Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ten artykuł zawiera dwa przykłady modeli rekomendacji opartych na uczeniu głębokim w usłudze Azure Databricks. W porównaniu z tradycyjnymi modelami rekomendacji modele uczenia głębokiego mogą osiągać wyniki o wyższej jakości i skalować do większych ilości danych. W miarę rozwoju tych modeli usługa Databricks zapewnia platformę do efektywnego trenowania modeli rekomendacji na dużą skalę, które mogą obsługiwać setki milionów użytkowników.
Ogólny system rekomendacji można wyświetlić jako lejek ze etapami przedstawionymi na diagramie.
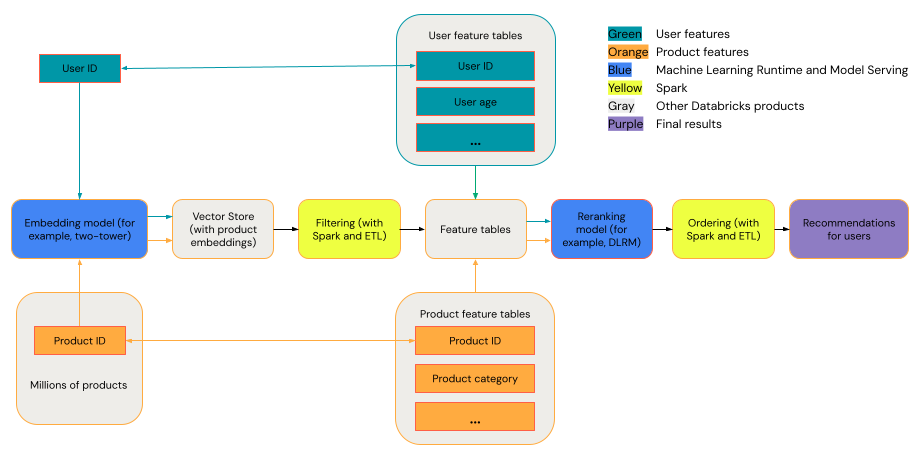
Niektóre modele, takie jak model dwuwieżowy, działają lepiej jako modele wyszukiwania. Te modele są mniejsze i mogą skutecznie działać na milionach punktów danych. Inne modele, takie jak DLRM lub DeepFM, działają lepiej jako modele ponownego klasyfikowania. Modele te mogą przyjmować więcej danych, są większe i mogą udostępniać szczegółowe zalecenia.
Wymagania
Środowisko uruchomieniowe Databricks 14.3 LTS ML
Narzędzia
Przykłady w tym artykule ilustrują następujące narzędzia:
- TorchDistributor: TorchDistributor to struktura, która umożliwia uruchamianie trenowania modelu PyTorch na dużą skalę w usłudze Databricks. Używa platformy Spark do orkiestracji i umożliwia skalowanie do tylu procesorów GPU, ile jest dostępnych w klastrze.
- Mosaic StreamingDataset: StreamingDataset zwiększa wydajność i skalowalność trenowania na dużych zestawach danych w usłudze Databricks, korzystając z takich funkcji jak wstępne pobieranie i przeplatanie.
- MLflow: MLflow umożliwia śledzenie parametrów, metryk i punktów kontrolnych modelu.
- TorchRec: Nowoczesne systemy rekomendacji używają tabelek wyszukiwania osadzania do obsługi milionów użytkowników i elementów w celu generowania rekomendacji wysokiej jakości. Większe rozmiary osadzania zwiększają wydajność modelu, ale wymagają znacznej ilości pamięci procesora GPU i konfiguracji z wieloma procesorami GPU. TorchRec udostępnia platformę do skalowania modeli rekomendacji i tabel wyszukiwania na wielu procesorach GPU, dzięki czemu idealnie nadaje się do dużego osadzania.
Przykład: rekomendacje dotyczące filmów przy użyciu architektury modelu z dwoma wieżami
Model dwu-wieżowy jest przeznaczony do obsługi zadań personalizacji na dużą skalę przez oddzielne przetwarzanie danych użytkowników i elementów przed ich połączeniem. Jest w stanie efektywnie generować setki lub tysiące przyzwoitych zaleceń dotyczących jakości. Model zazwyczaj oczekuje trzech danych wejściowych: funkcja user_id, funkcja product_id i etykieta binarna określająca, czy <użytkownik, interakcja produktu> była pozytywna (użytkownik kupił produkt) czy negatywna (użytkownik dał produktowi jedną ocenę gwiazdki). Dane wyjściowe modelu są osadzane zarówno dla użytkowników, jak i elementów, które są zwykle łączone (często przy użyciu produktu kropkowego lub podobieństwa cosinusu) w celu przewidywania interakcji między elementami użytkownika.
Ponieważ model dwuwężowy zapewnia osadzanie zarówno dla użytkowników, jak i produktów, można umieścić te osadzanie w indeksie wektorowym, takim jak Mozaika AI Vector Search, i wykonywać operacje podobne do wyszukiwania podobnych dla użytkowników i elementów. Można na przykład umieścić wszystkie elementy w przechowalni wektorów, a następnie dla każdego użytkownika wysłać zapytanie do tej przechowalni, aby znaleźć sto pierwszych elementów, których zakodowanie jest podobne do zakodowań użytkownika.
Poniższy przykładowy notatnik implementuje trening modelu z dwiema wieżami, korzystając z zestawu danych "Nauka z zestawów przedmiotów", aby przewidzieć prawdopodobieństwo, że użytkownik dobrze oceni określony film. Używa zestawu Danych Mozaika StreamingDataset do ładowania rozproszonych danych, TorchDistributor do trenowania modelu rozproszonego i MLflow do śledzenia i rejestrowania modeli.
Notatnik modelu rekomendacji z dwoma wieżami
Ten notatnik jest również dostępny w Marketplace usługi Databricks: notatnik modelu z dwiema wieżami
Uwaga
- Dane wejściowe dla modelu z dwiema wieżami są najczęściej cechami kategorialnymi user_id i product_id. Model można zmodyfikować tak, aby obsługiwał wiele wektorów funkcji dla użytkowników i produktów.
- Dane wyjściowe modelu z dwiema wieżami są zwykle wartościami binarnymi wskazującymi, czy użytkownik będzie miał pozytywną lub negatywną interakcję z produktem. Model można modyfikować dla innych aplikacji, takich jak regresja, klasyfikacja wieloklasowa i prawdopodobieństwo wielu akcji użytkownika (na przykład odrzucanie lub kupowanie). Złożone dane wyjściowe powinny być starannie implementowane, ponieważ konkurencyjne cele mogą obniżyć jakość osadzania generowanych przez model.
Przykład: trenowanie architektury DLRM przy użyciu syntetycznego zestawu danych
DLRM to najnowocześniejsze architektury sieci neuronowej zaprojektowane specjalnie do personalizacji i systemów rekomendacji. Łączy on dane wejściowe kategorii i liczbowe w celu efektywnego modelowania interakcji elementów użytkownika i przewidywania preferencji użytkownika. DlRM zwykle oczekuje danych wejściowych, które obejmują zarówno rozrzedłe funkcje (takie jak identyfikator użytkownika, identyfikator elementu, lokalizacja geograficzna lub kategoria produktu) i gęste funkcje (takie jak wiek użytkownika lub cena elementu). Dane wyjściowe usługi DLRM są zazwyczaj przewidywaniem zaangażowania użytkowników, takimi jak stawki kliknięć lub prawdopodobieństwo zakupu.
DlRMs oferują wysoce dostosowywalną strukturę, która może obsługiwać dane na dużą skalę, dzięki czemu nadaje się do złożonych zadań rekomendacji w różnych domenach. Ponieważ jest to większy model niż architektura dwóch wież, ten model jest często używany na etapie ponownego sortowania.
Poniższy przykładowy notatnik tworzy model DLRM w celu przewidywania etykiet binarnych przy użyciu cech gęstych (liczbowych) i cech rzadkich (kategorialnych). Używa syntetycznego zestawu danych do trenowania modelu, zestawu danych Mosaic StreamingDataset na potrzeby ładowania rozproszonych danych, TorchDistributor na potrzeby trenowania modelu rozproszonego i MLflow na potrzeby śledzenia i rejestrowania modeli.
Notatnik DLRM
Ten notatnik jest również dostępny na platformie Databricks Marketplace: DLRM notebook.
Przykład: dostrajanie modeli embeddingowych za pomocą llm-foundry na bezserwerowych platformach obliczeniowych GPU
Modele osadzania są krytycznym składnikiem nowoczesnych systemów rekomendacji, szczególnie w etapie pobierania, w którym umożliwiają wydajne wyszukiwanie podobieństw w milionach elementów. Chociaż model dwuwieżowy generuje osadzenia specyficzne dla zadań, wstępnie wytrenowane modele osadzeń mogą być dostosowane do zastosowań specyficznych dla domeny w celu poprawy jakości pobierania.
W poniższym przykładowym notesie pokazano, jak używać uczenia kontrastowego, aby dostosować model osadzania w stylu BERT na obliczeniach na bezserwerowych GPU (SGC). Używa frameworku llm-foundry z trenerem Composer do dostrajania modeli takich jak gte-large-en-v1.5, pracując z danymi przechowywanymi w tabelach Delta. W tym przykładzie użyto Mosaic Streaming do konwertowania danych na format Mosaic Data Shard (MDS) w celu ładowania danych w sposób rozproszony oraz biblioteki MLflow do śledzenia i rejestrowania modeli.
Dostosowywanie modelu osadzania w notatniku
Uwaga
- Model osadzania oczekuje danych z kolumnami dla
query_text,positive_passagei opcjonalnienegative_passages. - Dostrojone osadzania mogą być używane w magazynach wektorów na potrzeby operacji wyszukiwania podobieństwa, co umożliwia wydajne pobieranie odpowiednich elementów w systemach rekomendacji.
- Takie podejście jest szczególnie przydatne, gdy trzeba dostosować model osadzania ogólnego przeznaczenia do określonej domeny lub przypadku użycia.
Porównanie modeli dwuwieżowych i DLRM
W tabeli przedstawiono wskazówki dotyczące wybierania modelu rekomendacji do użycia.
| Typ modelu | Rozmiar zestawu danych wymagany do trenowania | Rozmiar modelu | Obsługiwane typy danych wejściowych | Obsługiwane typy danych wyjściowych | Przypadki użycia |
|---|---|---|---|---|---|
| Dwie wieże | Mniejszy | Mniejszy | Zazwyczaj dwie funkcje (user_id, product_id) | Głównie klasyfikacja binarna i generowanie osadzania | Generowanie setek lub tysięcy możliwych zaleceń |
| DLRM | Większy | Większy | Różne cechy kategoryczne i gęste (user_id, płeć, lokalizacja geograficzna, product_id, product_category, ...) | Klasyfikacja wieloklasowa, regresja, inne | "Wyszukiwanie z dużą dokładnością (polecanie dziesiątek bardzo istotnych elementów)" |
Podsumowując, model dwóch wież jest najbardziej odpowiedni do generowania tysięcy, dobrej jakości zaleceń bardzo wydajnie. Przykładem mogą być rekomendacje dotyczące filmów od dostawcy. Model DLRM najlepiej używać do generowania bardzo konkretnych zaleceń na podstawie większej ilości danych. Przykładem może być sprzedawca detaliczny, który chce przedstawić klientowi mniejszą liczbę produktów, które najprawdopodobniej kupią.