Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano sposób tworzenia i używania funkcji na żądanie w usłudze Azure Databricks.
Aby korzystać z funkcji na żądanie, obszar roboczy musi być włączony dla usługi Unity Catalog i należy użyć środowiska Databricks Runtime 13.3 LTS ML lub nowszego.
Co to są funkcje na żądanie?
Wyrażenie "Na żądanie" odnosi się do funkcji, których wartości nie są znane przed upływem czasu, ale są obliczane w czasie wnioskowania. W usłudze Azure Databricks używasz funkcji zdefiniowanych przez użytkownika (UDF) języka Python, aby określić sposób obliczania funkcji na żądanie. Te funkcjonalności są zarządzane przez Unity Catalog i można je odnaleźć za pośrednictwem Catalog Explorer .
Wymagania
- Aby utworzyć zestaw treningowy przy użyciu funkcji zdefiniowanej przez użytkownika (UDF) lub utworzyć Feature Serving endpoint, musisz mieć
USE CATALOGuprawnienia do katalogusystemiUSE SCHEMAuprawnienia do schematusystem.information_schemaw Unity Catalog.
Workflow
Aby obliczyć funkcje na żądanie, należy określić funkcję zdefiniowaną przez użytkownika języka Python (UDF), która opisuje sposób obliczania wartości funkcji.
- Podczas trenowania udostępniasz tę funkcję i jej powiązania wejściowe w
feature_lookupsparametrze interfejsucreate_training_setAPI. - Należy zarejestrować wytrenowany model przy użyciu metody
log_modelmagazynu funkcji . Dzięki temu model automatycznie ocenia funkcje na żądanie, gdy jest używany do wnioskowania. - W przypadku oceniania wsadowego interfejs API
score_batchautomatycznie oblicza i zwraca wszystkie wartości funkcji, w tym funkcje na żądanie. - Gdy udostępniasz model z usługą Mosaic AI Model Serving, model automatycznie używa funkcji zdefiniowanej przez użytkownika języka Python do obliczania funkcji na żądanie dla każdego żądania oceniania.
Tworzenie funkcji zdefiniowanej przez użytkownika języka Python
Funkcję UDF języka Python można utworzyć przy użyciu kodu SQL lub Python. W poniższych przykładach utworzono funkcję Python UDF w katalogu main i schemacie default.
Python
Aby użyć języka Python, należy najpierw zainstalować databricks-sdk[openai] pakiet. Użyj %pip install w następujący sposób:
%pip install unitycatalog-ai[databricks]
dbutils.library.restartPython()
Następnie użyj kodu podobnego do poniższego, aby utworzyć funkcję UDF języka Python:
from unitycatalog.ai.core.databricks import DatabricksFunctionClient
client = DatabricksFunctionClient()
CATALOG = "main"
SCHEMA = "default"
def add_numbers(number_1: float, number_2: float) -> float:
"""
A function that accepts two floating point numbers, adds them,
and returns the resulting sum as a float.
Args:
number_1 (float): The first of the two numbers to add.
number_2 (float): The second of the two numbers to add.
Returns:
float: The sum of the two input numbers.
"""
return number_1 + number_2
function_info = client.create_python_function(
func=add_numbers,
catalog=CATALOG,
schema=SCHEMA,
replace=True
)
Język SQL usługi Databricks
Poniższy kod pokazuje, jak używać Databricks SQL do tworzenia UDF (funkcji zdefiniowanej przez użytkownika) w języku Python.
%sql
CREATE OR REPLACE FUNCTION main.default.add_numbers(x INT, y INT)
RETURNS INT
LANGUAGE PYTHON
COMMENT 'add two numbers'
AS $$
def add_numbers(n1: int, n2: int) -> int:
return n1 + n2
return add_numbers(x, y)
$$
Po uruchomieniu kodu możesz przejść przez trzypoziomową przestrzeń nazw w eksploratorze katalogu , aby wyświetlić definicję funkcji:
funkcja 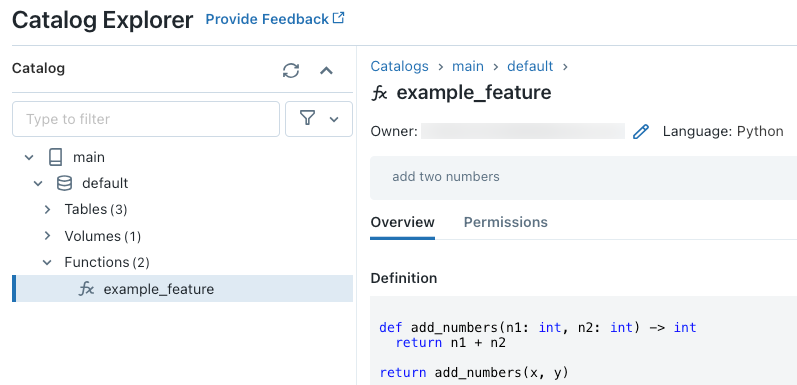
Aby uzyskać więcej informacji na temat tworzenia funkcji zdefiniowanych przez użytkownika języka Python, zobacz Rejestrowanie funkcji zdefiniowanej przez użytkownika języka Python w Unity Catalog i podręcznik języka SQL.
Jak obsługiwać brakujące wartości funkcji
Gdy funkcja UDF języka Python zależy od wyniku funkcjiLookup, wartość zwrócona, jeśli żądany klucz odnośnika nie zostanie znaleziony, zależy od środowiska. W przypadku użycia score_batchzwracana wartość to None. W przypadku korzystania z usługi online zwracana wartość to float("nan").
Poniższy kod to przykład obsługi obu przypadków.
%sql
CREATE OR REPLACE FUNCTION square(x INT)
RETURNS INT
LANGUAGE PYTHON AS
$$
import numpy as np
if x is None or np.isnan(x):
return 0
return x * x
$$
Trenowanie modelu przy użyciu funkcji na żądanie
Aby wytrenować model, należy użyć FeatureFunctionelementu , który jest przekazywany do interfejsu create_training_set API w parametrze feature_lookups .
Poniższy przykładowy kod używa funkcji UDF main.default.example_feature języka Python zdefiniowanej w poprzedniej sekcji.
# Install databricks-feature-engineering first with:
# %pip install databricks-feature-engineering
# dbutils.library.restartPython()
from databricks.feature_engineering import FeatureEngineeringClient
from databricks.feature_engineering import FeatureFunction, FeatureLookup
from sklearn import linear_model
fe = FeatureEngineeringClient()
features = [
# The feature 'on_demand_feature' is computed as the sum of the input value 'new_source_input'
# and the pre-materialized feature 'materialized_feature_value'.
# - 'new_source_input' must be included in base_df and also provided at inference time.
# - For batch inference, it must be included in the DataFrame passed to 'FeatureEngineeringClient.score_batch'.
# - For real-time inference, it must be included in the request.
# - 'materialized_feature_value' is looked up from a feature table.
FeatureFunction(
udf_name="main.default.example_feature", # UDF must be in Unity Catalog so uses a three-level namespace
input_bindings={
"x": "new_source_input",
"y": "materialized_feature_value"
},
output_name="on_demand_feature",
),
# retrieve the prematerialized feature
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id'
)
]
# base_df includes the columns 'id', 'new_source_input', and 'label'
training_set = fe.create_training_set(
df=base_df,
feature_lookups=features,
label='label',
exclude_columns=['id', 'new_source_input', 'materialized_feature_value'] # drop the columns not used for training
)
# The training set contains the columns 'on_demand_feature' and 'label'.
training_df = training_set.load_df().toPandas()
# training_df columns ['materialized_feature_value', 'label']
X_train = training_df.drop(['label'], axis=1)
y_train = training_df.label
model = linear_model.LinearRegression().fit(X_train, y_train)
Określanie wartości domyślnych
Aby określić wartości domyślne dla funkcji, użyj parametru default_values w pliku FeatureLookup.
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id',
default_values={
"materialized_feature_value": 0
}
)
Jeśli nazwy kolumn funkcji zostaną zmienione przy użyciu parametru rename_outputs , default_values należy użyć nazw funkcji o zmienionej nazwie.
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id',
rename_outputs={"materialized_feature_value": "feature_value"},
default_values={
"feature_value": 0
}
)
Zaloguj model i zarejestruj go w Unity Catalog
Modele z metadanymi funkcji można zarejestrować w katalogu Unity. Do budowania modelu muszą być używane tabele cech przechowywane w katalogu Unity.
Aby upewnić się, że model automatycznie ocenia funkcje na żądanie podczas wnioskowania, należy ustawić identyfikator URI rejestru, a następnie zarejestrować model w następujący sposób:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="main.default.model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model"
)
Jeśli funkcja UDF języka Python, która definiuje funkcje na żądanie, importuje wszystkie pakiety języka Python, należy określić te pakiety przy użyciu argumentu extra_pip_requirements. Na przykład:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model",
extra_pip_requirements=["scikit-learn==1.20.3"]
)
Ograniczenie
Funkcje na żądanie mogą zwracać wszystkie typy danych obsługiwane przez magazyn funkcji z wyjątkiem MapType i ArrayType.
Przykłady notesów: funkcje na żądanie
W poniższym notesie przedstawiono przykład trenowania i oceniania modelu korzystającego z funkcji na żądanie.
Podstawowy notes demonstracyjny funkcji na żądanie
W poniższym notesie przedstawiono przykład modelu rekomendacji restauracji. Lokalizacja restauracji jest wyszukiwana w internetowej tabeli usługi Databricks. Bieżąca lokalizacja użytkownika jest wysyłana w ramach żądania oceniania. Model używa funkcji na żądanie, aby obliczyć odległość w czasie rzeczywistym od użytkownika do restauracji. Ta odległość jest następnie używana jako dane wejściowe do modelu.