지 않도록 특수한 작업을 수행할 필요가 없습니다. 삭제가 완전히 처리되도록 구체화된 뷰를 새로 고치고 유지 관리를 실행해야 합니다.
구체화된 뷰는 전체 재계산보다 저렴하지만 정확성을 희생하지 않는 경우 증분 계산을 사용하기 때문에 항상 올바른 결과를 반환합니다. 즉, 원본에서 데이터를 삭제하면 구체화된 뷰가 완전히 다시 계산될 수 있습니다.
삭제를 자동으로 처리하는 방법을 보여 주는 
스트리밍 테이블: skipChangeCommits를 사용하여 데이터 삭제 및 스트리밍 원본 읽기
스트리밍 테이블은 델타 테이블 원본에서 스트리밍할 때 추가 전용 데이터를 처리합니다. 스트리밍 원본에서 레코드를 업데이트하거나 삭제하는 등의 다른 작업은 지원되지 않으며 스트림을 중단합니다.
비고
보다 강력한 스트리밍 구현을 위해 대신 델타 테이블의 변경 피드에서 스트림하고 처리 코드에서 업데이트 및 삭제를 처리합니다. 옵션 1: 변경 데이터 캡처(CDC) 피드에서 스트리밍을 참조하세요.

델타 테이블의 스트리밍은 새 데이터만 처리하므로 데이터에 대한 변경 내용을 직접 처리해야 합니다. 권장되는 방법은 (1) DML을 사용하여 원본 델타 테이블의 데이터를 삭제하고(2) DML을 사용하여 스트리밍 테이블에서 데이터를 삭제한 다음(3) 사용할 skipChangeCommits스트리밍 읽기를 업데이트하는 것입니다. 이 플래그는 스트리밍 테이블이 업데이트 또는 삭제와 같은 삽입 이외의 항목을 건너뛰어야 했음을 나타냅니다.
skipChangeCommits를 사용하는 GDPR 준수 방법을 보여 주는 
또는 (1) 원본에서 데이터를 삭제한 다음(2) 스트리밍 테이블을 완전히 새로 고칠 수 있습니다. 스트리밍 테이블을 완전히 새로 고치면 테이블의 스트리밍 상태를 지우고 모든 데이터를 다시 처리합니다. 보존 기간을 초과하는 업스트림 데이터 원본(예: 7일 후에 데이터를 노화시키는 Kafka 토픽)은 다시 처리되지 않으므로 데이터가 손실될 수 있습니다. 기록 데이터를 사용할 수 있고 다시 처리하는 데 비용이 많이 들지 않는 시나리오에서만 테이블을 스트리밍하는 데 이 옵션을 사용하는 것이 좋습니다.
스트리밍 테이블에서 전체 새로 고침을 수행하는 GDPR 준수 방법을 보여 주는 
예: 전자상거래 회사의 GDPR 및 CCPA 규정 준수
다음 다이어그램은 GDPR & CCPA 규정 준수를 구현해야 하는 전자 상거래 회사의 medallion 아키텍처를 보여줍니다. 사용자의 데이터가 삭제되더라도 다운스트림 집계에서 해당 활동을 계산할 수 있습니다.
전자상거래 회사의 GDPR 및 CCPA 규정 준수 예를 보여 주는 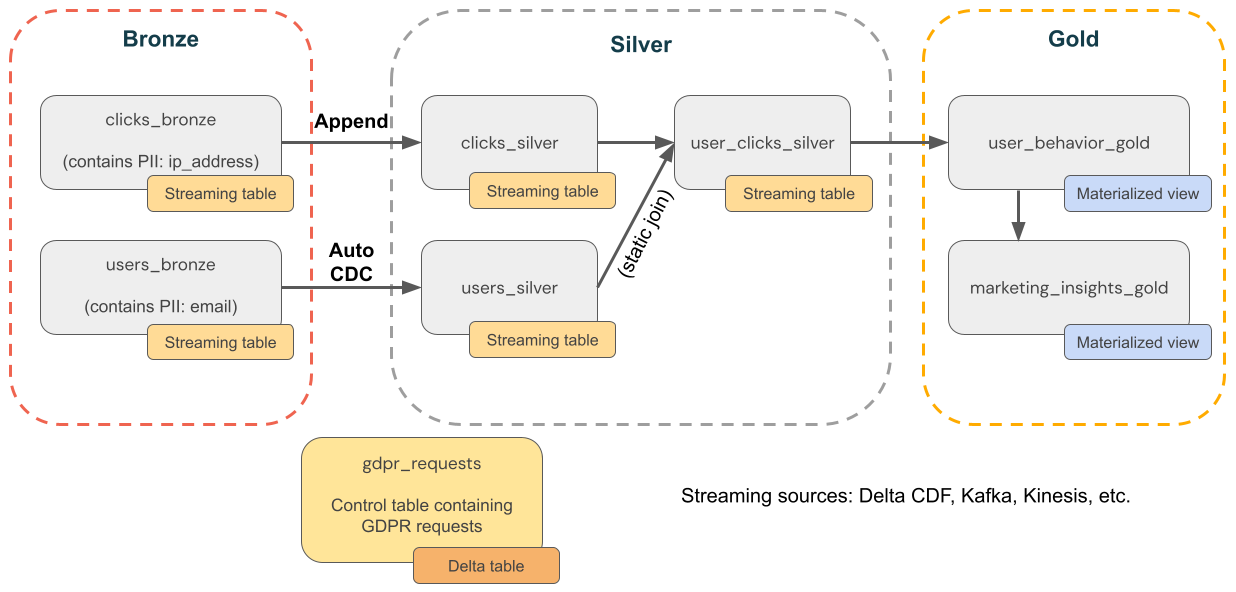
-
원본 테이블
-
source_users- 사용자의 스트리밍 원본 테이블(예: 여기에 생성됨). 프로덕션 환경에서는 일반적으로 Kafka, Kinesis 또는 유사한 스트리밍 플랫폼을 사용합니다. -
source_clicks- 클릭의 스트리밍 원본 테이블(예제의 경우 여기에 생성됨). 프로덕션 환경에서는 일반적으로 Kafka, Kinesis 또는 유사한 스트리밍 플랫폼을 사용합니다.
-
-
컨트롤 테이블
-
gdpr_requests- "잊혀질 권리"가 적용되는 사용자 ID가 포함된 컨트롤 테이블입니다. 사용자가 제거를 요청하면 여기에 추가합니다.
-
-
청동 층
-
users_bronze- 사용자 차원입니다. PII(예: 전자 메일 주소)를 포함합니다. -
clicks_bronze- 이벤트를 클릭합니다. PII(예: IP 주소)를 포함합니다.
-
-
실버 계층
-
clicks_silver- 정리되고 표준화된 클릭 데이터입니다. -
users_silver- 정리되고 표준화된 사용자 데이터입니다. -
user_clicks_silver-clicks_silver(스트리밍)과users_silver의 스냅샷을 조인합니다.
-
-
골드 레이어
-
user_behavior_gold- 집계된 사용자 동작 메트릭입니다. -
marketing_insights_gold- 시장 인사이트에 대한 사용자 세그먼트입니다.
-
1단계: 샘플 데이터로 테이블 채우기
다음 코드는 이 예제에 대해 이러한 두 테이블을 만들고 샘플 데이터로 채웁니다.
-
source_users사용자에 대한 차원 데이터를 포함합니다. 이 테이블에는email이라는 PII 열이 포함되어 있습니다. -
source_clicks사용자가 수행한 활동에 대한 이벤트 데이터를 포함합니다. 여기에는ip_address이라는 PII 열이 포함되어 있습니다.
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, MapType, DateType
catalog = "users"
schema = "name"
# Create table containing sample users
users_schema = StructType([
StructField('user_id', IntegerType(), False),
StructField('username', StringType(), True),
StructField('email', StringType(), True),
StructField('registration_date', StringType(), True),
StructField('user_preferences', MapType(StringType(), StringType()), True)
])
users_data = [
(1, 'alice', 'alice@example.com', '2021-01-01', {'theme': 'dark', 'language': 'en'}),
(2, 'bob', 'bob@example.com', '2021-02-15', {'theme': 'light', 'language': 'fr'}),
(3, 'charlie', 'charlie@example.com', '2021-03-10', {'theme': 'dark', 'language': 'es'}),
(4, 'david', 'david@example.com', '2021-04-20', {'theme': 'light', 'language': 'de'}),
(5, 'eve', 'eve@example.com', '2021-05-25', {'theme': 'dark', 'language': 'it'})
]
users_df = spark.createDataFrame(users_data, schema=users_schema)
users_df.write.mode("overwrite").saveAsTable(f"{catalog}.{schema}.source_users")
# Create table containing clickstream (i.e. user activities)
from pyspark.sql.types import TimestampType
clicks_schema = StructType([
StructField('click_id', IntegerType(), False),
StructField('user_id', IntegerType(), True),
StructField('url_clicked', StringType(), True),
StructField('click_timestamp', StringType(), True),
StructField('device_type', StringType(), True),
StructField('ip_address', StringType(), True)
])
clicks_data = [
(1001, 1, 'https://example.com/home', '2021-06-01T12:00:00', 'mobile', '192.168.1.1'),
(1002, 1, 'https://example.com/about', '2021-06-01T12:05:00', 'desktop', '192.168.1.1'),
(1003, 2, 'https://example.com/contact', '2021-06-02T14:00:00', 'tablet', '192.168.1.2'),
(1004, 3, 'https://example.com/products', '2021-06-03T16:30:00', 'mobile', '192.168.1.3'),
(1005, 4, 'https://example.com/services', '2021-06-04T10:15:00', 'desktop', '192.168.1.4'),
(1006, 5, 'https://example.com/blog', '2021-06-05T09:45:00', 'tablet', '192.168.1.5')
]
clicks_df = spark.createDataFrame(clicks_data, schema=clicks_schema)
clicks_df.write.format("delta").mode("overwrite").saveAsTable(f"{catalog}.{schema}.source_clicks")
2단계: PII 데이터를 처리하는 파이프라인 만들기
다음 코드는 위에 표시된 medallion 아키텍처의 브론즈, 실버 및 골드 레이어를 만듭니다.
from pyspark import pipelines as dp
from pyspark.sql.functions import col, concat_ws, count, countDistinct, avg, when, expr
catalog = "users"
schema = "name"
# ----------------------------
# Bronze Layer - Raw Data Ingestion
# ----------------------------
@dp.table(
name=f"{catalog}.{schema}.users_bronze",
comment='Raw users data loaded from source'
)
def users_bronze():
return (
spark.readStream.table(f"{catalog}.{schema}.source_users")
)
@dp.table(
name=f"{catalog}.{schema}.clicks_bronze",
comment='Raw clicks data loaded from source'
)
def clicks_bronze():
return (
spark.readStream.table(f"{catalog}.{schema}.source_clicks")
)
# ----------------------------
# Silver Layer - Data Cleaning and Enrichment
# ----------------------------
@dp.create_streaming_table(
name=f"{catalog}.{schema}.users_silver",
comment='Cleaned and standardized users data'
)
@dp.view
@dp.expect_or_drop('valid_email', "email IS NOT NULL")
def users_bronze_view():
return (
spark.readStream
.table(f"{catalog}.{schema}.users_bronze")
.withColumn('registration_date', col('registration_date').cast('timestamp'))
.dropDuplicates(['user_id', 'registration_date'])
.select('user_id', 'username', 'email', 'registration_date', 'user_preferences')
)
@dp.create_auto_cdc_flow(
target=f"{catalog}.{schema}.users_silver",
source="users_bronze_view",
keys=["user_id"],
sequence_by="registration_date",
)
@dp.table(
name=f"{catalog}.{schema}.clicks_silver",
comment='Cleaned and standardized clicks data'
)
@dp.expect_or_drop('valid_click_timestamp', "click_timestamp IS NOT NULL")
def clicks_silver():
return (
spark.readStream
.table(f"{catalog}.{schema}.clicks_bronze")
.withColumn('click_timestamp', col('click_timestamp').cast('timestamp'))
.withWatermark('click_timestamp', '10 minutes')
.dropDuplicates(['click_id'])
.select('click_id', 'user_id', 'url_clicked', 'click_timestamp', 'device_type', 'ip_address')
)
@dp.table(
name=f"{catalog}.{schema}.user_clicks_silver",
comment='Joined users and clicks data on user_id'
)
def user_clicks_silver():
# Read users_silver as a static DataFrame - each refresh
# will use a snapshot of the users_silver table.
users = spark.read.table(f"{catalog}.{schema}.users_silver")
# Read clicks_silver as a streaming DataFrame.
clicks = spark.readStream \
.table('clicks_silver')
# Perform the join - join of a static dataset with a
# streaming dataset creates a streaming table.
joined_df = clicks.join(users, on='user_id', how='inner')
return joined_df
# ----------------------------
# Gold Layer - Aggregated and Business-Level Data
# ----------------------------
@dp.materialized_view(
name=f"{catalog}.{schema}.user_behavior_gold",
comment='Aggregated user behavior metrics'
)
def user_behavior_gold():
df = spark.read.table(f"{catalog}.{schema}.user_clicks_silver")
return (
df.groupBy('user_id')
.agg(
count('click_id').alias('total_clicks'),
countDistinct('url_clicked').alias('unique_urls')
)
)
@dp.materialized_view(
name=f"{catalog}.{schema}.marketing_insights_gold",
comment='User segments for marketing insights'
)
def marketing_insights_gold():
df = spark.read.table(f"{catalog}.{schema}.user_behavior_gold")
return (
df.withColumn(
'engagement_segment',
when(col('total_clicks') >= 100, 'High Engagement')
.when((col('total_clicks') >= 50) & (col('total_clicks') < 100), 'Medium Engagement')
.otherwise('Low Engagement')
)
)
3단계: 원본 테이블에서 데이터 삭제
이 단계에서는 PII가 있는 모든 테이블에서 데이터를 삭제합니다. 다음 함수는 PII가 있는 테이블에서 사용자의 PII 인스턴스를 모두 제거합니다.
catalog = "users"
schema = "name"
def apply_gdpr_delete(user_id):
tables_with_pii = ["clicks_bronze", "users_bronze", "clicks_silver", "users_silver", "user_clicks_silver"]
for table in tables_with_pii:
print(f"Deleting user_id {user_id} from table {table}")
spark.sql(f"""
DELETE FROM {catalog}.{schema}.{table}
WHERE user_id = {user_id}
""")
4단계: 영향을 받는 스트리밍 테이블의 정의에 skipChangeCommits 추가
이 단계에서는 추가하지 않는 행을 건너뛰도록 Lakeflow Spark 선언적 파이프라인에 지시해야 합니다. skipChangeCommits 옵션을 다음 메서드에 추가합니다. 구체화된 뷰의 정의는 업데이트 및 삭제를 자동으로 처리하므로 업데이트할 필요가 없습니다.
users_bronzeusers_silverclicks_bronzeclicks_silveruser_clicks_silver
다음 코드는 users_bronze 메서드를 업데이트하는 방법을 보여줍니다.
def users_bronze():
return (
spark.readStream.option('skipChangeCommits', 'true').table(f"{catalog}.{schema}.source_users")
)
파이프라인을 다시 실행하면 성공적으로 업데이트됩니다.