Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule pokazano, jak rozpocząć pracę z narzędziami deweloperskich w celu zautomatyzowania tworzenia zadań i zarządzania nimi. Przedstawia interfejs wiersza polecenia Databricks, zestawy SDK Databricks oraz interfejs API REST.
Notatka
Ten artykuł zawiera przykłady tworzenia zadań i zarządzania nimi przy użyciu interfejsu wiersza polecenia usługi Databricks, zestawu SDK języka Python usługi Databricks i interfejsu API REST jako łatwego wprowadzenia do tych narzędzi. Aby programowo zarządzać pracami w ramach CI/CD, użyj pakietów zasobów usługi Databricks lub dostawcy Databricks Terraform .
Porównanie narzędzi
W poniższej tabeli porównaliśmy interfejs wiersza polecenia usługi Databricks, zestawy SDK usługi Databricks i interfejs API REST do programowego tworzenia zadań i zarządzania nimi. Aby dowiedzieć się więcej o wszystkich dostępnych narzędziach deweloperskich, zobacz Lokalne narzędzia programistyczne.
| Narzędzie | Opis |
|---|---|
| interfejs wiersza polecenia (CLI) Databricks | Uzyskaj dostęp do funkcji usługi Databricks przy użyciu interfejsu wiersza polecenia usługi Databricks, który opakowuje interfejs API REST. Użyj interfejsu wiersza polecenia dla jednorazowych zadań, takich jak przeprowadzanie eksperymentów, tworzenie skryptów powłoki i bezpośrednie korzystanie z API REST. |
| SDK Databricks | Twórz aplikacje i twórz niestandardowe przepływy pracy usługi Databricks przy użyciu zestawu SDK usługi Databricks dostępnego dla języków Python, Java, Go lub R. Zamiast wysyłać wywołania interfejsu API REST bezpośrednio przy użyciu narzędzia curl lub Postman, możesz użyć zestawu SDK do interakcji z usługą Databricks. |
| Databricks API REST | Jeśli żadna z powyższych opcji nie będzie działać dla konkretnego przypadku użycia, możesz bezpośrednio użyć interfejsu API REST usługi Databricks. Użyj interfejsu API REST bezpośrednio w przypadku przypadków użycia, takich jak automatyzacja procesów, w których zestaw SDK w preferowanym języku programowania nie jest obecnie dostępny. |
Rozpocznij pracę z interfejsem wiersza polecenia usługi Databricks
Aby zainstalować i skonfigurować uwierzytelnianie dla Databricks CLI, zobacz Instalowanie lub aktualizowanie Databricks CLI i Uwierzytelnianie dla Databricks CLI.
Interfejs wiersza polecenia usługi Databricks zawiera grupy poleceń dla funkcji usługi Databricks, w tym jeden dla zadań, które zawierają zestaw powiązanych poleceń, które mogą również zawierać polecenia podrzędne. Grupa poleceń jobs umożliwia zarządzanie zadaniami i przebiegami zadań za pomocą akcji, takich jak create, delete i get. Ponieważ CLI obsługuje interfejs API REST usługi Databricks, większość poleceń CLI odpowiada na żądania interfejsu API REST. Na przykład databricks jobs get odwzorowuje GET/api/2.2/jobs/get.
Aby uzyskać bardziej szczegółowe informacje o użyciu i składni dotyczące grupy poleceń jobs, pojedynczego polecenia lub podpolecenia, użyj flagi h:
databricks jobs -hdatabricks jobs <command-name> -hdatabricks jobs <command-name> <subcommand-name> -h
Przykład: pobieranie zadania przy użyciu CLI (interfejsu wiersza polecenia)
Aby wydrukować informacje o pojedynczym zadaniu w obszarze roboczym, uruchom następujące polecenie:
$ databricks jobs get <job-id>
databricks jobs get 478701692316314
To polecenie zwraca kod JSON:
{
"created_time": 1730983530082,
"creator_user_name": "someone@example.com",
"job_id": 478701692316314,
"run_as_user_name": "someone@example.com",
"settings": {
"email_notifications": {
"no_alert_for_skipped_runs": false
},
"format": "MULTI_TASK",
"max_concurrent_runs": 1,
"name": "job_name",
"tasks": [
{
"email_notifications": {},
"notebook_task": {
"notebook_path": "/Workspace/Users/someone@example.com/directory",
"source": "WORKSPACE"
},
"run_if": "ALL_SUCCESS",
"task_key": "success",
"timeout_seconds": 0,
"webhook_notifications": {}
},
{
"depends_on": [
{
"task_key": "success"
}
],
"disable_auto_optimization": true,
"email_notifications": {},
"max_retries": 3,
"min_retry_interval_millis": 300000,
"notebook_task": {
"notebook_path": "/Workspace/Users/someone@example.com/directory",
"source": "WORKSPACE"
},
"retry_on_timeout": false,
"run_if": "ALL_SUCCESS",
"task_key": "fail",
"timeout_seconds": 0,
"webhook_notifications": {}
}
],
"timeout_seconds": 0,
"webhook_notifications": {}
}
}
Przykład: tworzenie zadania przy użyciu interfejsu wiersza polecenia
W poniższym przykładzie do utworzenia zadania użyto interfejsu wiersza polecenia usługi Databricks. To zadanie zawiera jedno zadanie, które uruchamia określony notatnik. Ten notatnik ma zależność od określonej wersji pakietu PyPI wheel. Aby uruchomić to zadanie, zadanie tymczasowo tworzy klaster, który eksportuje zmienną środowiskową o nazwie PYSPARK_PYTHON. Po uruchomieniu zadania klaster zostanie wyłączony.
Skopiuj i wklej następujący kod JSON do pliku. Aby uzyskać dostęp do formatu JSON dowolnego istniejącego zadania, wybierz opcję Wyświetl kod JSON w interfejsie użytkownika strony zadania.
{ "name": "My hello notebook job", "tasks": [ { "task_key": "my_hello_notebook_task", "notebook_task": { "notebook_path": "/Workspace/Users/someone@example.com/hello", "source": "WORKSPACE" } } ] }Uruchom następujące polecenie, zastępując
<file-path>ścieżką i nazwą właśnie utworzonego pliku.databricks jobs create --json @<file-path>
Uruchom zadanie przy użyciu CLI
Istnieją trzy sposoby uruchamiania zadania yoaur podczas korzystania z wiersza polecenia.
Zaplanowane. Jeśli definicja zadania (w formacie JSON) zawiera harmonogram, podobnie jak w poniższym przykładzie, zadanie zostanie automatycznie uruchomione zgodnie z harmonogramem.
"schedule": { "quartz_cron_expression": "46 0 9 * * ?", "timezone_id": "America/Los_Angeles", "pause_status": "UNPAUSED" }, "max_concurrent_runs": 1,Wyzwól za pomocą
run-now. Poleceniedatabricks jobs run-nowCLI wyzwala przebieg zadania, które zostało już utworzone.Wyzwalacz za pomocą polecenia
submit. Poleceniedatabricks jobs submitinterfejsu wiersza polecenia przyjmuje definicję zadania i wyzwala uruchomienie zadania.W programie
submitzadanie nie jest zapisywane i nie jest widoczne w interfejsie użytkownika. Jest uruchamiany raz i po zakończeniu nie istnieje już jako zadanie.Ponieważ nie są one zapisywane, przesłane zadania nie mogą być automatycznie zoptymalizowane pod kątem obliczeń bezserwerowych w przypadku awarii. Jeśli zadanie zakończy się niepowodzeniem, możesz użyć klasycznego środowiska obliczeniowego, aby określić potrzeby obliczeniowe dla zadania. Użyj
jobs createijobs run-now, aby utworzyć i uruchomić zadanie.
Rozpocznij korzystanie z zestawu SDK Databricks
Usługa Databricks udostępnia zestawy SDK, które umożliwiają automatyzowanie operacji przy użyciu popularnych języków programowania, takich jak Python, Java i Go. W tej sekcji pokazano, jak rozpocząć korzystanie z zestawu SDK języka Python w celu tworzenia zadań usługi Databricks i zarządzania nimi.
Możesz użyć zestawu SDK usługi Databricks z notesu Databricks lub swojej lokalnej stacji roboczej. Jeśli używasz lokalnej maszyny programistycznej, upewnij się, że najpierw ukończysz Wprowadzenie do zestawu SDK Databricks dla języka Python.
Notatka
Jeśli programujesz z poziomu notesu usługi Databricks i używasz klastra korzystającego z środowiska Databricks Runtime 12.2 LTS i poniżej, najpierw musisz zainstalować zestaw SDK usługi Databricks dla języka Python. Zobacz Instalowanie lub uaktualnianie zestawu SDK usługi Databricks dla języka Python.
Przykład: tworzenie zadania przy użyciu zestawu SDK języka Python
Poniższy przykładowy kod notesu tworzy zadanie, które uruchamia istniejący notes. Pobiera ścieżkę istniejącego notatnika oraz powiązane ustawienia zadań w zestawie z monitami.
Najpierw upewnij się, że zainstalowano poprawną wersję zestawu SDK:
%pip install --upgrade databricks-sdk==0.74.0
%restart_python
Następnie, aby utworzyć zadanie z wykorzystaniem notatnika, wykonaj następujące polecenie i odpowiedz na monity:
from databricks.sdk.service.jobs import JobSettings as Job
from databricks.sdk import WorkspaceClient
job_name = input("Provide a short name for the job, for example, my-job: ")
notebook_path = input("Provide the workspace path of the notebook to run, for example, /Users/someone@example.com/my-notebook: ")
task_key = input("Provide a unique key to apply to the job's tasks, for example, my-key: ")
test_sdk = Job.from_dict(
{
"name": job_name ,
"tasks": [
{
"task_key": task_key,
"notebook_task": {
"notebook_path": notebook_path,
"source": "WORKSPACE",
},
},
],
}
)
w = WorkspaceClient()
j = w.jobs.create(**test_sdk.as_shallow_dict())
print(f"View the job at {w.config.host}/#job/{j.job_id}\n")
Uruchamianie zadania przy użyciu zestawu SDK języka Python
Istnieją trzy sposoby uruchamiania zadania podczas korzystania z interfejsu API.
Zaplanowane. Jeśli definicja zadania (w formacie JSON) zawiera harmonogram, podobnie jak w poniższym przykładzie, zadanie zostanie automatycznie uruchomione zgodnie z harmonogramem.
"schedule": { "quartz_cron_expression": "46 0 9 * * ?", "timezone_id": "America/Los_Angeles", "pause_status": "UNPAUSED" }, "max_concurrent_runs": 1,Uruchomienie z
run-now. Interfejsjobs.run_nowAPI inicjuje wykonanie dla zadania, które już zostało utworzone.Wyzwól za pomocą
submit. Interfejsjobs.runs.submitAPI przyjmuje definicję zadania i wyzwala uruchomienie zadania.W programie
submitzadanie nie jest zapisywane i nie jest widoczne w interfejsie użytkownika. Uruchamia się raz, a po zakończeniu przestaje istnieć jako zadanie.Ponieważ nie są one zapisywane, przesłane zadania nie mogą być automatycznie zoptymalizowane pod kątem obliczeń bezserwerowych w przypadku awarii. Jeśli zadanie zakończy się niepowodzeniem, możesz użyć klasycznego środowiska obliczeniowego, aby określić potrzeby obliczeniowe dla zadania. Możesz też użyć polecenia
jobs.createijobs.run_now, aby utworzyć i uruchomić zadanie.
Rozpocznij korzystanie z interfejsu API REST usługi Databricks
Notatka
Databricks zaleca używanie interfejsu wiersza polecenia Databricks i Databricks SDK, chyba że używasz języka programowania, który nie ma odpowiedniego Databricks SDK.
Poniższy przykład wysyła żądanie do interfejsu API REST usługi Databricks w celu pobrania szczegółów pojedynczego zadania. Przyjęto założenie, DATABRICKS_HOST że zmienne środowiskowe i DATABRICKS_TOKEN zostały ustawione zgodnie z opisem w temacie Wykonywanie uwierzytelniania osobistego tokenu dostępu.
$ curl --request GET "https://${DATABRICKS_HOST}/api/2.2/jobs/get" \
--header "Authorization: Bearer ${DATABRICKS_TOKEN}" \
--data '{ "job": "11223344" }'
Aby uzyskać informacje na temat korzystania z interfejsu API REST usługi Databricks, zobacz dokumentację interfejsu API REST usługi Databricks.
Wyświetlanie zadań jako kodu
W obszarze roboczym usługi Databricks możesz wyświetlić reprezentację zadania w formacie JSON, YAML lub Python.
Na pasku bocznym obszaru roboczego usługi Azure Databricks kliknij pozycję Zadania i potoki i wybierz zadanie.
Kliknij kebab po lewej stronie przycisku Uruchom teraz , a następnie kliknij pozycję Wyświetl jako kod:
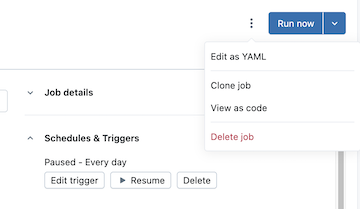
Kliknij pozycję YAML, Python lub JSON , aby wyświetlić zadanie jako kod w tym języku.
- W przypadku kodu YAML kliknij przycisk Kopiuj, a następnie wklej kod bezpośrednio do plików konfiguracji
*.yamlpakietu zasobów usługi Databricks, aby uwzględnić istniejące zadanie w pakiecie. Możesz również kliknąć przycisk Edytuj , aby zmodyfikować konfigurację zadania w języku YAML zamiast interfejsu użytkownika. - W przypadku języka Python wybierz pozycję Zestaw SDK usługi Databricks lub Pakiety zasobów usługi Databricks, a następnie kliknij pozycję Kopiuj.
- Kod języka Python dla zestawu SDK może służyć do tworzenia zadania w notesach lub lokalnie podczas korzystania z zestawu SDK języka Python usługi Databricks. Zobacz Tworzenie zadania przy użyciu zestawu SDK języka Python.
- Kod języka Python dla pakietów może służyć do uwzględnienia zadania w pakiecie przy użyciu języka Python. Zobacz Konfiguracja pakietu w języku Python.
- W przypadku formatu JSON kliknij pozycję Kopiuj i użyj kodu, aby utworzyć, zaktualizować lub pobrać zadanie przy użyciu interfejsu wiersza polecenia usługi Databricks, zestawów SDK usługi Databricks lub interfejsu API REST usługi Databricks.
- W przypadku kodu YAML kliknij przycisk Kopiuj, a następnie wklej kod bezpośrednio do plików konfiguracji
Czyszczenie
Aby usunąć wszystkie utworzone zadania, uruchom databricks jobs delete <job-id> z interfejsu wiersza polecenia usługi Databricks lub usuń zadanie bezpośrednio z interfejsu użytkownika obszaru roboczego usługi Databricks.
Następne kroki
- Aby dowiedzieć się więcej na temat Databricks CLI, zobacz Co to jest Databricks CLI? i Polecenia Databricks CLI, aby dowiedzieć się o innych grupach poleceń.
- Aby dowiedzieć się więcej na temat zestawu SDK usługi Databricks, zobacz Zestawy SDK usługi Azure Databricks.
- Aby dowiedzieć się więcej na temat ciągłej integracji/ciągłego wdrażania przy użyciu usługi Databricks, zobacz Pakiety zasobów usługi Databricks i Databricks Terraform provider i Terraform CDKTF dla Databricks.
- Aby zapoznać się z kompleksowym omówieniem wszystkich narzędzi deweloperskich, zobacz Lokalne narzędzia programistyczne.