Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ten artykuł zawiera ogólne omówienie architektury usługi Azure Databricks, w tym jej architektury przedsiębiorstwa, w połączeniu z platformą Azure.
Obiekty usługi Databricks
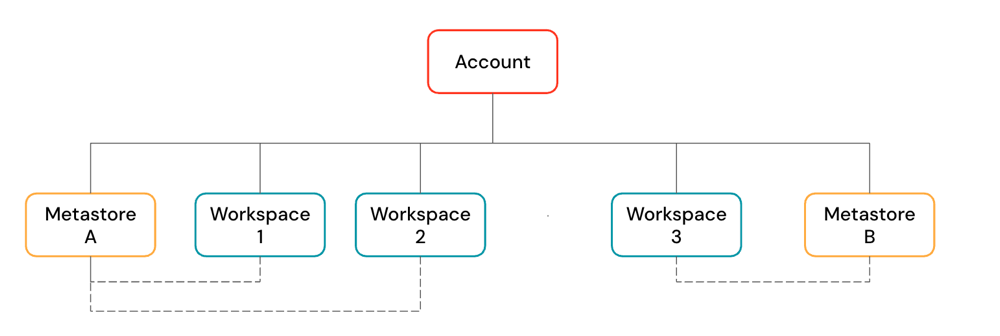
Konto usługi Azure Databricks to konstrukcja najwyższego poziomu używana do zarządzania usługą Azure Databricks w całej organizacji. Na poziomie konta zarządzasz:
- Tożsamość i dostęp: użytkownicy, grupy, zasady dostępu do usług i zarządzanie zasobami użytkowników.
Zarządzanie obszarem roboczym: tworzenie, aktualizowanie i usuwanie obszarów roboczych w wielu regionach.
Zarządzanie metasklepem katalogu Unity: tworzenie i przypisywanie metasklepu do obszarów roboczych.
Zarządzanie użyciem: rozliczenia, zgodność i zasady.
Konto może zawierać wiele obszarów roboczych i metamagazynów Unity Catalog.
Obszary robocze to środowisko współpracy, w którym użytkownicy uruchamiają obciążenia obliczeniowe, takie jak pozyskiwanie, interaktywna eksploracja, zaplanowane zadania i trenowanie uczenia maszynowego.
Magazyny metadanych Unity Catalog to centralny system zarządzania zasobami danych, takimi jak tabele i modele uczenia maszynowego. Dane są organizowane w magazynie metadanych w trójpoziomowej przestrzeni nazw.
<catalog-name>.<schema-name>.<object-name>
Magazyny metadanych są dołączane do obszarów roboczych. Pojedynczy magazyn metadanych można połączyć z wieloma obszarami roboczymi usługi Azure Databricks w tym samym regionie, dając każdemu obszarowi roboczemu ten sam widok danych. Mechanizmy kontroli dostępu do danych można zarządzać we wszystkich połączonych obszarach roboczych.
Architektura obszaru roboczego
Usługa Azure Databricks działa poza płaszczyzną sterowania i płaszczyzną obliczeniową.
Płaszczyzna sterowania obejmuje usługi zaplecza zarządzane przez usługę Azure Databricks na koncie usługi Azure Databricks. Aplikacja internetowa znajduje się na płaszczyźnie sterowania.
To na płaszczyźnie obliczeniowej przetwarzane są twoje dane. Istnieją dwa typy płaszczyzn obliczeniowych w zależności od używanych zasobów obliczeniowych.
- W przypadku bezserwerowych zasobów obliczeniowych zasoby te działają na bezserwerowej płaszczyźnie obliczeniowej na koncie usługi Azure Databricks.
- W przypadku klasycznych zasobów obliczeniowych usługi Azure Databricks zasoby obliczeniowe znajdują się w subskrypcji platformy Azure w tak zwanej klasycznej płaszczyźnie obliczeniowej. Dotyczy to sieci w ramach subskrypcji platformy Azure i jej zasobów.
Aby dowiedzieć się więcej o klasycznych obliczeniach i bezserwerowych obliczeniach, zobacz Obliczenia.
Klasyczna architektura obszaru roboczego
Klasyczne obszary robocze Azure Databricks mają przypisane konto przechowywania, znane jako konto przechowywania obszaru roboczego. Konto magazynu obszaru roboczego znajduje się w subskrypcji platformy Azure.
Na poniższym diagramie opisano ogólną architekturę usługi Azure Databricks dla klasycznych obszarów roboczych.

Architektura bezserwerowego obszaru roboczego
Pamięć masowa w obszarach roboczych bezserwerowych znajduje się w domyślnym magazynie obszaru roboczego. Możesz również nawiązać połączenie z kontem chmury, aby uzyskać dostęp do swoich danych. Na poniższym diagramie opisano ogólną architekturę dla obszarów roboczych bezserwerowych.
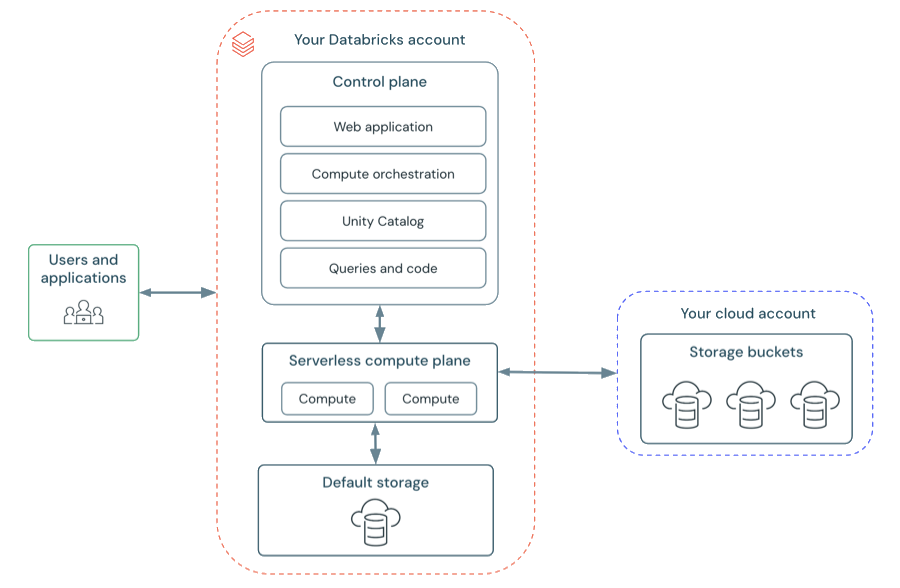
Bezserwerowa płaszczyzna obliczeniowa
Na bezserwerowej płaszczyźnie obliczeniowej zasoby obliczeniowe usługi Azure Databricks są uruchamiane w warstwie obliczeniowej na koncie usługi Azure Databricks. Usługa Azure Databricks tworzy bezserwerową płaszczyznę obliczeniową w tym samym regionie świadczenia usługi Azure co klasyczna płaszczyzna obliczeniowa obszaru roboczego. Ten region należy wybrać podczas tworzenia obszaru roboczego.
Aby chronić dane klientów w bezserwerowej płaszczyźnie obliczeniowej, bezserwerowe obliczenia są uruchamiane w granicach sieci dla obszaru roboczego, z różnymi warstwami zabezpieczeń w celu odizolowania różnych obszarów roboczych klientów usługi Azure Databricks i dodatkowych mechanizmów kontroli sieci między klastrami tego samego klienta.
Aby dowiedzieć się więcej na temat sieci na bezserwerowej płaszczyźnie obliczeniowej, sieć bezserwerowej płaszczyzny obliczeniowej.
Klasyczna płaszczyzna obliczeniowa
W klasycznej płaszczyźnie obliczeniowej zasoby obliczeniowe usługi Azure Databricks są uruchamiane w ramach subskrypcji platformy Azure. Nowe zasoby obliczeniowe są tworzone w ramach sieci wirtualnej każdego obszaru roboczego w ramach subskrypcji platformy Azure klienta.
Tradycyjna platforma obliczeniowa ma naturalną izolację, ponieważ działa w subskrypcji Azure klienta. Aby dowiedzieć się więcej na temat sieci w klasycznej płaszczyźnie obliczeniowej, zobacz Klasyczne sieci płaszczyzn obliczeniowych.
Aby uzyskać pomoc regionalną, zobacz Regiony usługi Azure Databricks.
Przechowywanie przestrzeni roboczej
Przechowywanie w obszarach roboczych jest zarządzane inaczej w zależności od typu obszaru roboczego. Aby uzyskać więcej informacji na temat typów obszarów roboczych, zobacz Tworzenie obszaru roboczego.
Obszary robocze bezserwerowe
Środowiska bezserwerowe używają domyślnego magazynu, który jest w pełni zarządzaną lokalizacją przechowywania dla danych systemowych środowiska oraz katalogów Unity Catalog. Obszary robocze bezserwerowe obsługują również możliwość łączenia się z lokalizacjami przechowywania w chmurze. Zobacz Domyślna pamięć masowa w Databricks.
Klasyczne obszary robocze
Konto magazynu obszaru roboczego zawiera:
- Dane systemu obszarów roboczych: dane systemowe obszaru roboczego są generowane podczas korzystania z różnych funkcji usługi Azure Databricks, takich jak tworzenie notesów. Ten zasobnik zawiera poprawki notesu, szczegóły uruchomienia zadania, wyniki poleceń i dzienniki platformy Spark
- Katalog obszaru roboczego Unity Catalog: Jeśli obszar roboczy został automatycznie włączony do Unity Catalog, konto magazynowe obszaru roboczego zawiera domyślny katalog obszaru roboczego. Wszyscy użytkownicy w obszarze roboczym mogą tworzyć zasoby w domyślnym schemacie w tym katalogu. Zobacz Rozpocznij pracę z Unity Catalog.
- DBFS (starsza wersja): Korzeń DBFS i zamontowane katalogi DBFS są przestarzałe i mogą być wyłączone w obszarze roboczym. DBFS (System plików Databricks) to rozproszony system plików w środowiskach Azure Databricks, dostępny pod przestrzenią nazw
dbfs:/. Instalacja systemu plików DBFS root i DBFS jest zarówno wdbfs:/przestrzeni nazw. Przechowywanie i uzyskiwanie dostępu do danych przy użyciu DBFS root lub zamontowań DBFS jest przestarzałym wzorcem i nie jest zalecane przez Databricks. Aby uzyskać więcej informacji, zobacz Co to jest system plików DBFS?.
Aby ograniczyć dostęp do konta magazynu obszaru roboczego tylko z autoryzowanych zasobów i sieci, zapoznaj się z informacjami w , jak włączyć obsługę zapory dla konta magazynu obszaru roboczego.