검색 솔루션에서 복잡한 패턴 또는 특수 문자가 있는 문자열은 기본 분석기가 패턴의 의미 있는 부분을 제거하거나 잘못 해석하기 때문에 작업하기가 어려울 수 있습니다. 이로 인해 사용자가 예상한 정보를 찾을 수 없는 검색 환경이 저하됩니다. 전화 번호는 분석하기 어려운 문자열의 전형적인 예입니다. 다양한 형식으로 제공되며 기본 분석기에서 무시하는 특수 문자를 포함합니다.
전화 번호를 제목으로 사용하는 이 자습서에서는 Search Service REST API 를 사용하여 사용자 지정 분석기를 사용하여 패턴이 지정된 데이터 문제를 해결합니다. 이 방법은 전화 번호의 경우와 같이 사용하거나 URL, 전자 메일, 우편 번호 및 날짜와 같은 특성(특수 문자로 패턴화됨)을 가진 필드에 맞게 조정할 수 있습니다.
이 자습서에서는 다음을 수행합니다.
- 문제 이해
- 전화번호 처리를 위한 초기 사용자 지정 분석기 개발
- 사용자 지정 분석기 테스트
- 사용자 지정 분석기 디자인을 반복하여 결과 개선
필수 구성 요소
활성 구독이 있는 Azure 계정. 무료로 계정을 만듭니다.
REST 클라이언트 확장이 있는 Visual Studio Code입니다.
파일 다운로드
이 자습서의 소스 코드는 Azure-Samples/azure-search-rest-samples GitHub 리포지토리의 custom-analyzer.rest 파일에 있습니다.
관리 키 및 URL 복사
이 자습서의 REST 호출에는 검색 서비스 엔드포인트 및 관리자 API 키가 필요합니다. Azure Portal에서 이러한 값을 가져올 수 있습니다.
Azure Portal에 로그인하고 검색 서비스를 선택합니다.
왼쪽 창에서 개요 를 선택하고 엔드포인트를 복사합니다. 다음 형식이어야 합니다.
https://my-service.search.windows.net왼쪽 창에서 설정>키를 선택하고 서비스에 대한 모든 권한을 위해 관리 키를 복사합니다. 교체 가능한 두 개의 관리자 키가 있으며, 하나를 롤오버해야 하는 경우 비즈니스 연속성을 위해 다른 하나가 제공됩니다. 요청에서 키를 사용하여 개체를 추가, 수정 또는 삭제할 수 있습니다.

초기 인덱스 만들기
Visual Studio Code에서 새 텍스트 파일을 엽니다.
이전 섹션에서 수집한 검색 엔드포인트 및 API 키로 변수를 설정합니다.
@baseUrl = PUT-YOUR-SEARCH-SERVICE-URL-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE파일을
.rest파일 확장자를 사용하여 저장합니다.다음 예제를 붙여넣어
phone-numbers-index이라고 하는 작은 인덱스를 만들고, 두 개의 필드id과phone_number를 포함합니다.### Create a new index POST {{baseUrl}}/indexes?api-version=2025-09-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false } ] }아직 분석기를 정의하지 않았으므로
standard.lucene분석기가 기본적으로 사용됩니다.요청 보내기를 선택합니다. 응답이
HTTP/1.1 201 Created있어야 하며, 응답 본문에는 인덱스 스키마의 JSON 표현이 포함되어야 합니다.다양한 전화 번호 형식이 포함된 문서를 사용하여 인덱스에 데이터를 로드합니다. 이것이 테스트 데이터입니다.
### Load documents POST {{baseUrl}}/indexes/phone-numbers-index/docs/index?api-version=2025-09-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "value": [ { "@search.action": "upload", "id": "1", "phone_number": "425-555-0100" }, { "@search.action": "upload", "id": "2", "phone_number": "(321) 555-0199" }, { "@search.action": "upload", "id": "3", "phone_number": "+1 425-555-0100" }, { "@search.action": "upload", "id": "4", "phone_number": "+1 (321) 555-0199" }, { "@search.action": "upload", "id": "5", "phone_number": "4255550100" }, { "@search.action": "upload", "id": "6", "phone_number": "13215550199" }, { "@search.action": "upload", "id": "7", "phone_number": "425 555 0100" }, { "@search.action": "upload", "id": "8", "phone_number": "321.555.0199" } ] }사용자가 입력할 수 있는 것과 유사한 쿼리를 시도합니다. 예를 들어 사용자는 다양한 형식으로 검색
(425) 555-0100할 수 있으며 결과가 반환될 것으로 예상할 수 있습니다.(425) 555-0100를 검색하여 시작합니다.### Search for a phone number POST {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2025-09-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "search": "(425) 555-0100" }쿼리는 예상 결과 4개 중 3개를 반환하지만 예기치 않은 결과 두 개도 반환합니다.
{ "value": [ { "@search.score": 0.05634898, "phone_number": "+1 425-555-0100" }, { "@search.score": 0.05634898, "phone_number": "425 555 0100" }, { "@search.score": 0.05634898, "phone_number": "425-555-0100" }, { "@search.score": 0.020766128, "phone_number": "(321) 555-0199" }, { "@search.score": 0.020766128, "phone_number": "+1 (321) 555-0199" } ] }서식 없이 다시 시도합니다
4255550100.### Search for a phone number POST {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2025-09-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "search": "4255550100" }이 쿼리는 이전보다 더 나빠져서, 4개의 올바른 매치 중 하나만 반환합니다.
{ "value": [ { "@search.score": 0.6015292, "phone_number": "4255550100" } ] }
이러한 결과는 누구에게나 혼란스럽습니다. 다음 섹션에서는 이러한 결과를 가져오는 이유를 설명합니다.
분석기 작동 방식 검토
이러한 검색 결과를 이해하려면 분석기가 수행하는 작업을 이해해야 합니다. 여기에서 분석 API를 사용하여 기본 분석기를 테스트하여 요구 사항을 더 잘 충족하는 분석기를 디자인하기 위한 기반을 제공할 수 있습니다.
분석기는 쿼리 문자열 및 인덱싱된 문서의 텍스트를 처리하는 전체 텍스트 검색 엔진의 구성 요소입니다. 시나리오에 따라 여러 분석기가 다양한 방법으로 텍스트를 조작합니다. 이 시나리오에서는 전화 번호에 맞게 조정되는 분석기를 빌드해야 합니다.
분석기를 구성하는 세 가지 구성 요소는 다음과 같습니다.
- 문자 필터 - 입력 텍스트에서 개별 문자를 제거하거나 바꿉니다.
- 입력 텍스트를 토큰으로 나눕니다. 이 토큰은 검색 인덱스의 키가 됩니다.
- 토큰 필터 - 토크나이저에서 생성된 토큰을 조작합니다.
다음 다이어그램에서는 이러한 세 구성 요소가 함께 작동하여 문장을 토큰화하는 방법을 보여 줍니다.
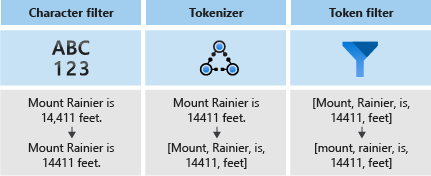
그런 다음, 이러한 토큰은 반전된 인덱스에 저장되어 전체 텍스트를 빠르게 검색할 수 있도록 허용합니다. 반전된 인덱스는 어휘 분석 중에 추출된 모든 고유한 용어를 해당 용어가 발생한 문서에 매핑하여 전체 텍스트 검색을 가능하게 합니다. 다음 다이어그램에서 예제를 볼 수 있습니다.

모든 검색에서 반전된 인덱스에 저장된 용어를 검색하게 됩니다. 사용자가 쿼리를 실행하는 경우 다음과 같이 수행됩니다.
- 쿼리를 구문 분석하고 쿼리 용어를 분석합니다.
- 반전된 인덱스는 일치하는 용어가 있는 문서를 검색합니다.
- 점수 매기기 알고리즘은 검색된 문서의 순위를 지정합니다.
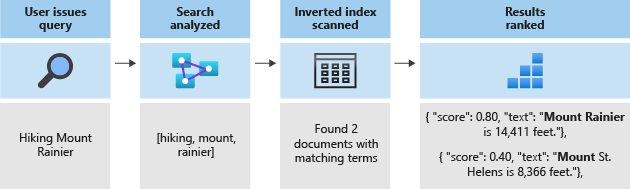
쿼리 용어가 반전된 인덱스의 용어와 일치하지 않으면 결과가 반환되지 않습니다. 쿼리 작동 방식에 대한 자세한 내용은 Azure AI Search에서 전체 텍스트 검색을 참조하세요.
참고
부분 용어 쿼리는 이 규칙의 중요한 예외입니다. 일반 용어 쿼리와 달리 이러한 쿼리(접두사 쿼리, 와일드카드 쿼리 및 정규식 쿼리)는 어휘 분석 프로세스를 무시합니다. 부분 용어는 소문자로 처리한 후에만 인덱스의 용어와 일치시킵니다. 이러한 유형의 쿼리를 지원하도록 분석기가 구성되지 않은 경우 일치하는 용어가 인덱스에 없기 때문에 예기치 않은 결과가 발생하는 경우가 많습니다.
분석 API를 사용하여 분석기 테스트
Azure AI 검색은 분석기를 테스트하여 분석기에서 텍스트를 처리하는 방법을 이해할 수 있도록 하는 분석 API를 제공합니다.
다음 요청을 사용하여 분석 API를 호출합니다.
### Test analyzer
POST {{baseUrl}}/indexes/phone-numbers-index/analyze?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "(425) 555-0100",
"analyzer": "standard.lucene"
}
API는 지정한 분석기를 사용하여 텍스트에서 추출된 토큰을 반환합니다. 표준 Lucene 분석기는 전화 번호를 세 개의 개별 토큰으로 분할합니다.
{
"tokens": [
{
"token": "425",
"startOffset": 1,
"endOffset": 4,
"position": 0
},
{
"token": "555",
"startOffset": 6,
"endOffset": 9,
"position": 1
},
{
"token": "0100",
"startOffset": 10,
"endOffset": 14,
"position": 2
}
]
}
반대로, 문장 부호 없이 형식이 지정된 4255550100 전화 번호는 단일 토큰으로 토큰화됩니다.
{
"text": "4255550100",
"analyzer": "standard.lucene"
}
응답:
{
"tokens": [
{
"token": "4255550100",
"startOffset": 0,
"endOffset": 10,
"position": 0
}
]
}
쿼리 용어와 인덱싱된 문서 모두 분석을 거칩니다. 이전 단계의 검색 결과를 다시 생각해 보면 해당 결과가 반환되는 이유를 확인할 수 있습니다.
첫 번째 쿼리에서 예기치 않은 전화 번호가 반환되는 이유는 해당 토큰 555중 하나가 검색한 용어 중 하나와 일치하기 때문입니다. 두 번째 쿼리에서는 토큰이 일치하는 4255550100유일한 레코드이기 때문에 하나의 숫자만 반환됩니다.
사용자 지정 분석기 빌드
표시되는 결과를 이해했으므로 이제 사용자 지정 분석기를 빌드하여 토큰화 논리를 개선합니다.
목표는 쿼리 또는 인덱싱된 문자열의 형식에 관계없이 전화 번호를 직관적으로 검색하는 것입니다. 이 결과를 얻으려면 문자 필터, 토큰 변환기 및 토큰 필터를 지정합니다.
문자 필터
문자 필터는 토케나이저에 공급되기 전에 텍스트를 처리합니다. 문자 필터의 일반적인 용도는 HTML 요소를 필터링하고 특수 문자를 대체하는 것입니다.
전화 번호의 경우 모든 전화 번호 형식에 동일한 특수 문자와 공백이 포함되지 않으므로 공백과 특수 문자를 제거하려고 합니다.
"charFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.MappingCharFilter",
"name": "phone_char_mapping",
"mappings": [
"-=>",
"(=>",
")=>",
"+=>",
".=>",
"\\u0020=>"
]
}
]
필터는 입력에서 -()+. 및 공백을 제거합니다.
| 입력 | 출력 |
|---|---|
(321) 555-0199 |
3215550199 |
321.555.0199 |
3215550199 |
토크나이저
토크나이저는 텍스트를 토큰으로 분할하고 문장 부호와 같은 일부 문자를 삭제합니다. 대부분의 경우 토큰화의 목표는 문장을 개별 단어로 분할하는 것입니다.
이 시나리오에서는 키워드 tokenizer keyword_v2를 사용하여 전화 번호를 단일 용어로 캡처합니다. 대체 방법 섹션에서 설명한 대로 이 문제를 해결하는 유일한 방법은 아닙니다.
키워드 토큰라이저는 항상 단일 용어로 지정된 것과 동일한 텍스트를 출력합니다.
| 입력 | 출력 |
|---|---|
The dog swims. |
[The dog swims.] |
3215550199 |
[3215550199] |
토큰 필터
토큰 필터는 토큰 변환기에서 생성된 토큰을 수정하거나 필터링합니다. 토큰 필터의 일반적인 용도 중 하나는 소문자 토큰 필터를 사용하여 모든 문자를 소문자로 처리하는 것입니다. 또 다른 일반적인 용도는 중지 단어(예: the, and또는 is.)를 필터링하는 것입니다.
이 시나리오에서는 이러한 필터 중 하나를 사용할 필요는 없지만 nGram 토큰 필터를 사용하여 전화 번호의 부분 검색을 허용합니다.
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2",
"name": "custom_ngram_filter",
"minGram": 3,
"maxGram": 20
}
]
NGramTokenFilterV2
nGram_v2 토큰 필터는 minGram 및 maxGram 매개 변수를 기반으로 하여 토큰을 지정된 크기의 n-그램으로 분할합니다.
전화 분석기의 minGram는 사용자가 검색할 것으로 예상되는 가장 짧은 부분 문자열이기 때문에 3로 설정됩니다.
내선 번호도 포함하여 모든 전화 번호가 단일 n-그램에 맞도록 maxGram이 20으로 설정됩니다.
n-그램의 부작용은 일부 가양성이 반환된다는 것입니다. n-gram 토큰 필터를 포함하지 않는 검색을 위해 별도의 분석기를 빌드하여 이후 단계에서 이 문제를 해결합니다.
| 입력 | 출력 |
|---|---|
[12345] |
[123, 1234, 12345, 234, 2345, 345] |
[3215550199] |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
분석기
문자 필터, 토큰 변환기 및 토큰 필터가 준비되면 분석기를 정의할 준비가 되었습니다.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer",
"tokenizer": "keyword_v2",
"tokenFilters": [
"custom_ngram_filter"
],
"charFilters": [
"phone_char_mapping"
]
}
]
분석 API에서 다음 입력이 제공되면 사용자 지정 분석기 출력은 다음과 같습니다.
| 입력 | 출력 |
|---|---|
12345 |
[123, 1234, 12345, 234, 2345, 345] |
(321) 555-0199 |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
출력 열의 모든 토큰이 인덱스에 있습니다. 쿼리에 해당 용어가 포함된 경우 전화 번호가 반환됩니다.
새 분석기를 사용하여 다시 빌드
현재 인덱스 삭제
### Delete the index DELETE {{baseUrl}}/indexes/phone-numbers-index?api-version=2025-09-01 HTTP/1.1 api-key: {{apiKey}}새 분석기를 사용하여 인덱스를 다시 만듭니다. 이 인덱스 스키마는 전화 번호 필드에 사용자 지정 분석기 정의 및 사용자 지정 분석기 할당을 추가합니다.
### Create a new index POST {{baseUrl}}/indexes?api-version=2025-09-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index-2", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false, "analyzer": "phone_analyzer" } ], "analyzers": [ { "@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer", "name": "phone_analyzer", "tokenizer": "keyword_v2", "tokenFilters": [ "custom_ngram_filter" ], "charFilters": [ "phone_char_mapping" ] } ], "charFilters": [ { "@odata.type": "#Microsoft.Azure.Search.MappingCharFilter", "name": "phone_char_mapping", "mappings": [ "-=>", "(=>", ")=>", "+=>", ".=>", "\\u0020=>" ] } ], "tokenFilters": [ { "@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2", "name": "custom_ngram_filter", "minGram": 3, "maxGram": 20 } ] }
사용자 지정 분석기 테스트
인덱스 다시 생성 후 다음 요청을 사용하여 분석기를 테스트합니다.
### Test custom analyzer
POST {{baseUrl}}/indexes/phone-numbers-index-2/analyze?api-version=2025-09-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "+1 (321) 555-0199",
"analyzer": "phone_analyzer"
}
이제 전화 번호로 인한 토큰 컬렉션이 표시됩니다.
{
"tokens": [
{
"token": "132",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "1321",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "13215",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
...
...
...
]
}
가양성을 처리하도록 사용자 지정 분석기 수정
사용자 지정 분석기를 사용하여 인덱스에 대한 샘플 쿼리를 수행한 후 회수가 개선되었으며 일치하는 모든 전화 번호가 반환됩니다. 그러나 n-그램 토큰 필터로 인해 일부 가양성이 반환되기도 합니다. 이는 n-그램 토큰 필터의 일반적인 부작용입니다.
오탐지를 방지하기 위해 쿼리를 위한 별도의 분석기를 생성합니다. 이 분석기는 을 생략한다는 점을 제외하고 이전 분석기와 custom_ngram_filter동일합니다.
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_search",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [],
"charFilters": [
"phone_char_mapping"
]
}
인덱스 정의에서 indexAnalyzer와 searchAnalyzer 둘 다 지정합니다.
{
"name": "phone_number",
"type": "Edm.String",
"sortable": false,
"searchable": true,
"filterable": false,
"facetable": false,
"indexAnalyzer": "phone_analyzer",
"searchAnalyzer": "phone_analyzer_search"
}
이렇게 변경하면 모든 설정이 완료됩니다. 다음 단계는 다음과 같습니다.
인덱스를 삭제합니다.
새 사용자 지정 분석기(
phone_analyzer-search)를 추가한 후 인덱스 다시 만들고 해당 분석기를 필드의phone-number속성에searchAnalyzer할당합니다.데이터를 다시 로드합니다.
쿼리를 다시 테스트하여 검색이 예상대로 작동하는지 확인합니다. 샘플 파일을 사용하는 경우 이 단계에서는
phone-number-index-3이라는 세 번째 인덱스가 만들어집니다.
대체 방법
이전 섹션에서 설명한 분석기는 검색 유연성을 최대화하도록 설계되었습니다. 그러나 잠재적으로 중요하지 않은 여러 용어를 인덱스에 저장하는 데 비용이 들어갑니다.
다음 예제에서는 토큰화에 더 효율적이지만 단점이 있는 대체 분석기를 보여 줍니다.
14255550100이 입력된 경우 분석기는 전화번호를 논리적으로 청크할 수 없습니다. 예를 들어 국가 코드 1과 지역 코드 425를 분리할 수 없습니다. 이러한 불일치로 인해 사용자가 검색에 국가 코드를 포함하지 않는 경우 전화 번호가 반환되지 않습니다.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_shingles",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [
"custom_shingle_filter"
]
}
],
"tokenizers": [
{
"@odata.type": "#Microsoft.Azure.Search.StandardTokenizerV2",
"name": "custom_tokenizer_phone",
"maxTokenLength": 4
}
],
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.ShingleTokenFilter",
"name": "custom_shingle_filter",
"minShingleSize": 2,
"maxShingleSize": 6,
"tokenSeparator": ""
}
]
다음 예제에서 전화 번호는 일반적으로 사용자가 검색할 것으로 예상되는 청크로 분할됩니다.
| 입력 | 출력 |
|---|---|
(321) 555-0199 |
[321, 555, 0199, 321555, 5550199, 3215550199] |
요구 사항에 따라 이는 문제에 대한 더 효율적인 방법일 수 있습니다.
핵심 내용
이 자습서에서는 사용자 지정 분석기를 빌드하고 테스트하는 프로세스를 설명했습니다. 인덱스를 만들고, 데이터를 인덱싱한 다음, 인덱스를 쿼리하여 반환되는 검색 결과를 확인했습니다. 여기서는 분석 API를 사용하여 어휘 분석 프로세스가 실제로 작동하는지 확인했습니다.
이 자습서에 정의된 분석기는 전화번호를 쉽게 검색할 수 있는 솔루션을 제공하지만, 이와 동일한 프로세스를 사용하여 유사한 특성을 공유하는 모든 시나리오에 대한 사용자 지정 분석기를 빌드할 수 있습니다.
리소스 정리
사용자 고유의 구독에서 작업하는 경우 프로젝트를 종료할 때 더 이상 필요하지 않은 리소스를 제거하는 것이 좋습니다. 계속 실행되는 리소스에는 요금이 부과될 수 있습니다. 리소스를 개별적으로 삭제하거나 리소스 그룹을 삭제하여 전체 리소스 세트를 삭제할 수 있습니다.
왼쪽 탐색 창의 모든 리소스 또는 리소스 그룹 링크를 사용하여 Azure Portal에서 리소스를 찾고 관리할 수 있습니다.
다음 단계
이제 사용자 지정 분석기를 만드는 방법을 알아보고 다양한 검색 환경을 빌드하는 데 사용할 수 있는 다양한 필터, 토케나이저 및 분석기를 모두 살펴보세요.