Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Postępuj zgodnie z tym artykułem, gdy chcesz przeanalizować pliki Parquet lub zapisać dane w formacie Parquet.
Format Parquet jest obsługiwany dla następujących łączników:
- Amazon S3
- Magazyn zgodny z usługą Amazon S3
- Azure Blob
- Usługa Azure Data Lake Storage 1. generacji
- Azure Data Lake Storage Gen2
- Azure Files
- System plików
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
Listę obsługiwanych funkcji dla wszystkich dostępnych łączników można znaleźć w artykule Omówienie łączników.
Korzystanie z własnego środowiska Integration Runtime
Ważne
W przypadku kopiowania z uprawnieniami własnego środowiska Integration Runtime, np. między lokalnymi i w chmurze magazynami danych, jeśli pliki Parquet nie są kopiowane, musisz zainstalować 64-bitowe środowisko JRE 8 (Java Runtime Environment), zestaw JDK 23 (Java Development Kit) lub zestaw OpenJDK na maszynie IR. Zapoznaj się z poniższym akapitem, aby uzyskać więcej szczegółów.
W przypadku kopiowania działającego na własnym środowisku IR z serializacji/deserializacji plików Parquet usługa lokalizuje środowisko uruchomieniowe Języka Java, sprawdzając najpierw rejestr (SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome) środowiska JRE, jeśli nie zostanie znaleziony, po drugie sprawdzając zmienną systemową JAVA_HOME dla zestawu OpenJDK.
- Aby użyć środowiska JRE: 64-bitowe środowisko IR wymaga 64-bitowego środowiska JRE. Możesz go znaleźć tutaj.
-
Aby użyć zestawu JDK: 64-bitowe środowisko IR wymaga 64-bitowego zestawu JDK 23. Możesz go znaleźć tutaj. Pamiętaj, aby zaktualizować zmienną
JAVA_HOMEsystemową do folderu głównego instalacji zestawu JDK 23, tj.C:\Program Files\Java\jdk-23, i dodać ścieżkę doC:\Program Files\Java\jdk-23\binfolderu iC:\Program Files\Java\jdk-23\bin\serverdo zmiennejPathsystemowej. - Aby użyć zestawu OpenJDK: jest obsługiwany od czasu środowiska IR w wersji 3.13. Spakuj jvm.dll ze wszystkimi innymi wymaganymi zestawami zestawu OpenJDK na maszynę własnego środowiska IR i ustaw odpowiednio zmienną środowiskową systemu JAVA_HOME, a następnie uruchom ponownie własne środowisko IR, aby natychmiast rozpocząć działanie. Aby pobrać zestaw Microsoft Build of OpenJDK, zobacz Microsoft Build of OpenJDK (Kompilacja Microsoft Build zestawu OpenJDK™).
Napiwek
Jeśli skopiujesz dane do/z formatu Parquet przy użyciu własnego środowiska Integration Runtime i wystąpi błąd informujący o błędzie "Wystąpił błąd podczas wywoływania języka Java, komunikat: java.lang.OutOfMemoryError: Przestrzeń sterty Java", możesz dodać zmienną środowiskową _JAVA_OPTIONS na maszynie, która hostuje własne środowisko IR, aby dostosować minimalny/maksymalny rozmiar sterty dla maszyny JVM w celu wzmocnienia takiej możliwości kopiowania, a następnie ponownie uruchomić potok.

Przykład: ustaw zmienną _JAVA_OPTIONS z wartością -Xms256m -Xmx16g. Flaga Xms określa początkową pulę alokacji pamięci dla maszyny wirtualnej Java (JVM), podczas gdy Xmx określa maksymalną pulę alokacji pamięci. Oznacza to, że maszyny JVM zostaną uruchomione z ilością Xms pamięci i będą mogły korzystać z maksymalnej Xmx ilości pamięci. Domyślnie usługa używa min 64 MB i maksymalnej liczby 1G.
Właściwości zestawu danych
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania zestawów danych, zobacz artykuł Zestawy danych. Ta sekcja zawiera listę właściwości obsługiwanych przez zestaw danych Parquet.
| Właściwości | Opis | Wymagania |
|---|---|---|
| typ | Właściwość type zestawu danych musi być ustawiona na Parquet. | Tak |
| lokalizacja | Ustawienia lokalizacji plików. Każdy łącznik oparty na plikach ma własny typ lokalizacji i obsługiwane właściwości w obszarze location.
Zobacz szczegóły w artykule dotyczącym łącznika —> sekcja Właściwości zestawu danych. |
Tak |
| compressionCodec | Koder koder-dekoder kompresji używany podczas zapisywania w plikach Parquet. Podczas odczytywania z plików Parquet fabryki danych automatycznie określają koder-dekoder kompresji na podstawie metadanych pliku. Obsługiwane typy to "none", "gzip", "snappy" (ustawienie domyślne) i "lzo". Uwaga obecnie działanie Kopiuj nie obsługuje LZO podczas odczytu/zapisu plików Parquet. |
Nie. |
Uwaga
Białe znaki w nazwie kolumny nie są obsługiwane w przypadku plików Parquet.
Poniżej przedstawiono przykład zestawu danych Parquet w usłudze Azure Blob Storage:
{
"name": "ParquetDataset",
"properties": {
"type": "Parquet",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compressionCodec": "snappy"
}
}
}
Właściwości działania kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz artykuł Pipelines (Potoki ). Ta sekcja zawiera listę właściwości obsługiwanych przez źródło i ujście Parquet.
Parquet jako źródło
Następujące właściwości są obsługiwane w sekcji działanie kopiowania *źródło* .
| Właściwości | Opis | Wymagania |
|---|---|---|
| typ | Właściwość type źródła działania kopiowania musi być ustawiona na ParquetSource. | Tak |
| storeSettings | Grupa właściwości dotyczących odczytywania danych z magazynu danych. Każdy łącznik oparty na plikach ma własne obsługiwane ustawienia odczytu w obszarze storeSettings.
Zobacz szczegóły w artykule dotyczącym łącznika —> sekcja właściwości działanie Kopiuj. |
Nie. |
Parquet jako ujście
Następujące właściwości są obsługiwane w sekcji działanie kopiowania *ujście*.
| Właściwości | Opis | Wymagania |
|---|---|---|
| typ | Właściwość type ujścia działania kopiowania musi być ustawiona na ParquetSink. | Tak |
| formatUstawienia | Grupa właściwości. Zapoznaj się z poniższą tabelą ustawień zapisu Parquet. | Nie. |
| storeSettings | Grupa właściwości dotyczących sposobu zapisywania danych w magazynie danych. Każdy łącznik oparty na plikach ma własne obsługiwane ustawienia zapisu w obszarze storeSettings.
Zobacz szczegóły w artykule dotyczącym łącznika —> sekcja właściwości działanie Kopiuj. |
Nie. |
Obsługiwane ustawienia zapisu Parquet w obszarze formatSettings:
| Właściwości | Opis | Wymagania |
|---|---|---|
| typ | Typ formatUstawienia musi być ustawiony na ParquetWriteSettings. | Tak |
| maxRowsPerFile | Podczas zapisywania danych w folderze można wybrać zapisywanie w wielu plikach i określić maksymalną liczbę wierszy na plik. | Nie. |
| fileNamePrefix | Dotyczy konfiguracji maxRowsPerFile .Określ prefiks nazwy pliku podczas zapisywania danych w wielu plikach, co spowodowało następujący wzorzec: <fileNamePrefix>_00000.<fileExtension>. Jeśli nie zostanie określony, prefiks nazwy pliku zostanie wygenerowany automatycznie. Ta właściwość nie ma zastosowania, gdy źródło jest magazynem opartym na plikach lub magazynem danych z włączoną opcją partycji. |
Nie. |
Właściwości przepływu mapowania danych
W przepływach danych mapowania można odczytywać i zapisywać w formacie parquet w następujących magazynach danych: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 i SFTP, a format parquet można odczytywać w usłudze Amazon S3.
Właściwości źródła
W poniższej tabeli wymieniono właściwości obsługiwane przez źródło parquet. Te właściwości można edytować na karcie Opcje źródła.
| Nazwa/nazwisko | Opis | Wymagania | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Formatuj | Format musi być następujący: parquet |
tak | parquet |
format |
| Ścieżki z symbolami wieloznacznymi | Wszystkie pliki pasujące do ścieżki wieloznacznej zostaną przetworzone. Zastępuje folder i ścieżkę pliku ustawioną w zestawie danych. | nie | Ciąg[] | symbole wieloznacznePaths |
| Ścieżka główna partycji | W przypadku danych plików podzielonych na partycje można wprowadzić ścieżkę katalogu głównego partycji, aby odczytywać foldery podzielone na partycje jako kolumny | nie | String | partitionRootPath |
| Lista plików | Czy źródło wskazuje plik tekstowy, który wyświetla listę plików do przetworzenia | nie |
true lub false |
fileList |
| Kolumna do przechowywania nazwy pliku | Utwórz nową kolumnę z nazwą pliku źródłowego i ścieżką | nie | String | rowUrlColumn |
| Po zakończeniu | Usuń lub przenieś pliki po przetworzeniu. Ścieżka pliku rozpoczyna się od katalogu głównego kontenera | nie | Usuń: true lub false Ruszać: [<from>, <to>] |
przeczyszczanie plików moveFiles |
| Filtruj według ostatniej modyfikacji | Wybierz filtrowanie plików w oparciu o czas ich ostatniej zmiany | nie | Sygnatura czasowa | modifiedAfter modifiedBefore |
| Zezwalaj na brak znalezionych plików | Jeśli wartość true, błąd nie jest zgłaszany, jeśli nie znaleziono żadnych plików | nie |
true lub false |
ignoreNoFilesFound |
Przykład źródła
Na poniższej ilustracji przedstawiono przykład konfiguracji źródła parquet w przepływach danych mapowania.
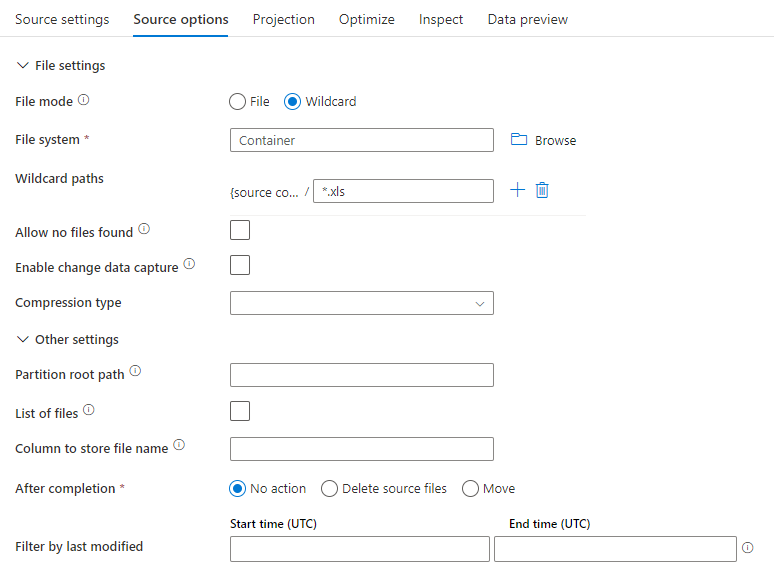
Skojarzony skrypt przepływu danych to:
source(allowSchemaDrift: true,
validateSchema: false,
rowUrlColumn: 'fileName',
format: 'parquet') ~> ParquetSource
Właściwości ujścia
W poniższej tabeli wymieniono właściwości obsługiwane przez ujście parquet. Te właściwości można edytować na karcie Ustawienia .
| Nazwa/nazwisko | Opis | Wymagania | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Formatuj | Format musi być następujący: parquet |
tak | parquet |
format |
| Wyczyść folder | Jeśli folder docelowy zostanie wyczyszczone przed zapisem | nie |
true lub false |
obcinać |
| Opcja Nazwa pliku | Format nazewnictwa zapisanych danych. Domyślnie jeden plik na partycję w formacie part-#####-tid-<guid> |
nie | Wzorzec: ciąg Na partycję: Ciąg[] Jako dane w kolumnie: Ciąg Dane wyjściowe do pojedynczego pliku: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Przykład ujścia
Na poniższej ilustracji przedstawiono przykład konfiguracji ujścia parquet w przepływach danych mapowania.

Skojarzony skrypt przepływu danych to:
ParquetSource sink(
format: 'parquet',
filePattern:'output[n].parquet',
truncate: true,
allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> ParquetSink
Mapowanie typów danych dla Parquet
Podczas odczytywania danych z łącznika źródłowego w formacie Parquet następujące mapowania są używane z typów danych Parquet do tymczasowych typów danych używanych przez usługę wewnętrznie.
| Typ Parquet | Typ danych usługi tymczasowej |
|---|---|
| BOOLEAN | logiczny |
| INT_8 | SByte |
| INT_16 | Int16 |
| INT_32 | Int32 |
| INT_64 | Int64 |
| INT96 | DateTime |
| UINT_8 | Byte |
| UINT_16 | UInt16 |
| UINT_32 | UInt32 |
| UINT_64 | UInt64 |
| DZIESIĘTNA | Decimal |
| FLOAT | Single |
| Podwójny | Double |
| DATE | Date |
| TIME_MILLIS | TimeSpan |
| TIME_MICROS | Int64 |
| TIMESTAMP_MILLIS | DateTime |
| TIMESTAMP_MICROS | Int64 |
| STRING | String |
| UTF8 | String |
| ENUM | Tablica bajtów |
| UUID | Tablica bajtów |
| JSON | Tablica bajtów |
| BSON | Tablica bajtów |
| BINARY | Tablica bajtów |
| FIXED_LEN_BYTE_ARRAY | Tablica bajtów |
Podczas zapisywania danych do łącznika ujścia w formacie Parquet następujące mapowania są używane z tymczasowych typów danych używanych przez usługę wewnętrznie do typów danych Parquet.
| Typ danych usługi tymczasowej | Typ Parquet |
|---|---|
| logiczny | BOOLEAN |
| SByte | INT_8 |
| Int16 | INT_32 |
| Int32 | INT_32 |
| Int64 | INT_64 |
| Byte | INT_32 |
| UInt16 | INT_32 |
| UInt32 | INT_64 |
| UInt64 | DZIESIĘTNA |
| Decimal | DZIESIĘTNA |
| Single | FLOAT |
| Double | Podwójny |
| Date | DATE |
| DateTime | INT96 |
| DateTimeOffset | INT96 |
| TimeSpan | INT96 |
| String | UTF8 |
| GUID | UTF8 |
| Tablica bajtów | BINARY |
Aby dowiedzieć się, jak działanie kopiowania mapuje schemat źródłowy i typ danych na docelowy, zobacz Mapowanie schematu i typu danych.
Złożone typy danych Parquet (np. MAP, LIST, STRUCT) są obecnie obsługiwane tylko w Przepływ danych, a nie w działaniu kopiowania. Aby używać złożonych typów w przepływach danych, nie importuj schematu pliku w zestawie danych, pozostawiając schemat pusty w zestawie danych. Następnie w transformacji Źródło zaimportuj projekcję.