Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
For each zadania przekazują tablice parametrów do zadań zagnieżdżonych w sposób iteracyjny, aby każdemu zagnieżdżonemu zadaniu dostarczyć informacji potrzebnych do jego działania. Tablice parametrów są ograniczone do 10 000 znaków lub 48 KB, jeśli używasz odwołań do wartości zadania, aby je przekazać. Jeśli masz większą ilość danych do przekazania do zagnieżdżonych zadań, nie można bezpośrednio użyć parametrów wejściowych, wartości zadania ani parametrów zadań jako sposobu na przekazanie tych danych.
Jedną z alternatyw dla przekazywania pełnych danych jest przechowywanie danych zadania jako pliku JSON i przekazywanie klucza odnośnika (do danych JSON) za pomocą danych wejściowych zadania zamiast pełnych danych. Zagnieżdżone zadania mogą używać klucza do pobierania określonych danych, które są potrzebne dla każdej iteracji.
Poniższy przykład przedstawia przykładowy plik konfiguracji JSON i sposób przekazywania parametrów do zagnieżdżonego zadania, które wyszukuje wartości w konfiguracji JSON.
Przykładowa konfiguracja kodu JSON
Ta przykładowa konfiguracja to lista kroków z parametrami (args) dla każdej iteracji (pokazano tylko trzy kroki w tym przykładzie). Załóżmy, że ten plik JSON jest zapisywany jako /Workspace/Users/<user>/copy-filtered-table-config.json. Odwołujemy się do tego w zagnieżdżonym zadaniu.
{
"steps": [
{
"key": "table_1",
"args": {
"catalog": "my-catalog",
"schema": "my-schema",
"source_table": "raw_data_table_1",
"destination_table": "filtered_table_1",
"filter_column": "col_a",
"filter_value": "value_1"
}
}
{
"key": "table_2",
"args": {
"catalog": "my-catalog",
"schema": "my-schema",
"source_table": "raw_data_table_2",
"destination_table": "filtered_table_2",
"filter_column": "col_b",
"filter_value": "value_2"
}
},
{
"key": "table_3",
"args": {
"catalog": "my-catalog",
"schema": "my-schema",
"source_table": "raw_data_table_3",
"destination_table": "filtered_table_3",
"filter_column": "col_c",
"filter_value": "value_3"
}
},
]
}
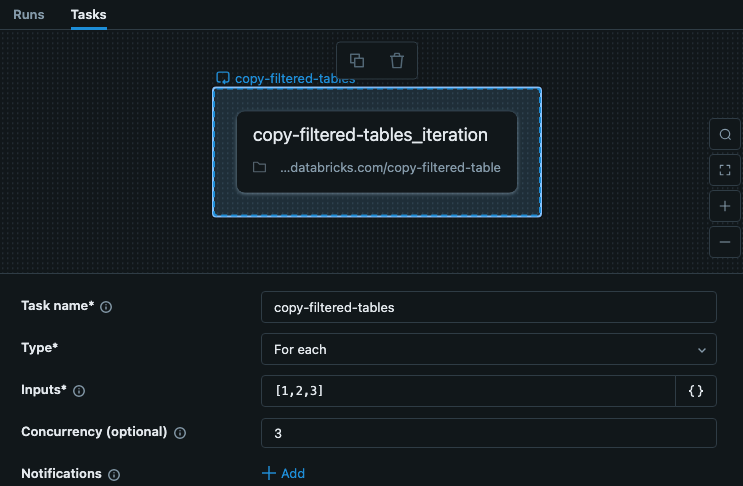
Przykładowe For each zadanie
Zadanie For each w twojej pracy obejmuje dane wejściowe w kluczach dla każdej iteracji. W tym przykładzie pokazano zadanie o nazwie copy-filtered-tables z danymi wejściowymi ustawionymi na ["table_1","table_2","table_3"]. Ta lista jest ograniczona do 10 000 znaków, ale ponieważ po prostu przekazujesz klucze, jest ona znacznie mniejsza niż pełne dane.
W tym przykładzie kroki nie zależą od innych kroków lub zadań, więc możemy ustawić współbieżność większą niż 1, aby zadanie działało szybciej.
Przykładowe zadanie zagnieżdżone
Zagnieżdżonemu zadaniu przekazywane są dane wejściowe z zadania nadrzędnego For each. W tym przypadku ustawiamy dane wejściowe, aby były używane jako Key w pliku konfiguracji. Na poniższym obrazie przedstawiono zagnieżdżone zadanie, w tym skonfigurowanie parametru o nazwie key z wartością {{input}}.
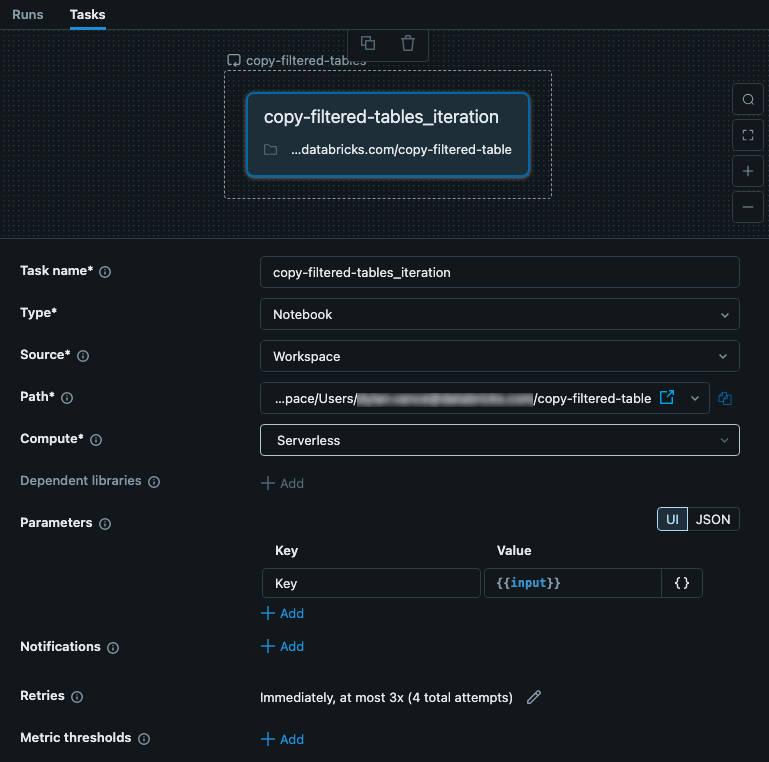
To zadanie jest notesem zawierającym kod. W notesie możesz użyć następującego kodu w języku Python, aby odczytać dane wejściowe i użyć go jako klucza do pliku JSON konfiguracji. Dane z pliku JSON są używane do odczytywania, filtrowania i zapisywania danych z tabeli.
# copy-filtered-table (iteratable task code to read a table, filter by a value, and write as a new table)
from pyspark.sql.functions import expr
from types import SimpleNamespace
import json
# If the notebook is run outside of a job with a key parameter, this provides
# a default. This allows testing outside of a For each task
dbutils.widgets.text("key", "table_1", "key")
# load configuration (note that the path must be set to valid configuration file)
config_path = "/Workspace/Users/<user>/copy-filtered-table-config.json"
with open(config_path, "r") as file:
config = json.loads(file.read())
# look up step and arguments
key = dbutils.widgets.get("key")
current_step = next((step for step in config['steps'] if step['key'] == key), None)
if current_step is None:
raise ValueError(f"Could not find step '{key}' in the configuration")
args = SimpleNamespace(**current_step["args"])
# read the source table defined for the step, and filter it
df = spark.read.table(f"{args.catalog}.{args.schema}.{args.source_table}") \
.filter(expr(f"{args.filter_column} like '%{args.filter_value}%'"))
# write the filtered table to the destination
df.write.mode("overwrite").saveAsTable(f"{args.catalog}.{args.schema}.{args.destination_table}")