Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W inżynierii danych backfilling odnosi się do procesu wstecznego przetwarzania danych historycznych za pośrednictwem potoku danych, który został zaprojektowany do przetwarzania danych bieżących lub strumieniowych.
Zazwyczaj jest to oddzielny przepływ wysyłający dane do istniejących tabel. Na poniższej ilustracji przedstawiono przepływ wypełniania wysyłający dane historyczne do brązowych tabel w potoku.
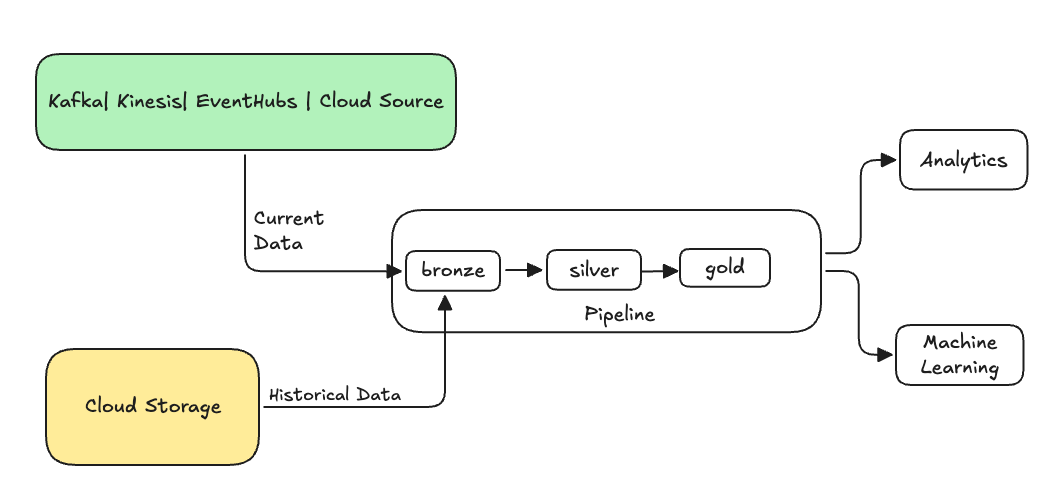
Niektóre scenariusze, które mogą wymagać wypełnienia danych:
- Przetwarzanie danych historycznych ze starszego systemu w celu wytrenowania modelu uczenia maszynowego (ML) lub utworzenia panelu analizy trendów historycznych.
- Ponowne przetwarzanie podzbioru danych z powodu problemu z jakością danych z nadrzędnymi źródłami danych.
- Wymagania biznesowe uległy zmianie i trzeba uzupełnić dane wstecz dla innego okresu czasowego, który nie był objęty początkowym kanałem przetwarzania danych.
- Logika biznesowa została zmieniona i trzeba ponownie przetworzyć zarówno dane historyczne, jak i bieżące.
Wypełnianie w Spark Declarative Pipelines w Lakeflow jest obsługiwane przez wyspecjalizowany przepływ dołączania, który korzysta z opcji ONCE. Aby uzyskać więcej informacji na temat opcji, zobacz append_flow lub ONCE).
Zagadnienia dotyczące uzupełniania danych historycznych do tabeli strumieniowej
- Zazwyczaj dołącz dane do brązowej tabeli przesyłania strumieniowego. Niższe warstwy srebra i złota będą pobierać nowe dane z warstwy z brązu.
- Upewnij się, że twoje przetwarzanie danych może zarządzać zduplikowanymi danymi bez błędów w przypadku wielokrotnego dodawania tych samych danych.
- Upewnij się, że schemat danych historycznych jest zgodny z bieżącym schematem danych.
- Rozważ rozmiar woluminu danych i wymaganą umowę SLA czasu przetwarzania, a następnie odpowiednio skonfiguruj rozmiary klastra i partii.
Przykład: dodawanie wypełnienia do istniejącego potoku
Zakładając, że masz przepływ danych, który pozyskuje nieprzetworzone dane rejestracji wydarzeń ze źródła w chmurze, począwszy od 01 stycznia 2025 r. Później zdajesz sobie sprawę, że chcesz wypełnić dane historyczne z poprzednich trzech lat na potrzeby podrzędnego raportowania i analizy przypadków użycia. Wszystkie dane są w jednej lokalizacji, partycjonowane według roku, miesiąca i dnia w formacie JSON.
Potok początkowy
** Oto kod początkowego potoku, który przyrostowo wczytuje nieprzetworzone dane rejestracji zdarzeń z magazynu w chmurze.
Python
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
incremental_load_path = f"{source_root_path}/*/*/*"
# create a streaming table and the default flow to ingest streaming events
@dp.table(name="registration_events_raw", comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2025-01-01T00:00:00.000+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}") # safeguard to not process data before begin_year
)
SQL
-- create a streaming table and the default flow to ingest streaming events
CREATE OR REFRESH STREAMING LIVE TABLE registration_events_raw AS
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025'; -- safeguard to not process data before begin_year
W tej sekcji używamy opcji modifiedAfter Auto Loader, aby upewnić się, że nie przetwarzamy wszystkich danych ze ścieżki przechowywania w chmurze. Przetwarzanie przyrostowe jest odcięte na tej granicy.
Wskazówka
Inne źródła danych, takie jak Kafka, Kinesis i Azure Event Hubs, mają równoważne opcje czytnika, aby osiągnąć to samo zachowanie.
Wypełnianie danych z poprzednich 3 lat
Teraz chcesz dodać jeden lub więcej przepływów, aby uzupełnić poprzednie dane. W tym przykładzie wykonaj następujące czynności:
- Użyj
append onceprzepływu. Wykonuje to jednorazowe wypełnianie bez kontynuowania działania po tym pierwszym wypełnianiu. Kod pozostaje w pipeline, a jeśli pipeline zostanie kiedykolwiek w pełni odświeżony, uzupełnianie braków jest uruchamiane ponownie. - Utwórz trzy przepływy uzupełniania, każdy na jeden rok (w tym przypadku dane są dzielone w ścieżce według roku). W przypadku języka Python parametryzujemy tworzenie przepływów, ale w języku SQL powtarzamy kod trzy razy, raz dla każdego przepływu.
Jeśli pracujesz nad własnym projektem i nie korzystasz z obliczeń serverless, możesz zaktualizować maksymalną liczbę pracowników dla potoku. Zwiększenie maksymalnej liczby pracowników gwarantuje, że masz zasoby do przetwarzania danych historycznych przy jednoczesnym przetwarzaniu bieżących danych przesyłanych strumieniowo zgodnie z oczekiwanym poziomem usługi (SLA).
Wskazówka
Jeśli używasz bezserwerowych obliczeń z rozszerzonym skalowaniem automatycznym (ustawieniem domyślnym), klaster automatycznie zwiększa rozmiar po wzroście obciążenia.
Python
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
backfill_years = spark.conf.get("backfill_years") # e.g. "2024,2023,2022"
incremental_load_path = f"{source_root_path}/*/*/*"
# meta programming to create append once flow for a given year (called later)
def setup_backfill_flow(year):
backfill_path = f"{source_root_path}/year={year}/*/*"
@dp.append_flow(
target="registration_events_raw",
once=True,
name=f"flow_registration_events_raw_backfill_{year}",
comment=f"Backfill {year} Raw registration events")
def backfill():
return (
spark
.read
.format("json")
.option("inferSchema", "true")
.load(backfill_path)
)
# create the streaming table
dp.create_streaming_table(name="registration_events_raw", comment="Raw registration events")
# append the original incremental, streaming flow
@dp.append_flow(
target="registration_events_raw",
name="flow_registration_events_raw_incremental",
comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2024-12-31T23:59:59.999+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}")
)
# parallelize one time multi years backfill for faster processing
# split backfill_years into array
for year in backfill_years.split(","):
setup_backfill_flow(year) # call the previously defined append_flow for each year
SQL
-- create the streaming table
CREATE OR REFRESH STREAMING TABLE registration_events_raw;
-- append the original incremental, streaming flow
CREATE FLOW
registration_events_raw_incremental
AS INSERT INTO
registration_events_raw BY NAME
SELECT * FROM STREAM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025';
-- one time backfill 2024
CREATE FLOW
registration_events_raw_backfill_2024
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2024/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2023
CREATE FLOW
registration_events_raw_backfill_2023
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2023/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2022
CREATE FLOW
registration_events_raw_backfill_2022
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2022/*/*",
format => "json",
inferColumnTypes => true
);
Ta implementacja wyróżnia kilka ważnych wzorców.
Separacja obaw
- Przetwarzanie przyrostowe jest niezależne od operacji uzupełniania braków.
- Każdy przepływ ma własne ustawienia konfiguracji i optymalizacji.
- Istnieje wyraźne rozróżnienie między operacjami przyrostowymi a uzupełniania.
Kontrolowane wykonywanie
- Użycie opcji
ONCEgwarantuje, że każde wypełnienie jest uruchamiane dokładnie raz. - Przepływ wypełniania pozostaje na grafie potoku, ale staje się bezczynny po zakończeniu. Jest on gotowy do użycia podczas pełnego odświeżania, automatycznie.
- Istnieje wyraźny ślad audytu operacji uzupełniania w definicji potoku.
Optymalizacja przetwarzania
- Duże wypełnienie można podzielić na wiele mniejszych wypełnień w celu szybszego przetwarzania oraz kontroli nad przetwarzaniem.
- Użycie rozszerzonego skalowania automatycznego dynamicznie skaluje rozmiar klastra na podstawie bieżącego obciążenia klastra.
Ewolucja schematu
- Korzystanie z
schemaEvolutionMode="addNewColumns"obsługuje zmiany schematu w sposób bezproblemowy. - Masz jednolite wnioskowanie schematu dla danych historycznych i bieżących.
- Istnieje bezpieczna obsługa nowych kolumn w nowszych danych.