Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ciągła integracja/ciągłe dostarczanie (ciągła integracja i ciągłe dostarczanie) odnosi się do zautomatyzowanego procesu tworzenia, wdrażania, monitorowania i obsługi aplikacji. Automatyzując kompilowanie, testowanie i wdrażanie kodu, zespoły programistyczne mogą częściej i bardziej niezawodnie dostarczać wydania niż w przypadku wciąż powszechnych procesów ręcznych w wielu zespołach inżynierii danych i nauki o danych. CI/CD dla uczenia maszynowego łączy techniki metodyk MLOps, DataOps, ModelOps i DevOps.
W tym artykule opisano, w jaki sposób Databricks wspiera CI/CD (ciągłą integrację i ciągłe wdrażanie) dla rozwiązań uczenia maszynowego. W aplikacjach uczenia maszynowego CI/CD jest ważne nie tylko dla zasobów kodu, ale również stosowane do potoków danych, obejmując zarówno dane wejściowe, jak i wyniki generowane przez model.

Elementy procesu uczenia maszynowego, które wymagają ciągłej integracji/ciągłego wdrażania
Jednym z wyzwań związanych z programowaniem uczenia maszynowego jest to, że różne zespoły posiadają różne części procesu. Zespoły mogą polegać na różnych narzędziach i mają różne harmonogramy wydania. Usługa Azure Databricks udostępnia pojedynczą, ujednoliconą platformę danych i uczenia maszynowego ze zintegrowanymi narzędziami w celu poprawy wydajności zespołów oraz zapewnienia spójności i powtarzalności potoków danych i uczenia maszynowego.
Ogólnie dla zadań uczenia maszynowego należy śledzić następujące elementy w zautomatyzowanym przepływie pracy ciągłej integracji i wdrażania (CI/CD):
- Dane szkoleniowe, w tym jakość danych, zmiany schematu i zmiany dystrybucji.
- Ścieżki wejścia danych.
- Kod do trenowania, walidacji i obsługi modelu.
- Przewidywania i wydajność modelu.
Zintegruj Databricks z procesami CI/CD
Metodyki MLOps, DataOps, ModelOps i DevOps odnoszą się do integracji procesów programistycznych z "operacjami" — dzięki czemu procesy i infrastruktura są przewidywalne i niezawodne. W tym zestawie artykułów opisano sposób integrowania zasad operacji ("ops") z przepływami pracy uczenia maszynowego na platformie Databricks.
Usługa Databricks obejmuje wszystkie składniki wymagane do cyklu życia uczenia maszynowego, w tym narzędzia do tworzenia "konfiguracji jako kodu", aby zapewnić powtarzalność i "infrastrukturę jako kod" w celu zautomatyzowania aprowizacji usług w chmurze. Obejmuje również usługi rejestrowania i zgłaszania alertów, które ułatwiają wykrywanie i rozwiązywanie problemów w przypadku ich wystąpienia.
DataOps: niezawodne i bezpieczne dane
Dobre modele uczenia maszynowego zależą od niezawodnych potoków danych i infrastruktury. Dzięki platformie analizy danych usługi Databricks cały potok danych od pozyskiwania danych do danych wyjściowych z obsługiwanego modelu znajduje się na jednej platformie i używa tego samego zestawu narzędzi, co ułatwia produktywność, powtarzalność, udostępnianie i rozwiązywanie problemów.

Zadania i narzędzia DataOps w Databricks
Tabela zawiera listę typowych zadań i narzędzi usługi DataOps w usłudze Databricks:
| Zadanie DataOps | Narzędzie w usłudze Databricks |
|---|---|
| Pozyskiwanie i przekształcanie danych | Automatyczne ładowanie i platforma Apache Spark |
| Śledzenie zmian danych, w tym wersjonowanie i śledzenie pochodzenia danych. | tabele delty |
| Tworzenie potoków przetwarzania danych, zarządzanie nimi i monitorowanie ich | Potoki deklaratywne platformy Spark w usłudze Lakeflow |
| Zapewnienie bezpieczeństwa danych i zarządzania. | Katalog Unity |
| Eksploracyjna analiza danych i dashboardy | Databricks SQL, Pulpity i notatniki Databricks |
| Ogólne kodowanie | Databricks SQL i notatniki Databricks |
| Planowanie potoków danych | Zadania lakeflow |
| Automatyzowanie ogólnych przepływów pracy | Zadania lakeflow |
| Tworzenie, przechowywanie i odnajdywanie funkcji na potrzeby trenowania modelu oraz zarządzanie nimi | Magazyn funkcji usługi Databricks |
| Monitorowanie danych | Monitorowanie jakości danych |
ModelOps: programowanie i cykl życia modelu
Opracowanie modelu wymaga serii eksperymentów oraz sposobu śledzenia i porównywania warunków i wyników tych eksperymentów. Platforma Inteligencji Danych Databricks obejmuje MLflow do śledzenia rozwoju modeli oraz Rejestr Modeli MLflow do zarządzania cyklem życia modelu, w tym fazą przygotowania, obsługą i przechowywaniem artefaktów modelu.
Po wydaniu modelu do środowiska produkcyjnego wiele elementów może się zmienić, co może mieć wpływ na jego wydajność. Oprócz monitorowania wydajności przewidywania modelu należy również monitorować dane wejściowe pod kątem zmian jakości lub cech statystycznych, które mogą wymagać ponownego trenowania modelu.
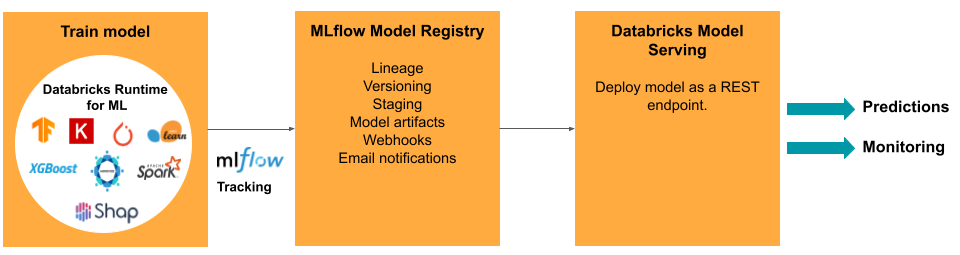
Zadania i narzędzia metody ModelOps w usłudze Databricks
Tabela zawiera listę typowych zadań i narzędzi metodyki ModelOps udostępnianych przez usługę Databricks:
| zadanie ModelOps | Narzędzie w usłudze Databricks |
|---|---|
| Śledzenie rozwoju modeli | Śledzenie modelu MLflow |
| Zarządzanie cyklem życia modelu | Modele w katalogu Unity |
| Kontrola wersji kodu modelu i udostępnianie | Foldery Git usługi Databricks |
| Tworzenie modelu bez kodu | AutoML |
| Monitorowanie modelu | Profilowanie danych |
DevOps: produkcja i automatyzacja
Platforma Databricks obsługuje modele uczenia maszynowego w środowisku produkcyjnym z następującymi elementami:
- Ścieżka danych i modeli od początku do końca: od modeli w środowisku produkcyjnym z powrotem do pierwotnego źródła danych, na tej samej platformie.
- Obsługa modelu na poziomie produkcyjnym: automatycznie skaluje w górę lub w dół w zależności od potrzeb biznesowych.
- Zadania: automatyzuje zadania i tworzy zaplanowane przepływy pracy uczenia maszynowego.
- Foldery Git: przechowywanie wersji kodu i udostępnianie ich z obszaru roboczego, pomaga również zespołom w przestrzeganiu najlepszych rozwiązań w zakresie inżynierii oprogramowania.
- Pakiety zasobów usługi Databricks: automatyzuje tworzenie i wdrażanie zasobów usługi Databricks, takich jak zadania, zarejestrowane modele i obsługa punktów końcowych.
- Databricks Terraform provider: Automatyzuje wdrażanie infrastruktury w chmurach na potrzeby zadań związanych z wnioskowaniem maszynowym, obsługą punktów końcowych oraz przygotowywaniem cech.
Obsługa modelu
W przypadku wdrażania modeli w środowisku produkcyjnym rozwiązanie MLflow znacznie upraszcza proces, zapewniając wdrożenie jednokrotne jako zadanie wsadowe dla dużych ilości danych lub jako punkt końcowy REST w klastrze skalowania automatycznego. Integracja Feature Store usługi Databricks z platformą MLflow zapewnia również spójność funkcji podczas treningu i serwowania; ponadto modele MLflow mogą automatycznie wyszukiwać funkcje z Feature Store, nawet w przypadku serwowania online o małych opóźnieniach.
Platforma Databricks obsługuje wiele opcji wdrażania modelu:
- Kod i kontenery.
- Obsługa wsadowa.
- Obsługa online o małych opóźnieniach.
- Obsługa na urządzeniu lub krawędzi.
- Architektura multi-cloud, na przykład trenowanie modelu w jednej chmurze i wdrażanie go za pomocą innej.
Aby uzyskać więcej informacji, zobacz Mosaic AI Model Serving (Obsługa modelu mozaiki sztucznej inteligencji).
Stanowiska
Zadania lakeflow umożliwiają automatyzowanie i planowanie dowolnego typu obciążenia — od ETL do uczenia maszynowego. Usługa Databricks obsługuje również integracje z popularnymi orkiestratorami innych firm , takimi jak Airflow.
Katalogi Git
Platforma Databricks obejmuje pomoc techniczną usługi Git w obszarze roboczym, aby pomóc zespołom w przestrzeganiu najlepszych rozwiązań w zakresie inżynierii oprogramowania przez wykonywanie operacji usługi Git za pośrednictwem interfejsu użytkownika. Administratorzy i inżynierowie DevOps mogą używać interfejsów API do konfigurowania automatyzacji za pomocą ulubionych narzędzi ciągłej integracji/ciągłego wdrażania (CI/CD). Usługa Databricks obsługuje dowolny typ wdrożenia usługi Git, w tym sieci prywatne.
Aby uzyskać więcej informacji na temat najlepszych praktyk dotyczących tworzenia kodu przy użyciu folderów Git usługi Databricks, zobacz Przepływy pracy CI/CD z integracją Git i foldery Git usługi Databricks oraz Używanie CI/CD. Te techniki, wraz z interfejsem API REST usługi Databricks, umożliwiają tworzenie zautomatyzowanych procesów wdrażania przy użyciu funkcji GitHub Actions, potoków usługi Azure DevOps lub zadań serwera Jenkins.
Unity Catalog dla zarządzania i bezpieczeństwa
Platforma Databricks obejmuje Unity Catalog, który umożliwia administratorom skonfigurowanie szczegółowej kontroli dostępu, zasad bezpieczeństwa i zarządzania dla wszystkich danych i zasobów AI na platformie Databricks.