Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Uwaga
Obsługa tej wersji środowiska Databricks Runtime została zakończona. Aby uzyskać datę zakończenia pomocy technicznej, zobacz Historia zakończenia pomocy technicznej. Wszystkie obsługiwane wersje środowiska Databricks Runtime można znaleźć w temacie Databricks Runtime release notes versions and compatibility (Wersje i zgodność środowiska Databricks Runtime).
Usługa Databricks wydała tę wersję w październiku 2019 r.
Poniższe informacje o wersji zawierają informacje o środowisku Databricks Runtime 6.0 obsługiwanym przez platformę Apache Spark.
Nowe funkcje
Środowisko języka Python
Środowisko Databricks Runtime 6.0 zawiera istotne zmiany w języku Python i sposób konfigurowania środowisk języka Python, w tym uaktualnianie języka Python do wersji 3.7.3, uściślinie listy zainstalowanych pakietów języka Python i uaktualnianie zainstalowanych pakietów do nowszych wersji. Aby uzyskać szczegółowe informacje, zobacz Zainstalowane biblioteki języka Python.
Ponadto, jak wcześniej ogłoszono, środowisko Databricks Runtime 6.0 nie obsługuje języka Python 2.
Główne zmiany obejmują:
- Uaktualniono język Python z wersji 3.5.2 do wersji 3.7.3. Niektóre stare wersje pakietów języka Python mogą nie być zgodne z językiem Python 3.7, ponieważ zależą one od starych wersji narzędzia Cython, które nie są zgodne z językiem Python 3.7. Instalowanie takiego pakietu może wyzwalać błędy podobne do
'PyThreadState' {'struct _ts'} has no member named 'exc_type'(zobacz problem z usługą GitHub 1978 , aby uzyskać szczegółowe informacje). Zamiast tego, zainstaluj wersje pakietów Pythona zgodne z wersją 3.7. - Uaktualnienia głównych pakietów:
- boto3 do 1.9.162
- ipython do wersji 7.4.0
- matplotlib do wersji 3.0.3
- aktualizacja numpy do wersji 1.16.2
- biblioteka pandas wersja 0.24.2
- pyarrow do 0.13.0
- W porównaniu z środowiskiem Databricks Runtime 5.5 LTS (EoS) następujące pakiety języka Python zostały dodane: asn1crypto, backcall, jedi, kiwisolver, parso i PySocks.
- W porównaniu z środowiskiem Databricks Runtime 5.5 LTS (EoS) następujące pakiety języka Python nie są zainstalowane: ansi2html, brewer2mpl, colorama, configobj, enum34, et-xmlfile, freetype-py, funcsigs, fusepy, ggplot, html5lib, ipaddress, jdcal, Jinja2, llvmlite, lxml, MarkupSafe, mpld3, msgpack-python, ndg-httpsclient, numba, openpyxl, pathlib2, Pillow, ply, pyasn1, pypng, python-geohash, scour, simplejson i singledispatch.
- Funkcja
displayobiektów ggplot języka Python nie jest już obsługiwana, ponieważ pakiet ggplot nie jest zgodny z nowszą wersją biblioteki pandas. - Ustawienie
PYSPARK_PYTHONna/databricks/python2/bin/pythonnie jest obsługiwane, ponieważ środowisko Databricks Runtime 6.0 nie obsługuje języka Python 2. Klaster z takim ustawieniem nadal może się uruchomić. Jednak notesy języka Python i polecenia języka Python nie będą działać, czyli komórki poleceń języka Python zakończą się niepowodzeniem z komunikatem "Błąd: 'Anulowano'", a w dziennikach sterowników pojawi się komunikat o błędziePython shell failed to start. - Jeśli
PYSPARK_PYTHONwskazuje plik wykonywalny języka Python, który znajduje się w środowisku zarządzanym przez usługę Virtualenv , to środowisko zostanie aktywowane dla skryptów inicjowania i notesów. Można użyćpythonipippoleceń zdefiniowanych bezpośrednio w aktywowanym środowisku bez konieczności określania bezwzględnych lokalizacji tych poleceń. DomyślniePYSPARK_PYTHONjest ustawiona na wartość/databricks/python3/bin/python. W związku z tym domyślniepythonwskazuje na/databricks/python3/bin/python, apipwskazuje na/databricks/python3/bin/pipw przypadku skryptów inicjalizacyjnych i notesów. JeśliPYSPARK_PYTHONwskazuje na plik wykonywalny Python, który nie znajduje się w środowisku zarządzanym przez Virtualenv lub jeśli piszesz skrypt inicjowania w celu utworzenia Pythona określonego przezPYSPARK_PYTHON, należy użyć ścieżek bezwzględnych w celu uzyskania dostępu do poprawnegopythonipip. Po włączeniu izolacji biblioteki języka Python (jest ona domyślnie włączona), aktywowane środowisko jest nadal środowiskiemPYSPARK_PYTHONskojarzonym z. Zalecamy użycie narzędzia biblioteka (dbutils.library) (starsza wersja) w celu zmodyfikowania środowiska izolowanego skojarzonego z notesem języka Python.
API języka Scala i Java dla poleceń DML platformy Delta Lake
Teraz można modyfikować dane w tabelach delty przy użyciu programowych interfejsów API do usuwania, aktualizowania i scalania. Te interfejsy API odzwierciedlają składnię i semantykę odpowiadających im poleceń SQL i są doskonałe dla wielu obciążeń, na przykład operacji dotyczących wolno zmieniających się wymiarów (SCD), scalania danych zmian na potrzeby replikacji oraz operacji typu upsert wynikających z zapytań strumieniowych.
Aby uzyskać szczegółowe informacje, zobacz Co to jest usługa Delta Lake w usłudze Azure Databricks?.
API Scala i Java dla poleceń narzędziowych Delta Lake
Środowisko Databricks Runtime ma teraz programowe interfejsy API dla poleceń narzędziowych vacuum i history. Te interfejsy API dublują składnię i semantyki odpowiednich poleceń SQL dostępnych we wcześniejszych wersjach środowiska Databricks Runtime.
Możesz wyczyścić pliki, do których nie odwołuje się już tabela Delta i które są starsze niż próg przechowywania, uruchamiając vacuum na tabeli. Uruchomienie polecenia vacuum w tabeli rekursywnie opróżnia katalogi skojarzone z tabelą delty. Domyślny próg przechowywania dla plików wynosi 7 dni. Możliwość powrotu do wersji starszej niż okres przechowywania zostanie utracona po uruchomieniu programu vacuum. Polecenie vacuum nie jest wyzwalane automatycznie.
Informacje na temat operacji, użytkownika, znacznika czasu itd. dla każdego zapisu w tabeli delty można pobrać, uruchamiając polecenie history. Operacje są zwracane w odwrotnej kolejności chronologicznej. Domyślnie historia tabel jest przechowywana przez 30 dni.
Aby uzyskać szczegółowe informacje, zobacz Co to jest usługa Delta Lake w usłudze Azure Databricks?.
Buforowanie pamięci masowej dostępne dla instancji Azure Lsv2
buforowanie dysków jest teraz domyślnie włączone dla wszystkich wystąpień Lsv2.
Zoptymalizowane przechowywanie przy użyciu lokalnych interfejsów API plików
Lokalne interfejsy API plików są przydatne, ponieważ umożliwiają one dostęp do plików z bazowego rozproszonego magazynu obiektów jako plików lokalnych. W Databricks Runtime 6.0 ulepszyliśmy montowanie FUSE, które umożliwia użycie lokalnych API plików, aby rozwiązywać kluczowe ograniczenia. Środowisko Databricks Runtime 6.0 znacznie poprawia szybkość odczytu i zapisu oraz obsługuje pliki większe niż 2 GB. Jeśli potrzebujesz szybszych i bardziej niezawodnych operacji odczytu i zapisu, takich jak na potrzeby trenowania modelu rozproszonego, możesz znaleźć to ulepszenie szczególnie przydatne. Ponadto nie trzeba ładować danych do lokalnej pamięci dla obciążenia roboczego, co pozwala zaoszczędzić koszty i zwiększyć produktywność.
Aby uzyskać szczegółowe informacje, zobacz Co to jest system plików DBFS?.
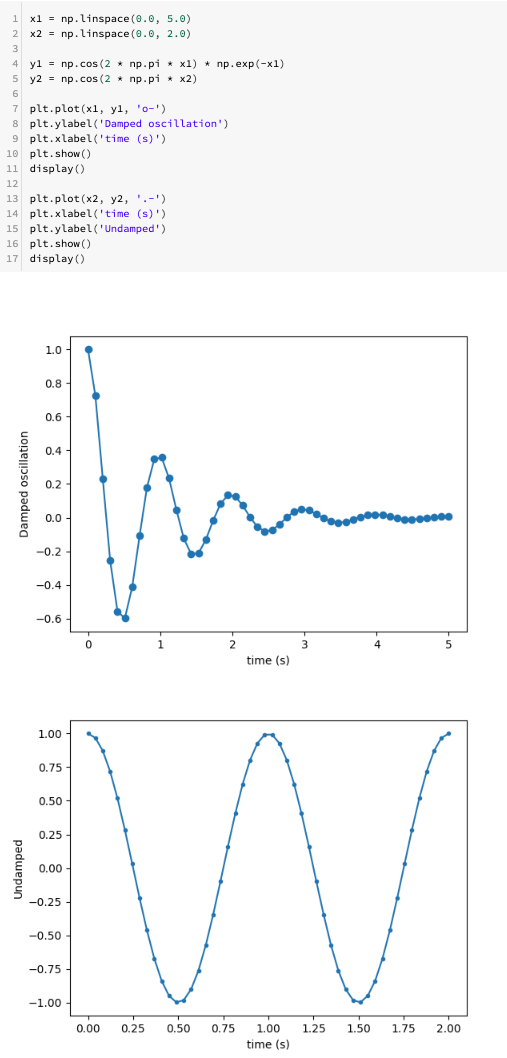
Wiele wykresów matplotlib w jednej komórce notatnika
Teraz można wyświetlić wiele wykresów matplotlib w jednej komórce zeszytu.
Poświadczenia usługi dla wielu kont usługi Azure Data Lake Storage Gen1
Teraz można skonfigurować poświadczenia usługi dla wielu kont magazynu platformy Azure do użycia w ramach jednej sesji platformy Apache Spark. W tym celu dodaj account.<account-name> do kluczy konfiguracji. Jeśli na przykład chcesz skonfigurować poświadczenia dla kont w celu uzyskania dostępu do adl://example1.azuredatalakestore.net i adl://example2.azuredatalakestore.net, możesz to zrobić w następujący sposób:
spark.conf.set("fs.adl.oauth2.access.token.provider.type", "ClientCredential")
spark.conf.set("fs.adl.account.example1.oauth2.client.id", "<application-id-example1>")
spark.conf.set("fs.adl.account.example1.oauth2.credential", dbutils.secrets.get(scope = "<scope-name>", key = "<key-name-for-service-credential-example1>"))
spark.conf.set("fs.adl.account.example1.oauth2.refresh.url", "https://login.microsoftonline.com/<directory-id-example1>/oauth2/token")
spark.conf.set("fs.adl.account.example2.oauth2.client.id", "<application-id-example2>")
spark.conf.set("fs.adl.account.example2.oauth2.credential", dbutils.secrets.get(scope = "<scope-name>", key = "<key-name-for-service-credential-example2>"))
spark.conf.set("fs.adl.account.example2.oauth2.refresh.url", "https://login.microsoftonline.com/<directory-id-example2>/oauth2/token")
Ulepszenia
- Uaktualniono zestaw AWS SDK do wersji 1.11.596.
- Uaktualniono zestaw AZURE Storage SDK w sterowniku WASB do wersji 7.0.
-
OPTIMIZETeraz zawiera podsumowanie metryk, takich jak liczba dodanych plików, liczba usuniętych plików oraz maksymalny i minimalny rozmiar pliku. Zobacz Optymalizowanie układu pliku danych.
Usunięcie
Eksportowanie modelu uczenia maszynowego w usłudze Databricks zostało usunięte. Zamiast tego użyj narzędzia MLeap do importowania i eksportowania modeli.
Apache Spark
Uwaga
Ten artykuł zawiera odwołania do terminu podrzędnego — terminu, którego usługa Azure Databricks nie używa. Po usunięciu terminu z oprogramowania usuniemy go z tego artykułu.
Środowisko Databricks Runtime 6.0 obejmuje platformę Apache Spark 2.4.3. Ta wersja zawiera wszystkie poprawki i ulepszenia platformy Spark zawarte w środowisku Databricks Runtime 5.5 LTS (EoS), a także następujące dodatkowe poprawki błędów i ulepszenia wprowadzone na platformie Spark:
- [SPARK-27992][SPARK-28881][PYTHON] Pozwól językowi Python dołączyć do wątku połączenia, aby propagować błędy
- [SPARK-27330][SS]obsługa przerywania zadań w foreach writerze (6.0, 5.x)
- [SPARK-28642][SQL] Ukryj poświadczenia w SHOW CREATE TABLE
- [SPARK-28699][CORE] Naprawiono szczególny przypadek przerywania etapu nieokreślonego
- [SPARK-28647][WEBUI] Przywrócenie dodatkowych funkcji metryki
- [SPARK-28766][R][DOC] Naprawiono ostrzeżenie dotyczące wykonalności przychodzącej usługi CRAN dotyczące nieprawidłowego adresu URL
- [SPARK-28486][CORE][PYTHON] Mapuj plik danych PythonBroadcast na BroadcastBlock, aby uniknąć usunięcia przez GC
- [SPARK-25035][CORE] Unikanie mapowania pamięci w replikacji bloków przechowywanych na dysku
- [SPARK-27234][SS][PYTHON] Użyj InheritableThreadLocal dla aktualnej epoki w klasie EpochTracker (aby obsługiwać Python UDF)
- [SPARK-28638][WEBUI] Podsumowanie zadań powinno zawierać tylko metryki zadań zakończonych powodzeniem
- [SPARK-28153][PYTHON] Użyj AtomicReference w InputFileBlockHolder (aby obsługiwać input_file_name z funkcją UDF w Pythonie)
- [SPARK-28564][CORE] Aplikacja historii dostępu domyślnie używa identyfikatora ostatniej próby
- [SPARK-28260] Klaster może zakończyć się automatycznie, gdy zapytanie thriftserver nadal pobiera wyniki
- [SPARK-26152][CORE] Synchronizowanie oczyszczania procesu roboczego z zamykaniem procesu roboczego
- [SPARK-28545][SQL] Dodaj rozmiar mapy skrótu do dziennika kierunkowego obiektu ObjectAggregationIterator
- [SPARK-28489][SS] Naprawiono błąd powodujący, że KafkaOffsetRangeCalculator.getRanges może pomijać przesunięcia.
- [SPARK-28421][ML] Optymalizacja wydajności SparseVector.apply
- [SPARK-28156][SQL] Samołączenie nie powinno ignorować widoków z pamięci podręcznej
- [SPARK-28152][SQL] Mapowanie typu ShortType na SMALLINT i FloatType na REAL dla MsSqlServerDialect
- [SPARK-28054][SQL] Napraw błąd podczas dynamicznego wstawiania partycjonowanej tabeli Hive, gdzie nazwa partycji ma wielką literę
- [SPARK-27159][SQL] aktualizacja dialektu serwera mssql w celu obsługi typu binarnego
- [SPARK-28355][CORE][PYTHON] Użyj conf platformy Spark dla progu, w którym com...
- [SPARK-27989][CORE] Dodano ponawianie prób połączenia z sterownikiem dla k8s
- [SPARK-27416][SQL] UnsafeMapData i UnsafeArrayData serializacji Kryo ...
- [SPARK-28430][Interfejs użytkownika] Naprawianie renderowania tabeli etapów, gdy brakuje metryk niektórych zadań
- [SPARK-27485] Upewnij się, że Requirements.reorder powinna obsługiwać zduplikowane wyrażenia w sposób bezproblemowy
- [SPARK-28404][SS] Naprawianie ujemnej wartości limitu czasu w parametrze RateStreamContinuousPartitionReader
- [SPARK-28378][PYTHON] Usuń użycie cgi.escape
- [SPARK-28371][SQL] Uczynienie filtrowania Parquet "StartsWith" bezpiecznym dla wartości null
- [SPARK-28015][SQL] Sprawdzenie, czy funkcja stringToDate() zużywa całe dane wejściowe dla formatów rrrr oraz rrrr-[m]m
- [SPARK-28302][CORE] Upewnij się, aby wygenerować unikatowy plik wyjściowy dla SparkLauncher na Windowsie
- [SPARK-28308][CORE] Część poniżej sekundy CalendarInterval powinna być dopełniona przed parsowaniem.
- [SPARK-28170][ML][PYTHON] Dokumentacja ujednoliconych wektorów i macierzy
- [SPARK-28160][CORE] Poprawiono usterkę, która mogła powodować zawieszenie funkcji zwrotnej w przypadku pominięcia niezaznaczonego wyjątku.
- [SPARK-27839][SQL] Zmień wartość UTF8String.replace() na działanie na bajtach UTF8
- [SPARK-28157][CORE] Wyczyść KVStore LogInfo shS dla wpisów na czarnej liście
- [SPARK-28128][PYTHON][SQL] Grupowane UDF pandas pomijają puste partycje
- [SPARK-28012][SQL] Funkcja UDF programu Hive obsługuje wyrażenie typu strukturalnego możliwe do uproszczenia.
- [SPARK-28164] Napraw opis użycia start-slave.sh
- [SPARK-27100][SQL] Użyj Array zamiast Seq w FilePartition, aby zapobiec błędowi StackOverflowError
- [SPARK-28154][ML] GMM naprawa podwójnego buforowania
Aktualizacje konserwacyjne
Zobacz Aktualizacje związane z konserwacją środowiska Databricks Runtime 6.0.
Środowisko systemu
- System operacyjny: Ubuntu 16.04.6 LTS
- Java: 1.8.0_232
- Scala: 2.11.12
- Python: 3.7.3
- R: R w wersji 3.6.1 (2019-07-05)
- Delta Lake: 0.3.0
Uwaga
Mimo że język Scala 2.12 jest dostępny jako funkcja eksperymentalna w systemie Apache Spark 2.4, nie jest obsługiwany w środowisku Databricks Runtime 6.0.
Zainstalowane biblioteki języka Python
| Biblioteka | Wersja | Biblioteka | Wersja | Biblioteka | Wersja |
|---|---|---|---|---|---|
| asn1crypto | 0.24.0 | wywołanie zwrotne | 0.1.0 | boto | 2.49.0 |
| boto3 | 1.9.162 | botocore | 1.12.163 | certyfikat | 2019.3.9 |
| cffi | 1.12.2 | chardet | 3.0.4 | kryptografia | 2.6.1 |
| rowerzysta | 0.10.0 | Cython | 0.29.6 | dekorator | 4.4.0 |
| docutils | 0,14 | IDNA | 2.8 | ipython | 7.4.0 |
| ipython-genutils | 0.2.0 | Jedi | 0.13.3 | jmespath | 0.9.4 |
| kiwisolver | 1.1.0 | biblioteka matplotlib | 3.0.3 | numpy | 1.16.2 |
| Pandas | 0.24.2 | parso | 0.3.4 | Patsy | 0.5.1 |
| pexpect | 4.6.0 | pickleshare (jeśli to nazwa własna, nie trzeba tłumaczyć) | 0.7.5 | pip (menedżer pakietów Pythona) | 19.0.3 |
| zestaw narzędzi prompt | 2.0.9 | psycopg2 | 2.7.6.1 | ptyprocess | 0.6.0 |
| pyarrow | 0.13.0 | pycparser | 2.19 | pycurl | 7.43.0 |
| Pygments | 2.3.1 | PyGObject | 3.20.0 | pyOpenSSL | 19.0.0 |
| pyparsing – biblioteka do przetwarzania tekstu w Pythonie | 2.4.2 | PySocks | 1.6.8 | python-apt | 1.1.0.b1+ubuntu0.16.04.5 |
| python-dateutil (biblioteka Pythona do zarządzania datami) | 2.8.0 | pytz (biblioteka Pythona do obliczeń stref czasowych) | 2018.9 | żądania | 2.21.0 |
| s3transfer | 0.2.1 | scikit-learn | 0.20.3 | scipy (biblioteka naukowa dla Pythona) | 1.2.1 |
| seaborn - biblioteka wizualizacji danych w Pythonie | 0.9.0 | setuptools | 40.8.0 | Sześć | 1.12.0 |
| ssh-import-id (narzędzie do importowania kluczy SSH) | 5,5 | statsmodels - biblioteka do modelowania statystycznego | 0.9.0 | traitlety | 4.3.2 |
| nienadzorowane uaktualnienia | 0.1 | urllib3 | 1.24.1 | virtualenv | 16.4.1 |
| szerokość(wcwidth) | 0.1.7 | wheel | 0.33.1 |
Zainstalowane biblioteki języka R
| Biblioteka | Wersja | Biblioteka | Wersja | Biblioteka | Wersja |
|---|---|---|---|---|---|
| abind | 1.4-5 | askpass | 1.1 | potwierdzić to | 0.2.1 |
| backporty | 1.1.3 | baza | 3.6.1 | base64enc | 0.1-3 |
| BH | 1.69.0-1 | odrobina | 1.1-14 | bit-64 | 0.9-7 |
| bitops | 1.0-6 | blob | 1.1.1 | uruchomienie | 1.3-23 |
| warzyć | 1.0-6 | obiekt wywołujący | 3.2.0 | samochód | 3.0-2 |
| dane samochodowe | 3.0-2 | karetka | 6.0-82 | cellranger | 1.1.0 |
| Chroń | 2.3-53 | klasa | 7.3-15 | CLI | 1.1.0 |
| clipr | 0.5.0 | clisymbols | 1.2.0 | klaster | 2.1.0 |
| codetools | 0.2-16 | przestrzeń kolorów | 1.4-1 | commonmark | 1,7 |
| kompilator | 3.6.1 | konfiguracja | 0,3 | kredka | 1.3.4 |
| skręt | 3.3 | tabela danych | 1.12.0 | zestawy danych | 3.6.1 |
| DBI | 1.0.0 | dbplyr | 1.3.0 | Opis | 1.2.0 |
| devtools | 2.0.1 | skrót | 0.6.18 | DoMC | 1.3.5 |
| dplyr | 0.8.0.1 | wielokropek | 0.1.0 | fani | 0.4.0 |
| dla kotów | 0.4.0 | foreach | 1.4.4 | zagraniczny | 0.8-72 |
| kuźnia | 0.2.0 | Fs | 1.2.7 | Gbm | 2.1.5 |
| typy ogólne | 0.0.2 | ggplot2 | 3.1.0 | Gh | 1.0.1 |
| git2r | 0.25.2 | glmnet | 2.0-16 | klej | 1.3.1 |
| Gower | 0.2.0 | grafika | 3.6.1 | grDevices | 3.6.1 |
| siatka | 3.6.1 | gridExtra | 2.3 | gsubfn | 0,7 |
| gtabela | 0.3.0 | H2O | 3.22.1.1 | przystań | 2.1.0 |
| HMS | 0.4.2 | htmltools – narzędzie do tworzenia stron internetowych | 0.3.6 | widżety HTML | 1.3 |
| httr | 1.4.0 | hwriter | 1.3.2 | hwriterPlus | 1.0-3 |
| ini | 0.3.1 | ipred | 0.9-8 | Iteratory | 1.0.10 |
| jsonlite | 1.6 | KernSmooth | 2.23-15 | Etykietowanie | 0,3 |
| krata | 0.20-38 | lawa | 1.6.5 | opóźnienie | 0.2.2 |
| mniejszy | 0.3.7 | lme4 | 1.1-21 | lubridate | 1.7.4 |
| magrittr | 1.5 | mapproj | 1.2.6 | Mapy | 3.3.0 |
| maptools | 0.9-5 | MASA | 7.3-51.4 | Macierz | 1.2-17 |
| MatrixModels | 0.4-1 | zapamiętywanie | 1.1.0 | metody | 3.6.1 |
| mgcv | 1.8-28 | mim | 0,6 | minqa | 1.2.4 |
| Metryki modelu | 1.2.2 | munsell | 0.5.0 | mvtnorm | 1.0-10 |
| nlme | 3.1-141 | nloptr | 1.2.1 | sieć neuronowa (nnet) | 7.3-12 |
| numDeriv | 2016.8-1 | openssl | 1.3 | openxlsxx | 4.1.0 |
| równoległy | 3.6.1 | pbkrtest | 0.4-7 | filar | 1.3.1 |
| pkgbuild | 1.0.3 | pkgconfig | 2.0.2 | pkgKitten | 0.1.4 |
| pkgload | 1.0.2 | plogr | 0.2.0 | plyr | 1.8.4 |
| pochwała | 1.0.0 | prettyunits | 1.0.2 | Proc | 1.14.0 |
| Procesx | 3.3.0 | prodlim | 2018.04.18 | Postęp | 1.2.0 |
| Proto | 1.0.0 | PS | 1.3.0 | mruczenie | 0.3.2 |
| quantreg | 5.38 | R.methodsS3 | 1.7.1 | R.oo | 1.22.0 |
| R.utils | 2.8.0 | r2d3 | 0.2.3 | R6 | 2.4.0 |
| "randomForest" | 4.6-14 | rappdirs | 0.3.1 | rcmdcheck | 1.3.2 |
| RColorBrewer | 1.1-2 | Rcpp | 1.0.1 | RcppEigen | 0.3.3.5.0 |
| RcppRoll | 0.3.0 | RCurl | 1.95-4.12 | czytnik | 1.3.1 |
| readxl (biblioteka do odczytu plików Excel) | 1.3.1 | przepisy | 0.1.5 | rewanż | 1.0.1 |
| Piloty | 2.0.2 | zmień kształt2 | 1.4.3 | Rio | 0.5.16 |
| rlang | 0.3.3 | RODBC | 1.3-15 | roxygen2 | 6.1.1 |
| rpart | 4.1-15 | rprojroot | 1.3-2 | Rserve | 1.8-6 |
| RSQLite | 2.1.1 | rstudioapi | 0.10 | wagi | 1.0.0 |
| informacje o sesji | 1.1.1 | Sp | 1.3-1 | sparklyr | 1.0.0 |
| SparkR | 2.4.4 | Rozrzednia | 1.77 | przestrzenny | 7.3-11 |
| Splajnów | 3.6.1 | sqldf | 0.4-11 | KWADRAT | 2017.10-1 |
| statmod | 1.4.30 | Statystyki | 3.6.1 | statystyki4 | 3.6.1 |
| łańcuchy | 1.4.3 | stringr | 1.4.0 | przetrwanie | 2.44-1.1 |
| sys | 3.1 | tcltk | 3.6.1 | Demonstracje nauczania | 2.10 |
| testthat | 2.0.1 | tibble | 2.1.1 | tidyr | 0.8.3 |
| tidyselect | 0.2.5 | czasData | 3043.102 | narzędzia | 3.6.1 |
| Użyj tego | 1.4.0 | utf8 | 1.1.4 | narzędzia | 3.6.1 |
| viridisLite | 0.3.0 | wąs | 0.3-2 | Withr | 2.1.2 |
| xml2 | 1.2.0 | xopen | 1.0.0 | yaml | 2.2.0 |
| suwak | 2.0.1 |
Zainstalowane biblioteki Java i Scala (wersja klastra Scala 2.11)
| Identyfikator grupy | Identyfikator artefaktu | Wersja |
|---|---|---|
| antlr | antlr | 2.7.7 |
| com.amazonaws | Klient Amazon Kinesis | 1.8.10 |
| com.amazonaws | aws-java-sdk-automatyczne-skalowanie | 1.11.595 |
| com.amazonaws | aws-java-sdk-cloudformation | 1.11.595 |
| com.amazonaws | aws-java-sdk-cloudfront | 1.11.595 |
| com.amazonaws | aws-java-sdk-cloudhsm (zestaw narzędzi Java dla usługi CloudHSM) | 1.11.595 |
| com.amazonaws | aws-java-sdk-cloudsearch | 1.11.595 |
| com.amazonaws | aws-java-sdk-cloudtrail | 1.11.595 |
| com.amazonaws | aws-java-sdk-cloudwatch | 1.11.595 |
| com.amazonaws | aws-java-sdk-cloudwatchmetrics | 1.11.595 |
| com.amazonaws | aws-java-sdk-codedeploy (biblioteka do zarządzania wdrażaniem kodu w AWS) | 1.11.595 |
| com.amazonaws | aws-java-sdk-cognitoidentity | 1.11.595 |
| com.amazonaws | aws-java-sdk-cognitosync | 1.11.595 |
| com.amazonaws | aws-java-sdk-config (konfiguracja aws-java-sdk) | 1.11.595 |
| com.amazonaws | aws-java-sdk-core | 1.11.595 |
| com.amazonaws | aws-java-sdk-datapipeline | 1.11.595 |
| com.amazonaws | aws-java-sdk-directconnect (pakiet narzędzi programistycznych dla Java do współpracy z AWS Direct Connect) | 1.11.595 |
| com.amazonaws | aws-java-sdk-directory | 1.11.595 |
| com.amazonaws | aws-java-sdk-dynamodb | 1.11.595 |
| com.amazonaws | aws-java-sdk-ec2 | 1.11.595 |
| com.amazonaws | aws-java-sdk-ecs | 1.11.595 |
| com.amazonaws | aws-java-sdk-efs | 1.11.595 |
| com.amazonaws | aws-java-sdk-elasticache | 1.11.595 |
| com.amazonaws | aws-java-sdk-elasticbeanstalk | 1.11.595 |
| com.amazonaws | aws-java-sdk-elasticloadbalancing | 1.11.595 |
| com.amazonaws | aws-java-sdk-elastictranscoder | 1.11.595 |
| com.amazonaws | aws-java-sdk-emr (biblioteka SDK Java dla usługi Amazon EMR) | 1.11.595 |
| com.amazonaws | AWS Java SDK dla Glacier | 1.11.595 |
| com.amazonaws | aws-java-sdk-klej | 1.11.595 |
| com.amazonaws | aws-java-sdk-iam | 1.11.595 |
| com.amazonaws | AWS-Java-SDK-ImportExport | 1.11.595 |
| com.amazonaws | AWS SDK dla Javy - Kinesis | 1.11.595 |
| com.amazonaws | aws-java-sdk-kms | 1.11.595 |
| com.amazonaws | aws-java-sdk-lambda | 1.11.595 |
| com.amazonaws | aws-java-sdk-logs | 1.11.595 |
| com.amazonaws | aws-java-sdk-uczenie-maszynowe | 1.11.595 |
| com.amazonaws | aws-java-sdk-opsworks | 1.11.595 |
| com.amazonaws | aws-java-sdk-rds (pakiet programistyczny Java dla AWS RDS) | 1.11.595 |
| com.amazonaws | aws-java-sdk-redshift | 1.11.595 |
| com.amazonaws | aws-java-sdk-route53 | 1.11.595 |
| com.amazonaws | aws-java-sdk-s3 | 1.11.595 |
| com.amazonaws | aws-java-sdk-ses | 1.11.595 |
| com.amazonaws | aws-java-sdk-simpledb | 1.11.595 |
| com.amazonaws | aws-java-sdk-simpleworkflow | 1.11.595 |
| com.amazonaws | aws-java-sdk-sns | 1.11.595 |
| com.amazonaws | aws-java-sdk-sqs | 1.11.595 |
| com.amazonaws | aws-java-sdk-ssm | 1.11.595 |
| com.amazonaws | aws-java-sdk-storagegateway | 1.11.595 |
| com.amazonaws | aws-java-sdk-sts (pakiet programistyczny Java dla AWS STS) | 1.11.595 |
| com.amazonaws | wsparcie dla aws-java-sdk | 1.11.595 |
| com.amazonaws | aws-java-sdk-swf-biblioteki | 1.11.22 |
| com.amazonaws | aws-java-sdk-workspaces | 1.11.595 |
| com.amazonaws | jmespath-java | 1.11.595 |
| com.carrotsearch | hppc | 0.7.2 |
| com.chuusai | shapeless_2.11 | 2.3.2 |
| com.clearspring.analytics | odtwarzać strumieniowo | 2.7.0 |
| com.databricks | Rserve | 1.8-3 |
| com.databricks | dbml-local_2.11 | 0.5.0-db8-spark2.4 |
| com.databricks | dbml-local_2.11-tests | 0.5.0-db8-spark2.4 |
| com.databricks | jets3t | 0.7.1-0 |
| com.databricks.scalapb | kompilatorwtyczka_2.11 | 0.4.15-9 |
| com.databricks.scalapb | scalapb-runtime_2.11 | 0.4.15-9 |
| com.esotericsoftware | kriogenicznie cieniowane | 4.0.2 |
| com.esotericsoftware | minlog | 1.3.0 |
| com.fasterxml | kolega z klasy | 1.0.0 |
| com.fasterxml.jackson.core | adnotacje Jackson | 2.6.7 |
| com.fasterxml.jackson.core | jackson-core | 2.6.7 |
| com.fasterxml.jackson.core | jackson-databind | 2.6.7.1 |
| com.fasterxml.jackson.dataformat | Jackson-format-danych-CBOR | 2.6.7 |
| com.fasterxml.jackson.datatype | jackson-datatype-joda | 2.6.7 |
| com.fasterxml.jackson.module | jackson-module-paranamer | 2.6.7 |
| com.fasterxml.jackson.module | jackson-module-scala_2.11 | 2.6.7.1 |
| com.github.fommil | jniloader | 1.1 |
| com.github.fommil.netlib | rdzeń | 1.1.2 |
| com.github.fommil.netlib | natywne_odniesienie-java | 1.1 |
| com.github.fommil.netlib | native_ref-java-natives | 1.1 |
| com.github.fommil.netlib | natywny_system java | 1.1 |
| com.github.fommil.netlib | system_natywny-java-natywne | 1.1 |
| com.github.fommil.netlib | netlib-native_ref-linux-x86_64-natives | 1.1 |
| com.github.fommil.netlib | "netlib-native_system-linux-x86_64-natives" | 1.1 |
| com.github.luben | zstd-jni | 1.3.2-2 |
| com.github.rwl | jtransforms | 2.4.0 |
| com.google.code.findbugs | jsr305 | 2.0.1 |
| com.google.code.gson | gson | 2.2.4 |
| com.google.guava | guawa | 15,0 |
| com.google.protobuf | protobuf-java | 2.6.1 |
| com.googlecode.javaewah | JavaEWAH | 0.3.2 |
| com.h2database | h2 | 1.3.174 |
| com.jcraft | jsch | 0.1.50 |
| com.jolbox | bonecp | 0.8.0.WYDANIE |
| com.microsoft.azure | azure-data-lake-store-sdk (SDK do przechowywania danych Azure Data Lake) | 2.2.8 |
| com.microsoft.azure | Azure Storage | 7.0.0 |
| com.microsoft.sqlserver | mssql-jdbc | 6.2.2.jre8 |
| com.ning | compress-lzf (biblioteka do kompresji danych) | 1.0.3 |
| com.sun.mail | javax.mail | 1.5.2 |
| com.thoughtworks.paranamer | paranamer | 2.8 |
| com.trueaccord.lenses | lenses_2.11 | 0,3 |
| com.twitter | chill-java | 0.9.3 |
| com.twitter | relaks_2.11 | 0.9.3 |
| com.twitter | pakiet parquet-hadoop | 1.6.0 |
| com.twitter | util-app_2.11 | 6.23.0 |
| com.twitter | util-core_2.11 | 6.23.0 |
| com.twitter | util-jvm_2.11 | 6.23.0 |
| com.typesafe | konfiguracja | 1.2.1 |
| com.typesafe.scala-logging | scala-logging-api_2.11 | 2.1.2 |
| com.typesafe.scala-logging | scala-logging-slf4j_2.11 | 2.1.2 |
| com.univocity | parsery jednowołciowości | 2.7.3 |
| com.vlkan | flatbuffers | 1.2.0-3f79e055 |
| com.zaxxer | HikariCP | 3.1.0 |
| commons-beanutils | commons-beanutils | 1.9.3 |
| commons-cli | commons-cli | 1.2 |
| commons-codec | commons-codec | 1.10 |
| Zbiory Commons | Zbiory Commons | 3.2.2 |
| commons-configuration | commons-configuration | 1.6 |
| commons-dbcp | commons-dbcp | 1.4 |
| commons-digester | commons-digester | 1.8 |
| commons-httpclient | commons-httpclient | 3.1 |
| commons-io | commons-io | 2,4 |
| commons-lang | commons-lang | 2.6 |
| commons-logging | commons-logging | 1.1.3 |
| commons-net | commons-net | 3.1 |
| commons-pool | commons-pool | 1.5.4 |
| info.ganglia.gmetric4j | gmetric4j | 1.0.7 |
| io.airlift | kompresor powietrza | 0.10 |
| io.dropwizard.metrics | metryki —rdzeń | 3.1.5 |
| io.dropwizard.metrics | metrics-ganglia | 3.1.5 |
| io.dropwizard.metrics | metrics-graphite | 3.1.5 |
| io.dropwizard.metrics | wskaźniki-kontrole zdrowia | 3.1.5 |
| io.dropwizard.metrics | metrics-jetty9 | 3.1.5 |
| io.dropwizard.metrics | metryki w formacie JSON | 3.1.5 |
| io.dropwizard.metrics | metryki-JVM | 3.1.5 |
| io.dropwizard.metrics | metrics-log4j | 3.1.5 |
| io.dropwizard.metrics | serwlety metryk | 3.1.5 |
| io.netty | Netty | 3.9.9.Final |
| io.netty | netty-all | 4.1.17.Final |
| javax.activation | aktywacja | 1.1.1 |
| javax.annotation | javax.annotation-api | 1.2 |
| javax.el | javax.el-api | 2.2.4 |
| javax.jdo | jdo-api | 3.0.1 |
| javax.servlet | javax.servlet-api | 3.1.0 |
| javax.servlet.jsp | jsp-api | 2.1 |
| javax.transaction | jta | 1.1 |
| javax.validation | validation-api | 1.1.0.Final |
| javax.ws.rs | javax.ws.rs-api | 2.0.1 |
| javax.xml.bind | jaxb-api | 2.2.2 |
| javax.xml.stream | stax-api | 1.0-2 |
| javolution | javolution | 5.5.1 |
| jline | jline | 2.14.6 |
| joda-time | joda-time | 2.9.3 |
| junit | junit | 4.12 |
| log4j | apache-log4j-extras | 1.2.17 |
| log4j | log4j | 1.2.17 |
| net.hydromatic | eigenbase-properties | 1.1.5 |
| net.razorvine | pirolit | 4.13 |
| net.sf.jpam | jpam | 1.1 |
| net.sf.opencsv | opencsv | 2.3 |
| net.sf.supercsv | super-csv | 2.2.0 |
| net.snowflake | SDK do pobierania danych Snowflake | 0.9.5 |
| net.snowflake | snowflake-jdbc | 3.6.15 |
| net.snowflake | spark-snowflake_2.11 | 2.4.10-spark_2.4 |
| net.sourceforge.f2j | arpack_combined_all | 0.1 |
| org.acplt | oncrpc | 1.0.7 |
| org.antlr | ST4 | 4.0.4 |
| org.antlr | antlr-runtime | 3.4 |
| org.antlr | antlr4-runtime | 4.7 |
| org.antlr | Szablon łańcucha | 3.2.1 |
| org.apache.ant | mrówka | 1.9.2 |
| org.apache.ant | ant-jsch | 1.9.2 |
| org.apache.ant | program uruchamiający Ant | 1.9.2 |
| org.apache.arrow | format strzałki | 0.10.0 |
| org.apache.arrow | strzałka w pamięci | 0.10.0 |
| org.apache.arrow | wektor strzałki | 0.10.0 |
| org.apache.avro | avro | 1.8.2 |
| org.apache.avro | avro-ipc | 1.8.2 |
| org.apache.avro | avro-mapred-hadoop2 | 1.8.2 |
| org.apache.calcite | calcite-avatica | 1.2.0 inkubacja |
| org.apache.calcite | rdzeń kalcytowy | 1.2.0 inkubacja |
| org.apache.calcite | calcite-linq4j | 1.2.0 inkubacja |
| org.apache.commons | commons-compress | 1.8.1 |
| org.apache.commons | commons-crypto | 1.0.0 |
| org.apache.commons | commons-lang3 | 3.5 |
| org.apache.commons | commons-math3 | 3.4.1 |
| org.apache.curator | kurator-klient | 2.7.1 |
| org.apache.curator | struktura kuratora | 2.7.1 |
| org.apache.curator | przepisy kuratora kulinarnego | 2.7.1 |
| org.apache.derby | Derby | 10.12.1.1 |
| org.apache.directory.api | api-asn1-api | 1.0.0-M20 |
| org.apache.directory.api | api-util | 1.0.0-M20 |
| org.apache.directory.server | apacheds-i18n | 2.0.0-M15 |
| org.apache.directory.server | apacheds-kerberos-codec | 2.0.0-M15 |
| org.apache.hadoop | adnotacje hadoop | 2.7.3 |
| org.apache.hadoop | hadoop-auth | 2.7.3 |
| org.apache.hadoop | hadoop-klient | 2.7.3 |
| org.apache.hadoop | hadoop-common | 2.7.3 |
| org.apache.hadoop | Hadoop-HDFS (Hadoop Distributed File System) | 2.7.3 |
| org.apache.hadoop | Klient aplikacji Hadoop MapReduce | 2.7.3 |
| org.apache.hadoop | hadoop-mapreduce-client-common | 2.7.3 |
| org.apache.hadoop | hadoop-mapreduce-client-core | 2.7.3 |
| org.apache.hadoop | hadoop-mapreduce-client-jobclient | 2.7.3 |
| org.apache.hadoop | hadoop-mapreduce-client-shuffle (moduł mieszający klienta w Hadoop MapReduce) | 2.7.3 |
| org.apache.hadoop | hadoop-yarn-api | 2.7.3 |
| org.apache.hadoop | hadoop-yarn-client (klient Hadoop YARN) | 2.7.3 |
| org.apache.hadoop | hadoop-yarn-common | 2.7.3 |
| org.apache.hadoop | hadoop-yarn-server-common (Wspólne komponenty serwera Hadoop YARN) | 2.7.3 |
| org.apache.htrace | htrace-core | 3.1.0 inkubacja |
| org.apache.httpcomponents | httpclient | 4.5.6 |
| org.apache.httpcomponents | httpcore | 4.4.10 |
| org.apache.ivy | bluszcz | 2.4.0 |
| org.apache.orc | orc-core-nohive | 1.5.5 |
| org.apache.orc | orc-mapreduce-nohive | 1.5.5 |
| org.apache.orc | podkładki orc-shim | 1.5.5 |
| org.apache.parquet | kolumna parkietowa | 1.10.1.2-databricks3 |
| org.apache.parquet | parquet-wspólny | 1.10.1.2-databricks3 |
| org.apache.parquet | kodowanie Parquet | 1.10.1.2-databricks3 |
| org.apache.parquet | format typu parquet | 2.4.0 |
| org.apache.parquet | Parquet-Hadoop (framework do analizy danych) | 1.10.1.2-databricks3 |
| org.apache.parquet | parquet-jackson | 1.10.1.2-databricks3 |
| org.apache.thrift | libfb303 | 0.9.3 |
| org.apache.thrift | libthrift | 0.9.3 |
| org.apache.xbean | xbean-asm6-cieniowany | 4.8 |
| org.apache.zookeeper - system do zarządzania konfiguracją i synchronizacją dla aplikacji rozproszonych. | opiekun zwierząt | 3.4.6 |
| org.codehaus.jackson | jackson-core-asl | 1.9.13 |
| org.codehaus.jackson | jackson-jaxrs | 1.9.13 |
| org.codehaus.jackson | jackson-mapujący-ASL | 1.9.13 |
| org.codehaus.jackson | jackson-xc | 1.9.13 |
| org.codehaus.janino | commons-kompilator | 3.0.10 |
| org.codehaus.janino | Janino | 3.0.10 |
| org.datanucleus | datanucleus-api-jdo | 3.2.6 |
| org.datanucleus | datanucleus-core | 3.2.10 |
| org.datanucleus | datanucleus-rdbms | 3.2.9 |
| org.eclipse.jetty | jetty-client | 9.3.27.v20190418 |
| org.eclipse.jetty | jetty-kontynuacja | 9.3.27.v20190418 |
| org.eclipse.jetty | jetty-http | 9.3.27.v20190418 |
| org.eclipse.jetty | jetty-io | 9.3.27.v20190418 |
| org.eclipse.jetty | jetty-jndi | 9.3.27.v20190418 |
| org.eclipse.jetty | Jetty-plus | 9.3.27.v20190418 |
| org.eclipse.jetty | serwer pośredniczący Jetty | 9.3.27.v20190418 |
| org.eclipse.jetty | moduł bezpieczeństwa Jetty | 9.3.27.v20190418 |
| org.eclipse.jetty | serwer aplikacji Jetty | 9.3.27.v20190418 |
| org.eclipse.jetty | jetty-servlet | 9.3.27.v20190418 |
| org.eclipse.jetty | jetty-servlets | 9.3.27.v20190418 |
| org.eclipse.jetty | jetty-util | 9.3.27.v20190418 |
| org.eclipse.jetty | Jetty-aplikacja internetowa | 9.3.27.v20190418 |
| org.eclipse.jetty | jetty-xml | 9.3.27.v20190418 |
| org.fusesource.leveldbjni | leveldbjni-all | 1.8 |
| org.glassfish.hk2 | hk2-api | 2.4.0-b34 |
| org.glassfish.hk2 | lokalizator hk2 | 2.4.0-b34 |
| org.glassfish.hk2 | hk2-utils | 2.4.0-b34 |
| org.glassfish.hk2 | lokalizator zasobów OSGi | 1.0.1 |
| org.glassfish.hk2.external | aopalliance-zapakowane ponownie | 2.4.0-b34 |
| org.glassfish.hk2.external | javax.inject (pakiet w języku Java) | 2.4.0-b34 |
| org.glassfish.jersey.bundles.repackaged | jersey-guawa | 2.22.2 |
| org.glassfish.jersey.containers | serwlet kontenerowy Jersey | 2.22.2 |
| org.glassfish.jersey.containers | jersey-container-servlet-core | 2.22.2 |
| org.glassfish.jersey.core | jersey-client | 2.22.2 |
| org.glassfish.jersey.core | dzianina-zwykła | 2.22.2 |
| org.glassfish.jersey.core | serwer jersey | 2.22.2 |
| org.glassfish.jersey.media | - "jersey-media-jaxb" не wymaga tłumaczenia, gdyż jest to nazwa techniczna, ale dla polskich odbiorców warto dodać opis lub kontynuować bez zmian, jeżeli nazwa już jako taka przyjęła się w lokalnym użyciu. | 2.22.2 |
| org.hamcrest | hamcrest-core | 1.3 |
| org.hamcrest | hamcrest-biblioteka | 1.3 |
| org.hibernate | moduł sprawdzania poprawności hibernacji | 5.1.1.Ostateczna |
| org.iq80.snappy | Żwawy | 0,2 |
| org.javassist | javassist | 3.18.1-GA |
| org.jboss.logging | jboss-logging (narzędzie do rejestrowania zdarzeń w JBoss) | 3.1.3.GA |
| org.jdbi | jdbi | 2.63.1 |
| org.joda | joda-convert | 1,7 |
| org.jodd | jodd-core | 3.5.2 |
| org.json4s | json4s-ast_2.11 | 3.5.3 |
| org.json4s | json4s-core_2.11 | 3.5.3 |
| org.json4s | json4s-jackson_2.11 | 3.5.3 |
| org.json4s | json4s-scalap_2.11 | 3.5.3 |
| org.lz4 | lz4-java | 1.4.0 |
| org.mariadb.jdbc | mariadb-java-client | 2.1.2 |
| org.mockito | mockito-core | 1.10.19 |
| org.objenesis | objenesis | 2.5.1 |
| org.postgresql | postgresql | 42.1.4 |
| org.roaringbitmap | RoaringBitmap | 0.7.45 |
| org.roaringbitmap | Podkładki | 0.7.45 |
| org.rocksdb | rocksdbjni | 6.2.2 |
| org.rosuda.REngine | REngine | 2.1.0 |
| org.scala-lang | scala-compiler_2.11 | 2.11.12 |
| org.scala-lang | scala-library_2.11 | 2.11.12 |
| org.scala-lang | scala-reflect_2.11 | 2.11.12 |
| org.scala-lang.modules | scala-parser-combinators_2.11 | 1.1.0 |
| org.scala-lang.modules | scala-xml_2.11 | 1.0.5 |
| org.scala-sbt | interfejs testowy | 1.0 |
| org.scalacheck | scalacheck_2.11 | 1.12.5 |
| org.scalactic | scalactic_2.11 | 3.0.3 |
| org.scalanlp | breeze-macros_2.11 | 0.13.2 |
| org.scalanlp | breeze_2.11 | 0.13.2 |
| org.scalatest | scalatest_2.11 | 3.0.3 |
| org.slf4j | jcl-over-slf4j | 1.7.16 |
| org.slf4j | jul-to-slf4j | 1.7.16 |
| org.slf4j | slf4j-api | 1.7.16 |
| org.slf4j | slf4j-log4j12 | 1.7.16 |
| org.spark-project.hive | hive-beeline (narzędzie do interakcji z bazą danych Hive) | 1.2.1.spark2 |
| org.spark-project.hive | hive-cli | 1.2.1.spark2 |
| org.spark-project.hive | hive-jdbc | 1.2.1.spark2 |
| org.spark-project.hive | magazyn metadanych Hive | 1.2.1.spark2 |
| org.spark-project.spark.spark | Nieużywane | 1.0.0 |
| org.spire-math | spire-macros_2.11 | 0.13.0 |
| org.spire-math | spire_2.11 | 0.13.0 |
| org.springframework | spring-core (podstawowy moduł Spring) | 4.1.4.WYDANIE |
| org.springframework | test sprężynowy | 4.1.4.WYDANIE |
| org.tukaani | xz | 1.5 |
| org.typelevel | mechanik_2.11 | 0.6.1 |
| org.typelevel | macro-compat_2.11 | 1.1.1 |
| org.xerial | sqlite-jdbc | 3.8.11.2 |
| org.xerial.snappy | snappy-java | 1.1.7.3 |
| org.yaml | snakeyaml | 1.16 |
| oro | oro | 2.0.8 |
| oprogramowanie.amazon.ion | ion-java | 1.0.2 |
| Stax | stax-api | 1.0.1 |
| xmlenc (standard szyfrowania XML) | xmlenc (standard szyfrowania XML) | 0.52 |