ML.NET 미리 학습된 ONNX 모델을 사용하여 이미지에서 개체를 검색하는 방법을 알아봅니다.
개체 검색 모델을 처음부터 학습하려면 수백만 개의 매개 변수, 많은 양의 레이블이 지정된 학습 데이터 및 방대한 양의 컴퓨팅 리소스(수백 시간)를 설정해야 합니다. 미리 학습된 모델을 사용하면 학습 프로세스를 바로 가기로 지정할 수 있습니다.
이 튜토리얼에서는 다음을 배우게 됩니다:
- 문제 이해
- ONNX란 무엇이며 ML.NET 어떻게 작동하는지 알아봅니다.
- 모델 이해
- 미리 학습된 모델 다시 사용
- 로드된 모델을 사용하여 개체 검색
필수 조건
- Visual Studio 2022 이상.
- Microsoft.ML NuGet 패키지
- Microsoft.ML.ImageAnalytics NuGet 패키지
- Microsoft.ML.OnnxTransformer NuGet 패키지
- Tiny YOLOv2 미리 학습된 모델
- Netron (선택 사항)
ONNX 개체 검색 샘플 개요
이 샘플에서는 미리 학습된 딥 러닝 ONNX 모델을 사용하여 이미지 내의 개체를 검색하는 .NET Core 콘솔 애플리케이션을 만듭니다. 이 샘플의 코드는 GitHub의 dotnet/machinelearning-samples 리포지토리 에서 찾을 수 있습니다.
객체 탐지란?
개체 감지는 컴퓨터 비전 문제입니다. 이미지 분류와 밀접한 관련이 있지만 개체 검색은 보다 세분화된 크기로 이미지 분류를 수행합니다. 객체 탐지는 이미지 내에서 객체를 찾고 분류합니다. 개체 검색 모델은 일반적으로 딥 러닝 및 신경망을 사용하여 학습됩니다. 자세한 내용은 딥 러닝과 기계 학습 을 참조하세요.
이미지에 서로 다른 형식의 여러 개체가 포함된 경우 개체 감지를 사용합니다.

개체 검색에 대한 몇 가지 사용 사례는 다음과 같습니다.
- 자율 주행 자동차
- 로봇공학
- 얼굴 감지
- 작업 공간 안전
- 객체 수 카운팅
- 움직임 인식
딥 러닝 모델 선택
딥 러닝은 기계 학습의 하위 집합입니다. 딥 러닝 모델을 학습하려면 대량의 데이터가 필요합니다. 데이터의 패턴은 일련의 계층으로 표시됩니다. 데이터의 관계는 가중치가 포함된 계층 간의 연결로 인코딩됩니다. 무게가 높을수록 관계가 강합니다. 전체적으로 이 일련의 계층과 연결을 인공 신경망이라고 합니다. 네트워크에서 계층이 많을수록 "더 깊게" 심층 신경망이 됩니다.
다양한 유형의 신경망이 있으며, 가장 일반적인 것은 MLP(다계층 퍼셉트론), CNN(나선형 신경망) 및 RNN(되풀이 신경망)입니다. 가장 기본적인 것은 입력 집합을 출력 집합에 매핑하는 MLP입니다. 이 신경망은 데이터에 공간 또는 시간 구성 요소가 없는 경우에 적합합니다. CNN은 나선형 계층을 사용하여 데이터에 포함된 공간 정보를 처리합니다. CNN의 좋은 사용 사례는 이미지의 영역에서 기능의 존재를 감지하기 위한 이미지 처리입니다(예: 이미지 중앙에 코가 있습니까?). 마지막으로, RNN을 사용하면 상태 또는 메모리의 지속성을 입력으로 사용할 수 있습니다. RNN은 이벤트의 순차적 순서 및 컨텍스트가 중요한 시계열 분석에 사용됩니다.
모델 이해
개체 감지는 이미지 처리 작업입니다. 따라서 이 문제를 해결하기 위해 학습된 대부분의 딥 러닝 모델은 CNN입니다. 이 자습서에서 사용된 모델은 Redmon과 Farhadi의 "YOLO9000: 더 나은, 더 빠름, 더 강해"라는 논문에 설명된 YOLOv2 모델의 더 컴팩트한 버전인 Tiny YOLOv2 모델입니다. Tiny YOLOv2는 Pascal VOC 데이터 세트에서 학습되며 20가지 개체 클래스를 예측할 수 있는 15개의 계층으로 구성됩니다. Tiny YOLOv2는 원래 YOLOv2 모델의 압축된 버전이므로 속도와 정확도 간에 절충이 이루어집니다. 모델을 구성하는 다양한 계층은 Netron과 같은 도구를 사용하여 시각화할 수 있습니다. 모델을 검사하면 신경망을 구성하는 모든 계층 간의 연결 매핑이 생성됩니다. 여기서 각 계층에는 각 입력/출력의 차원과 함께 계층 이름이 포함됩니다. 모델의 입력 및 출력을 설명하는 데 사용되는 데이터 구조를 텐서라고 합니다. 텐서를 N차원에 데이터를 저장하는 컨테이너로 간주할 수 있습니다. Tiny YOLOv2의 경우, 입력 계층의 이름은 image이며 3 x 416 x 416 차원의 텐서를 예상합니다. 출력 계층 grid 의 이름은 차원의 출력 텐서를 생성합니다 125 x 13 x 13.
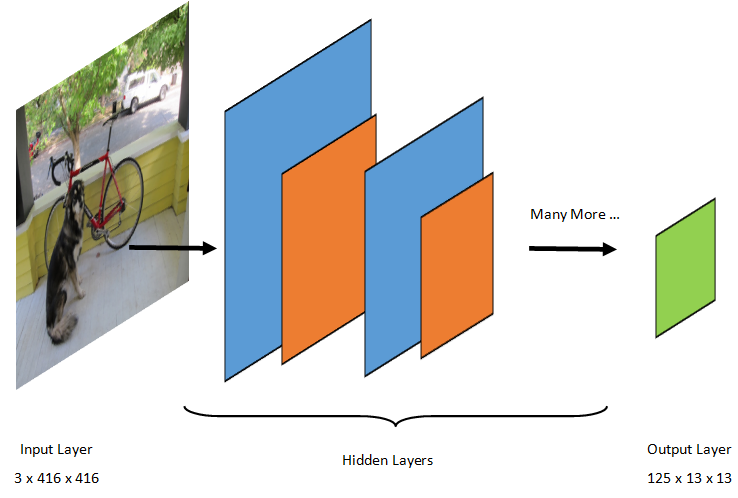
YOLO 모델은 이미지를 3(RGB) x 416px x 416px사용합니다. 모델은 이 입력을 가져와서 다른 계층을 통해 전달하여 출력을 생성합니다. 출력은 입력 이미지를 표로 13 x 13 나누고 표의 125 각 셀은 값으로 구성됩니다.
ONNX 모델이란?
ONNX(Open Neural Network Exchange)는 AI 모델의 오픈 소스 형식입니다. ONNX는 프레임워크 간의 상호 운용성을 지원합니다. 즉, PyTorch와 같은 널리 사용되는 기계 학습 프레임워크 중 하나에서 모델을 학습시키고, ONNX 형식으로 변환하고, ML.NET 같은 다른 프레임워크에서 ONNX 모델을 사용할 수 있습니다. 자세한 내용은 ONNX 웹 사이트를 방문하세요.

미리 학습된 Tiny YOLOv2 모델은 계층의 직렬화된 표현과 해당 계층의 학습된 패턴인 ONNX 형식으로 저장됩니다. ML.NET과 ONNX 간의 상호 운용성은 ImageAnalytics 및 OnnxTransformer NuGet 패키지를 통해 달성됩니다. 패키지에는 ImageAnalytics 이미지를 가져와서 예측 또는 학습 파이프라인에 입력으로 사용할 수 있는 숫자 값으로 인코딩하는 일련의 변환이 포함되어 있습니다. 패키지는 OnnxTransformer ONNX 런타임을 활용하여 ONNX 모델을 로드하고 이를 사용하여 제공된 입력을 기반으로 예측을 만듭니다.
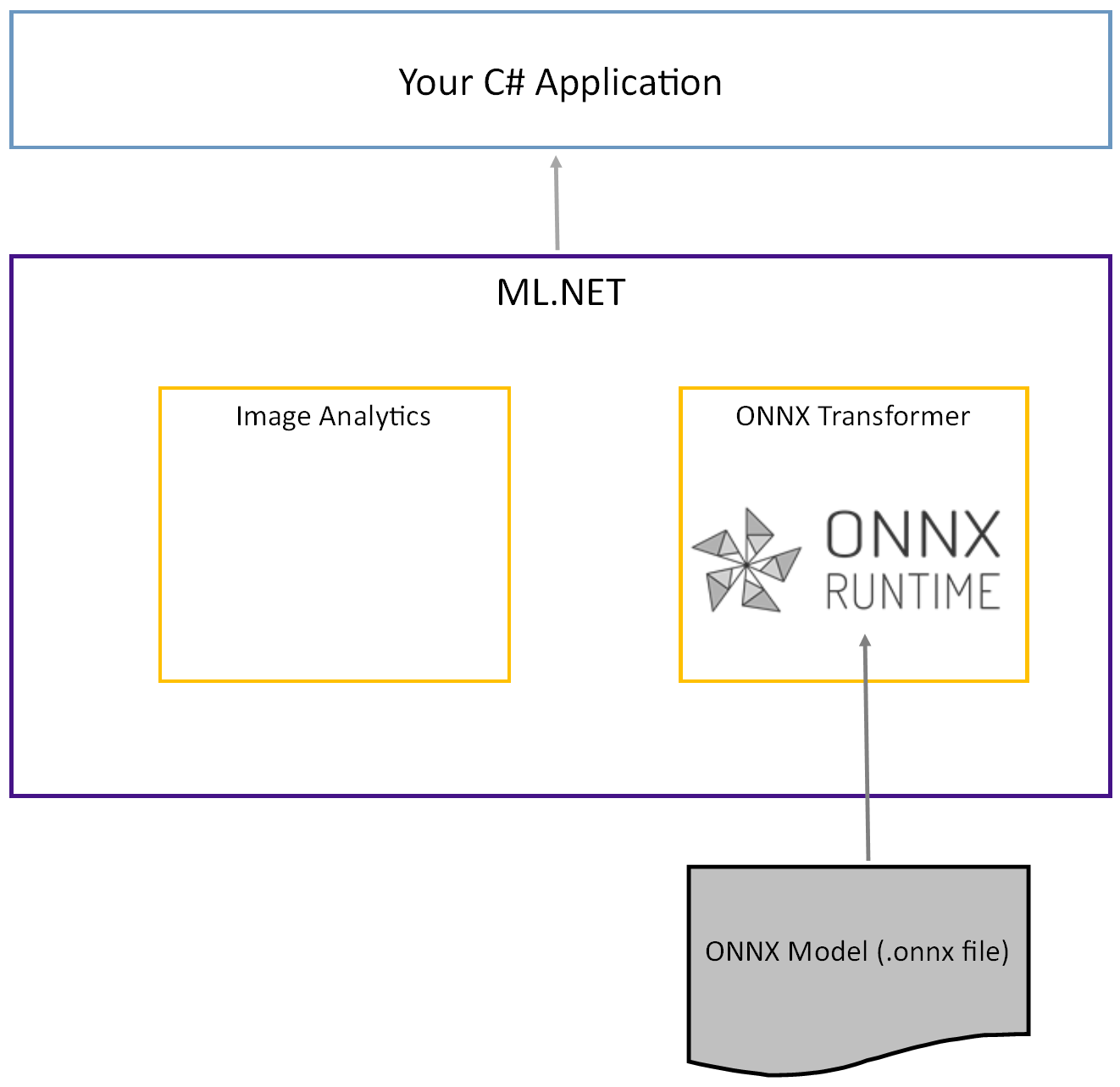
.NET 콘솔 프로젝트 설정
이제 ONNX가 무엇이고 Tiny YOLOv2가 어떻게 작동하는지에 대한 일반적인 이해가 있으므로 애플리케이션을 빌드해야 합니다.
콘솔 애플리케이션 만들기
"ObjectDetection"이라는 C# 콘솔 애플리케이션 을 만듭니다. 다음 단추를 클릭합니다.
사용할 프레임워크로 .NET 8을 선택합니다. 만들기 버튼을 클릭합니다.
Microsoft.ML NuGet 패키지를 설치합니다.
비고
이 샘플에서는 달리 명시되지 않는 한 언급된 안정적인 최신 버전의 NuGet 패키지를 사용합니다.
- 솔루션 탐색기에서 프로젝트를 마우스 오른쪽 단추로 클릭하고 NuGet 패키지 관리를 선택합니다.
- 패키지 원본으로 "nuget.org"을 선택하고 찾아보기 탭을 선택하고 Microsoft.ML 검색합니다.
- 설치 단추를 선택합니다.
- 변경 내용 미리 보기 대화 상자에서 확인단추를 선택한 다음, 나열된 패키지의 사용 조건에 동의하는 경우 라이선스 승인 대화 상자에서 동의 단추를 선택합니다.
- Microsoft.Windows.Compatibility, Microsoft.ML.ImageAnalytics, Microsoft.ML.OnnxTransformer 및 Microsoft.ML.OnnxRuntime에 대해 다음 단계를 반복합니다.
데이터 및 미리 학습된 모델 준비
프로젝트 자산 디렉터리 zip 파일을 다운로드하고 압축을 풉니다.
assets디렉터리를 ObjectDetection 프로젝트 디렉터리에 복사합니다. 이 디렉터리와 해당 하위 디렉터리에는 이 자습서에 필요한 이미지 파일(다음 단계에서 다운로드하여 추가할 Tiny YOLOv2 모델 제외)이 포함됩니다.ONNX 모델 동물원에서 Tiny YOLOv2 모델을 다운로드합니다.
model.onnxObjectDetection 프로젝트assets\Model디렉터리에 파일을 복사하고 이름을 바꿉니다TinyYolo2_model.onnx. 이 디렉터리에는 이 자습서에 필요한 모델이 포함되어 있습니다.솔루션 탐색기에서 자산 디렉터리 및 하위 디렉터리의 각 파일을 마우스 오른쪽 단추로 클릭하고 속성을 선택합니다. 고급 탭에서 출력 디렉터리에 복사 설정을 새 버전인 경우에만 복사로 변경합니다.
클래스 만들기 및 경로 정의
Program.cs 파일을 열고 파일 맨 위에 다음 추가 using 지시문을 추가합니다.
using System.Drawing;
using System.Drawing.Drawing2D;
using ObjectDetection.YoloParser;
using ObjectDetection.DataStructures;
using ObjectDetection;
using Microsoft.ML;
다음으로, 다양한 자산의 경로를 정의합니다.
먼저
GetAbsolutePath메서드를 Program.cs 파일의 맨 아래에 만듭니다.string GetAbsolutePath(string relativePath) { FileInfo _dataRoot = new FileInfo(typeof(Program).Assembly.Location); string assemblyFolderPath = _dataRoot.Directory.FullName; string fullPath = Path.Combine(assemblyFolderPath, relativePath); return fullPath; }그런 다음 지시문 아래에
using자산을 저장할 필드를 만듭니다.var assetsRelativePath = @"../../../assets"; string assetsPath = GetAbsolutePath(assetsRelativePath); var modelFilePath = Path.Combine(assetsPath, "Model", "TinyYolo2_model.onnx"); var imagesFolder = Path.Combine(assetsPath, "images"); var outputFolder = Path.Combine(assetsPath, "images", "output");
프로젝트에 새 디렉터리를 추가하여 입력 데이터 및 예측 클래스를 저장합니다.
솔루션 탐색기에서 프로젝트를 마우스 오른쪽 단추로 클릭한 다음새 폴더>를 선택합니다. 솔루션 탐색기에 새 폴더가 나타나면 이름을 "DataStructures"로 지정합니다.
새로 만든 DataStructures 디렉터리에 입력 데이터 클래스를 만듭니다.
솔루션 탐색기에서 DataStructures 디렉터리를 마우스 오른쪽 단추로 클릭한 다음새 항목>를 선택합니다.
새 항목 추가 대화 상자에서 클래스를 선택하고 이름 필드를 ImageNetData.cs 변경합니다. 그런 후 추가를 선택합니다.
ImageNetData.cs 파일이 코드 편집기에서 열립니다.
using맨 위에 다음 지시문을 추가합니다.using System.Collections.Generic; using System.IO; using System.Linq; using Microsoft.ML.Data;기존 클래스 정의를 제거하고 클래스에 대한
ImageNetData다음 코드를 ImageNetData.cs 파일에 추가합니다.public class ImageNetData { [LoadColumn(0)] public string ImagePath; [LoadColumn(1)] public string Label; public static IEnumerable<ImageNetData> ReadFromFile(string imageFolder) { return Directory .GetFiles(imageFolder) .Where(filePath => Path.GetExtension(filePath) != ".md") .Select(filePath => new ImageNetData { ImagePath = filePath, Label = Path.GetFileName(filePath) }); } }ImageNetData는 입력 이미지 데이터 클래스이며 다음 String 필드가 있습니다.-
ImagePath에는 이미지가 저장되는 경로가 포함됩니다. -
Label에는 파일 이름이 포함됩니다.
ImageNetData또한 지정된 경로에 저장된ReadFromFile여러 이미지 파일을 로드하고 개체 컬렉션imageFolder으로 반환하는 메서드ImageNetData를 포함합니다.-
DataStructures 디렉터리에서 예측 클래스를 만듭니다.
솔루션 탐색기에서 DataStructures 디렉터리를 마우스 오른쪽 단추로 클릭한 다음새 항목>를 선택합니다.
새 항목 추가 대화 상자에서 클래스를 선택하고 이름 필드를 ImageNetPrediction.cs 변경합니다. 그런 후 추가를 선택합니다.
ImageNetPrediction.cs 파일이 코드 편집기에서 열립니다. ImageNetPrediction.cs 맨 위에 다음 지시문을 추가합니다
using.using Microsoft.ML.Data;기존 클래스 정의를 제거하고 클래스에 대한
ImageNetPrediction다음 코드를 ImageNetPrediction.cs 파일에 추가합니다.public class ImageNetPrediction { [ColumnName("grid")] public float[] PredictedLabels; }ImageNetPrediction는 예측 데이터 클래스이며 다음float[]필드가 있습니다.-
PredictedLabels에는 이미지에서 감지된 각 경계 상자에 대한 차원, 객체 점수와 클래스 확률이 포함됩니다.
-
변수 초기화
MLContext 클래스는 모든 ML.NET 작업의 시작점이며 초기화 mlContext 하면 모델 생성 워크플로 개체 간에 공유할 수 있는 새 ML.NET 환경이 만들어집니다. 개념적으로 DBContext Entity Framework와 유사합니다.
다음 줄을 outputFolder 필드 아래에 추가하여 mlContext의 새 인스턴스로 MLContext 변수를 초기화합니다.
MLContext mlContext = new MLContext();
후처리 모델 출력에 대한 파서 만들기
모델은 각 그리드 셀이 13 x 13 있는 그리드로 이미지를 분할합니다 32px x 32px. 각 그리드 셀에는 5개의 잠재적인 객체 경계 상자가 포함되어 있습니다. 경계 상자에는 25개 요소가 있습니다.
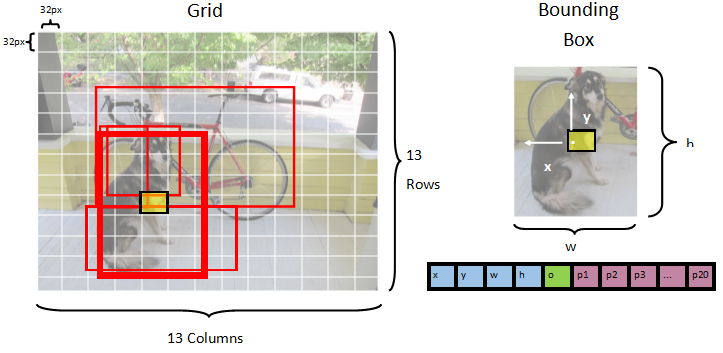
-
x경계 상자 가운데의 x 좌표는 연결된 그리드 셀에 대해 상대적입니다. -
y연결된 그리드 셀을 기준으로 경계 상자 가운데의 y 위치입니다. -
w경계 상자의 너비입니다. -
h경계 상자의 높이입니다. -
o경계 상자 내 개체 존재에 대한 신뢰도 값(개체성 점수라고도 함)입니다. -
p1-p20모델에서 예측하는 20개 클래스 각각에 대한 클래스 확률입니다.
총 5개의 경계 상자를 설명하는 25개 요소는 각 그리드 셀에 포함된 125개의 요소를 구성합니다.
미리 학습된 ONNX 모델이 생성한 출력은 길이 21125의 부동소수점 배열로, 차원 125 x 13 x 13의 텐서 요소를 나타냅니다. 모델에서 생성된 예측을 텐서로 변환하려면 일부 후처리 작업이 필요합니다. 이렇게 하려면 출력을 구문 분석하는 데 도움이 되는 클래스 집합을 만듭니다.
프로젝트에 새 디렉터리를 추가하여 파서 클래스 집합을 구성합니다.
- 솔루션 탐색기에서 프로젝트를 마우스 오른쪽 단추로 클릭한 다음새 폴더>를 선택합니다. 솔루션 탐색기에 새 폴더가 나타나면 이름을 "YoloParser"로 지정합니다.
경계 상자 및 크기 만들기
모델에 의해 출력된 데이터에는 이미지 내의 객체 경계 상자의 좌표와 크기가 포함됩니다. 차원에 대한 기본 클래스를 만듭니다.
솔루션 탐색기에서 YoloParser 디렉터리를 마우스 오른쪽 단추로 클릭한 다음새 항목>를 선택합니다.
새 항목 추가 대화 상자에서 클래스를 선택하고 이름 필드를 DimensionsBase.cs 변경합니다. 그런 후 추가를 선택합니다.
DimensionsBase.cs 파일이 코드 편집기에서 열립니다. 모든
using지시문 및 기존 클래스 정의를 제거합니다.클래스에 대한
DimensionsBase다음 코드를 DimensionsBase.cs 파일에 추가합니다.public class DimensionsBase { public float X { get; set; } public float Y { get; set; } public float Height { get; set; } public float Width { get; set; } }DimensionsBase에는 다음과 같은 속성이 있습니다float.-
X에는 x축을 따라 개체의 위치가 포함됩니다. -
Y에는 y축을 따라 개체의 위치가 포함됩니다. -
Height에는 개체의 높이가 포함됩니다. -
Width에는 개체의 너비가 포함됩니다.
-
다음으로 경계 상자에 대한 클래스를 생성합니다.
솔루션 탐색기에서 YoloParser 디렉터리를 마우스 오른쪽 단추로 클릭한 다음새 항목>를 선택합니다.
새 항목 추가 대화 상자에서 클래스를 선택하고 이름 필드를 YoloBoundingBox.cs 변경합니다. 그런 후 추가를 선택합니다.
YoloBoundingBox.cs 파일이 코드 편집기에서 열립니다.
using맨 위에 다음 지시문을 추가합니다.using System.Drawing;기존 클래스 정의 바로 위에
DimensionsBase클래스로부터 상속받는BoundingBoxDimensions라는 새로운 클래스 정의를 추가하여 해당 경계 상자의 차원을 포함합니다.public class BoundingBoxDimensions : DimensionsBase { }기존
YoloBoundingBox클래스 정의를 제거하고 클래스에 대한YoloBoundingBox다음 코드를 YoloBoundingBox.cs 파일에 추가합니다.public class YoloBoundingBox { public BoundingBoxDimensions Dimensions { get; set; } public string Label { get; set; } public float Confidence { get; set; } public RectangleF Rect { get { return new RectangleF(Dimensions.X, Dimensions.Y, Dimensions.Width, Dimensions.Height); } } public Color BoxColor { get; set; } }YoloBoundingBox에는 다음과 같은 속성이 있습니다.-
Dimensions에는 경계 상자의 치수가 포함됩니다. -
Label에는 경계 상자 내에서 검색된 개체 클래스가 포함됩니다. -
Confidence는 클래스의 신뢰도를 포함합니다. -
Rect에는 경계 상자의 차원을 사각형 형태로 표현한 것이 포함됩니다. -
BoxColor에는 이미지에 그리는 데 사용되는 각 클래스와 연결된 색이 포함됩니다.
-
파서 만들기
차원 및 경계 상자에 대한 클래스를 만들었으므로 이제 파서를 만들어야 합니다.
솔루션 탐색기에서 YoloParser 디렉터리를 마우스 오른쪽 단추로 클릭한 다음새 항목>를 선택합니다.
새 항목 추가 대화 상자에서 클래스를 선택하고 이름 필드를 YoloOutputParser.cs 변경합니다. 그런 후 추가를 선택합니다.
YoloOutputParser.cs 파일이 코드 편집기에서 열립니다. YoloOutputParser.cs 맨 위에 다음
using지시문을 추가합니다.using System; using System.Collections.Generic; using System.Drawing; using System.Linq;기존
YoloOutputParser클래스 정의 내에 이미지에 있는 각 셀의 차원이 포함된 중첩 클래스를 추가합니다.CellDimensions클래스에서 상속되는 클래스에 대해YoloOutputParser클래스 정의의 맨 위에 다음 코드를 추가합니다.class CellDimensions : DimensionsBase { }YoloOutputParser클래스 정의 내에 다음 상수 및 필드를 추가합니다.public const int ROW_COUNT = 13; public const int COL_COUNT = 13; public const int CHANNEL_COUNT = 125; public const int BOXES_PER_CELL = 5; public const int BOX_INFO_FEATURE_COUNT = 5; public const int CLASS_COUNT = 20; public const float CELL_WIDTH = 32; public const float CELL_HEIGHT = 32; private int channelStride = ROW_COUNT * COL_COUNT;-
ROW_COUNT는 이미지가 분할된 그리드의 행 수입니다. -
COL_COUNT는 이미지가 분할된 그리드의 열 수입니다. -
CHANNEL_COUNT는 표의 한 셀에 포함된 값의 총 개수입니다. -
BOXES_PER_CELL는 셀의 경계 상자 수입니다. -
BOX_INFO_FEATURE_COUNT은 상자에 포함된 기능 수입니다(x,y,height,width,confidence). -
CLASS_COUNT는 각 경계 상자에 포함된 클래스 예측의 수입니다. -
CELL_WIDTH는 이미지 표에 있는 한 셀의 너비입니다. -
CELL_HEIGHT는 이미지 표에 있는 한 셀의 높이입니다. -
channelStride는 표에서 현재 셀의 시작 위치입니다.
모델은 점수 매기기라고도 하는 예측을 만들 때 입력 이미지를 셀 크기의
416px x 416px그리드로 나눕니다13 x 13. 각 셀은32px x 32px을 포함합니다. 각 셀에는 각각 5개의 기능(x, y, 너비, 높이, 신뢰도)이 포함된 5개의 경계 상자가 있습니다. 또한 각 경계 상자에는 각 클래스의 확률이 포함되며, 이 경우 20입니다. 따라서 각 셀에는 125개의 정보(5개 기능 + 20개 클래스 확률)가 포함됩니다.-
5개의 경계 상자 모두에 대해 channelStride 아래에 앵커 목록을 만드세요.
private float[] anchors = new float[]
{
1.08F, 1.19F, 3.42F, 4.41F, 6.63F, 11.38F, 9.42F, 5.11F, 16.62F, 10.52F
};
앵커는 경계 상자의 미리 정의된 높이 및 너비 비율입니다. 모델에서 검색된 대부분의 개체 또는 클래스의 비율은 비슷합니다. 이는 경계 상자를 만들 때 유용합니다. 경계 상자를 예측하는 대신 미리 정의된 차원의 오프셋이 계산되므로 경계 상자를 예측하는 데 필요한 계산이 줄어듭니다. 일반적으로 이러한 앵커 비율은 사용되는 데이터 세트를 기반으로 계산됩니다. 이 경우 데이터 세트가 알려져 있고 값이 미리 계산되었으므로 앵커를 하드 코딩할 수 있습니다.
다음으로, 모델이 예측할 레이블 또는 클래스를 정의합니다. 이 모델은 원래 YOLOv2 모델에서 예측한 총 클래스 수의 하위 집합인 20개의 클래스를 예측합니다.
아래에 anchors레이블 목록을 추가합니다.
private string[] labels = new string[]
{
"aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"
};
각 클래스와 연결된 색이 있습니다. 다음 아래에 클래스 색을 할당합니다 labels.
private static Color[] classColors = new Color[]
{
Color.Khaki,
Color.Fuchsia,
Color.Silver,
Color.RoyalBlue,
Color.Green,
Color.DarkOrange,
Color.Purple,
Color.Gold,
Color.Red,
Color.Aquamarine,
Color.Lime,
Color.AliceBlue,
Color.Sienna,
Color.Orchid,
Color.Tan,
Color.LightPink,
Color.Yellow,
Color.HotPink,
Color.OliveDrab,
Color.SandyBrown,
Color.DarkTurquoise
};
도우미 함수 만들기
사후 처리 단계에는 일련의 단계가 있습니다. 이를 돕기 위해 몇 가지 도우미 방법을 사용할 수 있습니다.
파서에서 사용되는 도우미 메서드는 다음과 같습니다.
-
Sigmoid는 0에서 1 사이의 숫자를 출력하는 시그모이드 함수를 적용합니다. -
Softmax는 입력 벡터를 확률 분포로 정규화합니다. -
GetOffset는 모델의 1차원 출력 요소를125 x 13 x 13텐서의 해당 위치에 매핑합니다. -
ExtractBoundingBoxes는 모델 출력에서 메서드를 사용하여GetOffset경계 상자 차원을 추출합니다. -
GetConfidence는 모델이 개체를 감지하고 함수를 사용하여Sigmoid백분율로 전환하는지 확인하는 방법을 나타내는 신뢰도 값을 추출합니다. -
MapBoundingBoxToCell는 경계 상자의 크기를 사용하여 이미지 내의 해당 셀에 매핑합니다. -
ExtractClasses는GetOffset메서드를 사용하여 모델 출력에서 경계 상자에 대한 클래스 예측을 추출하고Softmax메서드를 사용하여 이를 확률 분포로 변환합니다. -
GetTopResult는 확률이 가장 높은 예측 클래스 목록에서 클래스를 선택합니다. -
IntersectionOverUnion는 확률이 낮은 겹치는 경계 상자를 필터링합니다.
목록 classColors아래에 모든 도우미 메서드에 대한 코드를 추가합니다.
private float Sigmoid(float value)
{
var k = (float)Math.Exp(value);
return k / (1.0f + k);
}
private float[] Softmax(float[] values)
{
var maxVal = values.Max();
var exp = values.Select(v => Math.Exp(v - maxVal));
var sumExp = exp.Sum();
return exp.Select(v => (float)(v / sumExp)).ToArray();
}
private int GetOffset(int x, int y, int channel)
{
// YOLO outputs a tensor that has a shape of 125x13x13, which
// WinML flattens into a 1D array. To access a specific channel
// for a given (x,y) cell position, we need to calculate an offset
// into the array
return (channel * this.channelStride) + (y * COL_COUNT) + x;
}
private BoundingBoxDimensions ExtractBoundingBoxDimensions(float[] modelOutput, int x, int y, int channel)
{
return new BoundingBoxDimensions
{
X = modelOutput[GetOffset(x, y, channel)],
Y = modelOutput[GetOffset(x, y, channel + 1)],
Width = modelOutput[GetOffset(x, y, channel + 2)],
Height = modelOutput[GetOffset(x, y, channel + 3)]
};
}
private float GetConfidence(float[] modelOutput, int x, int y, int channel)
{
return Sigmoid(modelOutput[GetOffset(x, y, channel + 4)]);
}
private CellDimensions MapBoundingBoxToCell(int x, int y, int box, BoundingBoxDimensions boxDimensions)
{
return new CellDimensions
{
X = ((float)x + Sigmoid(boxDimensions.X)) * CELL_WIDTH,
Y = ((float)y + Sigmoid(boxDimensions.Y)) * CELL_HEIGHT,
Width = (float)Math.Exp(boxDimensions.Width) * CELL_WIDTH * anchors[box * 2],
Height = (float)Math.Exp(boxDimensions.Height) * CELL_HEIGHT * anchors[box * 2 + 1],
};
}
public float[] ExtractClasses(float[] modelOutput, int x, int y, int channel)
{
float[] predictedClasses = new float[CLASS_COUNT];
int predictedClassOffset = channel + BOX_INFO_FEATURE_COUNT;
for (int predictedClass = 0; predictedClass < CLASS_COUNT; predictedClass++)
{
predictedClasses[predictedClass] = modelOutput[GetOffset(x, y, predictedClass + predictedClassOffset)];
}
return Softmax(predictedClasses);
}
private ValueTuple<int, float> GetTopResult(float[] predictedClasses)
{
return predictedClasses
.Select((predictedClass, index) => (Index: index, Value: predictedClass))
.OrderByDescending(result => result.Value)
.First();
}
private float IntersectionOverUnion(RectangleF boundingBoxA, RectangleF boundingBoxB)
{
var areaA = boundingBoxA.Width * boundingBoxA.Height;
if (areaA <= 0)
return 0;
var areaB = boundingBoxB.Width * boundingBoxB.Height;
if (areaB <= 0)
return 0;
var minX = Math.Max(boundingBoxA.Left, boundingBoxB.Left);
var minY = Math.Max(boundingBoxA.Top, boundingBoxB.Top);
var maxX = Math.Min(boundingBoxA.Right, boundingBoxB.Right);
var maxY = Math.Min(boundingBoxA.Bottom, boundingBoxB.Bottom);
var intersectionArea = Math.Max(maxY - minY, 0) * Math.Max(maxX - minX, 0);
return intersectionArea / (areaA + areaB - intersectionArea);
}
모든 도우미 메서드를 정의한 후에는 이를 사용하여 모델 출력을 처리해야 합니다.
IntersectionOverUnion 메서드 아래에서 모델에서 ParseOutputs 생성된 출력을 처리하는 메서드를 만듭니다.
public IList<YoloBoundingBox> ParseOutputs(float[] yoloModelOutputs, float threshold = .3F)
{
}
경계 상자를 저장하고 메서드 내부에 ParseOutputs 변수를 정의하는 목록을 만듭니다.
var boxes = new List<YoloBoundingBox>();
각 이미지는 셀 표 13 x 13 로 나뉩니다. 각 셀에는 5개의 경계 상자가 있습니다.
boxes 변수 아래에 각 셀의 모든 상자를 처리하는 코드를 추가합니다.
for (int row = 0; row < ROW_COUNT; row++)
{
for (int column = 0; column < COL_COUNT; column++)
{
for (int box = 0; box < BOXES_PER_CELL; box++)
{
}
}
}
가장 안쪽 루프 내에서 1차원 모델 출력 내에서 현재 상자의 시작 위치를 계산합니다.
var channel = (box * (CLASS_COUNT + BOX_INFO_FEATURE_COUNT));
바로 아래에서 메서드를 ExtractBoundingBoxDimensions 사용하여 현재 경계 상자의 크기를 가져옵니다.
BoundingBoxDimensions boundingBoxDimensions = ExtractBoundingBoxDimensions(yoloModelOutputs, row, column, channel);
그런 다음 GetConfidence 메서드를 사용하여 현재의 경계 상자에 대한 신뢰도 값을 가져옵니다.
float confidence = GetConfidence(yoloModelOutputs, row, column, channel);
그런 다음 메서드를 MapBoundingBoxToCell 사용하여 현재 경계 상자를 처리 중인 현재 셀에 매핑합니다.
CellDimensions mappedBoundingBox = MapBoundingBoxToCell(row, column, box, boundingBoxDimensions);
추가 처리를 수행하기 전에 신뢰도 값이 제공된 임계값보다 큰지 확인합니다. 그렇지 않은 경우 다음 경계 상자를 처리합니다.
if (confidence < threshold)
continue;
그렇지 않으면 출력 처리를 계속합니다. 다음 단계는 ExtractClasses 메서드를 사용하여 현재 경계 상자에 대해 예측된 클래스의 확률 분포를 얻는 것입니다.
float[] predictedClasses = ExtractClasses(yoloModelOutputs, row, column, channel);
그런 다음 메서드를 GetTopResult 사용하여 현재 상자에 대한 확률이 가장 높은 클래스의 값과 인덱스 값을 가져와 점수를 계산합니다.
var (topResultIndex, topResultScore) = GetTopResult(predictedClasses);
var topScore = topResultScore * confidence;
topScore 지정된 임계값을 초과하는 경계 상자만 다시 한 번 유지하려면 이 값을 사용합니다.
if (topScore < threshold)
continue;
마지막으로 현재 경계 상자가 임계값을 초과하는 경우 새 BoundingBox 개체를 만들어 boxes 목록에 추가합니다.
boxes.Add(new YoloBoundingBox()
{
Dimensions = new BoundingBoxDimensions
{
X = (mappedBoundingBox.X - mappedBoundingBox.Width / 2),
Y = (mappedBoundingBox.Y - mappedBoundingBox.Height / 2),
Width = mappedBoundingBox.Width,
Height = mappedBoundingBox.Height,
},
Confidence = topScore,
Label = labels[topResultIndex],
BoxColor = classColors[topResultIndex]
});
이미지의 모든 셀이 처리되면 목록을 반환합니다 boxes . 메서드의 가장 외부 for-loop ParseOutputs 아래에 다음 return 문을 추가합니다.
return boxes;
겹치는 상자 필터링
이제 모델 출력에서 신뢰도 높은 경계 상자가 모두 추출되었으므로 겹치는 이미지를 제거하려면 추가 필터링을 수행해야 합니다. 메서드 아래에 호출 FilterBoundingBoxes 된 메서드를 ParseOutputs 추가합니다.
public IList<YoloBoundingBox> FilterBoundingBoxes(IList<YoloBoundingBox> boxes, int limit, float threshold)
{
}
메서드 내에서 FilterBoundingBoxes 검색된 상자 크기와 동일한 배열을 만들고 모든 슬롯을 활성 또는 처리 준비 상태로 표시하여 시작합니다.
var activeCount = boxes.Count;
var isActiveBoxes = new bool[boxes.Count];
for (int i = 0; i < isActiveBoxes.Length; i++)
isActiveBoxes[i] = true;
그런 다음 경계 상자가 포함된 목록을 신뢰도에 따라 내림차순으로 정렬합니다.
var sortedBoxes = boxes.Select((b, i) => new { Box = b, Index = i })
.OrderByDescending(b => b.Box.Confidence)
.ToList();
그런 다음 필터링된 결과를 저장할 목록을 만듭니다.
var results = new List<YoloBoundingBox>();
각 경계 상자를 반복하여 각 경계 상자 처리를 시작합니다.
for (int i = 0; i < boxes.Count; i++)
{
}
이 for 루프 내에서 현재 경계 상자가 처리 가능한지 확인합니다.
if (isActiveBoxes[i])
{
}
만약 그렇다면, 결과 목록에 경계 상자를 추가합니다. 결과가 추출할 상자의 지정된 한도를 초과하면 루프를 중단합니다. if 문 내에 다음 코드를 추가합니다.
var boxA = sortedBoxes[i].Box;
results.Add(boxA);
if (results.Count >= limit)
break;
그렇지 않으면 인접한 경계 상자를 확인합니다. 상자 제한 확인 아래에 다음 코드를 추가합니다.
for (var j = i + 1; j < boxes.Count; j++)
{
}
첫 번째 상자와 마찬가지로 인접한 상자가 활성화되어 있거나 처리할 준비가 되면 메서드를 사용하여 IntersectionOverUnion 첫 번째 상자와 두 번째 상자가 지정된 임계값을 초과하는지 여부를 확인합니다. 가장 안쪽의 for-루프에 다음 코드를 추가합니다.
if (isActiveBoxes[j])
{
var boxB = sortedBoxes[j].Box;
if (IntersectionOverUnion(boxA.Rect, boxB.Rect) > threshold)
{
isActiveBoxes[j] = false;
activeCount--;
if (activeCount <= 0)
break;
}
}
인접한 경계 상자를 확인하는 가장 안쪽 for-loop 외부에서 처리할 나머지 경계 상자가 있는지 확인합니다. 그렇지 않은 경우 외부 for-loop에서 중단합니다.
if (activeCount <= 0)
break;
마지막으로 메서드의 초기 for-loop FilterBoundingBoxes 외부에서 결과를 반환합니다.
return results;
좋습니다! 이제 점수 매기기 모델과 함께 이 코드를 사용할 차례입니다.
점수 매기기를 위해 모델 사용
사후 처리와 마찬가지로 점수 매기기 단계에는 몇 가지 단계가 있습니다. 이 문제를 해결하려면 점수 매기기 논리를 포함하는 클래스를 프로젝트에 추가합니다.
솔루션 탐색기에서 프로젝트를 마우스 오른쪽 단추로 클릭한 다음새 항목>를 선택합니다.
새 항목 추가 대화 상자에서 클래스를 선택하고 이름 필드를 OnnxModelScorer.cs 변경합니다. 그런 후 추가를 선택합니다.
OnnxModelScorer.cs 파일이 코드 편집기에서 열립니다. OnnxModelScorer.cs 맨 위에 다음
using지시문을 추가합니다.using System; using System.Collections.Generic; using System.Linq; using Microsoft.ML; using Microsoft.ML.Data; using ObjectDetection.DataStructures; using ObjectDetection.YoloParser;OnnxModelScorer클래스 정의 내에 다음 변수를 추가합니다.private readonly string imagesFolder; private readonly string modelLocation; private readonly MLContext mlContext; private IList<YoloBoundingBox> _boundingBoxes = new List<YoloBoundingBox>();바로 아래에 이전에 정의된 변수를
OnnxModelScorer초기화하는 클래스에 대한 생성자를 만듭니다.public OnnxModelScorer(string imagesFolder, string modelLocation, MLContext mlContext) { this.imagesFolder = imagesFolder; this.modelLocation = modelLocation; this.mlContext = mlContext; }생성자를 만든 후에는 이미지 및 모델 설정과 관련된 변수를 포함하는 몇 가지 구조체를 정의합니다. 모델 입력으로 예상되는 높이와 너비를 포함하는
ImageNetSettings라는 구조체를 만드세요.public struct ImageNetSettings { public const int imageHeight = 416; public const int imageWidth = 416; }그런 다음 모델의 입력 및 출력 계층의 이름을 포함하는 다른 구조체를 만듭니
TinyYoloModelSettings다. 모델의 입력 및 출력 계층의 이름을 시각화하려면 Netron과 같은 도구를 사용할 수 있습니다.public struct TinyYoloModelSettings { // for checking Tiny yolo2 Model input and output parameter names, //you can use tools like Netron, // which is installed by Visual Studio AI Tools // input tensor name public const string ModelInput = "image"; // output tensor name public const string ModelOutput = "grid"; }다음으로, 채점에 사용하는 첫 번째 메서드 집합을 만듭니다.
LoadModel클래스 내에서 메서드를 만듭니다OnnxModelScorer.private ITransformer LoadModel(string modelLocation) { }메서드 내에서
LoadModel로깅을 위해 다음 코드를 추가합니다.Console.WriteLine("Read model"); Console.WriteLine($"Model location: {modelLocation}"); Console.WriteLine($"Default parameters: image size=({ImageNetSettings.imageWidth},{ImageNetSettings.imageHeight})");ML.NET 파이프라인은 메서드를 호출할 때 작동할 데이터 스키마를
Fit알아야 합니다. 이 경우 학습과 유사한 프로세스가 사용됩니다. 그러나 실제 학습이 발생하지 않으므로 빈IDataView학습을 사용할 수 있습니다. 빈 목록에서 파이프라인에 대한 새IDataView항목을 만듭니다.var data = mlContext.Data.LoadFromEnumerable(new List<ImageNetData>());그 아래에서 파이프라인을 정의합니다. 파이프라인은 4개의 변환으로 구성됩니다.
-
LoadImages는 이미지를 비트맵으로 로드합니다. -
ResizeImages지정된 크기(이 경우416 x 416)로 이미지 크기를 다시 조정합니다. -
ExtractPixels는 이미지의 픽셀 표현을 비트맵에서 숫자 벡터로 변경합니다. -
ApplyOnnxModel는 ONNX 모델을 로드하고 이를 사용하여 제공된 데이터에 대해 점수를 매깁니다.
변수 아래의 메서드에서
LoadModel파이프라인을data정의합니다.var pipeline = mlContext.Transforms.LoadImages(outputColumnName: "image", imageFolder: "", inputColumnName: nameof(ImageNetData.ImagePath)) .Append(mlContext.Transforms.ResizeImages(outputColumnName: "image", imageWidth: ImageNetSettings.imageWidth, imageHeight: ImageNetSettings.imageHeight, inputColumnName: "image")) .Append(mlContext.Transforms.ExtractPixels(outputColumnName: "image")) .Append(mlContext.Transforms.ApplyOnnxModel(modelFile: modelLocation, outputColumnNames: new[] { TinyYoloModelSettings.ModelOutput }, inputColumnNames: new[] { TinyYoloModelSettings.ModelInput }));이제 점수 매기기 모델을 인스턴스화할 차례입니다. 파이프라인에서
Fit메서드를 호출하고 추가 처리를 위해 반환합니다.var model = pipeline.Fit(data); return model;-
모델이 로드되면 예측을 만드는 데 사용할 수 있습니다. 해당 프로세스를 용이하게 하려면 메서드 아래에 호출 PredictDataUsingModel 된 메서드를 LoadModel 만듭니다.
private IEnumerable<float[]> PredictDataUsingModel(IDataView testData, ITransformer model)
{
}
내부에 PredictDataUsingModel로깅을 위해 다음 코드를 추가합니다.
Console.WriteLine($"Images location: {imagesFolder}");
Console.WriteLine("");
Console.WriteLine("=====Identify the objects in the images=====");
Console.WriteLine("");
그런 다음, 메서드를 Transform 사용하여 데이터 점수를 매깁니다.
IDataView scoredData = model.Transform(testData);
예측된 확률을 추출하고 추가 처리를 위해 반환합니다.
IEnumerable<float[]> probabilities = scoredData.GetColumn<float[]>(TinyYoloModelSettings.ModelOutput);
return probabilities;
이제 두 단계가 모두 설정되었으므로 단일 메서드로 결합합니다.
PredictDataUsingModel 메서드 아래에 라는 Score새 메서드를 추가합니다.
public IEnumerable<float[]> Score(IDataView data)
{
var model = LoadModel(modelLocation);
return PredictDataUsingModel(data, model);
}
거의 다 왔어! 이제 모든 것을 사용할 시간입니다.
개체 검색
이제 모든 설정이 완료되었으므로 일부 개체를 검색해야 합니다.
모델 출력 점수 매기기 및 파싱
변수 생성 mlContext 아래에 try-catch 문을 추가합니다.
try
{
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
블록 내에서 try 개체 검색 논리 구현을 시작합니다. 먼저 데이터를 .에 로드합니다 IDataView.
IEnumerable<ImageNetData> images = ImageNetData.ReadFromFile(imagesFolder);
IDataView imageDataView = mlContext.Data.LoadFromEnumerable(images);
그런 다음 인스턴스를 OnnxModelScorer 만들어 로드된 데이터의 점수를 매기는 데 사용합니다.
// Create instance of model scorer
var modelScorer = new OnnxModelScorer(imagesFolder, modelFilePath, mlContext);
// Use model to score data
IEnumerable<float[]> probabilities = modelScorer.Score(imageDataView);
이제 사후 처리 단계가 준비되었습니다. 인스턴스 YoloOutputParser 를 만들고 이를 사용하여 모델 출력을 처리합니다.
YoloOutputParser parser = new YoloOutputParser();
var boundingBoxes =
probabilities
.Select(probability => parser.ParseOutputs(probability))
.Select(boxes => parser.FilterBoundingBoxes(boxes, 5, .5F));
모델 출력이 처리되면 이미지에 경계 상자를 그릴 시간입니다.
예측 시각화
모델이 이미지에 점수를 매기고 출력이 처리된 후에는 이미지에 경계 상자를 그려야 합니다. 이렇게 하려면 DrawBoundingBox 내의 메서드 아래에 호출된 GetAbsolutePath 메서드를 추가합니다.
void DrawBoundingBox(string inputImageLocation, string outputImageLocation, string imageName, IList<YoloBoundingBox> filteredBoundingBoxes)
{
}
먼저 이미지를 로드하고 메서드의 높이와 너비 크기를 가져옵니다 DrawBoundingBox .
Image image = Image.FromFile(Path.Combine(inputImageLocation, imageName));
var originalImageHeight = image.Height;
var originalImageWidth = image.Width;
그런 다음 모델에서 탐지한 각 경계 상자를 반복 처리하기 위해 for-each 루프를 생성합니다.
foreach (var box in filteredBoundingBoxes)
{
}
for-each 루프 내에서 경계 상자의 크기를 가져옵니다.
var x = (uint)Math.Max(box.Dimensions.X, 0);
var y = (uint)Math.Max(box.Dimensions.Y, 0);
var width = (uint)Math.Min(originalImageWidth - x, box.Dimensions.Width);
var height = (uint)Math.Min(originalImageHeight - y, box.Dimensions.Height);
경계 상자의 크기가 모델의 입력 416 x 416에 맞춰져 있기 때문에, 경계 상자의 크기를 이미지의 실제 크기에 맞도록 조정합니다.
x = (uint)originalImageWidth * x / OnnxModelScorer.ImageNetSettings.imageWidth;
y = (uint)originalImageHeight * y / OnnxModelScorer.ImageNetSettings.imageHeight;
width = (uint)originalImageWidth * width / OnnxModelScorer.ImageNetSettings.imageWidth;
height = (uint)originalImageHeight * height / OnnxModelScorer.ImageNetSettings.imageHeight;
그런 다음 각 경계 상자 위에 표시되는 텍스트에 대한 템플릿을 정의합니다. 텍스트에는 해당 경계 상자 내의 개체 클래스와 신뢰도가 포함됩니다.
string text = $"{box.Label} ({(box.Confidence * 100).ToString("0")}%)";
이미지를 그리려면 개체로 Graphics 변환합니다.
using (Graphics thumbnailGraphic = Graphics.FromImage(image))
{
}
코드 블록 내에서 using 그래픽의 Graphics 개체 설정을 튜닝합니다.
thumbnailGraphic.CompositingQuality = CompositingQuality.HighQuality;
thumbnailGraphic.SmoothingMode = SmoothingMode.HighQuality;
thumbnailGraphic.InterpolationMode = InterpolationMode.HighQualityBicubic;
그 아래에서 텍스트 및 경계 상자에 대한 글꼴 및 색 옵션을 설정합니다.
// Define Text Options
Font drawFont = new Font("Arial", 12, FontStyle.Bold);
SizeF size = thumbnailGraphic.MeasureString(text, drawFont);
SolidBrush fontBrush = new SolidBrush(Color.Black);
Point atPoint = new Point((int)x, (int)y - (int)size.Height - 1);
// Define BoundingBox options
Pen pen = new Pen(box.BoxColor, 3.2f);
SolidBrush colorBrush = new SolidBrush(box.BoxColor);
메서드를 사용하여 FillRectangle 텍스트를 포함하도록 경계 상자 위에 사각형을 만들고 채웁니다. 이렇게 하면 텍스트를 대조하고 가독성을 향상시키는 데 도움이 됩니다.
thumbnailGraphic.FillRectangle(colorBrush, (int)x, (int)(y - size.Height - 1), (int)size.Width, (int)size.Height);
그런 다음, DrawString 및 DrawRectangle 메서드를 사용하여 이미지에 텍스트와 경계 상자를 그립니다.
thumbnailGraphic.DrawString(text, drawFont, fontBrush, atPoint);
// Draw bounding box on image
thumbnailGraphic.DrawRectangle(pen, x, y, width, height);
for-each 루프 외부에서 이미지를 outputFolder저장하는 코드를 추가합니다.
if (!Directory.Exists(outputImageLocation))
{
Directory.CreateDirectory(outputImageLocation);
}
image.Save(Path.Combine(outputImageLocation, imageName));
애플리케이션이 런타임에 예상대로 예측을 수행한다는 추가 피드백을 보려면 LogDetectedObjects 파일의 DrawBoundingBox 메서드 아래에 호출 된 메서드를 추가하여 검색된 개체를 콘솔에 출력합니다.
void LogDetectedObjects(string imageName, IList<YoloBoundingBox> boundingBoxes)
{
Console.WriteLine($".....The objects in the image {imageName} are detected as below....");
foreach (var box in boundingBoxes)
{
Console.WriteLine($"{box.Label} and its Confidence score: {box.Confidence}");
}
Console.WriteLine("");
}
이제 예측에서 시각적 피드백을 생성하는 도우미 메서드가 있으므로, 점수 매기기 완료된 각 이미지를 반복하기 위해 for 루프를 추가합니다.
for (var i = 0; i < images.Count(); i++)
{
}
for-loop 내에서 이미지 파일의 이름과 연결된 경계 상자를 가져옵니다.
string imageFileName = images.ElementAt(i).Label;
IList<YoloBoundingBox> detectedObjects = boundingBoxes.ElementAt(i);
그 아래에서 메서드를 DrawBoundingBox 사용하여 이미지에 경계 상자를 그립니다.
DrawBoundingBox(imagesFolder, outputFolder, imageFileName, detectedObjects);
마지막으로 이 메서드를 LogDetectedObjects 사용하여 콘솔에 예측을 출력합니다.
LogDetectedObjects(imageFileName, detectedObjects);
try-catch 문 후에 프로세스가 실행 중임을 나타내는 논리를 추가합니다.
Console.WriteLine("========= End of Process..Hit any Key ========");
이것으로 끝입니다.
Results
이전 단계를 수행한 후 콘솔 앱(Ctrl + F5)을 실행합니다. 결과는 다음 출력과 유사해야 합니다. 경고 또는 메시지 처리가 표시될 수 있지만 명확성을 위해 다음 결과에서 이러한 메시지가 제거되었습니다.
=====Identify the objects in the images=====
.....The objects in the image image1.jpg are detected as below....
car and its Confidence score: 0.9697262
car and its Confidence score: 0.6674225
person and its Confidence score: 0.5226039
car and its Confidence score: 0.5224892
car and its Confidence score: 0.4675332
.....The objects in the image image2.jpg are detected as below....
cat and its Confidence score: 0.6461141
cat and its Confidence score: 0.6400049
.....The objects in the image image3.jpg are detected as below....
chair and its Confidence score: 0.840578
chair and its Confidence score: 0.796363
diningtable and its Confidence score: 0.6056048
diningtable and its Confidence score: 0.3737402
.....The objects in the image image4.jpg are detected as below....
dog and its Confidence score: 0.7608147
person and its Confidence score: 0.6321323
dog and its Confidence score: 0.5967442
person and its Confidence score: 0.5730394
person and its Confidence score: 0.5551759
========= End of Process..Hit any Key ========
경계 상자가 있는 이미지를 보려면 assets/images/output/ 디렉터리로 이동합니다. 다음은 처리된 이미지 중 하나의 샘플입니다.

축하합니다! 이제 ML.NET 미리 학습된 모델을 다시 사용하여 개체 검색을 위한 기계 학습 모델을 성공적으로 빌드했습니다 ONNX .
이 자습서의 소스 코드는 dotnet/machinelearning-samples 리포지토리에서 찾을 수 있습니다.
이 자습서에서는 다음 방법을 알아보았습니다.
- 문제 이해
- ONNX란 무엇이며 ML.NET 어떻게 작동하는지 알아봅니다.
- 모델 이해
- 미리 학습된 모델 다시 사용
- 로드된 모델을 사용하여 개체 검색
Machine Learning 샘플 GitHub 리포지토리를 확인하여 확장된 개체 검색 샘플을 탐색합니다.
GitHub에서 Microsoft와 공동 작업
이 콘텐츠의 원본은 GitHub에서 찾을 수 있으며, 여기서 문제와 끌어오기 요청을 만들고 검토할 수도 있습니다. 자세한 내용은 참여자 가이드를 참조하세요.
.NET