Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Uwaga
Obsługa tej wersji środowiska Databricks Runtime została zakończona. Aby uzyskać datę zakończenia pomocy technicznej, zobacz Historia zakończenia pomocy technicznej. Wszystkie obsługiwane wersje środowiska Databricks Runtime można znaleźć w temacie Databricks Runtime release notes versions and compatibility (Wersje i zgodność środowiska Databricks Runtime).
Usługa Databricks wydała tę wersję w listopadzie 2020 r.
Poniższe informacje o wersji zawierają informacje o środowisku Databricks Runtime 7.4 obsługiwanym przez platformę Apache Spark 3.0.
Nowe funkcje
W tej sekcji:
- Funkcje i ulepszenia usługi Delta Lake
- Automatyczne ładowanie obsługuje teraz delegowanie zasobów powiadomień o plikach do administratorów
-
Nowe
USAGEuprawnienia zapewniają administratorom większą kontrolę nad uprawnieniami dostępu do danych - Funkcja DBFS FUSE jest teraz włączona dla klastrów z obsługą przekazywania
Funkcje i ulepszenia usługi Delta Lake
Ta wersja zawiera następujące funkcje i ulepszenia usługi Delta Lake:
- Nowy interfejs API umożliwia usłudze Delta Lake sprawdzenie, czy dane dodane do tabeli spełniają ograniczenia
- Nowy interfejs API umożliwia wycofanie tabeli delty do starszej wersji tabeli
- Nowa wersja początkowa umożliwia zwracanie tylko najnowszych zmian w źródle przesyłania strumieniowego usługi Delta Lake
-
Zwiększona stabilność
OPTIMIZE
Nowy interfejs API umożliwia usłudze Delta Lake sprawdzenie, czy dane dodane do tabeli spełniają ograniczenia
Usługa Delta Lake obsługuje CHECK teraz ograniczenia. Po podaniu usługa Delta Lake automatycznie sprawdza, czy dane dodane do tabeli spełniają określone wyrażenie.
Aby dodać CHECK ograniczenia, użyj ALTER TABLE ADD CONSTRAINTS polecenia . Aby uzyskać szczegółowe informacje, zobacz Ograniczenia dotyczące usługi Azure Databricks.
Nowy interfejs API umożliwia wycofanie tabeli delty do starszej wersji tabeli
Teraz możesz wycofać tabele Delta do starszych wersji, używając polecenia RESTORE.
SQL
RESTORE <table> TO VERSION AS OF n;
RESTORE <table> TO TIMESTAMP AS OF 'yyyy-MM-dd HH:mm:ss';
Python
from delta.tables import DeltaTable
DeltaTable.forName(spark, "table_name").restoreToVersion(n)
DeltaTable.forName(spark, "table_name").restoreToTimestamp('yyyy-MM-dd')
Skala
import io.delta.tables.DeltaTable
DeltaTable.forName(spark, "table_name").restoreToVersion(n)
DeltaTable.forName(spark, "table_name").restoreToTimestamp("yyyy-MM-dd")
RESTORE Tworzy nowe zatwierdzenie, które powoduje wycofanie wszystkich zmian wprowadzonych w tabeli od wersji, którą chcesz przywrócić. Wszystkie istniejące dane i metadane są przywracane, w tym schemat, ograniczenia, identyfikatory transakcji przesyłania strumieniowego, COPY INTO metadane oraz wersja protokołu tabeli. Aby uzyskać szczegółowe informacje, zobacz Przywracanie tabeli delty.
Nowa wersja początkowa umożliwia zwracanie tylko najnowszych zmian w źródle przesyłania strumieniowego usługi Delta Lake
Aby zwrócić tylko najnowsze zmiany, określ startingVersion wartość latest. Aby uzyskać szczegółowe informacje, zobacz Określanie pozycji początkowej.
Zwiększona stabilność OPTIMIZE
OPTIMIZE (bez żadnych predykatów partycji) można skalować tak, by działać na tabelach z dziesiątkami milionów małych plików. Wcześniej sterownik platformy Apache Spark mógł zużyć całą pamięć, przez co OPTIMIZE nie zostałby ukończony.
OPTIMIZE teraz obsługuje bardzo duże tabele z dziesiątkami milionów plików.
Automatyczne ładowanie obsługuje teraz delegowanie zasobów powiadomień o plikach do administratorów
Nowy interfejs API języka Scala umożliwia administratorom konfigurowanie zasobów powiadomień dotyczących plików dla modułu ładującego automatycznego. Inżynierowie danych mogą teraz obsługiwać strumienie automatycznego modułu ładującego z mniejszą liczbą uprawnień, delegując początkową konfigurację zasobów do swoich administratorów. Zobacz Ręczne konfigurowanie zasobów powiadomień o plikach lub zarządzanie nimi.
Nowe USAGE uprawnienia zapewniają administratorom większą kontrolę nad uprawnieniami dostępu do danych
Aby wykonać akcję na obiekcie w bazie danych, należy teraz przyznać USAGE uprawnienie tej bazie danych oprócz uprawnień wymaganych do wykonania akcji. Uprawnienie USAGE jest przyznawane dla bazy danych lub wykazu. Wraz z wprowadzeniem USAGE uprawnień właściciel tabeli nie może już jednostronnie zdecydować się na udostępnienie go innemu użytkownikowi. Użytkownik musi również mieć USAGE uprawnienia do bazy danych zawierającej tabelę.
W obszarach roboczych z włączoną users kontrolą dostępu do tabel grupa automatycznie ma USAGE uprawnienia do katalogu głównego CATALOG.
Aby uzyskać szczegółowe informacje, zobacz USAGE uprawnienia.
Funkcja DBFS FUSE jest teraz włączona dla klastrów z obsługą przekazywania
Teraz można odczytywać i zapisywać z systemu plików DBFS przy użyciu instalacji FUSE, /dbfs/ gdy używasz klastra o wysokiej współbieżności włączonego na potrzeby przekazywania poświadczeń. Regularne instalowanie jest obsługiwane. Instalacje, które wymagają poświadczeń przejścia, nie są obsługiwane.
Ulepszenia
Język Spark SQL obsługuje IFF i CHARINDEX jako synonimy dla IF i POSITION
W środowisku Databricks Runtime IF() jest synonimem CASE WHEN <cond> THEN <expr1> ELSE <expr2> END
Środowisko Databricks Runtime obsługuje IFF() teraz jako synonim dla IF()
SELECT IFF(c1 = 1, 'Hello', 'World'), c1 FROM (VALUES (1), (2)) AS T(c1)
=> (Hello, 1)
(World, 2)
CHARINDEX to alternatywna nazwa POSITION funkcji.
CHARINDEX znajduje pozycję pierwszego wystąpienia ciągu w innym ciągu z opcjonalnym indeksem początkowym.
VALUES(CHARINDEX('he', 'hello from hell', 2))
=> 12
Domyślnie dla notesów języka Python włączono wiele danych wyjściowych na komórkę
Środowisko Databricks Runtime 7.1 wprowadziło obsługę wielu danych wyjściowych na komórkę w notesach języka Python (i komórkach języka Python w notesach innych niż Python), ale trzeba było włączyć tę funkcję dla notesu. Ta funkcja jest domyślnie włączona w środowisku Databricks Runtime 7.4. Zobacz Wyświetlanie wielu danych wyjściowych na komórkę.
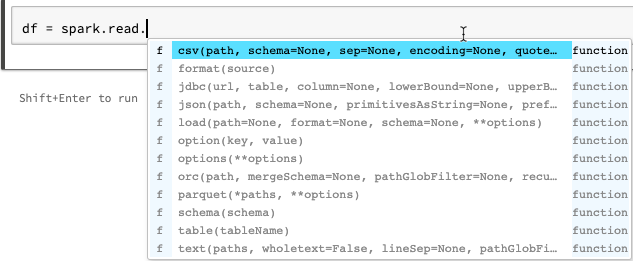
Ulepszenia autouzupełniania notesów języka Python
Autouzupełnianie dla języka Python zawiera dodatkowe informacje o typie generowane na podstawie statycznej analizy kodu przy użyciu biblioteki Jedi. Możesz nacisnąć Tab, aby wyświetlić listę opcji.
Ulepszono display wektory spark ML w wersji zapoznawczej ramki danych platformy Spark
Format display zawiera teraz etykiety dla typu wektorów (rozrzednionych lub gęstych), długości, indeksów (dla wektorów rozrzednionych) i wartości.
Inne poprawki
- Rozwiązano problem z picklingiem w
collections.namedtuplenotesach. - Rozwiązano problem z picklingiem z interakcyjnymi zdefiniowanymi klasami i metodami.
- Usunięto usterkę powodującą niepowodzenie wywołań
mlflow.start_run()w przypadku przekazywania lub klastrów z włączoną kontrolą dostępu do tabeli.
Uaktualnienia biblioteki
- Uaktualnione biblioteki języka Python:
- Narzędzie jedi zostało uaktualnione z wersji 0.14.1 do 0.17.2.
- Program koalas został uaktualniony z wersji 1.2.0 do wersji 1.3.0.
- Parso uaktualniono z wersji 0.5.2 do 0.7.0.
- Uaktualniono kilka zainstalowanych bibliotek języka R. Zobacz Zainstalowane biblioteki języka R.
Apache Spark
Środowisko Databricks Runtime 7.4 zawiera platformę Apache Spark 3.0.1. Ta wersja zawiera wszystkie poprawki i ulepszenia platformy Spark zawarte w środowisku Databricks Runtime 7.3 LTS (EoS), a także następujące dodatkowe poprawki błędów i ulepszenia wprowadzone na platformie Spark:
- [SPARK-33170] [SQL] Dodawanie konfiguracji SQL w celu kontrolowania zachowania szybkiej awarii w pliku FileFormatWriter
- [SPARK-33136] [SQL] Naprawiono błędnie zamieniony parametr w V2WriteCommand.outputResolved
- [SPARK-33134] [SQL] Zwracanie częściowych wyników tylko dla głównych obiektów JSON
- [SPARK-33038] [SQL] Połącz początkowe i bieżące plany AQE...
- [SPARK-33118] [SQL] TWORZENIE TYMCZASOWEgo TABLE kończy się niepowodzeniem z lokalizacją
- [SPARK-33101] [ML] Rozpropaguj konfigurację usługi Hadoop w formacie LibSVM z opcji DS do bazowego systemu plików HDFS
- [SPARK-33035] [SQL] Aktualizuje przestarzałe wpisy mapowania atrybutów w poleceniu QueryPlan#transformUpWithNewOutput
- [SPARK-33091] [SQL] Unikaj używania mapy zamiast foreach, aby uniknąć potencjalnego efektu ubocznego u wywołujących orcUtils.readCatalystSchema
- [SPARK-33073] [PYTHON] Ulepszanie obsługi błędów w przypadku błędów konwersji biblioteki Pandas na strzałkę
- [SPARK-33043] [ML] Obsługa obliczeń heurystycznych spark.driver.maxResultSize=0 w obliczeniach heurystycznych programu RowMatrix
- [SPARK-29358] [SQL] Spraw, aby unionByName opcjonalnie wypełniało brakujące kolumny wartością null
- [SPARK-32996] [WEB-UI] Obsługa pustych funkcji Wykonawczej w funkcji ExecutorMetricsJsonSerializer
- [SPARK-32585] [SQL] Obsługa wyliczenia scala w scalaReflection
- [SPARK-33019] [CORE] Użyj polecenia spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version=1 domyślnie
- [SPARK-33018] [SQL] Rozwiązywanie problemu ze statystykami szacowania, jeśli element podrzędny ma 0 bajtów
- [SPARK-32901] [CORE] Nie przydzielaj pamięci podczas rozlania elementu UnsafeExternalSorter
- [SPARK-33015] [SQL] Użyj parametru millisToDays() w regule ComputeCurrentTime
- [SPARK-33015] [SQL] Obliczanie bieżącej daty tylko raz
- [SPARK-32999] [SQL] Użyj polecenia Utils.getSimpleName, aby uniknąć naciśnięcia źle sformułowanej nazwy klasy w węźle TreeNode
- [SPARK-32659] [ SQL] Rozgłoszeniowa tablica zamiast zestawu w InSubqueryExec
- [SPARK-32718] [SQL] Usuń niepotrzebne słowa kluczowe dla jednostek interwału
- [SPARK-32886] [WEBUI] naprawa "niezdefiniowanego" linku w widoku osi czasu zdarzenia
- [SPARK-32898] [CORE] Naprawianie nieprawidłowej funkcji wykonawczejRunTime, gdy zadanie zostało zabite przed rozpoczęciem rzeczywistym
- [SPARK-32635] [SQL] Dodawanie nowego przypadku testowego w module katalizatora
- [SPARK-32930] [CORE] Zastąp przestarzałe metody isFile/isDirectory
- [SPARK-32906] [SQL] Nazwy pól struktury nie powinny zmieniać się po normalizacji zmiennoprzecinkowych
- [SPARK-24994] [SQL] Dodawanie optymalizatora UnwrapCastInBinaryComparison w celu uproszczenia literału całkowitego
- [SPARK-32635] [SQL] Naprawianie propagacji składanej
-
[SPARK-32738] [CORE] Jeśli wystąpi błąd krytyczny, należy zmniejszyć liczbę aktywnych wątków
Inbox.process - [SPARK-32900] [CORE] Zezwalaj na rozlanie elementu UnsafeExternalSorter w przypadku wystąpienia wartości null
- [SPARK-32897] [ PYTHON] Nie pokazuj ostrzeżenia o wycofaniu w metodzie SparkSession.builder.getOrCreate
- [SPARK-32715] [CORE] Naprawianie przecieku pamięci, gdy nie można przechowywać fragmentów emisji
- [SPARK-32715] [CORE] Naprawianie przecieku pamięci, gdy nie można przechowywać fragmentów emisji
- [SPARK-32872] [CORE] Zapobiegaj przekroczeniu progu wzrostu przez element BytesToBytesMap w MAX_CAPACITY
- [SPARK-32876] [SQL] Zmień domyślne wersje rezerwowe na 3.0.1 i 2.4.7 w programie HiveExternalCatalogVersionsSuite
- [SPARK-32840] [SQL] Nieprawidłowa wartość interwału może być po prostu klejem z jednostką
- [SPARK-32819] [SQL] ignoreNullability parametr powinien być skuteczny rekursywnie
- [SPARK-32832] [SS] Użyj opcji CaseInsensitiveMap dla opcji DataStreamReader/Writer
- [SPARK-32794] [SS] Naprawiono rzadki błąd przypadku narożnego w a aparatze mikrosadowym z niektórymi zapytaniami stanowymi + brak partii danych i źródłami V1
- [SPARK-32813] [ SQL] Pobierz domyślną konfigurację czytnika wektoryzowanego ParquetSource, jeśli nie ma aktywnej sesji SparkSession
- [SPARK-32823] [INTERNETOWY interfejs użytkownika] Naprawianie głównego raportowania zasobów interfejsu użytkownika
- [SPARK-32824] [CORE] Popraw komunikat o błędzie, gdy użytkownik zapomni o wartości .amount w konfiguracji zasobu
- [SPARK-32614] [SQL] Nie stosuj przetwarzania komentarzy, jeśli "komentarz" nie jest ustawiony dla pliku CSV
- [SPARK-32638] [SQL] Poprawia odwołania podczas dodawania aliasów w WidenSetOperationTypes
- [SPARK-32810] [SQL] Źródła danych CSV/JSON powinny unikać ścieżek globbingu podczas wnioskowania schematu
- [SPARK-32815] [ML] Naprawienie błędu ładowania źródła danych LibSVM w ścieżkach plików za pomocą metacharactrów glob
- [SPARK-32753] [SQL] Kopiowanie tagów tylko do węzła bez tagów
- [SPARK-32785] [SQL] Interwał z zwisanymi częściami nie powinien powodować wartości null
- [SPARK-32764] [SQL] -0.0 powinna być równa 0,0
- [SPARK-32810] [SQL] Źródła danych CSV/JSON powinny unikać ścieżek globbingu podczas wnioskowania schematu
- [SPARK-32779] [SQL] Unikaj używania zsynchronizowanego interfejsu API sesjiCatalog w przepływie klienta. Prowadzi to do zakleszczenia
- [SPARK-32791] [SQL] Metryka tabeli niepartycjonowanej nie powinna mieć czasu dynamicznego przycinania partycji
- [SPARK-32767] [SQL] Połączenie segmentowe powinno działać, jeśli spark.sql.shuffle.partitions jest większe niż liczba segmentów
- [SPARK-32788] [ SQL] skanowanie tabeli bez partycji nie powinno mieć filtru partycji
- [SPARK-32776] [SS] Limit strumieniowania nie powinien być optymalizowany przez PropagateEmptyRelation
- [SPARK-32624] [SQL] Naprawianie regresji w kodziegenContext.addReferenceObj w zagnieżdżonych typach Scala
- [SPARK-32659] [SQL] Ulepszanie testu oczyszczania DPP dla typu niepodzielnego
- [SPARK-31511] [SQL] Zabezpieczanie wątków przez iteratory BytesToBytesMap
- [SPARK-32693] [SQL] Porównaj dwie ramki danych z tym samym schematem z wyjątkiem właściwości dopuszczanej do wartości null
- [SPARK-28612] [SQL] Poprawny dokument metody DataFrameWriterV2.replace()
Aktualizacje konserwacyjne
Zobacz Aktualizacje konserwacji środowiska Databricks Runtime 7.4.
Środowisko systemu
- System operacyjny: Ubuntu 18.04.5 LTS
- Java: Zulu 8.48.0.53-CA-linux64 (kompilacja 1.8.0_265-b11)
- Scala: 2.12.10
- Python: 3.7.5
- R: R w wersji 3.6.3 (2020-02-29)
- Delta Lake 0.7.0
Zainstalowane biblioteki języka Python
| Biblioteka | Wersja | Biblioteka | Wersja | Biblioteka | Wersja |
|---|---|---|---|---|---|
| asn1crypto | 1.3.0 | Wezwanie zwrotne | 0.1.0 | boto3 | 1.12.0 |
| botocore | 1.15.0 | certyfikat | 2020.6.20 | cffi | 1.14.0 |
| chardet | 3.0.4 | kryptografia | 2.8 | rowerzysta | 0.10.0 |
| Cython | 0.29.15 | dekorator | 4.4.1 | docutils | 0.15.2 |
| punkty wejścia | 0,3 | IDNA | 2.8 | ipykernel | 5.1.4 |
| ipython | 7.12.0 | ipython-genutils | 0.2.0 | Jedi | 0.17.2 |
| jmespath | 0.10.0 | joblib | 0.14.1 | jupyter-client | 5.3.4 |
| jupyter-core | 4.6.1 | kiwisolver | 1.1.0 | Koale | 1.3.0 |
| biblioteka matplotlib | 3.1.3 | numpy | 1.18.1 | Pandas | 1.0.1 |
| parso | 0.7.0 | Patsy | 0.5.1 | pexpect | 4.8.0 |
| pickleshare (jeśli to nazwa własna, nie trzeba tłumaczyć) | 0.7.5 | pip (menedżer pakietów Pythona) | 20.0.2 | zestaw narzędzi prompt | 3.0.3 |
| psycopg2 | 2.8.4 | ptyprocess | 0.6.0 | pyarrow | 1.0.1 |
| pycparser | 2.19 | Pygments | 2.5.2 | PyGObject | 3.26.1 |
| pyOpenSSL | 19.1.0 | pyparsing – biblioteka do przetwarzania tekstu w Pythonie | 2.4.6 | PySocks | 1.7.1 |
| python-apt | 1.6.5+ubuntu0.3 | python-dateutil (biblioteka Pythona do zarządzania datami) | 2.8.1 | pytz (biblioteka Pythona do obliczeń stref czasowych) | 2019.3 |
| pyzmq | 18.1.1 | żądania | 2.22.0 | s3transfer | 0.3.3 |
| scikit-learn | 0.22.1 | scipy (biblioteka naukowa dla Pythona) | 1.4.1 | urodzony na morzu | 0.10.0 |
| setuptools | 45.2.0 | Sześć | 1.14.0 | ssh-import-id (narzędzie do importowania kluczy SSH) | 5.7 |
| statsmodels - biblioteka do modelowania statystycznego | 0.11.0 | tornado | 6.0.3 | traitlety | 4.3.3 |
| nienadzorowane uaktualnienia | 0.1 | urllib3 | 1.25.8 | virtualenv | 16.7.10 |
| szerokość(wcwidth) | 0.1.8 | wheel | 0.34.2 |
Zainstalowane biblioteki języka R
Biblioteki języka R są instalowane z migawki CRAN firmy Microsoft w wersji XXXX-XX-XX.
| Biblioteka | Wersja | Biblioteka | Wersja | Biblioteka | Wersja |
|---|---|---|---|---|---|
| askpass | 1.1 | potwierdzić to | 0.2.1 | backports (backports) | 1.1.8 |
| baza | 3.6.3 | base64enc | 0.1-3 | BH | 1.72.0-3 |
| bitowe | 1.1-15.2 | bit-64 | 0.9-7 | blob | 1.2.1 |
| rozruch | 1.3-25 | warzyć | 1.0-6 | miotła | 0.7.0 |
| obiekt wywołujący | 3.4.3 | karetka | 6.0-86 | cellranger | 1.1.0 |
| Chroń | 2.3-55 | klasa | 7.3-17 | CLI | 2.0.2 |
| clipr | 0.7.0 | klaster | 2.1.0 | codetools | 0.2-16 |
| przestrzeń kolorów | 1.4-1 | commonmark | 1,7 | kompilator | 3.6.3 |
| konfig | 0,3 | cover | 3.5.0 | kredka | 1.3.4 |
| Crosstalk | 1.1.0.1 | lok | 4.3 | tabela danych | 1.12.8 |
| usługi Power BI | 3.6.3 | DBI | 1.1.0 | dbplyr | 1.4.4 |
| Desc | 1.2.0 | devtools | 2.3.0 | skrót | 0.6.25 |
| dplyr | 0.8.5 | DT | 0,14 | wielokropek | 0.3.1 |
| ocenić | 0,14 | fani | 0.4.1 | kolory | 2.0.3 |
| szybka mapa | 1.0.1 | dla kotów | 0.5.0 | foreach | 1.5.0 |
| zagraniczny | 0.8-76 | kuźnia | 0.2.0 | Fs | 1.4.2 |
| typy ogólne | 0.0.2 | ggplot2 | 3.3.2 | Gh | 1.1.0 |
| git2r | 0.27.1 | glmnet | 3.0-2 | globalna | 0.12.5 |
| klej | 1.4.1 | Gower | 0.2.2 | grafika | 3.6.3 |
| grDevices | 3.6.3 | siatka | 3.6.3 | gridExtra | 2.3 |
| gsubfn | 0,7 | gtabela | 0.3.0 | przystań | 2.3.1 |
| wysoki | 0,8 | Hms | 0.5.3 | htmltools – narzędzie do tworzenia stron internetowych | 0.5.0 |
| widżety HTML | 1.5.1 | httpuv | 1.5.4 | httr | 1.4.1 |
| hwriter | 1.3.2 | hwriterPlus | 1.0-3 | ini | 0.3.1 |
| ipred | 0.9-9 | isoband | 0.2.2 | Iteratory | 1.0.12 |
| jsonlite | 1.7.0 | KernSmooth | 2.23-17 | knitr (narzędzie do generowania dynamicznych raportów w R) | 1,29 |
| Etykietowania | 0,3 | później | 1.1.0.1 | krata | 0.20-41 |
| lawa | 1.6.7 | opóźnienie | 0.2.2 | cykl życia | 0.2.0 |
| lubridate | 1.7.9 | magrittr | 1.5 | Markdown | 1.1 |
| MASA | 7.3-53 | Macierz | 1.2-18 | zapamiętywanie | 1.1.0 |
| metody | 3.6.3 | mgcv | 1.8-33 | mim | 0,9 |
| Metryki modelu | 1.2.2.2 | modeler | 0.1.8 | munsell | 0.5.0 |
| nlme | 3.1-149 | sieć neuronowa (nnet) | 7.3-14 | numDeriv | 2016.8-1.1 |
| openssl | 1.4.2 | równoległy | 3.6.3 | filar | 1.4.6 |
| pkgbuild | 1.1.0 | pkgconfig | 2.0.3 | pkgload | 1.1.0 |
| plogr | 0.2.0 | plyr | 1.8.6 | pochwała | 1.0.0 |
| prettyunits | 1.1.1 | Proc | 1.16.2 | Procesx | 3.4.3 |
| prodlim | 2019.11.13 | Postęp | 1.2.2 | Obietnice | 1.1.1 |
| Proto | 1.0.0 | PS | 1.3.3 | mruczenie | 0.3.4 |
| r2d3 | 0.2.3 | R6 | 2.4.1 | "randomForest" | 4.6-14 |
| rappdirs | 0.3.1 | rcmdcheck | 1.3.3 | RColorBrewer | 1.1-2 |
| Rcpp | 1.0.5 | czytnik | 1.3.1 | readxl (biblioteka do odczytu plików Excel) | 1.3.1 |
| przepisy | 0.1.13 | rewanż | 1.0.1 | rewanż2 | 2.1.2 |
| Piloty | 2.1.1 | przykład powtarzalny | 0.3.0 | zmień kształt2 | 1.4.4 |
| Rex | 1.2.0 | rjson | 0.2.20 | rlang | 0.4.7 |
| rmarkdown (narzędzie do tworzenia dokumentów w R) | 2.3 | RODBC | 1.3-16 | roxygen2 | 7.1.1 |
| rpart | 4.1-15 | rprojroot | 1.3-2 | Rserve | 1.8-7 |
| RSQLite | 2.2.0 | rstudioapi | 0,11 | rversions (rversions) | 2.0.2 |
| rvest | 0.3.5 | waga | 1.1.1 | selektor | 0.4-2 |
| Informacje o sesji | 1.1.1 | kształt | 1.4.4 | błyszczący | 1.5.0 |
| sourcetools | 0.1.7 | sparklyr | 1.3.1 | SparkR | 3.0.0 |
| przestrzenny | 7.3-11 | Splajnów | 3.6.3 | sqldf | 0.4-11 |
| KWADRAT | 2020.3 | Statystyki | 3.6.3 | statystyki4 | 3.6.3 |
| łańcuchy | 1.4.6 | stringr | 1.4.0 | przetrwanie | 3.2-7 |
| sys | 3.3 | tcltk | 3.6.3 | NauczanieDemos | 2.10 |
| testthat | 2.3.2 | tibble | 3.0.3 | tidyr | 1.1.0 |
| tidyselect | 1.1.0 | tidyverse | 1.3.0 | czasData | 3043.102 |
| tinytex | 0,24 | narzędzia | 3.6.3 | użyj tego | 1.6.1 |
| utf8 | 1.1.4 | narzędzia | 3.6.3 | UUID (Uniwersalnie Unikalny Identyfikator) | 0.1-4 |
| vctrs | 0.3.1 | viridisLite | 0.3.0 | wąs | 0,4 |
| Withr | 2.2.0 | xfun | 0,15 | xml2 | 1.3.2 |
| xopen | 1.0.0 | Xtable | 1.8-4 | yaml | 2.2.1 |
Zainstalowane biblioteki Java i Scala (wersja klastra Scala 2.12)
| Identyfikator grupy | Identyfikator artefaktu | Wersja |
|---|---|---|
| antlr | antlr | 2.7.7 |
| com.amazonaws | Klient Amazon Kinesis | 1.12.0 |
| com.amazonaws | aws-java-sdk-automatyczne-skalowanie | 1.11.655 |
| com.amazonaws | aws-java-sdk-cloudformation | 1.11.655 |
| com.amazonaws | aws-java-sdk-cloudfront | 1.11.655 |
| com.amazonaws | aws-java-sdk-cloudhsm (zestaw narzędzi Java dla usługi CloudHSM) | 1.11.655 |
| com.amazonaws | aws-java-sdk-cloudsearch | 1.11.655 |
| com.amazonaws | aws-java-sdk-cloudtrail | 1.11.655 |
| com.amazonaws | aws-java-sdk-cloudwatch | 1.11.655 |
| com.amazonaws | aws-java-sdk-cloudwatchmetrics | 1.11.655 |
| com.amazonaws | aws-java-sdk-codedeploy (biblioteka do zarządzania wdrażaniem kodu w AWS) | 1.11.655 |
| com.amazonaws | aws-java-sdk-cognitoidentity | 1.11.655 |
| com.amazonaws | aws-java-sdk-cognitosync | 1.11.655 |
| com.amazonaws | aws-java-sdk-config (konfiguracja aws-java-sdk) | 1.11.655 |
| com.amazonaws | aws-java-sdk-core | 1.11.655 |
| com.amazonaws | aws-java-sdk-datapipeline | 1.11.655 |
| com.amazonaws | aws-java-sdk-directconnect (pakiet narzędzi programistycznych dla Java do współpracy z AWS Direct Connect) | 1.11.655 |
| com.amazonaws | aws-java-sdk-directory | 1.11.655 |
| com.amazonaws | aws-java-sdk-dynamodb | 1.11.655 |
| com.amazonaws | aws-java-sdk-ec2 | 1.11.655 |
| com.amazonaws | aws-java-sdk-ecs | 1.11.655 |
| com.amazonaws | aws-java-sdk-efs | 1.11.655 |
| com.amazonaws | aws-java-sdk-elasticache | 1.11.655 |
| com.amazonaws | aws-java-sdk-elasticbeanstalk | 1.11.655 |
| com.amazonaws | aws-java-sdk-elasticloadbalancing | 1.11.655 |
| com.amazonaws | aws-java-sdk-elastictranscoder | 1.11.655 |
| com.amazonaws | aws-java-sdk-emr (biblioteka SDK Java dla usługi Amazon EMR) | 1.11.655 |
| com.amazonaws | AWS Java SDK dla Glacier | 1.11.655 |
| com.amazonaws | aws-java-sdk-iam | 1.11.655 |
| com.amazonaws | AWS-Java-SDK-ImportExport | 1.11.655 |
| com.amazonaws | AWS SDK dla Javy - Kinesis | 1.11.655 |
| com.amazonaws | aws-java-sdk-kms | 1.11.655 |
| com.amazonaws | aws-java-sdk-lambda | 1.11.655 |
| com.amazonaws | aws-java-sdk-logs | 1.11.655 |
| com.amazonaws | aws-java-sdk-uczenie-maszynowe | 1.11.655 |
| com.amazonaws | aws-java-sdk-opsworks | 1.11.655 |
| com.amazonaws | aws-java-sdk-rds (pakiet programistyczny Java dla AWS RDS) | 1.11.655 |
| com.amazonaws | aws-java-sdk-redshift | 1.11.655 |
| com.amazonaws | aws-java-sdk-route53 | 1.11.655 |
| com.amazonaws | aws-java-sdk-s3 | 1.11.655 |
| com.amazonaws | aws-java-sdk-ses | 1.11.655 |
| com.amazonaws | aws-java-sdk-simpledb | 1.11.655 |
| com.amazonaws | aws-java-sdk-simpleworkflow | 1.11.655 |
| com.amazonaws | aws-java-sdk-sns | 1.11.655 |
| com.amazonaws | aws-java-sdk-sqs | 1.11.655 |
| com.amazonaws | aws-java-sdk-ssm | 1.11.655 |
| com.amazonaws | aws-java-sdk-storagegateway | 1.11.655 |
| com.amazonaws | aws-java-sdk-sts (pakiet programistyczny Java dla AWS STS) | 1.11.655 |
| com.amazonaws | wsparcie dla aws-java-sdk | 1.11.655 |
| com.amazonaws | aws-java-sdk-biblioteka-biblioteka | 1.11.22 |
| com.amazonaws | aws-java-sdk-workspaces | 1.11.655 |
| com.amazonaws | jmespath-java | 1.11.655 |
| com.chuusai | shapeless_2.12 | 2.3.3 |
| com.clearspring.analytics | odtwarzać strumieniowo | 2.9.6 |
| com.databricks | Rserve | 1.8-3 |
| com.databricks | jets3t | 0.7.1-0 |
| com.databricks.scalapb | compilerplugin_2.12 | 0.4.15-10 |
| com.databricks.scalapb | scalapb-runtime_2.12 | 0.4.15-10 |
| com.esotericsoftware | kryo-cieniowane | 4.0.2 |
| com.esotericsoftware | minlog | 1.3.0 |
| com.fasterxml | kolega z klasy | 1.3.4 |
| com.fasterxml.jackson.core | adnotacje jackson | 2.10.0 |
| com.fasterxml.jackson.core | jackson-core | 2.10.0 |
| com.fasterxml.jackson.core | jackson-databind | 2.10.0 |
| com.fasterxml.jackson.dataformat | Jackson-format-danych-CBOR | 2.10.0 |
| com.fasterxml.jackson.datatype | jackson-datatype-joda | 2.10.0 |
| com.fasterxml.jackson.module | jackson-module-paranamer | 2.10.0 |
| com.fasterxml.jackson.module | jackson-module-scala_2.12 | 2.10.0 |
| com.github.ben-manes.kofeina | kofeina | 2.3.4 |
| com.github.fommil | jniloader | 1.1 |
| com.github.fommil.netlib | rdzeń | 1.1.2 |
| com.github.fommil.netlib | natywne_odniesienie-java | 1.1 |
| com.github.fommil.netlib | native_ref-java-natives | 1.1 |
| com.github.fommil.netlib | native_system java | 1.1 |
| com.github.fommil.netlib | system natywny-java-natives | 1.1 |
| com.github.fommil.netlib | netlib-native_ref-linux-x86_64-natives | 1.1 |
| com.github.fommil.netlib | "netlib-native_system-linux-x86_64-natives" | 1.1 |
| com.github.joshelser | dropwizard-metrics-hadoop-metrics2-reporter | 0.1.2 |
| com.github.luben | zstd-jni | 1.4.4-3 |
| com.github.wendykierp | JTransforms | 3.1 |
| com.google.code.findbugs | jsr305 | 3.0.0 |
| com.google.code.gson | gson | 2.2.4 |
| com.google.flatbuffers | flatbuffers-java | 1.9.0 |
| com.google.guava | guawa | 15,0 |
| com.google.protobuf | protobuf-java | 2.6.1 |
| com.h2database | h2 | 1.4.195 |
| com.helger | profiler | 1.1.1 |
| com.jcraft | jsch | 0.1.50 |
| com.jolbox | bonecp | 0.8.0.WYDANIE |
| com.lihaoyi | kodźródłowy_2.12 | 0.1.9 |
| com.microsoft.azure | azure-data-lake-store-sdk (SDK do przechowywania danych Azure Data Lake) | 2.2.8 |
| com.microsoft.sqlserver | mssql-jdbc | 8.2.1.jre8 |
| com.ning | compress-lzf (biblioteka do kompresji danych) | 1.0.3 |
| com.sun.mail | javax.mail | 1.5.2 |
| com.tdunning | JSON | 1.8 |
| com.thoughtworks.paranamer | paranamer | 2.8 |
| com.trueaccord.lenses | soczewki_2.12 | 0.4.12 |
| com.twitter | chill-java | 0.9.5 |
| com.twitter | chill_2.12 | 0.9.5 |
| com.twitter | util-app_2.12 | 7.1.0 |
| com.twitter | util-core_2.12 | 7.1.0 |
| com.twitter | util-function_2.12 | 7.1.0 |
| com.twitter | util-jvm_2.12 | 7.1.0 |
| com.twitter | util-lint_2.12 | 7.1.0 |
| com.twitter | util-registry_2.12 | 7.1.0 |
| com.twitter | util-stats_2.12 | 7.1.0 |
| com.typesafe | konfig | 1.2.1 |
| com.typesafe.scala-logging | scala-logging_2.12 | 3.7.2 |
| com.univocity | parsery jednowołciowości | 2.9.0 |
| com.zaxxer | HikariCP | 3.1.0 |
| commons-beanutils | commons-beanutils | 1.9.4 |
| commons-cli | commons-cli | 1.2 |
| commons-codec | commons-codec | 1.10 |
| Zbiory Commons | Zbiory Commons | 3.2.2 |
| commons-configuration | commons-configuration | 1.6 |
| commons-dbcp | commons-dbcp | 1.4 |
| commons-digester | commons-digester | 1.8 |
| wspólne przesyłanie plików | wspólne przesyłanie plików | 1.3.3 |
| commons-httpclient | commons-httpclient | 3.1 |
| commons-io | commons-io | 2,4 |
| commons-lang | commons-lang | 2.6 |
| commons-logging | commons-logging | 1.1.3 |
| commons-net | commons-net | 3.1 |
| commons-pool | commons-pool | 1.5.4 |
| info.ganglia.gmetric4j | gmetric4j | 1.0.10 |
| io.airlift | kompresor powietrza | 0.10 |
| io.dropwizard.metrics | metryki —rdzeń | 4.1.1 |
| io.dropwizard.metrics | metrics-graphite | 4.1.1 |
| io.dropwizard.metrics | wskaźniki-kontrole zdrowia | 4.1.1 |
| io.dropwizard.metrics | metrics-jetty9 | 4.1.1 |
| io.dropwizard.metrics | metrics-jmx | 4.1.1 |
| io.dropwizard.metrics | metryki w formacie JSON | 4.1.1 |
| io.dropwizard.metrics | metryki-JVM | 4.1.1 |
| io.dropwizard.metrics | serwlety metrics-servlets | 4.1.1 |
| io.netty | netty-all | 4.1.47.Final |
| jakarta.adnotacja | jakarta.annotation-api | 1.3.5 |
| \ jakarta.validation | jakarta.validation-api | 2.0.2 |
| jakarta.ws.rs | jakarta.ws.rs-api | 2.1.6 |
| javax.activation | aktywacja | 1.1.1 |
| javax.el | javax.el-api | 2.2.4 |
| javax.jdo | jdo-api | 3.0.1 |
| javax.servlet | javax.servlet-api | 3.1.0 |
| javax.servlet.jsp | jsp-api | 2.1 |
| javax.transaction | jta | 1.1 |
| javax.transaction | interfejs programistyczny transakcji | 1.1 |
| javax.xml.bind | jaxb-api | 2.2.2 |
| javax.xml.stream | stax-api | 1.0-2 |
| javolution | javolution | 5.5.1 |
| jline | jline | 2.14.6 |
| joda-time | joda-time | 2.10.5 |
| log4j | apache-log4j-extras | 1.2.17 |
| log4j | log4j | 1.2.17 |
| net.razorvine | pirolit | 4:30 |
| net.sf.jpam | jpam | 1.1 |
| net.sf.opencsv | opencsv | 2.3 |
| net.sf.supercsv | super-csv | 2.2.0 |
| net.snowflake | SDK do pobierania danych Snowflake | 0.9.6 |
| net.snowflake | snowflake-jdbc | 3.12.8 |
| net.snowflake | spark-snowflake_2.12 | 2.8.1-spark_3.0 |
| net.sourceforge.f2j | arpack_combined_all | 0.1 |
| org.acplt.remotetea | remotetea-oncrpc (niedostępne w lokalnym języku) | 1.1.2 |
| org.antlr | ST4 | 4.0.4 |
| org.antlr | antlr-runtime | 3.5.2 |
| org.antlr | antlr4-runtime | 4.7.1 |
| org.antlr | Szablon łańcucha | 3.2.1 |
| org.apache.ant | tat | 1.9.2 |
| org.apache.ant | ant-jsch | 1.9.2 |
| org.apache.ant | program uruchamiający Ant | 1.9.2 |
| org.apache.arrow | format strzałki | 0.15.1 |
| org.apache.arrow | strzałka w pamięci | 0.15.1 |
| org.apache.arrow | wektor strzałki | 0.15.1 |
| org.apache.avro | avro | 1.8.2 |
| org.apache.avro | avro-ipc | 1.8.2 |
| org.apache.avro | avro-mapred-hadoop2 | 1.8.2 |
| org.apache.commons | commons-compress | 1.8.1 |
| org.apache.commons | commons-crypto | 1.0.0 |
| org.apache.commons | commons-lang3 | 3.9 |
| org.apache.commons | commons-math3 | 3.4.1 |
| org.apache.commons | tekst wspólny | 1.6 |
| org.apache.curator | kurator-klient | 2.7.1 |
| org.apache.curator | struktura kuratora | 2.7.1 |
| org.apache.curator | przepisy kuratora | 2.7.1 |
| org.apache.derby | Derby | 10.12.1.1 |
| org.apache.directory.api | api-asn1-api | 1.0.0-M20 |
| org.apache.directory.api | api-util | 1.0.0-M20 |
| org.apache.directory.server | apacheds-i18n | 2.0.0-M15 |
| org.apache.directory.server | apacheds-kerberos-codec | 2.0.0-M15 |
| org.apache.hadoop | adnotacje hadoop | 2.7.4 |
| org.apache.hadoop | hadoop-auth | 2.7.4 |
| org.apache.hadoop | hadoop-klient | 2.7.4 |
| org.apache.hadoop | hadoop-common | 2.7.4 |
| org.apache.hadoop | Hadoop-HDFS (Hadoop Distributed File System) | 2.7.4 |
| org.apache.hadoop | Klient aplikacji Hadoop MapReduce | 2.7.4 |
| org.apache.hadoop | hadoop-mapreduce-client-common | 2.7.4 |
| org.apache.hadoop | hadoop-mapreduce-client-core | 2.7.4 |
| org.apache.hadoop | hadoop-mapreduce-client-jobclient | 2.7.4 |
| org.apache.hadoop | hadoop-mapreduce-client-shuffle (moduł mieszający klienta w Hadoop MapReduce) | 2.7.4 |
| org.apache.hadoop | hadoop-yarn-api | 2.7.4 |
| org.apache.hadoop | hadoop-yarn-client (klient Hadoop YARN) | 2.7.4 |
| org.apache.hadoop | hadoop-yarn-common | 2.7.4 |
| org.apache.hadoop | hadoop-yarn-server-common (Wspólne komponenty serwera Hadoop YARN) | 2.7.4 |
| org.apache.hive | hive-beeline (narzędzie do interakcji z bazą danych Hive) | 2.3.7 |
| org.apache.hive | hive-cli | 2.3.7 |
| org.apache.hive | hive-common | 2.3.7 |
| org.apache.hive | hive-exec-core | 2.3.7 |
| org.apache.hive | hive-jdbc | 2.3.7 |
| org.apache.hive | Klient hive-llap | 2.3.7 |
| org.apache.hive | hive-llap-common | 2.3.7 |
| org.apache.hive | magazyn metadanych Hive | 2.3.7 |
| org.apache.hive | hive-serde | 2.3.7 |
| org.apache.hive | podkładki hive | 2.3.7 |
| org.apache.hive | hive-storage-api (interfejs do przechowywania danych hive) | 2.7.1 |
| org.apache.hive | hive-vector-code-gen | 2.3.7 |
| org.apache.hive.shims | hive-shims-0.23 | 2.3.7 |
| org.apache.hive.shims | hive-shims-common | 2.3.7 |
| org.apache.hive.shims | harmonogram osłon/imitacji ula | 2.3.7 |
| org.apache.htrace | htrace-core | 3.1.0 inkubacja |
| org.apache.httpcomponents | httpclient | 4.5.6 |
| org.apache.httpcomponents | httpcore | 4.4.12 |
| org.apache.ivy | bluszcz | 2.4.0 |
| org.apache.orc | orc-core | 1.5.10 |
| org.apache.orc | orc-mapreduce | 1.5.10 |
| org.apache.orc | podkładki orc-shim | 1.5.10 |
| org.apache.parquet | parquet-kolumna | 1.10.1-databricks6 |
| org.apache.parquet | parquet-wspólny | 1.10.1-databricks6 |
| org.apache.parquet | kodowanie parquet | 1.10.1-databricks6 |
| org.apache.parquet | format parquet | 2.4.0 |
| org.apache.parquet | Parquet-Hadoop (framework do analizy danych) | 1.10.1-databricks6 |
| org.apache.parquet | parquet-jackson | 1.10.1-databricks6 |
| org.apache.thrift | libfb303 | 0.9.3 |
| org.apache.thrift | libthrift | 0.12.0 |
| org.apache.velocity | szybkość pracy | 1.5 |
| org.apache.xbean | xbean-asm7-cieniowany | 4.15 |
| org.apache.yetus | adnotacje odbiorców | 0.5.0 |
| org.apache.zookeeper - system do zarządzania konfiguracją i synchronizacją dla aplikacji rozproszonych. | opiekun zoo | 3.4.14 |
| org.codehaus.jackson | jackson-core-asl | 1.9.13 |
| org.codehaus.jackson | jackson-jaxrs | 1.9.13 |
| org.codehaus.jackson | jackson-mapujący-ASL | 1.9.13 |
| org.codehaus.jackson | jackson-xc | 1.9.13 |
| org.codehaus.janino | commons-kompilator | 3.0.16 |
| org.codehaus.janino | Janino | 3.0.16 |
| org.datanucleus | datanucleus-api-jdo | 4.2.4 |
| org.datanucleus | datanucleus-core | 4.1.17 |
| org.datanucleus | datanucleus-rdbms | 4.1.19 |
| org.datanucleus | javax.jdo | 3.2.0-m3 |
| org.eclipse.jetty | jetty-client | 9.4.18.v20190429 |
| org.eclipse.jetty | jetty-kontynuacja | 9.4.18.v20190429 |
| org.eclipse.jetty | jetty-http | 9.4.18.v20190429 |
| org.eclipse.jetty | jetty-io | 9.4.18.v20190429 |
| org.eclipse.jetty | jetty-jndi | 9.4.18.v20190429 |
| org.eclipse.jetty | Jetty-plus | 9.4.18.v20190429 |
| org.eclipse.jetty | serwer pośredniczący Jetty | 9.4.18.v20190429 |
| org.eclipse.jetty | moduł bezpieczeństwa Jetty | 9.4.18.v20190429 |
| org.eclipse.jetty | serwer aplikacji Jetty | 9.4.18.v20190429 |
| org.eclipse.jetty | jetty-servlet | 9.4.18.v20190429 |
| org.eclipse.jetty | jetty-servlets | 9.4.18.v20190429 |
| org.eclipse.jetty | jetty-util | 9.4.18.v20190429 |
| org.eclipse.jetty | Jetty-aplikacja internetowa | 9.4.18.v20190429 |
| org.eclipse.jetty | jetty-xml | 9.4.18.v20190429 |
| org.fusesource.leveldbjni | leveldbjni-all | 1.8 |
| org.glassfish.hk2 | hk2-api | 2.6.1 |
| org.glassfish.hk2 | lokalizator hk2 | 2.6.1 |
| org.glassfish.hk2 | hk2-utils | 2.6.1 |
| org.glassfish.hk2 | osgi-lokalizator-zasobów | 1.0.3 |
| org.glassfish.hk2.external | aopalliance-zapakowane ponownie | 2.6.1 |
| org.glassfish.hk2.external | jakarta.inject | 2.6.1 |
| org.glassfish.jersey.containers | serwlet kontenerowy Jersey | 2.30 |
| org.glassfish.jersey.containers | jersey-container-servlet-core | 2.30 |
| org.glassfish.jersey.core | jersey-client | 2.30 |
| org.glassfish.jersey.core | dzianina-zwykła | 2.30 |
| org.glassfish.jersey.core | serwer jersey | 2.30 |
| org.glassfish.jersey.inject | jersey-hk2 | 2.30 |
| org.glassfish.jersey.media | - "jersey-media-jaxb" не wymaga tłumaczenia, gdyż jest to nazwa techniczna, ale dla polskich odbiorców warto dodać opis lub kontynuować bez zmian, jeżeli nazwa już jako taka przyjęła się w lokalnym użyciu. | 2.30 |
| org.hibernate.validator | moduł sprawdzania poprawności hibernacji | 6.1.0 Final |
| org.javassist | javassist | 3.25.0-GA |
| org.jboss.logging | jboss-logging (narzędzie do rejestrowania zdarzeń w JBoss) | 3.3.2.Final |
| org.jdbi | jdbi | 2.63.1 |
| org.joda | joda-convert | 1,7 |
| org.jodd | jodd-core | 3.5.2 |
| org.json4s | json4s-ast_2.12 | 3.6.6 |
| org.json4s | json4s-core_2.12 | 3.6.6 |
| org.json4s | json4s-jackson_2.12 | 3.6.6 |
| org.json4s | json4s-scalap_2.12 | 3.6.6 |
| org.lz4 | lz4-java | 1.7.1 |
| org.mariadb.jdbc | mariadb-java-client | 2.1.2 |
| org.objenesis | objenesis | 2.5.1 |
| org.postgresql | postgresql | 42.1.4 |
| org.roaringbitmap | RoaringBitmap | 0.7.45 |
| org.roaringbitmap | Podkładki | 0.7.45 |
| org.rocksdb | rocksdbjni | 6.2.2 |
| org.rosuda.REngine | REngine | 2.1.0 |
| org.scala-lang | scala-compiler_2.12 | 2.12.10 |
| org.scala-lang | scala-library_2.12 | 2.12.10 |
| org.scala-lang | scala-reflect_2.12 | 2.12.10 |
| org.scala-lang.modules | scala-collection-compat_2.12 | 2.1.1 |
| org.scala-lang.modules | scala-parser-combinators_2.12 | 1.1.2 |
| org.scala-lang.modules | scala-xml_2.12 | 1.2.0 |
| org.scala-sbt | interfejs testowy | 1.0 |
| org.scalacheck | scalacheck_2.12 | 1.14.2 |
| org.scalactic | scalactic_2.12 | 3.0.8 |
| org.scalanlp | breeze-macros_2.12 | 1.0 |
| org.scalanlp | breeze_2.12 | 1.0 |
| org.scalatest | scalatest_2.12 | 3.0.8 |
| org.slf4j | jcl-over-slf4j | 1.7.30 |
| org.slf4j | jul-to-slf4j | 1.7.30 |
| org.slf4j | slf4j-api | 1.7.30 |
| org.slf4j | slf4j-log4j12 | 1.7.30 |
| org.spark-project.spark.spark | Nieużywane | 1.0.0 |
| org.springframework | spring-core (podstawowy moduł Spring) | 4.1.4.WYDANIE |
| org.springframework | test sprężynowy | 4.1.4.WYDANIE |
| org.threeten | trzydostępne dodatkowe | 1.5.0 |
| org.tukaani | xz | 1.5 |
| org.typelevel | algebra_2.12 | 2.0.0-M2 |
| org.typelevel | cats-kernel_2.12 | 2.0.0-M4 |
| org.typelevel | machinista_2.12 | 0.6.8 |
| org.typelevel | macro-compat_2.12 | 1.1.1 |
| org.typelevel | spire-macros_2.12 | 0.17.0-M1 |
| org.typelevel | spire-platform_2.12 | 0.17.0-M1 |
| org.typelevel | spire-util_2.12 | 0.17.0-M1 |
| org.typelevel | spire_2.12 | 0.17.0-M1 |
| org.xerial | sqlite-jdbc | 3.8.11.2 |
| org.xerial.snappy | snappy-java | 1.1.7.5 |
| org.yaml | snakeyaml | 1.24 |
| oro | oro | 2.0.8 |
| pl.edu.icm | JLargeArrays | 1.5 |
| oprogramowanie.amazon.ion | ion-java | 1.0.2 |
| Stax | stax-api | 1.0.1 |
| xmlenc (standard szyfrowania XML) | xmlenc (standard szyfrowania XML) | 0.52 |