Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule wdrożysz obciążenie platformy AWS EDW na platformie Azure.
Zaloguj się do Azure
Zaloguj się do platformy Azure przy użyciu polecenia
az login.az loginJeśli twoje konto platformy Azure ma wiele subskrypcji, upewnij się, że wybrano poprawną subskrypcję. Wyświetl nazwy i identyfikatory subskrypcji przy użyciu
az account listpolecenia .az account list --query "[].{id: id, name:name }" --output tableWybierz określoną subskrypcję przy użyciu
az account setpolecenia .az account set --subscription $subscriptionId
Skrypt wdrażania obciążenia EDW
Przejrzyj zmienne środowiskowe w pliku deployment/environmentVariables.sh , a następnie użyjesz skryptu deploy.sh w deployment/infra/ katalogu repozytorium GitHub , aby wdrożyć aplikację na platformie Azure.
Skrypt najpierw sprawdza, czy są zainstalowane wszystkie narzędzia wymagań wstępnych . Jeśli nie, skrypt zakończy działanie i wyświetli komunikat o błędzie informujący o braku wymagań wstępnych. Jeśli tak się stanie, przejrzyj wymagania wstępne, zainstaluj wszystkie brakujące narzędzia, a następnie uruchom skrypt ponownie. Flaga Node autoprovisioning (NAP) dla usługi AKS musi być zarejestrowana na subskrypcji platformy Azure. Jeśli jeszcze nie jest zarejestrowany, skrypt wykonuje polecenie Azure CLI, aby zarejestrować flagę funkcji.
Skrypt rejestruje stan wdrożenia w pliku o nazwie deploy.state, który znajduje się w deployment katalogu. Za pomocą tego pliku można ustawić zmienne środowiskowe podczas wdrażania aplikacji.
Gdy skrypt wykonuje polecenia w celu skonfigurowania infrastruktury dla przepływu pracy, sprawdza, czy każde polecenie zostanie wykonane pomyślnie. Jeśli wystąpią jakiekolwiek problemy, zostanie wyświetlony komunikat o błędzie i wykonanie zostanie zatrzymane.
Skrypt wyświetla dziennik podczas jego uruchamiania. Dziennik można utrwalać, przekierowując dane wyjściowe informacji dziennika i zapisując je do install.log pliku w logs katalogu przy użyciu następujących poleceń:
mkdir ./logs
./deployment/infra/deploy.sh | tee ./logs/install.log
Aby uzyskać więcej informacji, zobacz ./deployment/infra/deploy.sh skrypt w naszym repozytorium GitHub.
Zasoby obciążenia
Skrypt wdrażania tworzy następujące zasoby platformy Azure:
Grupa zasobów platformy Azure: grupa zasobów platformy Azure , w której są przechowywane zasoby utworzone przez skrypt wdrażania.
Konto usługi Azure Storage: konto usługi Azure Storage, które zawiera kolejkę, w której komunikaty są wysyłane przez aplikację producenta i odczytywane przez aplikację odbiorcy, oraz tabelę, w której aplikacja konsumenta przechowuje przetworzone komunikaty.
Rejestr kontenerów platformy Azure: rejestr kontenerów udostępnia repozytorium dla kontenera, który wdraża refaktoryzowany kod aplikacji konsumenckiej.
Klaster usługi Azure Kubernetes Service (AKS): klaster usługi AKS udostępnia orkiestrację kubernetes dla kontenera aplikacji konsumenckiej i ma włączone następujące funkcje:
- Automatyczne aprowizowanie węzłów (NAP): implementacja skalowacza węzłów Karpenter w AKS.
- Skalowanie automatyczne oparte na zdarzeniach platformy Kubernetes (KEDA): KEDA umożliwia skalowanie zasobników na podstawie zdarzeń, takich jak przekroczenie określonego progu głębokości kolejki.
- Tożsamość obciążenia roboczego: umożliwia dołączanie polityk dostępu opartych na rolach do tożsamości podów w celu zapewnienia zwiększonych zabezpieczeń.
- Dołączony rejestr kontenerów platformy Azure: ta funkcja umożliwia klastrowi usługi AKS ściąganie obrazów z repozytoriów w określonym wystąpieniu usługi ACR.
Pula aplikacji i węzłów systemowych: skrypt tworzy również pulę węzłów aplikacji i systemu w klastrze usługi AKS, która ma defekt, aby zapobiec zaplanowaniu zasobników aplikacji w puli węzłów systemowych.
Tożsamość zarządzana klastra usługi AKS: skrypt przypisuje tę rolę do tej tożsamości zarządzanej, co ułatwia dostęp do dołączonego rejestru kontenerów platformy Azure na potrzeby pobierania obrazów.
Tożsamość obciążenia: skrypt przypisuje role Współautor danych kolejki magazynu i Współautor danych tabeli magazynu w celu zapewnienia dostępu opartego na rolach (RBAC) do tej tożsamości zarządzanej, która jest skojarzona z kontem usługi Kubernetes używanym jako tożsamość dla zasobników, na których są wdrażane kontenery aplikacji konsumenckich.
Dwa poświadczenia federacyjne – jedno poświadczenie umożliwia tożsamości zarządzanej wdrożenie tożsamości pod, a drugie poświadczenie jest używane dla konta usługi operatora KEDA w celu zapewnienia dostępu do skalera KEDA, aby zebrać metryki potrzebne do kontrolowania automatycznego skalowania podów.
Weryfikowanie wdrożenia i uruchomienie zadania
Po zakończeniu działania skryptu wdrażania można wdrożyć obciążenie w klastrze AKS.
Aby ustawić źródło do aktualizacji i zbierania zmiennych środowiskowych dla
./deployment/environmentVariables.sh, użyj następującego polecenia:source ./deployment/environmentVariables.shPotrzebne są informacje w pliku,
./deployment/deploy.stateaby ustawić zmienne środowiskowe dla nazw zasobów utworzonych we wdrożeniu. Wyświetl zawartość pliku przy użyciu następującegocatpolecenia:cat ./deployment/deploy.stateDane wyjściowe powinny zawierać następujące zmienne:
SUFFIX= RESOURCE_GROUP= AZURE_STORAGE_ACCOUNT_NAME= AZURE_QUEUE_NAME= AZURE_COSMOSDB_TABLE= AZURE_CONTAINER_REGISTRY_NAME= AKS_MANAGED_IDENTITY_NAME= AKS_CLUSTER_NAME= WORKLOAD_MANAGED_IDENTITY_NAME= SERVICE_ACCOUNT= FEDERATED_IDENTITY_CREDENTIAL_NAME= KEDA_SERVICE_ACCT_CRED_NAME=Przeczytaj plik i utwórz zmienne środowiskowe dla nazw zasobów platformy Azure utworzonych przez skrypt wdrażania przy użyciu następujących poleceń:
while IFS= read -r; line do \ echo "export $line" \ export $line; \ done < ./deployment/deploy.statePobierz poświadczenia klastra AKS za pomocą polecenia
az aks get-credentials.az aks get-credentials --resource-group $RESOURCE_GROUP --name $AKS_CLUSTER_NAMESprawdź, czy zasobniki operatora KEDA działają w przestrzeni nazw
kube-systemw klastrze AKS, używając poleceniakubectl get.kubectl get pods --namespace kube-system | grep kedaDane wyjściowe powinny wyglądać podobnie do następujących przykładowych danych wyjściowych:

Generowanie symulowanego obciążenia
Teraz wygenerujesz symulowane obciążenie przy użyciu aplikacji producenta, aby wypełnić kolejkę komunikatami.
W osobnym oknie terminalu przejdź do katalogu projektu.
Ustaw zmienne środowiskowe, wykonując kroki opisane w poprzedniej sekcji. 1. Uruchom aplikację producenta przy użyciu następującego polecenia:
python3 ./app/keda/aqs-producer.pyGdy aplikacja zacznie wysyłać komunikaty, wróć do innego okna terminalu.
Wdróż kontener aplikacji konsumenckich w klastrze usługi AKS przy użyciu następujących poleceń:
chmod +x ./deployment/keda/deploy-keda-app-workload-id.sh ./deployment/keda/deploy-keda-app-workload-id.shSkrypt wdrażania (
deploy-keda-app-workload-id.sh) generuje szablony w pliku YAML manifestu aplikacji, aby przekazać zmienne środowiskowe do poda. Zapoznaj się z następującym fragmentem tego skryptu:cat <<EOF | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: $AQS_TARGET_DEPLOYMENT namespace: $AQS_TARGET_NAMESPACE spec: replicas: 1 selector: matchLabels: app: aqs-reader template: metadata: labels: app: aqs-reader azure.workload.identity/use: "true" spec: serviceAccountName: $SERVICE_ACCOUNT containers: - name: keda-queue-reader image: ${AZURE_CONTAINER_REGISTRY_NAME}.azurecr.io/aws2azure/aqs-consumer imagePullPolicy: Always env: - name: AZURE_QUEUE_NAME value: $AZURE_QUEUE_NAME - name: AZURE_STORAGE_ACCOUNT_NAME value: $AZURE_STORAGE_ACCOUNT_NAME - name: AZURE_TABLE_NAME value: $AZURE_TABLE_NAME resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m" EOFEtykieta
azure.workload.identity/usew sekcjispec/templateto szablon jednostki dla wdrożenia. Ustawienie etykiety natruewskazuje, że używasz tożsamości obciążenia roboczego. Specyfikacja zasobnikaserviceAccountNameokreśla konto usługi Kubernetes, które ma być skojarzone z tożsamością obciążenia. Chociaż specyfikacja zasobnika zawiera odwołanie do obrazu w repozytorium prywatnym, nie maimagePullSecretokreślonej wartości.Sprawdź, czy skrypt został uruchomiony pomyślnie przy użyciu
kubectl getpolecenia .kubectl get pods --namespace $AQS_TARGET_NAMESPACEW danych wyjściowych powinna pojawić się pojedyncza instancja 'pod'.
Sprawdź, czy utworzono pulę węzłów Karpenter. Zrób to za pomocą
kubectl get nodepoolpolecenia . Odpowiedź polecenia będzie wyglądać następująco:
Sprawdź, czy domyślna pula węzłów jest pulą węzłów Karpenter przy użyciu
kubectl describe nodepoolpolecenia . W odpowiedzi na polecenie możesz zidentyfikować, czy pula węzłów jest pulą Karpenter. Powinna zostać wyświetlona zawartość podobna do następującej:


Monitorowanie rozszerzania w poziomie dla zasobów i węzłów za pomocą k9s
Za pomocą różnych narzędzi, w tym portalu Azure i narzędzia k9s, możesz zweryfikować działanie aplikacji wdrożonych w usłudze AKS. Aby uzyskać więcej informacji na temat k9s, zobacz k9s overview (Omówienie k9s).
Zainstaluj program k9s w klastrze usługi AKS, korzystając z odpowiednich wskazówek dotyczących środowiska w przeglądzie instalacji programu k9s.
Utwórz dwa okna, jeden z widokiem zasobników, a drugi z widokiem węzłów w przestrzeni nazw określonej w
AQS_TARGET_NAMESPACEzmiennej środowiskowej (wartość domyślna toaqs-demo) i uruchomić k9s w każdym oknie.Powinna zostać wyświetlona zawartość podobna do następującej:

Po potwierdzeniu, że kontener aplikacji konsumenckiej jest zainstalowany i działa w klastrze AKS, zainstaluj
ScaledObject, aby uruchomić uwierzytelnianie oraz wyzwalacz wykorzystywane przez KEDA do automatycznego skalowania zasobników, korzystając z uruchomienia skryptu instalacji skalowanego obiektu (keda-scaleobject-workload-id.sh). przy użyciu następujących poleceń:chmod +x ./deployment/keda/keda-scaleobject-workload-id.sh ./deployment/keda/keda-scaleobject-workload-id.shSkrypt wykonuje również tworzenie szablonów, aby w razie potrzeby wprowadzać zmienne środowiskowe. Zapoznaj się z następującym fragmentem tego skryptu:
cat <<EOF | kubectl apply -f - apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: aws2az-queue-scaleobj namespace: ${AQS_TARGET_NAMESPACE} spec: scaleTargetRef: name: ${AQS_TARGET_DEPLOYMENT} #K8s deployement to target minReplicaCount: 0 # We don't want pods if the queue is empty nginx-deployment maxReplicaCount: 15 # We don't want to have more than 15 replicas pollingInterval: 30 # How frequently we should go for metrics (in seconds) cooldownPeriod: 10 # How many seconds should we wait for downscale triggers: - type: azure-queue authenticationRef: name: keda-az-credentials metadata: queueName: ${AZURE_QUEUE_NAME} accountName: ${AZURE_STORAGE_ACCOUNT_NAME} queueLength: '5' activationQueueLength: '20' # threshold for when the scaler is active cloud: AzurePublicCloud --- apiVersion: keda.sh/v1alpha1 kind: TriggerAuthentication metadata: name: keda-az-credentials namespace: $AQS_TARGET_NAMESPACE spec: podIdentity: provider: azure-workload identityId: '${workloadManagedIdentityClientId}' EOFManifest opisuje dwa zasoby:
TriggerAuthenticationobiekt, który informuje KEDA, że skalowany obiekt używa pod identity do uwierzytelniania, orazidentityIDwłaściwość, która odnosi się do tożsamości zarządzanej używanej jako tożsamość obciążenia.Po poprawnej instalacji obiektu podlegającego skalowaniu i po wykryciu przez KEDA przekroczenia progu skalowania, rozpoczyna się przydzielanie podów. Jeśli używasz k9s, powinieneś zobaczyć coś takiego:

Jeśli zezwolisz producentowi na wypełnienie kolejki wystarczającą ilością komunikatów, KEDA może potrzebować zaplanować więcej podów niż jest dostępnych węzłów do obsługi. Aby to obsłużyć, Karpenter rozpocznie przydzielanie węzłów. Jeśli używasz k9s, powinieneś zobaczyć coś podobnego do tego:

Na tych dwóch obrazach zwróć uwagę, jak liczba węzłów, których nazwy zawierają
aks-default, wzrosły z jednego do trzech węzłów. Jeśli zatrzymasz aplikację producenta przed dodawaniem komunikatów do kolejki, w końcu konsumenci zmniejszą długość kolejki poniżej progu, a zarówno KEDA, jak i Karpenter będą skalowane w dół. Jeśli używasz k9s, powinieneś zobaczyć coś takiego:
Na koniec możesz wyświetlić aktywność automatycznego skalowania Karpenter przy użyciu
kubectl get eventspolecenia, jak pokazano poniżej: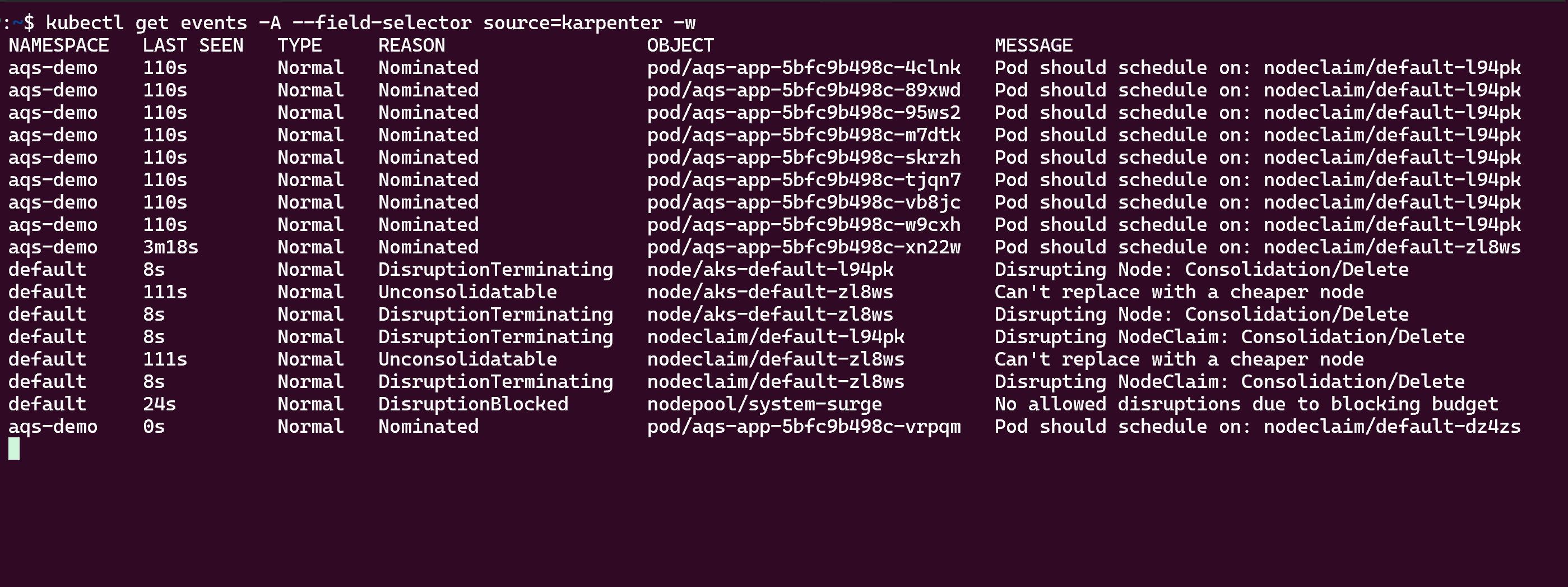





Uprzątnij zasoby
Możesz użyć skryptu oczyszczania (/deployment/infra/cleanup.sh) w naszym repozytorium GitHub , aby usunąć wszystkie utworzone zasoby.
Dalsze kroki
Aby uzyskać więcej informacji na temat tworzenia i uruchamiania aplikacji w usłudze AKS, zobacz następujące zasoby:
- Instalowanie istniejących aplikacji za pomocą narzędzia Helm w usłudze AKS
- Wdrażanie aplikacji Kubernetes i zarządzanie nią z witryny Azure Marketplace w usłudze AKS
- Wdrażanie aplikacji korzystającej z interfejsu OpenAI w usłudze AKS
Contributors
Firma Microsoft utrzymuje ten artykuł. Następujący autorzy pierwotnie napisali ten tekst:
- Ken Kilty | Główny TPM
- Russell de Pina | Główny Menedżer TPM
- Jenny Hayes | Starszy deweloper zawartości
- Carol Smith | Starszy deweloper zawartości
- Erin Schaffer | Content Developer 2