Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Po przejrzeniu wymagań można rozpocząć tworzenie modelu przetwarzania dokumentów.
Tworzenie modelu za pomocą kreatora
Model przetwarzania dokumentów można utworzyć za pomocą kreatora Utwórz model niestandardowy. Kreator przeprowadzi użytkownika przez proces tworzenia modelu w celu wyodrębnienia informacji z dokumentów.
Zaloguj się w Power Apps lub Power Automate.
W lewym okienku wybierz ... Więcej>Centrum AI.
(Opcjonalnie) Aby zachować modele AI na stałe w menu i mieć do nich łatwy dostęp, wybierz ikonę pin obok Centrum AI.
W obszarze Poznaj funkcję AI wybierz Modele AI.
Wybierz Wyodrębniaj informacje niestandardowe z dokumentów.
Wybierz opcję Utwórz model niestandardowy.
Kreator krok po kroku zawiera listę wszystkich danych, które mają zostać wyodrębnione z dokumentu.
Więcej informacji można znaleźć w sekcji Wybierz typ dokumentu niniejszego artykułu.
Jeśli chcesz utworzyć model przy użyciu własnych dokumentów, upewnij się, że masz co najmniej pięć przykładów korzystających z tego samego układu. W przeciwnym razie możesz utworzyć model przy użyciu przykładowych danych.
Wybierz Szkolenie.
Przetestuj model, wybierając opcję Szybki test.
Wybierz typ dokumentu
W kroku Wybierz typ dokumentu wybierasz typ dokumentu, na podstawie którego chcesz zbudować model sztucznej inteligencji, aby zautomatyzować pobieranie danych. Dostępne są trzy opcje: Dokumenty ze stałymi szablonami, Dokumenty ogólne i Faktury.
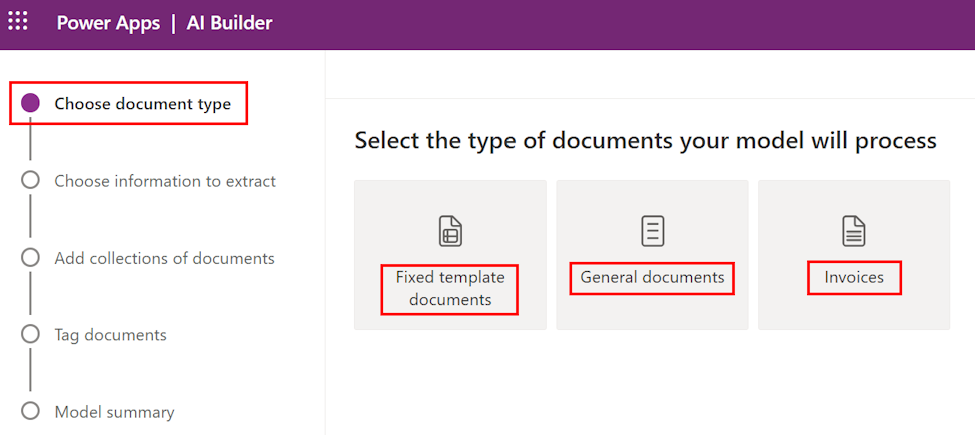
- Dokumenty ze stałym szablonem: Opcja ta, znana wcześniej jako Structured, jest idealna, gdy dla danego układu pola, tabele, pola wyboru, podpisy i inne produkty znajdują się w podobnych miejscach. Model ten można wykorzystać do wyodrębniania danych z ustrukturyzowanych dokumentów o różnych układach. Model ten charakteryzuje się krótkim czasem szkolenia.
- Dokumenty ogólne: ta opcja, wcześniej znana jako Niestrukturalne, jest idealna dla każdego rodzaju dokumentów, zwłaszcza gdy nie ma ustalonej struktury lub gdy format jest złożony. Model ten można wykorzystać do wyodrębniania danych z ustrukturyzowanych lub nieustrukturyzowanych dokumentów o różnych układach. Model ten jest wydajny, ale wymaga długiego czasu szkolenia.
- Faktury: rozszerzenie zachowania wstępnie zbudowanego modelu przetwarzania faktur poprzez dodanie nowych pól do wyodrębnienia oprócz pól domyślnych lub próbek dokumentów, które nie zostały prawidłowo wyodrębnione.
Zrozumienie wersji inteligencji dokumentów
Model analiz dokumentów jest dostępny w dwóch wersjach: v4.0 i v3.1. Wersja modelu zależy od daty ostatniej edycji modelu.
Document Intelligence v4.0 – ogólna dostępność (GA)
Oprócz funkcji wymienionych w tym artykule wersja 4.0 zachowuje wszystkie możliwości wersji 3.1.
- Nakładające się pola: wersja 4.0 obsługuje nakładające się pola w modelach niestandardowych, co umożliwia efektywniejsze wyodrębnianie informacji z dokumentów o złożonych układach.
- Wykrywanie podpisów: wersja 4.0 wykrywa podpisy w dokumentach, co jest szczególnie przydatne w przypadku umów, porozumień i innych podpisanych formularzy.
- Współczynniki ufności dla tabel: wersja 4.0 zawiera współczynniki ufności dla tabeli i ich komórek.
- Ulepszenia mechanizmu OCR: wersja 4.0 ulepsza mechanizm optycznego rozpoznawania znaków (OCR), zwiększając dokładność rozpoznawania tekstu i obsługując więcej typów i formatów dokumentów.
Document Intelligence v3.1 – ogólna dostępność (GA)
- Wersja 3.1 obsługuje modele niestandardowe wytrenowane w celu rozpoznawania określonych wzorców danych, takich jak unikatowe pola tekstowe lub struktury.
- Wersja 3.1 zawiera niestandardowe modele szablonów, które umożliwiają użytkownikom tworzenie szablonów na podstawie układu i struktury dokumentu.
Sprawdź wersję modelu
Możesz sprawdzić wersję używaną do trenowania i publikowania modelu. W tym celu wybierz pozycję Ustawienia> Opublikowana wersja modelu> Ostatnia wytrenowana wersja modelu.
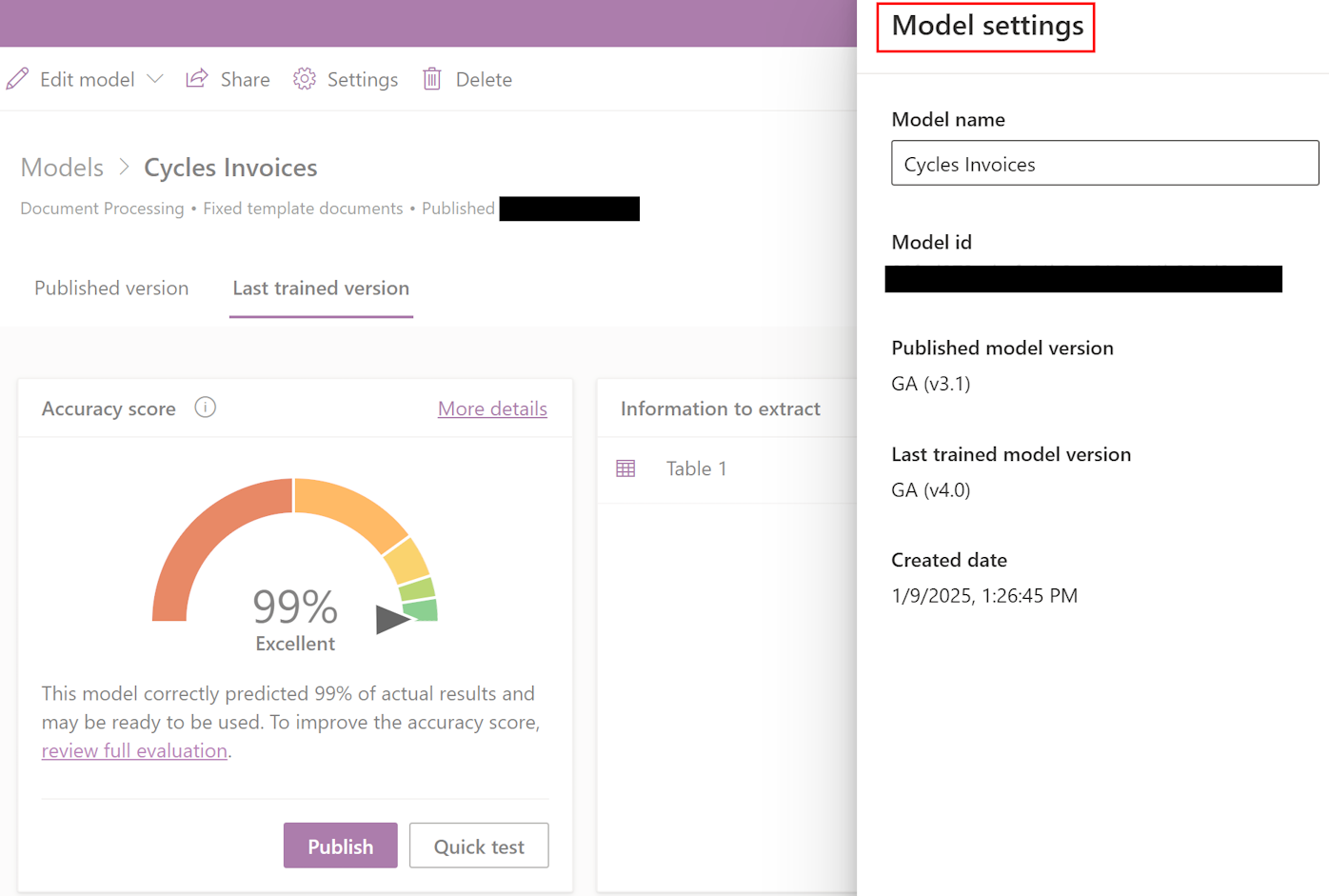
Model można przenieść z wersji 3.1 do wersji 4.0, edytując, ponownie trenując i publikując. Ponowne tagowanie i inne konkretne modyfikacje nie są konieczne. Dowiedz się więcej: Niestandardowy model przetwarzania dokumentów – FAQ.
Określ informacje do wyodrębnienia
Na ekranie Wybierz informacje do wyodrębnienia definiuje się pola, tabele i pola wyboru, które mają zostać wyodrębnione z modelu. Aby rozpocząć definiowanie tych elementów, wybierz +Dodaj.

Dla każdego pola tekstowego podaj nazwę pola do użycia w modelu.
Dla każdego pola numerycznego podaj nazwę pola do użycia w modelu.
Zdefiniuj format kropka (.) lub przecinek (,) jako separator dziesiętny.
Dla każdego pola daty podaj nazwę pola do użycia w modelu.
Dodatkowo zdefiniuj format daty (Rok, Miesiąc, Dzień) lub (Miesiąc, Dzień, Rok) lub (Dzień, Miesiąc, Rok)
Dla każdego pola wyboru podaj nazwę pola wyboru do użycia w modelu.
Zdefiniuj oddzielne pola wyboru dla każdego elementu, który można sprawdzić w dokumencie.
W przypadku każdej tabeli podaj nazwę tabeli.
Należy również zdefiniować różne kolumny, które mają zostać wyodrębnione z modelu.
Uwaga
Model niestandardowych faktur jest dostarczany z polami domyślnymi, których nie można edytować.
Grupowanie dokumentów według kolekcji
Kolekcja to grupa dokumentów, które mają ten sam układ. Utwórz dowolną liczbę kolekcji jako układy dokumentów, które mają zostać przetworzone przez model. Na przykład, jeśli tworzysz model AI w celu przetwarzania faktur od dwóch różnych dostawców, z których każdy ma własny szablon faktury, utwórz dwie kolekcje.
Dla każdej tworzonej kolekcji należy przekazać co najmniej pięć przykładowych dokumentów na jedną kolekcję. Pliki z formatami JPG, PNG i PDF są obecnie akceptowane.
Notatka
Można tworzyć do 200 zbiorów na model.
Następny krok
Oznaczanie dokumentów w modelu przetwarzania dokumentów