Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Usługa Databricks zaleca używanie platformy MLflow 3 do oceniania i monitorowania aplikacji GenAI. Na tej stronie opisano ocenę agenta MLflow 2.
- Aby zapoznać się z wprowadzeniem do oceny i monitorowania w usłudze MLflow 3, zobacz Ocena i monitorowanie agentów sztucznej inteligencji.
- Aby uzyskać informacje na temat migracji do platformy MLflow 3, zobacz Migrowanie do platformy MLflow 3 z wersji ewaluacyjnej agenta.
- Aby uzyskać informacje dotyczące platformy MLflow 3 w tym temacie, zobacz Samouczek: ocena i ulepszanie aplikacji GenAI.
W tym artykule opisano sposób uruchamiania oceny i wyświetlania wyników podczas opracowywania aplikacji sztucznej inteligencji. Aby uzyskać informacje na temat monitorowania wdrożonych agentów, zobacz Monitorowanie usługi GenAI w środowisku produkcyjnym.
Aby ocenić agenta, należy określić zestaw oceny. Zestaw oceny to co najmniej zbiór zapytań do aplikacji, które mogą pochodzić z wyselekcjonowanego zestawu zapytań ewaluacyjnych lub z działań użytkowników agenta. Aby uzyskać więcej informacji, zobacz Zestawy ewaluacyjne (MLflow 2) i Schemat danych wejściowych oceny agenta (MLflow 2).
Uruchamianie oceny
Aby uruchomić ocenę, użyj metody mlflow.evaluate() z interfejsu API platformy MLflow, określając model_type w databricks-agent, aby włączyć ocenę agentów w usłudze Databricks i wbudowanych sędziów AI.
Poniższy przykład określa zestaw globalnych wytycznych dotyczących odpowiedzi dla globalnego sędziego AI wytycznych , które powodują niepowodzenie oceny, gdy odpowiedzi nie są zgodne z wytycznymi. Nie musisz zbierać etykiet na żądanie, aby ocenić agenta przy użyciu tego podejścia.
import mlflow
from mlflow.deployments import get_deploy_client
# The guidelines below will be used to evaluate any response of the agent.
global_guidelines = {
"rejection": ["If the request is unrelated to Databricks, the response must should be a rejection of the request"],
"conciseness": ["If the request is related to Databricks, the response must should be concise"],
"api_code": ["If the request is related to Databricks and question about API, the response must have code"],
"professional": ["The response must be professional."]
}
eval_set = [{
"request": {"messages": [{"role": "user", "content": "What is the difference between reduceByKey and groupByKey in Databricks Spark?"}]}
}, {
"request": "What is the weather today?",
}]
# Define a very simple system-prompt agent.
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Evaluate the Agent with the evaluation set and log it to the MLFlow run "system_prompt_v0".
with mlflow.start_run(run_name="system_prompt_v0") as run:
mlflow.evaluate(
data=eval_set,
model=lambda request: llama3_agent(**request),
model_type="databricks-agent",
evaluator_config={
"databricks-agent": {
"global_guidelines": global_guidelines
}
}
)
Wyniki są dostępne na karcie Ślady na stronie Uruchamianie platformy MLflow:

W tym przykładzie uruchamiane są następujące procedury, które nie potrzebują etykiet prawdy: Przestrzeganie wytycznych, Znaczenie w kontekście zapytania, Bezpieczeństwo.
Jeśli używasz agenta z mechanizmem wyszukiwania, stosowane są następujące kriteria oceny: Ugruntowanie, Znaczenie fragmentu
mlflow.evaluate() również oblicza metryki opóźnienia i kosztu dla każdego rekordu oceny, agregując wyniki dla wszystkich danych wejściowych w danym przebiegu. Są one określane jako wyniki oceny. Wyniki oceny są rejestrowane w zamkniętym przebiegu wraz z informacjami rejestrowanymi przez inne polecenia, takie jak parametry modelu. Jeśli wywołasz mlflow.evaluate() poza sesją MLflow, zostanie utworzona nowa sesja.
Evaluate with ground-truth labels (Ocena za pomocą etykiet podstawowych prawdy)
W poniższym przykładzie określono etykiety referencyjne dla każdego wiersza: expected_facts i guidelines, które odnoszą się odpowiednio do poprawności i wytycznych dla sędziów. Poszczególne oceny są traktowane oddzielnie przy użyciu etykiet prawdy rzeczywistej dla każdego wiersza osobno.
%pip install databricks-agents
dbutils.library.restartPython()
import mlflow
from mlflow.types.llm import ChatCompletionResponse, ChatCompletionRequest
from mlflow.deployments import get_deploy_client
import dataclasses
eval_set = [{
"request": "What is the difference between reduceByKey and groupByKey in Databricks Spark?",
"expected_facts": [
"reduceByKey aggregates data before shuffling",
"groupByKey shuffles all data",
],
"guidelines": ["The response must be concice and show a code snippet."]
}, {
"request": "What is the weather today?",
"guidelines": ["The response must reject the request."]
}]
# Define a very simple system-prompt agent.
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Evaluate the agent with the evaluation set and log it to the MLFlow run "system_prompt_v0".
with mlflow.start_run(run_name="system_prompt_v0") as run:
mlflow.evaluate(
data=eval_set,
model=lambda request: llama3_agent(**request),
model_type="databricks-agent"
)
W tym przykładzie są uruchamiani ci sami sędziowie, co powyżej, oprócz następujących: Poprawność, Istotność, Bezpieczeństwo
Jeśli używasz agenta z programem retriever, zostanie uruchomiony następujący sędzia: Dostateczność kontekstu
Wymagania
Funkcje sztucznej inteligencji obsługiwane przez partnerów muszą być włączone dla obszaru roboczego.
Dostarcz dane wejściowe do procesu ewaluacyjnego
Istnieją dwa sposoby dostarczania danych wejściowych do przebiegu oceny:
Podaj wcześniej wygenerowane dane wyjściowe, aby porównać je z zestawem oceny. Ta opcja jest zalecana, jeśli chcesz ocenić dane wyjściowe z aplikacji, która jest już wdrożona w środowisku produkcyjnym, lub jeśli chcesz porównać wyniki oceny między konfiguracjami oceny.
W przypadku tej opcji należy określić zestaw oceny, jak pokazano w poniższym kodzie. Zestaw oceny musi zawierać wcześniej wygenerowane dane wyjściowe. Aby uzyskać bardziej szczegółowe przykłady, zobacz Przykład: Jak przekazać wcześniej wygenerowane dane wyjściowe do oceny agenta.
evaluation_results = mlflow.evaluate( data=eval_set_with_chain_outputs_df, # pandas DataFrame with the evaluation set and application outputs model_type="databricks-agent", )Przekaż jako argument wejściowy aplikację.
mlflow.evaluate()wywołuje aplikację dla każdego danego wejściowego w zestawie oceny i raportuje oceny jakości oraz inne metryki dla poszczególnych wygenerowanych wyników. Ta opcja jest zalecana, jeśli aplikacja została zarejestrowana przy użyciu biblioteki MLflow z włączoną funkcją śledzenia MLflow lub jeśli aplikacja jest zaimplementowana jako funkcja języka Python w notatniku. Ta opcja nie jest zalecana, jeśli aplikacja została opracowana poza usługą Databricks lub jest wdrażana poza usługą Databricks.W przypadku tej opcji należy określić zestaw oceny i aplikację w wywołaniu funkcji, jak pokazano w poniższym kodzie. Aby uzyskać bardziej szczegółowe przykłady, zobacz Przykład: jak przekazać aplikację do oceny agenta.
evaluation_results = mlflow.evaluate( data=eval_set_df, # pandas DataFrame containing just the evaluation set model=model, # Reference to the MLflow model that represents the application model_type="databricks-agent", )
Aby uzyskać szczegółowe informacje na temat schematu zestawu oceny, zobacz Schemat danych wejściowych oceny agenta (MLflow 2).
Dane wyjściowe oceny
Ocena agenta zwraca swoje dane wyjściowe z mlflow.evaluate() jako ram danych, a także rejestruje je również podczas uruchamiania w MLflow. Możesz sprawdzić dane wyjściowe w notesie lub na stronie odpowiedniego uruchomienia MLflow.
Przeglądanie danych wyjściowych w notatniku
Poniższy kod przedstawia kilka przykładów sposobu przeglądania wyników przebiegu oceny z notesu.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
###
# Run evaluation
###
evaluation_results = mlflow.evaluate(..., model_type="databricks-agent")
###
# Access aggregated evaluation results across the entire evaluation set
###
results_as_dict = evaluation_results.metrics
results_as_pd_df = pd.DataFrame([evaluation_results.metrics])
# Sample usage
print(f"The percentage of generated responses that are grounded: {results_as_dict['response/llm_judged/groundedness/percentage']}")
###
# Access data about each question in the evaluation set
###
per_question_results_df = evaluation_results.tables['eval_results']
# Show information about responses that are not grounded
per_question_results_df[per_question_results_df["response/llm_judged/groundedness/rating"] == "no"].display()
Ramka danych per_question_results_df zawiera wszystkie kolumny w schemacie wejściowym i wszystkie wyniki oceny specyficzne dla każdego żądania. Aby uzyskać więcej informacji na temat obliczonych wyników, zobacz Jak jakość, koszt i opóźnienie są oceniane przez ocenę agenta (MLflow 2).
Przeglądanie danych wyjściowych przy użyciu interfejsu użytkownika platformy MLflow
Wyniki oceny są również dostępne w interfejsie użytkownika platformy MLflow. Aby uzyskać dostęp do interfejsu użytkownika platformy MLflow, kliknij ![]() na prawym pasku bocznym notesu, a następnie wybierz odpowiedni zapis uruchomienia lub kliknij linki wyświetlane w wynikach komórki notesu, w której uruchomiłeś
na prawym pasku bocznym notesu, a następnie wybierz odpowiedni zapis uruchomienia lub kliknij linki wyświetlane w wynikach komórki notesu, w której uruchomiłeś mlflow.evaluate().
Przegląd wyników oceny dla pojedynczego przebiegu
W tej sekcji opisano sposób przeglądania wyników oceny dla jednego uruchomienia. Aby porównać wyniki między przebiegami, zobacz Porównanie wyników oceny między przebiegami.
Zestawienie ocen jakościowych przez sędziów LLM
Oceny sędziów na żądanie są dostępne w databricks-agents wersji 0.3.0 lub nowszej.
Aby zapoznać się z omówieniem jakości ocenianej przez LLM poszczególnych żądań w zestawie oceny, kliknij kartę Ślady na stronie uruchomienia MLflow.
)
W tym przeglądzie przedstawiono oceny poszczególnych sędziów dla każdego wniosku oraz czy każdy wniosek przeszedł ocenę jakości na podstawie tych ocen.
Aby uzyskać więcej informacji, kliknij wiersz w tabeli, aby wyświetlić stronę szczegółów dla tego żądania. Na stronie szczegółów możesz kliknąć pozycję Zobacz szczegółowy widok śledzenia.

Zagregowane wyniki w pełnym zestawie oceny
Aby wyświetlić zagregowane wyniki w całym zestawie oceny, kliknij kartę Przegląd (dla wartości liczbowych) lub kartę Metryki modelu (dla wykresów).


Porównaj wyniki oceny między przebiegami
Ważne jest, aby porównać wyniki oceny między przebiegami, aby zobaczyć, jak aplikacja agentowa reaguje na zmiany. Porównanie wyników może pomóc zrozumieć, czy zmiany wpływają pozytywnie na jakość lub ułatwiają rozwiązywanie problemów ze zmieniającym się zachowaniem.
Użyj strony Eksperyment MLflow, aby porównać wyniki między przebiegami. Aby uzyskać dostęp do strony Eksperyment, kliknij ikonę Eksperyment w prawym pasku bocznym notesu lub kliknij linki wyświetlane w wynikach komórki notesu, w której uruchomiono ![]() .
.
Porównaj wyniki poszczególnych żądań w różnych przebiegach
Aby porównać dane dla każdego pojedynczego żądania w ramach przebiegów, kliknij ikonę widoku oceny artefaktów, pokazaną na poniższym zrzucie ekranu. W tabeli przedstawiono każde pytanie w zestawie oceny. Użyj menu rozwijanych, aby wybrać kolumny do wyświetlenia. Kliknij komórkę, aby wyświetlić jego pełną zawartość.
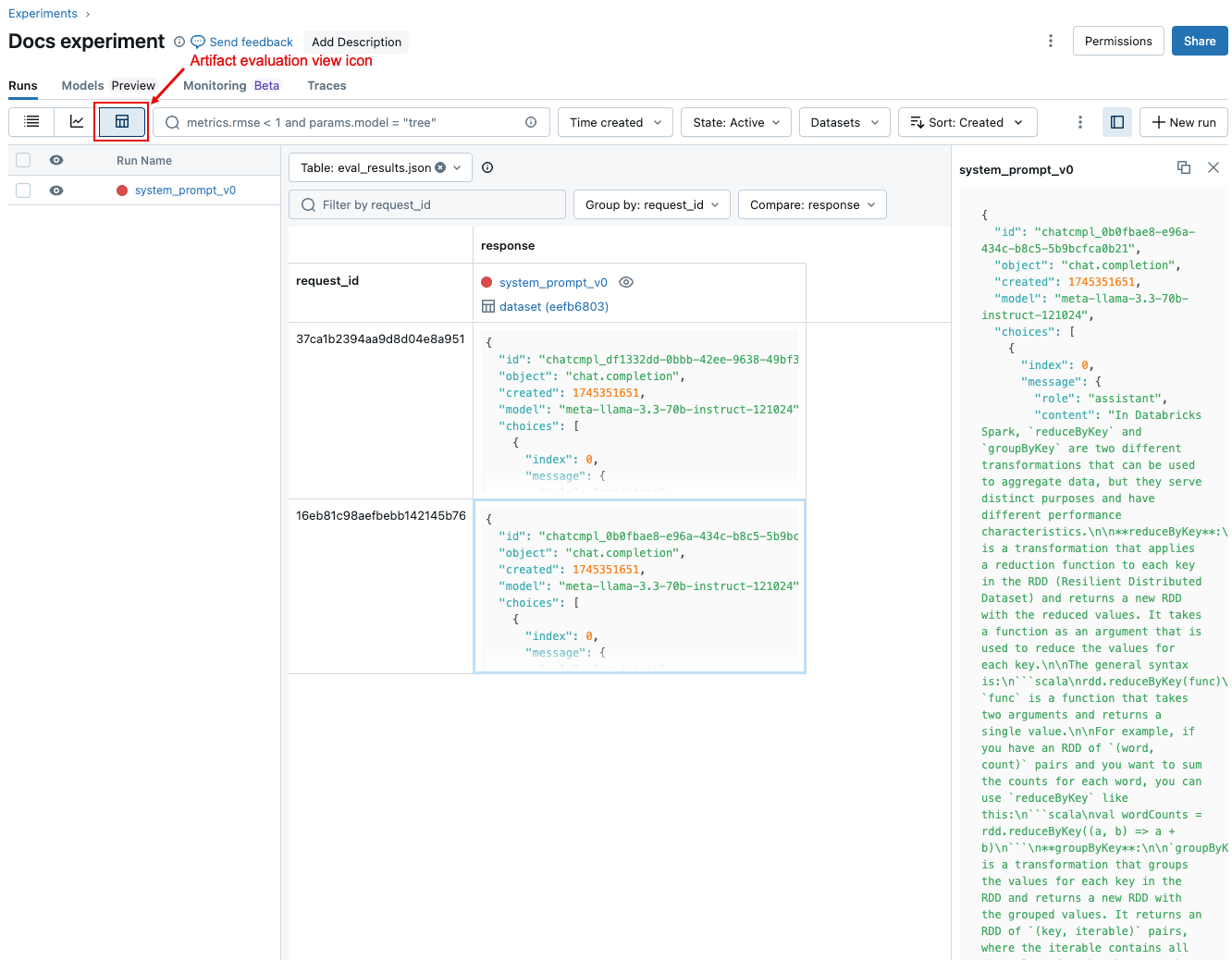
Porównanie zagregowanych wyników między przebiegami
Aby porównać zebrane wyniki z jednego lub z różnych przebiegów, kliknij ikonę widoku wykresu, przedstawioną na poniższym zrzucie ekranu. Dzięki temu można wizualizować zagregowane wyniki dla wybranego przebiegu i porównać je z wcześniejszymi przebiegami.

Którzy sędziowie są wybierani
Domyślnie, dla każdego rekordu oceny, ocena agenta Mosaic AI stosuje taki podzbiór sędziów, który najlepiej odpowiada informacjom zawartym w rekordzie. Szczególnie:
- Jeśli rekord zawiera odpowiedź będącą prawdą obiektywną, Ocena Agenta stosuje sędziów
context_sufficiency,groundedness,correctness,safety, iguideline_adherence. - Jeśli rekord nie zawiera odpowiedzi zgodnej z prawdą, ocena agenta stosuje sędziów
chunk_relevance,groundedness,relevance_to_query,safetyiguideline_adherence.
Aby uzyskać więcej informacji, zobacz:
- Uruchom podzbiór wbudowanych sędziów
- Niestandardowi sędziowie sztucznej inteligencji
- Jak jakość, koszt i opóźnienie są oceniane przez ocenę agenta (MLflow 2)
Aby uzyskać informacje o zaufaniu i bezpieczeństwie sędziego LLM, zobacz Informacje o modelach, które napędzają sędziów LLM.
Przykład: Jak przekazać wniosek do oceny przez agenta
Aby przekazać aplikację do mlflow_evaluate(), użyj argumentu model. Istnieje 5 opcji przekazywania aplikacji w argumencie model .
- Model zarejestrowany w katalogu Unity.
- Model zapisany przez MLflow w bieżącym eksperymencie MLflow.
- Model PyFunc, który jest załadowany w notatniku.
- Funkcja lokalna w notesie.
- Wdrożony punkt końcowy oprogramowania agenta.
Zapoznaj się z poniższymi sekcjami, aby zapoznać się z przykładami kodu ilustrującymi każdą opcję.
Sposób 1. Model zarejestrowany w katalogu Unity Catalog
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "models:/catalog.schema.model_name/1" # 1 is the version number
model_type="databricks-agent",
)
Sposób 2. Zapisany model MLflow w bieżącym eksperymencie MLflow
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `6b69501828264f9s9a64eff825371711` is the run_id, and `chain` is the artifact_path that was
# passed with mlflow.xxx.log_model(...).
# If you called model_info = mlflow.langchain.log_model() or mlflow.pyfunc.log_model(), you can access this value using `model_info.model_uri`.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "runs:/6b69501828264f9s9a64eff825371711/chain"
model_type="databricks-agent",
)
Sposób 3. Model PyFunc załadowany w notesie
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = mlflow.pyfunc.load_model(...)
model_type="databricks-agent",
)
Opcja 4. Funkcja lokalna w notatniku
Funkcja odbiera dane wejściowe sformatowane w następujący sposób:
{
"messages": [
{
"role": "user",
"content": "What is MLflow?",
}
],
...
}
Funkcja musi zwrócić wartość w postaci zwykłego ciągu lub słownika z możliwością serializacji (na przykład Dict[str, Any]). Aby uzyskać najlepsze wyniki w przypadku wbudowanych sędziów, Databricks zaleca użycie formatu czatu, takiego jak ChatCompletionResponse. Na przykład:
{
"choices": [
{
"message": {
"role": "assistant",
"content": "MLflow is a machine learning toolkit.",
},
...
}
],
...,
}
W poniższym przykładzie użyto funkcji lokalnej do otoczenia punktu końcowego modelu podstawowego i jego oceny.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
def model(model_input):
client = mlflow.deployments.get_deploy_client("databricks")
return client.predict(endpoint="endpoints:/databricks-meta-llama-3-1-405b-instruct", inputs={"messages": model_input["messages"]})
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = model
model_type="databricks-agent",
)
Opcja 5. Punkt końcowy wdrożonego agenta
Ta opcja działa tylko wtedy, gdy używasz punktów końcowych agenta, które zostały wdrożone przy użyciu databricks.agents.deploy oraz z wersją SDK databricks-agents lub nowszą. W przypadku modeli podstawowych lub starszych wersji zestawu SDK użyj opcji 4, aby opakowować model w funkcji lokalnej.
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
# In the following lines, `endpoint-name-of-your-agent` is the name of the agent endpoint.
evaluation_results = mlflow.evaluate(
data=eval_set_df, # pandas DataFrame with just the evaluation set
model = "endpoints:/endpoint-name-of-your-agent"
model_type="databricks-agent",
)
Jak przekazać zestaw oceny, gdy aplikacja jest uwzględniona w wywołaniu mlflow_evaluate()
W poniższym kodzie data jest ramką danych (DataFrame) biblioteki pandas z zestawem ewaluacji. Są to proste przykłady. Aby uzyskać szczegółowe informacje, zobacz schemat wejściowy .
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimal evaluation set
bare_minimum_eval_set_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
}]
# Complete evaluation set
complete_eval_set_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
}]
# Convert dictionary to a pandas DataFrame
eval_set_df = pd.DataFrame(bare_minimum_eval_set_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_df = spark_df.toPandas()
Przykład: Jak przekazać wcześniej wygenerowane dane wyjściowe do oceny agenta
W tej sekcji opisano sposób przekazywania wcześniej wygenerowanych danych wyjściowych w wywołaniu mlflow_evaluate() . Aby uzyskać wymagany schemat zestawu oceny, zobacz Schemat wejściowy oceny agenta (MLflow 2).
W poniższym kodzie data jest ramką danych Pandas, zawierającą zestaw ocen i dane wyjściowe wygenerowane przez aplikację. Są to proste przykłady. Aby uzyskać szczegółowe informacje, zobacz schemat wejściowy .
%pip install databricks-agents pandas
dbutils.library.restartPython()
import mlflow
import pandas as pd
evaluation_results = mlflow.evaluate(
data=eval_set_with_app_outputs_df, # pandas DataFrame with the evaluation set and application outputs
model_type="databricks-agent",
)
# You do not have to start from a dictionary - you can use any existing pandas or Spark DataFrame with this schema.
# Minimum required input
bare_minimum_input_schema = [
{
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
}]
# Input including optional arguments
complete_input_schema = [
{
"request_id": "your-request-id",
"request": "What is the difference between reduceByKey and groupByKey in Spark?",
"expected_retrieved_context": [
{
# In `expected_retrieved_context`, `content` is optional, and does not provide any additional functionality.
"content": "Answer segment 1 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_1",
},
{
"content": "Answer segment 2 related to What is the difference between reduceByKey and groupByKey in Spark?",
"doc_uri": "doc_uri_2_2",
},
],
"expected_response": "There's no significant difference.",
"response": "reduceByKey aggregates data before shuffling, whereas groupByKey shuffles all data, making reduceByKey more efficient.",
"retrieved_context": [
{
# In `retrieved_context`, `content` is optional. If provided, the Databricks Context Relevance LLM Judge is executed to check the `content`'s relevance to the `request`.
"content": "reduceByKey reduces the amount of data shuffled by merging values before shuffling.",
"doc_uri": "doc_uri_2_1",
},
{
"content": "groupByKey may lead to inefficient data shuffling due to sending all values across the network.",
"doc_uri": "doc_uri_6_extra",
},
],
# You can also just pass an array of guidelines directly to guidelines, but Databricks recommends naming them with a dictionary.
"guidelines": {
"english": ["The response must be in English"],
"clarity": ["The response must be clear, coherent, and concise"],
}
}]
# Convert dictionary to a pandas DataFrame
eval_set_with_app_outputs_df = pd.DataFrame(bare_minimum_input_schema)
# Use a Spark DataFrame
import numpy as np
spark_df = spark.table("catalog.schema.table") # or any other way to get a Spark DataFrame
eval_set_with_app_outputs_df = spark_df.toPandas()
Przykład: używanie funkcji niestandardowej do przetwarzania odpowiedzi z języka LangGraph
Agenci LangGraph, zwłaszcza ci z funkcją czatu, mogą zwracać wiele wiadomości podczas jednego wywołania wnioskowania. Użytkownik ponosi odpowiedzialność za przekonwertowanie odpowiedzi agenta na format, który obsługuje ocena agenta.
Jedną z metod jest użycie funkcji niestandardowej do przetwarzania odpowiedzi. W poniższym przykładzie pokazano funkcję niestandardową, która wyodrębnia ostatni komunikat czatu z modelu LangGraph. Ta funkcja jest następnie używana w mlflow.evaluate(), aby zwrócić pojedynczą odpowiedź ciągu, która może być porównywana z kolumną ground_truth.
Przykładowy kod przyjmuje następujące założenia:
- Model akceptuje dane wejściowe w formacie {„messages”: [{„role”: „user”, „content”: „hello”}]}.
- Model zwraca listę ciągów w formacie ["odpowiedź 1", "odpowiedź 2".
Poniższy kod wysyła skonkatowane odpowiedzi do sędziego w tym formacie: "odpowiedź 1nodpowiedź2"
import mlflow
import pandas as pd
from typing import List
loaded_model = mlflow.langchain.load_model(model_uri)
eval_data = pd.DataFrame(
{
"inputs": [
"What is MLflow?",
"What is Spark?",
],
"expected_response": [
"MLflow is an open-source platform for managing the end-to-end machine learning (ML) lifecycle. It was developed by Databricks, a company that specializes in big data and machine learning solutions. MLflow is designed to address the challenges that data scientists and machine learning engineers face when developing, training, and deploying machine learning models.",
"Apache Spark is an open-source, distributed computing system designed for big data processing and analytics. It was developed in response to limitations of the Hadoop MapReduce computing model, offering improvements in speed and ease of use. Spark provides libraries for various tasks such as data ingestion, processing, and analysis through its components like Spark SQL for structured data, Spark Streaming for real-time data processing, and MLlib for machine learning tasks",
],
}
)
def custom_langgraph_wrapper(model_input):
predictions = loaded_model.invoke({"messages": model_input["messages"]})
# Assuming `predictions` is a list of strings
return predictions.join("\n")
with mlflow.start_run() as run:
results = mlflow.evaluate(
custom_langgraph_wrapper, # Pass the function defined above
data=eval_data,
model_type="databricks-agent",
)
print(results.metrics)
Tworzenie pulpitu nawigacyjnego z metrykami
Gdy pracujesz nad jakością agenta, możesz udostępnić pulpit nawigacyjny interesariuszom, który pokazuje, jak jakość poprawiła się z czasem. Możesz wyodrębnić metryki z przebiegów oceny platformy MLflow, zapisać wartości w tabeli delty i utworzyć pulpit nawigacyjny.
W poniższym przykładzie pokazano, jak wyodrębnić i zapisać wartości metryk z ostatniego przebiegu oceny w notesie:
uc_catalog_name = "catalog"
uc_schema_name = "schema"
table_name = "results"
eval_results = mlflow.evaluate(
model=logged_agent_info.model_uri, # use the logged Agent
data=evaluation_set, # Run the logged Agent for all queries defined above
model_type="databricks-agent", # use Agent Evaluation
)
# The `append_metrics_to_table function` is defined below
append_metrics_to_table("<identifier-for-table>", eval_results.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
W poniższym przykładzie pokazano, jak wyodrębnić i zapisać wartości metryk dla poprzednich przebiegów zapisanych w eksperymencie MLflow.
import pandas as pd
def get_mlflow_run(experiment_name, run_name):
runs = mlflow.search_runs(experiment_names=[experiment_name], filter_string=f"run_name = '{run_name}'", output_format="list")
if len(runs) != 1:
raise ValueError(f"Found {len(runs)} runs with name {run_name}. {run_name} must identify a single run. Alternatively, you can adjust this code to search for a run based on `run_id`")
return runs[0]
run = get_mlflow_run(experiment_name ="/Users/<user_name>/db_docs_mlflow_experiment", run_name="evaluation__2024-10-09_02:27:17_AM")
# The `append_metrics_to_table` function is defined below
append_metrics_to_table("<identifier-for-table>", run.data.metrics, f"{uc_catalog_name}.{uc_schema_name}.{table_name}")
Teraz możesz utworzyć pulpit nawigacyjny przy użyciu tych danych.
Poniższy kod definiuje funkcję append_metrics_to_table używaną w poprzednich przykładach.
# Definition of `append_metrics_to_table`
def append_metrics_to_table(run_name, mlflow_metrics, delta_table_name):
data = mlflow_metrics.copy()
# Add identifying run_name and timestamp
data["run_name"] = run_name
data["timestamp"] = pd.Timestamp.now()
# Remove metrics with error counts
data = {k: v for k, v in mlflow_metrics.items() if "error_count" not in k}
# Convert to a Spark DataFrame(
metrics_df = pd.DataFrame([data])
metrics_df_spark = spark.createDataFrame(metrics_df)
# Append to the Delta table
metrics_df_spark.write.mode("append").saveAsTable(delta_table_name)
Informacje o modelach, które napędzają sędziów LLM
- Sędziowie LLM mogą korzystać z usług innych firm do oceny aplikacji GenAI, w tym azure OpenAI obsługiwanych przez firmę Microsoft.
- W przypadku Azure OpenAI, Databricks zrezygnował z monitorowania nadużyć, więc żadne monity ani odpowiedzi nie są przechowywane w usłudze Azure OpenAI.
- W przypadku obszarów roboczych Unii Europejskiej (UE) sędziowie LLM używają modeli hostowanych w UE. Wszystkie inne regiony używają modeli hostowanych w Stanach Zjednoczonych.
- Wyłączenie funkcji sztucznej inteligencji opartej na partnerach uniemożliwia sędziego LLM wywoływanie modeli opartych na partnerach. Nadal możesz używać sędziów LLM, dostarczając własny model.
- Sędziowie LLM mają pomóc klientom ocenić swoich agentów i aplikacje GenAI, a dane wyjściowe sędziów LLM nie powinny być używane do trenowania, ulepszania ani dostosowywania LLM.