Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym samouczku użyjesz interfejsu użytkownika usługi Azure Data Factory do utworzenia potoku danych, który kopiuje dane z bazy danych programu SQL Server do usługi Azure Blob Storage. Utworzysz i użyjesz samodzielnie hostowanego środowiska uruchomieniowego integracji, które umożliwia transfer danych między lokalnym a chmurowym magazynem danych.
Uwaga
Ten artykuł nie zawiera szczegółowego wprowadzenia do usługi Data Factory. Aby uzyskać więcej informacji, zobacz Wprowadzenie do usługi Azure Data Factory.
Ten samouczek obejmuje wykonanie następujących kroków:
- Tworzenie fabryki danych.
- Utwórz samodzielnie hostowane środowisko Integration Runtime.
- Tworzenie połączonych zestawów programu SQL Server i usługi Azure Storage.
- Tworzenie zestawów danych programu SQL Server i usługi Azure Blob.
- Utwórz potok z aktywnością kopiowania do przenoszenia danych.
- Uruchom przepływ pracy.
- Monitoruj przebieg potoku.
Wymagania wstępne
Subskrypcja platformy Azure
Jeśli nie masz jeszcze subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Role na platformie Azure
Aby utworzyć wystąpienia usługi Data Factory, konto użytkownika używane do logowania się na platformie Azure musi mieć przypisaną rolę współautora lub właściciela albo być administratorem subskrypcji platformy Azure.
Aby wyświetlić swoje uprawnienia do subskrypcji, przejdź do witryny Azure Portal. W prawym górnym rogu wybierz swoją nazwę użytkownika, a następnie wybierz pozycję Uprawnienia. Jeśli masz dostęp do wielu subskrypcji, wybierz odpowiednią subskrypcję. Aby uzyskać przykładowe instrukcje dotyczące dodawania użytkownika do roli, zobacz Przypisywanie ról platformy Azure przy użyciu witryny Azure Portal.
Program SQL Server 2014, 2016 oraz 2017
W tym samouczku użyjesz bazy danych programu SQL Server jako źródłowego magazynu danych. Potok danych w fabryce przetwarzania danych utworzony w tym samouczku kopiuje dane z tej bazy danych SQL Server (źródła) do magazynu Blob (ujścia). Następnie utworzysz tabelę o nazwie emp w bazie danych programu SQL Server i wstawisz kilka przykładowych wpisów do tabeli.
Uruchom program SQL Server Management Studio. Jeśli program nie jest jeszcze zainstalowany na używanej maszynie, przejdź do strony pobierania programu SQL Server Management Studio.
Połącz się z instancją SQL Server przy użyciu swoich poświadczeń.
Utwórz przykładową bazę danych. W widoku drzewa kliknij prawym przyciskiem myszy pozycję Bazy danych, a następnie wybierz pozycję Nowa baza danych.
W oknie Nowa baza danych wprowadź nazwę bazy danych, a następnie wybierz przycisk OK.
Aby utworzyć tabelę emp i wstawić do niej przykładowe dane, uruchom następujący skrypt zapytania w bazie danych. W widoku drzewa kliknij prawym przyciskiem myszy utworzoną bazę danych, a następnie wybierz pozycję Nowe zapytanie.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe') INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe') GO
Konto magazynu Azure
W tym samouczku używasz ogólnego konta usługi Azure Storage (dokładniej, usługi Blob storage) jako docelowego lub wyjściowego magazynu danych. Jeśli nie masz konta usługi Azure Storage ogólnego przeznaczenia, zobacz Tworzenie konta magazynu. Potok w fabryce danych utworzony w tym samouczku kopiuje dane z bazy danych programu SQL Server (źródła) do magazynu obiektów blob (ujścia).
Uzyskaj nazwę konta magazynu i jego klucz
W tym samouczku używasz nazwy i klucza swojego konta magazynowego. Aby uzyskać nazwę i klucz konta pamięci masowej, wykonaj następujące kroki:
Zaloguj się do witryny Azure Portal przy użyciu nazwy użytkownika i hasła do konta platformy Azure.
W lewym okienku wybierz pozycję Wszystkie usługi. Zastosuj filtrowanie według słowa kluczowego Storage, a następnie wybierz pozycję Konta Storage.

W razie potrzeby przefiltruj listę kont magazynu, aby znaleźć swoje konto magazynu. Następnie wybierz swoje konto pamięci masowej.
W oknie Konto magazynu wybierz pozycję Klucze dostępu.
Skopiuj wartości z pól Nazwa konta magazynowego i Klucz1 i wklej je do Notatnika lub innego edytora do późniejszego użycia w tym samouczku.
Tworzenie kontenera adftutorial
W tej sekcji utworzysz kontener obiektów blob o nazwie adftutorial w usłudze Blob Storage.
W oknie Konto magazynu przejdź do pozycji Przegląd, a następnie wybierz pozycję Kontenery.
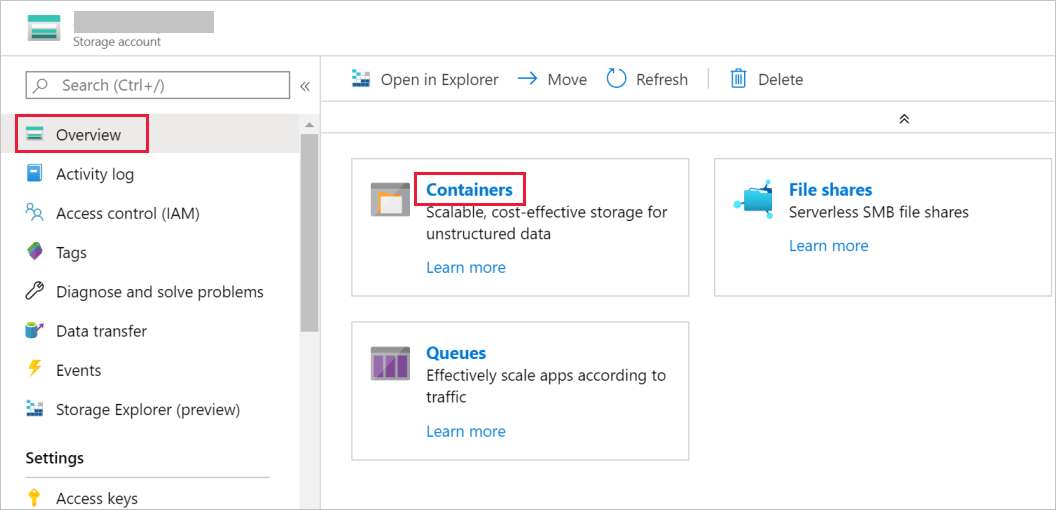
W oknie Kontenery wybierz pozycję + Kontener, aby utworzyć nowy.
W oknie Nowy kontener w polu Nazwa wprowadź wartość adftutorial. Następnie wybierz Utwórz.
Na liście kontenerów wybierz właśnie utworzoną pozycję adftutorial .
Pozostaw otwarte okno kontenera o nazwie adftutorial. Służy do weryfikowania danych wyjściowych na końcu samouczka. Usługa Data Factory automatycznie tworzy folder wyjściowy w tym kontenerze, więc Ty nie musisz go tworzyć.
Tworzenie fabryki danych
W tym kroku utworzysz centrum danych i uruchomisz interaktywny interfejs użytkownika usługi Data Factory, aby utworzyć potok w centrum danych.
Otwórz przeglądarkę internetową Microsoft Edge lub Google Chrome. Obecnie interfejs użytkownika usługi Data Factory jest obsługiwany tylko przez przeglądarki internetowe Microsoft Edge i Google Chrome.
W górnym menu wybierz pozycję Utwórz zasób>Analityka>Data Factory

Na stronie Nowa fabryka danych w polu Nazwa wprowadź wartość ADFTutorialDataFactory.
Nazwa fabryki danych musi być globalnie unikatowa. Jeśli dla pola nazwy zobaczysz poniższy komunikat o błędzie, zmień nazwę fabryki danych (np. twojanazwaADFTutorialDataFactory). Reguły nazewnictwa dla artefaktów usługi Data Factory można znaleźć w artykule Data Factory — reguły nazewnictwa.

Wybierz subskrypcję platformy Azure, w której chcesz utworzyć fabrykę danych.
W obszarze Grupa zasobów wykonaj jedną z następujących czynności:
Wybierz pozycję Użyj istniejącej, a następnie wybierz istniejącą grupę zasobów z listy rozwijanej.
Wybierz pozycję Utwórz nową, a następnie wprowadź nazwę grupy zasobów.
Informacje na temat grup zasobów znajdują się w artykule Using resource groups to manage your Azure resources (Używanie grup zasobów do zarządzania zasobami platformy Azure).
W obszarze Wersja wybierz pozycję V2.
W obszarze Lokalizacja wybierz lokalizację fabryki danych. Na liście rozwijanej są wyświetlane tylko obsługiwane lokalizacje. Magazyny danych (np. usługi Storage i SQL Database) oraz jednostki obliczeniowe (np. usługa Azure HDInsight) używane przez usługę Data Factory mogą mieścić się w innych regionach.
Wybierz pozycję Utwórz.
Po zakończeniu tworzenia zostanie wyświetlona strona Fabryka danych, jak pokazano na poniższej ilustracji:

Wybierz Otwórz na kafelku Open Azure Data Factory Studio, aby uruchomić interfejs użytkownika Data Factory na osobnej karcie.
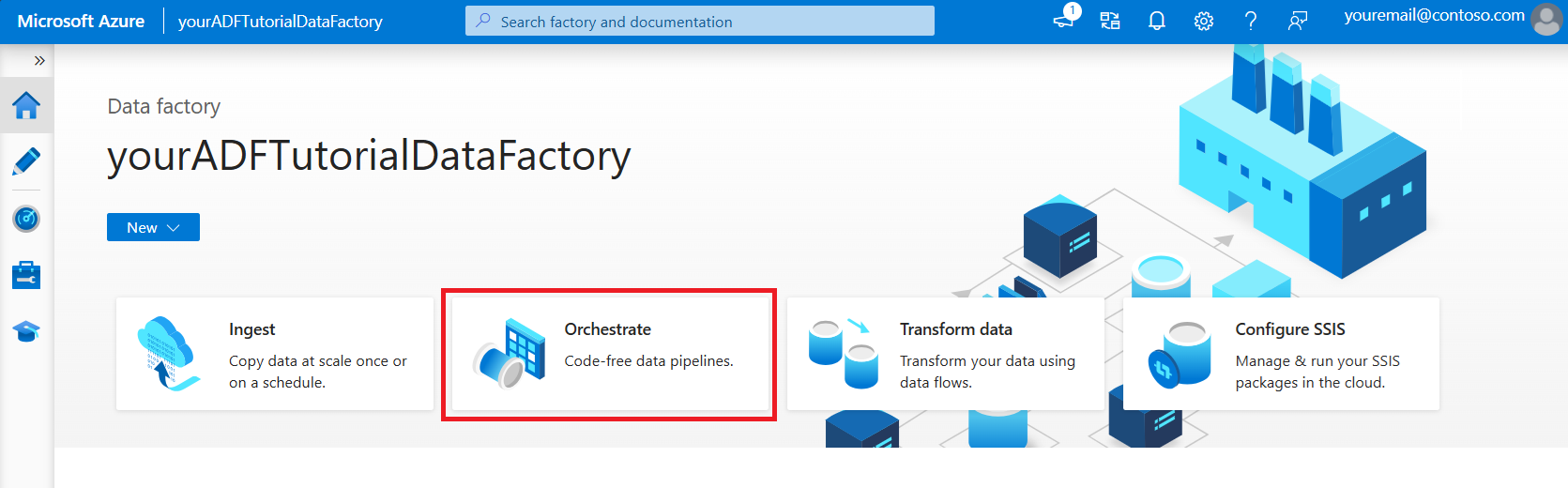
Utwórz potok
Na stronie głównej usługi Azure Data Factory wybierz pozycję Orkiestruj. Przepływ jest tworzony automatycznie. Widzisz potok danych w widoku drzewa, a jego edytor otwiera się.
W panelu Ogólne w obszarze Właściwości określ wartość SQLServerToBlobPipeline w polu Nazwa. Następnie zwiń panel, klikając ikonę Właściwości w prawym górnym rogu.
W skrzynce narzędziowej Działania rozwiń węzeł Przenieś i przekształć. Przeciągnij i upuść działanie Kopiowanie na powierzchnię projektowania potoku. Ustaw nazwę działania na wartość CopySqlServerToAzureBlobActivity.
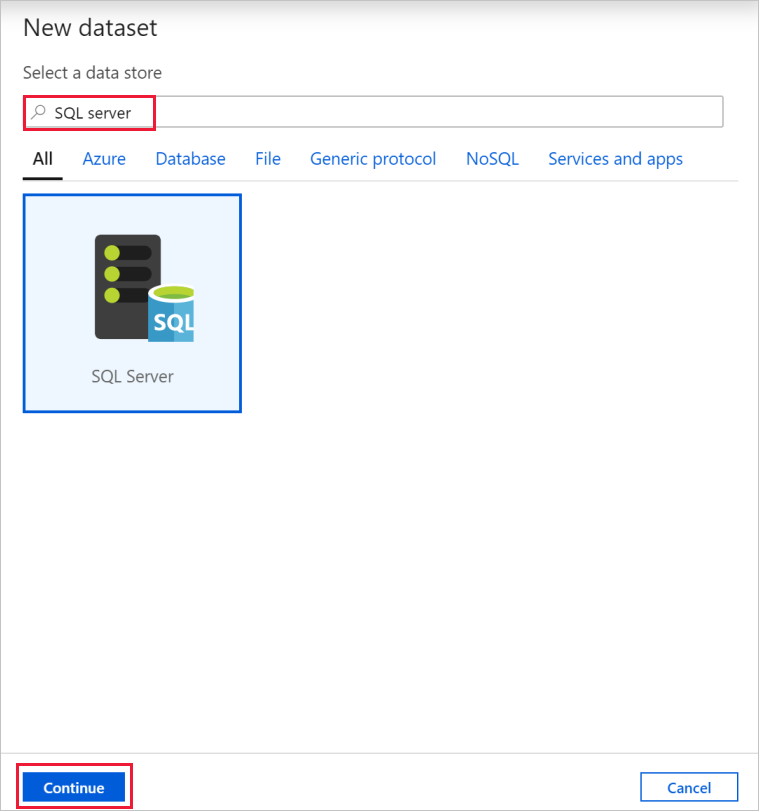
W oknie Właściwości przejdź do karty Źródło i wybierz pozycję + Nowy.
W oknie dialogowym Nowy zestaw danych wyszukaj pozycję SQL Server. Wybierz pozycję SQL Server, a następnie wybierz pozycję Kontynuuj.
W oknie dialogowym Ustawianie właściwości w obszarze Nazwa wprowadź wartość SqlServerDataset. W obszarze Połączona usługa wybierz pozycję + Nowy. W tym kroku tworzone jest połączenie z magazynem danych źródłowych (bazą danych programu SQL Server).
W oknie dialogowym Nowa połączona usługa dodaj nazwę jako SqlServerLinkedService. W obszarze Połącz za pośrednictwem środowiska Integration Runtime wybierz pozycję +Nowy. W tej sekcji utworzysz własne środowisko Integration Runtime i skojarzysz je z maszyną lokalną za pomocą bazy danych programu SQL Server. Własne środowisko Integration Runtime jest składnikiem, który kopiuje dane z bazy danych programu SQL Server na Twojej maszynie do usługi Blob Storage.
W oknie dialogowym Konfiguracja środowiska Integration Runtime wybierz pozycję Self-Hosted, a następnie wybierz pozycję Kontynuuj.
W polu nazwy wprowadź TutorialIntegrationRuntime. Następnie wybierz Utwórz.
W obszarze Ustawienia wybierz pozycję Kliknij tutaj, aby uruchomić instalację ekspresową dla tego komputera. Ta akcja instaluje na komputerze środowisko Integration Runtime i rejestruje je w usłudze Data Factory. Ewentualnie można użyć opcji instalacji ręcznej w celu pobrania pliku instalacyjnego, uruchomienia go i zarejestrowania środowiska Integration Runtime za pomocą klucza.

W oknie Instalacji Ekspresowej środowiska Integration Runtime (self-hosted) wybierz opcję Zamknij, gdy proces się zakończy.

W oknie dialogowym Nowa połączona usługa (SQL Server) upewnij się, że w obszarze Połącz za pośrednictwem środowiska Integration Runtime wybrano pozycję TutorialIntegrationRuntime. Następnie wykonaj następujące czynności:
a. W polu Nazwa wprowadź wartość SqlServerLinkedService.
b. W polu Nazwa serwera wprowadź nazwę wystąpienia programu SQL Server.
c. W polu Nazwa bazy danych wprowadź nazwę bazy danych zawierającej tabelę emp.
d. W polu Typ uwierzytelniania wybierz odpowiedni typ uwierzytelniania, którego usługa Data Factory powinna używać do nawiązania połączenia z bazą danych SQL Server.
e. W polach Nazwa użytkownika i Hasło wprowadź nazwę użytkownika i hasło. W razie potrzeby użyj nazwy użytkownika mydomain\myuser .
f. Wybierz pozycję Testuj połączenie. Ten krok polega na potwierdzeniu, że usługa Data Factory może nawiązać połączenie z bazą danych programu SQL Server przy użyciu utworzonego własnego środowiska Integration Runtime.
g. Aby zapisać połączoną usługę, wybierz pozycję Utwórz.

Po utworzeniu połączonej usługi jesteś z powrotem na stronie Ustawianie właściwości dla SqlServerDataset. Wykonaj następujące czynności:
a. W Połączonej usłudze upewnij się, że widzisz SqlServerLinkedService.
b. W obszarze Table name wybierz pozycję [dbo].[emp].
c. Wybierz przycisk OK.
Przejdź do karty SQLServerToBlobPipeline albo wybierz SQLServerToBlobPipeline w widoku drzewa.
Przejdź do karty Zlew u dołu okna Właściwości i wybierz + Nowy.
W oknie dialogowym Nowy zestaw danych wybierz pozycję Azure Blob Storage. Następnie wybierz pozycję Kontynuuj.
W oknie dialogowym Wybieranie formatu wybierz typ formatu danych. Następnie wybierz pozycję Kontynuuj.

W oknie dialogowym Ustawianie właściwości wprowadź wartość AzureBlobDataset w polu Nazwa. Kliknij pozycję + Nowy obok pola tekstowego Połączona usługa.
W oknie dialogowym Nowa połączona usługa (Azure Blob Storage) wprowadź nazwę AzureStorageLinkedService, wybierz konto magazynu z listy nazw kont magazynu. Przetestuj połączenie, a następnie wybierz pozycję Utwórz , aby wdrożyć połączoną usługę.
Po utworzeniu połączonej usługi wracasz na stronę Ustawianie właściwości. Wybierz przycisk OK.
Otwórz zbiór danych zlewu. Na karcie Połączenie wykonaj następujące kroki:
a. Upewnij się, że w polu Połączona usługa wybrano wartość AzureStorageLinkedService.
b. W polu Ścieżka pliku wprowadź adftutorial/fromonprem dla części kontener/katalog. Jeśli folder wyjściowy nie istnieje w kontenerze adftutorial, usługa Data Factory automatycznie utworzy folder wyjściowy.
c. W części Plik wybierz pozycję Dodaj zawartość dynamiczną.

d. Dodaj
@CONCAT(pipeline().RunId, '.txt'), a następnie wybierz Zakończ. Ta akcja spowoduje zmianę nazwy pliku na PipelineRunID.txt.Przejdź na kartę z otwartym potokiem lub wybierz potok w widoku drzewa. Upewnij się, że w Zestaw danych docelowy wybrano AzureBlobDataset.
Aby zweryfikować poprawność ustawień potoku, wybierz pozycję Weryfikuj na pasku narzędzi dla potoku. Aby zamknąć dane wyjściowe weryfikacji potoku

Aby opublikować jednostki utworzone w usłudze Data Factory, wybierz pozycję Opublikuj wszystko.
Poczekaj, aż pojawi się okno podręczne z komunikatem "Publikowanie zostało ukończone". Aby sprawdzić stan publikowania, wybierz link Pokaż powiadomienia w górnej części okna. Aby zamknąć okno powiadomienia, wybierz Close.
Wyzwalanie uruchomienia potoku
Wybierz pozycję Dodaj wyzwalacz na pasku narzędzi potoku, a następnie wybierz pozycję Wyzwól teraz.
Monitoruj przepływ
Przejdź do karty Monitorowanie . W poprzednim kroku zostanie wyświetlony potok, który został ręcznie wyzwolony.
Aby wyświetlić uruchomienia działań skojarzone z uruchomieniem potoku, wybierz link SQLServerToBlobPipeline w sekcji NAZWA POTOKU.

Na stronie z uruchomieniami działań wybierz link Szczegóły (obraz okularów), aby wyświetlić informacje dotyczące operacji kopiowania. Aby wrócić do widoku Uruchomienia procesów, wybierz u góry pozycję Wszystkie uruchomienia procesów.
Sprawdzanie danych wyjściowych
Potok danych automatycznie tworzy folder wyjściowy o nazwie fromonprem w kontenerze blob adftutorial. Upewnij się, że plik [pipeline().RunId].txt jest widoczny w folderze wyjściowym.
Powiązana zawartość
Potok w tym przykładzie kopiuje dane z jednej lokalizacji do innej w usłudze Blob Storage. Nauczyłeś się, jak:
- Tworzenie fabryki danych.
- Utwórz samodzielnie hostowane środowisko Integration Runtime.
- Tworzenie połączonych usług programu SQL Server i usługi Storage.
- Tworzenie zestawów danych programu SQL Server i usługi Blob Storage.
- Utwórz potok z aktywnością kopiowania do przenoszenia danych.
- Uruchom przepływ pracy.
- Monitoruj przebieg potoku.
Lista magazynów danych obsługiwanych przez usługę Data Factory znajduje się w artykule Obsługiwane magazyny danych.
Aby dowiedzieć się, jak zbiorczo kopiować dane z lokalizacji źródłowej do docelowej, przejdź do następującego samouczka: