Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Interfejs użytkownika usługi Azure Databricks zawiera edytor SQL, którego można użyć do tworzenia zapytań, przeglądania dostępnych danych i tworzenia wizualizacji. Zapisane zapytania można również udostępniać innym członkom zespołu w obszarze roboczym. W tym artykule wyjaśniono, jak używać edytora SQL do pisania, uruchamiania zapytań i zarządzania nimi. Aby dowiedzieć się, jak włączyć i pracować z nowym edytorem SQL, zobacz Pisanie zapytań i eksplorowanie danych w nowym edytorze SQL.
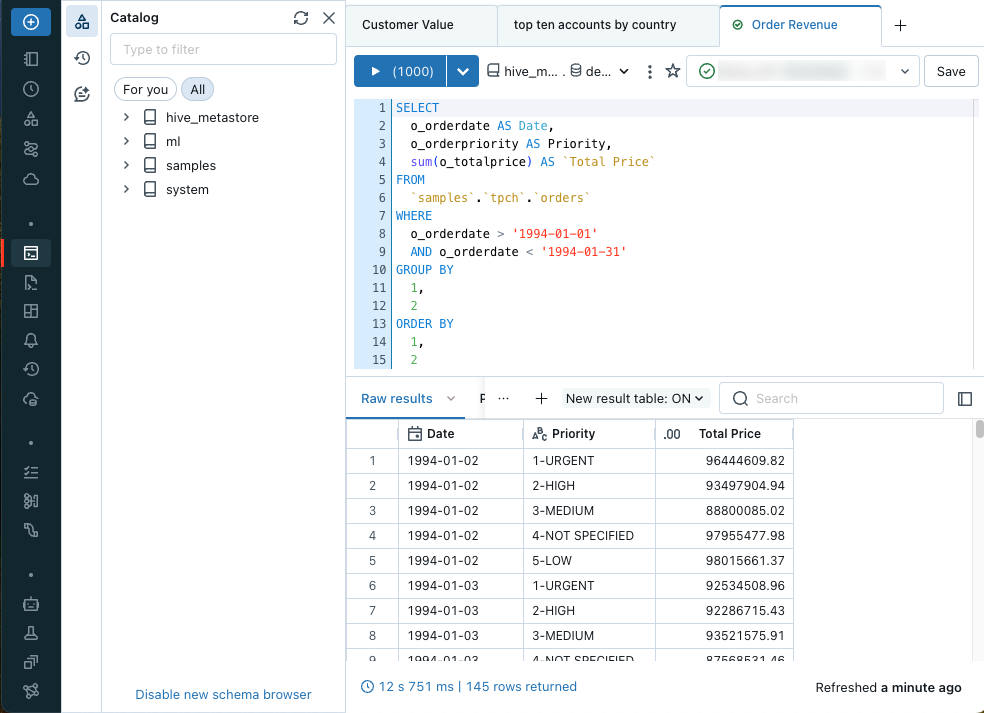
Po otwarciu edytora możesz utworzyć zapytanie SQL lub przejrzeć dostępne dane. Edytor tekstów obsługuje autouzupełnianie, autoformatowanie i różne inne skróty klawiaturowe.
Wiele zapytań można otwierać przy użyciu kart zapytań w górnej części edytora tekstów. Każda karta zapytania zawiera kontrolki uruchamiania zapytania, oznaczania zapytania jako ulubionego i nawiązywania połączenia z usługą SQL Warehouse. Możesz również zapisywać, planować lub udostępniać zapytania.
Otwieranie edytora SQL
Aby otworzyć edytor SQL w interfejsie użytkownika usługi Azure Databricks, kliknij pozycję ![]() Edytor SQL na pasku bocznym.
Edytor SQL na pasku bocznym.
Edytor SQL otwiera ostatnie otwarte zapytanie. Jeśli żadne zapytanie nie istnieje lub wszystkie zapytania zostały jawnie zamknięte, zostanie otwarte nowe zapytanie. Jest on automatycznie nazwany Nowe zapytanie , a sygnatura czasowa tworzenia jest dołączana w tytule.
Jeśli nowy edytor SQL jest włączony, możesz wyłączyć go, aby uzyskać dostęp do starszego edytora SQL. Zobacz, jak wyłączyć nowy edytor SQL.
Nawiązywanie połączenia z obliczeniami
Aby uruchamiać zapytania, musisz mieć co najmniej uprawnienia CAN USE w uruchomionym magazynie SQL Warehouse. Aby wyświetlić dostępne opcje, możesz użyć listy rozwijanej w górnej części edytora. Aby przefiltrować listę, wprowadź tekst w polu tekstowym.
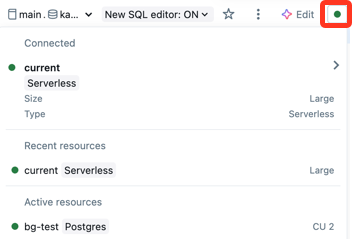
Po pierwszym utworzeniu zapytania lista dostępnych magazynów SQL jest wyświetlana alfabetycznie. Ostatnio używany magazyn SQL Jest wybierany przy następnym utworzeniu zapytania.
Ikona obok usługi SQL Warehouse wskazuje stan:
- Bieganie

- Zatrzymany
Uwaga / Notatka
Jeśli na liście nie ma żadnych magazynów SQL, skontaktuj się z administratorem obszaru roboczego.
Wybrany magazyn SQL Warehouse zostanie automatycznie uruchomiony ponownie po uruchomieniu zapytania. Zobacz Rozpoczynanie pracy z usługą SQL Warehouse , aby dowiedzieć się więcej o innych sposobach uruchamiania usługi SQL Warehouse.
Przeglądanie obiektów danych w edytorze SQL
Jeśli masz uprawnienie do odczytu metadanych, przeglądarka schematu w edytorze SQL wyświetla dostępne bazy danych i tabele. Możesz również przeglądać obiekty danych z Catalog Explorer.

Można nawigować po obiektach bazy danych zarządzanych przez Unity Catalog w Eksploratorze katalogu bez aktywnego obliczeń. Aby eksplorować dane w hive_metastore oraz innych katalogach, które nie są zarządzane przez Unity Catalog, musisz podłączyć się do jednostki obliczeniowej z odpowiednimi uprawnieniami. Zobacz Zarządzanie danymi za pomocą usługi Azure Databricks.
Uwaga / Notatka
Jeśli w przeglądarce schematu lub Eksploratorze wykazu nie istnieją żadne obiekty danych, skontaktuj się z administratorem obszaru roboczego.
Kliknij ikonę odświeżenia schematu ![]() w górnej części przeglądarki schematu, aby odświeżyć schemat. Schemat można filtrować, wpisując ciągi filtru w polu wyszukiwania.
w górnej części przeglądarki schematu, aby odświeżyć schemat. Schemat można filtrować, wpisując ciągi filtru w polu wyszukiwania.
Kliknij nazwę tabeli, aby wyświetlić kolumny dla tej tabeli.
Tworzenie zapytania
Możesz wprowadzić tekst, aby utworzyć zapytanie w edytorze SQL. Elementy można wstawić z przeglądarki schematów do odwołań do katalogów i tabel.
Wpisz zapytanie w edytorze SQL.
Edytor SQL obsługuje autouzupełnianie. Podczas wpisywania autouzupełnianie sugeruje ukończenie. Na przykład, jeśli prawidłowym uzupełnieniem w miejscu kursora jest kolumna, autouzupełnianie sugeruje nazwę kolumny. Jeśli wpiszesz
select * from table_name as t where t., funkcja autouzupełniania rozpoznaje, żetjest aliasemtable_namei sugeruje kolumny wtable_name.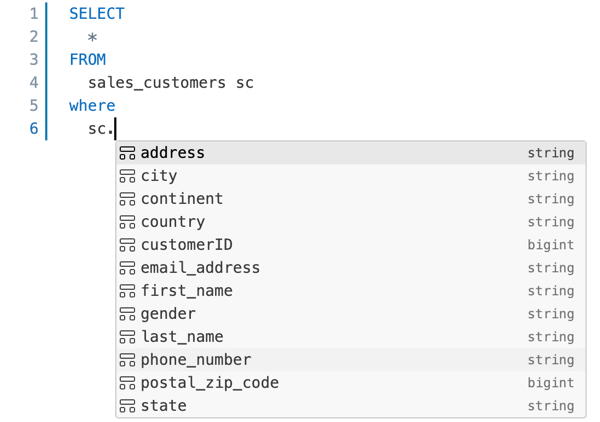
(Opcjonalnie) Po zakończeniu edytowania kliknij przycisk Zapisz. Domyślnie zapytanie jest zapisywane w folderze głównym użytkownika lub możesz wybrać inną lokalizację. Następnie kliknij przycisk Zapisz.
Wykonywanie zapytań o źródła danych
Źródło zapytania można zidentyfikować przy użyciu w pełni kwalifikowanej nazwy tabeli w samym zapytaniu lub wybierając kombinację wykazu i schematu z selektorów listy rozwijanej wraz z nazwą tabeli w zapytaniu. W zapytaniu w pełni kwalifikowana nazwa tabeli zastępuje selektory katalogu i schematu w edytorze zapytań SQL. Jeśli nazwa tabeli lub kolumny zawiera spacje, umieszczaj te identyfikatory w apostrofach odwrotnych w zapytaniach SQL.
W poniższych przykładach pokazano, jak wykonywać zapytania dotyczące różnych obiektów przypominających tabelę, które można przechowywać w wykazie.
Wykonywanie zapytań względem standardowej tabeli lub widoku
Poniższy przykład wykonuje zapytanie dotyczące tabeli z samples wykazu.
SELECT
o_orderdate,
o_orderkey,
o_custkey,
o_totalprice,
o_shippriority
FROM
samples.tpch.orders
Wykonywanie zapytań względem widoku metryki
Poniższy przykład wykonuje zapytanie dotyczące widoku metryki, który używa tabeli z wykazu przykładów jako jego źródła. Ocenia trzy wymienione miary i agreguje względem Order Month i Order Status. Zwraca wyniki posortowane według Order Month. Aby utworzyć podobny widok metryki w obszarze roboczym, zobacz Tworzenie widoku metryki.
Wszystkie oceny wskaźników muszą być zawinięte w funkcję MEASURE. Zobacz measure funkcję agregacji
SELECT
`Order Month`,
`Order Status`,
MEASURE(`Order Count`),
MEASURE(`Total Revenue`),
MEASURE(`Total Revenue per Customer`)
FROM
orders_metric_view
GROUP BY ALL
ORDER BY 1 ASC;
Włączanie i wyłączanie autouzupełniania
Autouzupełnianie na żywo może uzupełniać tokeny schematu, identyfikatory składni zapytań (takie jak SELECT i JOIN) oraz tytuły fragmentów zapytań, takich jak i. Jest ona domyślnie włączona, chyba że schemat bazy danych przekracza pięć tysięcy tokenów (tabel lub kolumn).
Użyj przełącznika poniżej edytora SQL, aby wyłączyć lub włączyć automatyczne uzupełnianie na żywo.
- Aby wyłączyć autouzupełnianie na żywo, naciśnij Ctrl + Spacja
 lub kliknij przycisk poniżej edytora SQL.
lub kliknij przycisk poniżej edytora SQL.
Optymalizowanie zapytania za pomocą asystenta usługi Databricks
Polecenie ukośnika /optimize powoduje, że Asystent ocenia i optymalizuje zapytania. Aby uzyskać więcej informacji, zobacz Optymalizowanie języka Python, PySpark i kodu SQL.
Zapisywanie zapytań
Przycisk Zapisz w prawym górnym rogu edytora SQL zapisuje zapytanie.
Ważne
Podczas modyfikowania zapytania, ale jeśli nie klikniesz wyraźnie przycisku Zapisz, ten stan zostanie zachowany jako wersja robocza zapytania. Wersje robocze zapytań są przechowywane przez 30 dni. Po upływie 30 dni wersje robocze zapytań zostaną automatycznie usunięte. Aby zachować zmiany, musisz je jawnie zapisać.
Edytowanie wielu zapytań
Domyślnie edytor SQL używa kart, dzięki czemu można jednocześnie edytować wiele zapytań. Aby otworzyć nową kartę, kliknij przycisk +, a następnie wybierz opcję Utwórz nowe zapytanie lub Otwórz istniejące zapytanie. Kliknij Otwórz istniejące zapytanie, aby wyświetlić listę zapisanych zapytań. kliknij pozycję Moje zapytania lub Ulubione, aby przefiltrować listę zapytań. W wierszu zawierającym zapytanie, które chcesz wyświetlić, kliknij przycisk Otwórz.

Uruchomienie pojedynczego zapytania lub zapytań wieloinstrukcyjnych
Aby uruchomić instrukcję zapytania lub wszystkie instrukcje zapytania:
Wybierz usługę SQL Warehouse.
Wyróżnij zapytanie w edytorze SQL (jeśli wiele zapytań jest w okienku zapytania).
Naciśnij Ctrl/Cmd + Enter lub kliknij Uruchom (1000), aby wyświetlić wyniki jako tabelę w okienku wyników.
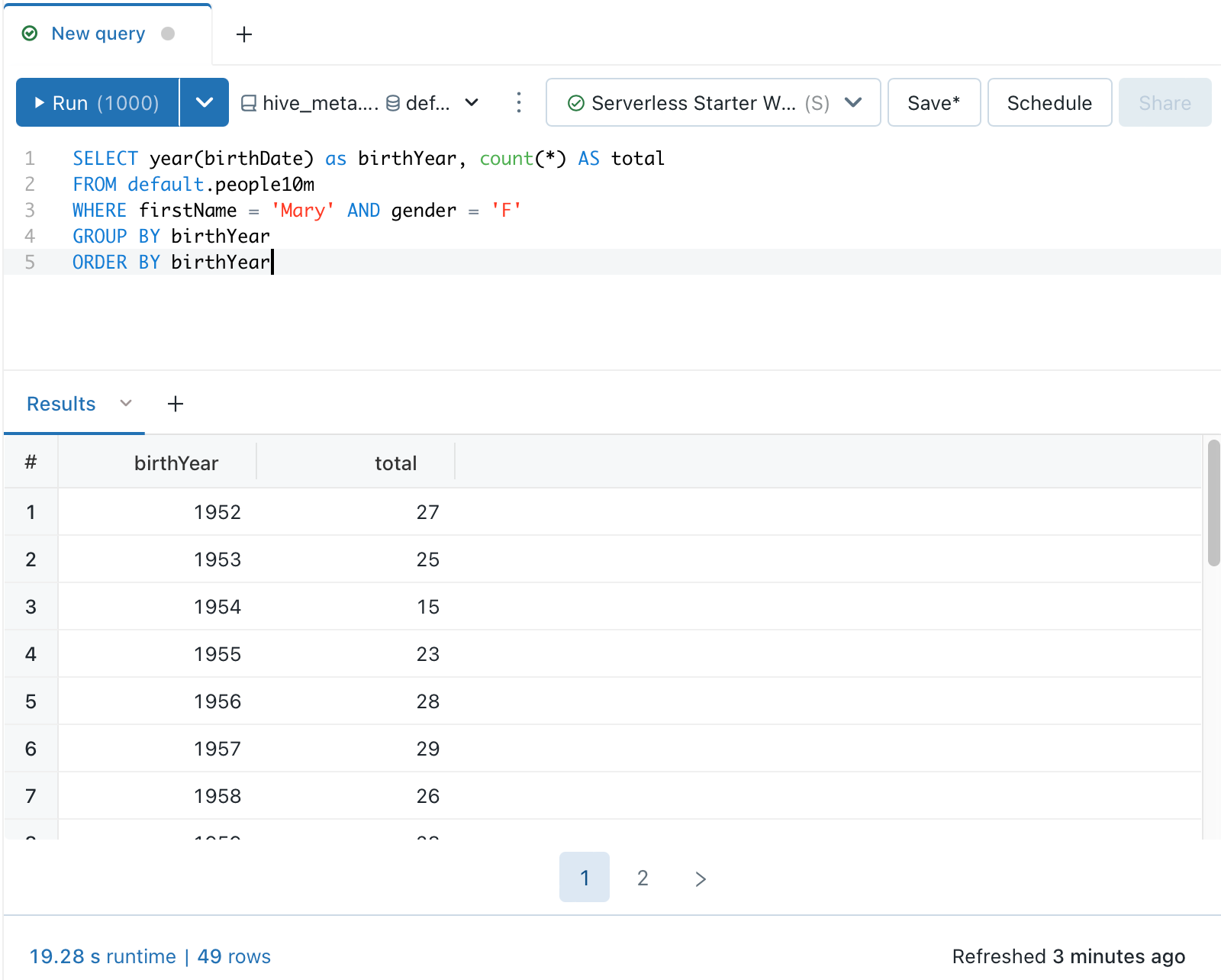
Uwaga / Notatka
Domyślnie wybrano opcję Ogranicz 1000 , aby ograniczyć wyniki zapytania do 1000 wierszy.
Jeśli zapytanie jest zapisywane z limitem 1000, to ustawienie dotyczy wszystkich przebiegów zapytań, w tym na pulpitach nawigacyjnych.
Aby zwrócić wszystkie wiersze (aż do 64 000), odznacz opcję Ogranicz 1000 z menu rozwijanego Uruchom (1000).
Aby określić inny limit wierszy, dodaj klauzulę LIMIT do zapytania SQL.
Maksymalna liczba wierszy zwracanych w tabeli wynosi 64 000.
Kończenie zapytania
Aby zakończyć zapytanie podczas jego działania, kliknij przycisk Anuluj. Administrator może zatrzymać uruchomione zapytanie uruchomione przez innego użytkownika, wyświetlając polecenie Zakończ wykonywanie zapytania.
Opcje zapytań
Możesz użyć ![]() znajdującej się w górnej części edytora zapytań, aby uzyskać dostęp do opcji klonowania, przywracania, formatowania i edytowania informacji o zapytaniu.
znajdującej się w górnej części edytora zapytań, aby uzyskać dostęp do opcji klonowania, przywracania, formatowania i edytowania informacji o zapytaniu.
Przywracanie do zapisanego zapytania
Podczas edytowania zapytania zostanie wyświetlona opcja Przywróć zmiany w menu kontekstowym zapytania. Możesz kliknąć pozycję Przywróć, aby wrócić do zapisanej wersji.
Odrzucanie i przywracanie zapytań
Aby przenieść zapytanie do kosza:
- Kliknij
 obok zapytania w edytorze SQL i wybierz pozycję Przenieś do kosza.
obok zapytania w edytorze SQL i wybierz pozycję Przenieś do kosza. - Kliknij pozycję Przenieś do kosza , aby potwierdzić.
Aby odzyskać zapytanie z kosza:
- Na liście Wszystkie zapytania kliknij pozycję
 .
. - Kliknij zapytanie.
- Kliknij w prawym górnym rogu edytora SQL, a następnie wybierz Przywróć.
Ustawianie opisu zapytania i wyświetlanie informacji o kwerendzie
Aby ustawić opis zapytania:
Kliknij
menu kontekstowe kebab obok kwerendy i kliknij pozycję Edytuj informacje o kwerendzie.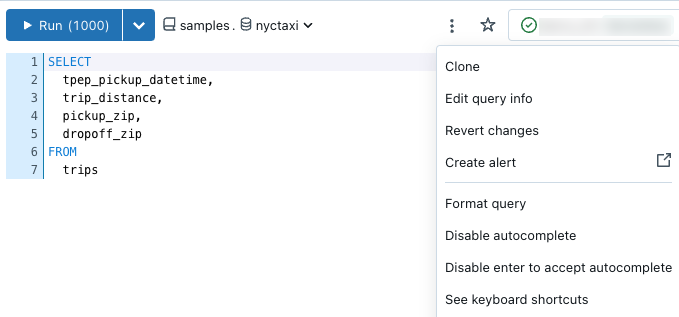
W polu tekstowym Opis wprowadź opis. Następnie kliknij przycisk Zapisz. Możesz również wyświetlić historię zapytania, w tym czas jego utworzenia i zaktualizowania w tym oknie dialogowym.
Zapytania ulubione i tagowe
Możesz użyć ulubionych i tagów, aby filtrować listy zapytań i pulpitów nawigacyjnych wyświetlanych na stronie docelowej obszaru roboczego oraz na każdej ze stron listy dla pulpitów nawigacyjnych i zapytań.
Ulubione: Aby dodać zapytanie do ulubionych, kliknij gwiazdkę po lewej stronie jego tytułu na liście zapytań. Gwiazda zmieni kolor na żółty.
Tagi: zapytania i pulpity nawigacyjne można tagować przy użyciu dowolnego znaczącego ciągu w organizacji.
Dodaj tag
Dodaj tagi w edytorze zapytań.
Kliknij
menu kontekstowe kebab obok kwerendy i kliknij pozycję Edytuj informacje o kwerendzie. Zostanie wyświetlone okno dialogowe Informacje o kwerendzie.Jeśli zapytanie nie ma zastosowanych tagów, w polu tekstowym, gdzie pojawią się tagi, wyświetla się napisDodaj kilka tagów. Aby utworzyć nowy tag, wpisz go w polu . Aby wprowadzić wiele tagów, naciśnij Tab między wpisami.
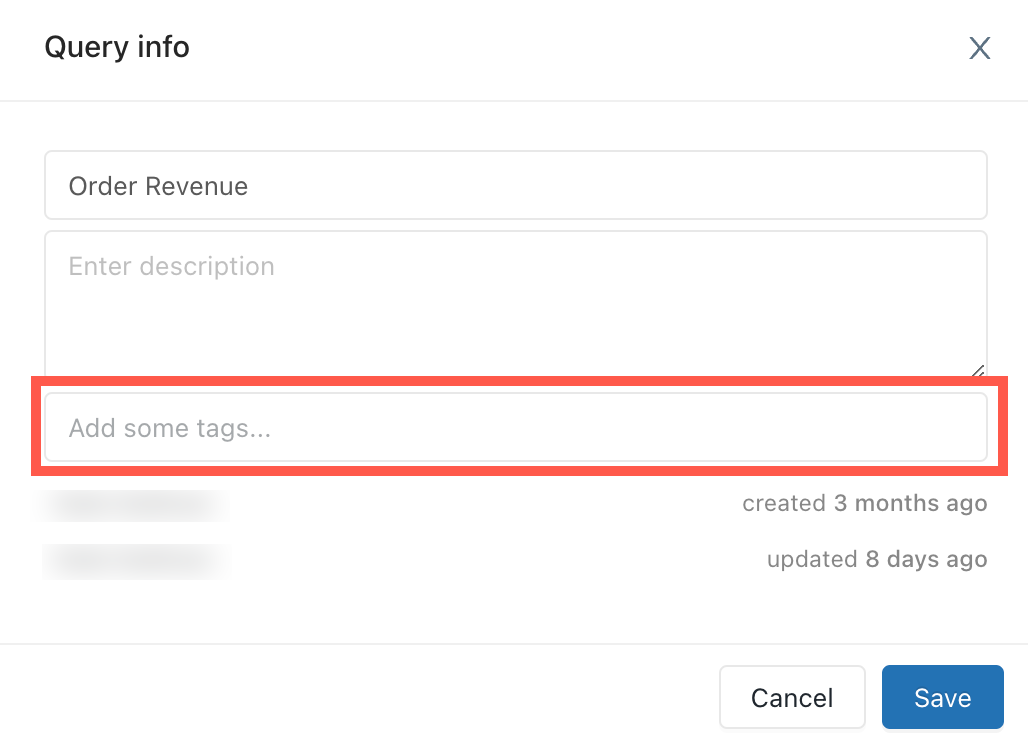
Kliknij przycisk Zapisz , aby zastosować tagi i zamknąć okno dialogowe.
Usuwanie tagów
- Kliknij menu kontekstowe kebab obok kwerendy i kliknij pozycję Edytuj informacje o kwerendzie.
- Kliknij X na dowolnym tagu, który chcesz usunąć.
- Kliknij przycisk Zapisz , aby zamknąć okno dialogowe.
Wyświetlanie wyników zapytania
Po uruchomieniu zapytania wyniki pojawią się w okienku poniżej. Nowa tabela wyników jest ON dla nowych zapytań. W razie potrzeby kliknij listę rozwijaną, aby ją wyłączyć. Obrazy w tej sekcji używają nowej tabeli wyników.
Możesz korzystać z wyników zapytania i eksplorować je przy użyciu okienka wyników. Okienko wyników zawiera następujące funkcje do eksplorowania wyników.
Wizualizacje, filtry i parametry
Kliknij przycisk , ![]() aby dodać wizualizację, filtr lub parametr. Pojawią się następujące opcje:
aby dodać wizualizację, filtr lub parametr. Pojawią się następujące opcje:
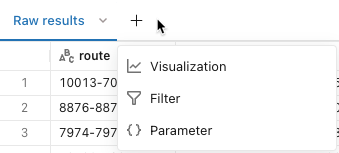
Wizualizacja: wizualizacje mogą ułatwić eksplorowanie zestawu wyników. Zobacz Typy wizualizacji notesu i edytora SQL , aby uzyskać pełną listę dostępnych typów wizualizacji.
Filtr: filtry umożliwiają ograniczenie zestawu wyników po wykonaniu zapytania. Filtry można stosować do selektywnego pokazywania różnych podzestawów danych. Zobacz Filtry zapytań , aby dowiedzieć się, jak używać filtrów.
Parametr: Parametry umożliwiają ograniczenie zestawu wyników przez podstawianie wartości do zapytania w czasie jego wykonywania. Aby dowiedzieć się, jak stosować parametry, zobacz Pracę z parametrami zapytania.
Edytowanie, pobieranie lub dodawanie do pulpitu nawigacyjnego
Ważne
Databricks zaleca używanie dashboardów AI/BI (dawniej dashboardów Lakeview). Wcześniejsze wersje pulpitów nawigacyjnych, wcześniej znane jako pulpity nawigacyjne Databricks SQL, nazywane są teraz pulpitami nawigacyjnymi legacy.
Harmonogram zakończenia wsparcia:
- 12 stycznia 2026 r. Starsze pulpity nawigacyjne i interfejsy API nie są już dostępne bezpośrednio. Można je jednak nadal konwertować na pulpity nawigacyjne sztucznej inteligencji/analizy biznesowej. Strona migracji jest dostępna do 2 marca 2026 r.
Konwertowanie starszych pulpitów nawigacyjnych przy użyciu narzędzia do migracji lub interfejsu API REST. Aby uzyskać instrukcje dotyczące korzystania z wbudowanego narzędzia do migracji, zobacz Jak sklonować starszy pulpit nawigacyjny na pulpit nawigacyjny AI/BI. Zobacz Używanie interfejsów API usługi Azure Databricks do zarządzania pulpitami nawigacyjnymi w celu zapoznania się z samouczkami dotyczącymi tworzenia pulpitów nawigacyjnych i zarządzania nimi przy użyciu interfejsu API REST.
![]() Kliknij kartę wyników, aby wyświetlić więcej opcji.
Kliknij kartę wyników, aby wyświetlić więcej opcji.
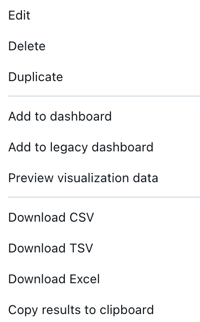
- Kliknij przycisk Edytuj , aby dostosować wyniki wyświetlane w wizualizacji.
- Kliknij przycisk Usuń, aby usunąć kartę wyników.
- Kliknij pozycję Duplikuj , aby sklonować kartę wyników.
- Kliknij pozycję Dodaj do pulpitu nawigacyjnego , aby skopiować zapytanie i wizualizację do nowego pulpitu nawigacyjnego.
- Ta akcja powoduje utworzenie nowego pulpitu nawigacyjnego zawierającego wszystkie wizualizacje skojarzone z zapytaniem. Zobacz Pulpity nawigacyjne, aby dowiedzieć się, jak edytować pulpit nawigacyjny.
- Zostanie wyświetlony monit o wybranie nazwy nowego pulpitu nawigacyjnego. Nowy pulpit nawigacyjny jest zapisywany w folderze głównym.
- Nie można dodać wyników do istniejącego pulpitu nawigacyjnego.
- Kliknij pozycję Dodaj do starszego pulpitu nawigacyjnego, aby dodać kartę wyników do istniejącego starszego pulpitu nawigacyjnego.
- Kliknij dowolną z opcji pobierania, aby pobrać wyniki. Aby uzyskać szczegółowe informacje i limity, zobacz następujący opis.
Wyniki pobierania: wyniki można pobrać jako plik CSV, TSV lub Excel.
Możesz pobrać do około 1 GB danych wyników z usługi Databricks SQL w formacie CSV i TSV oraz maksymalnie 100 000 wierszy do pliku programu Excel.
Ostateczny rozmiar pobierania pliku może być nieco większy lub mniejszy niż 1 GB, ponieważ limit 1 GB jest stosowany do wcześniejszego kroku niż pobieranie pliku końcowego.
Uwaga / Notatka
Jeśli nie możesz pobrać zapytania, administrator obszaru roboczego wyłączył pobieranie dla obszaru roboczego.
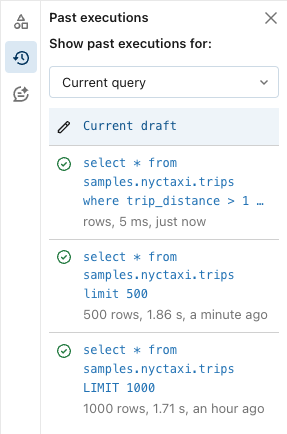
Poprzednie wykonania
Poprzednie uruchomienia zapytania można wyświetlić, w tym pełną składnię zapytania. Poprzednie wykonania są otwierane w trybie tylko do odczytu i zawierają przyciski klonowania do nowego zapytania lub wznawiania edycji. Ta karta nie zawiera zaplanowanych przebiegów.
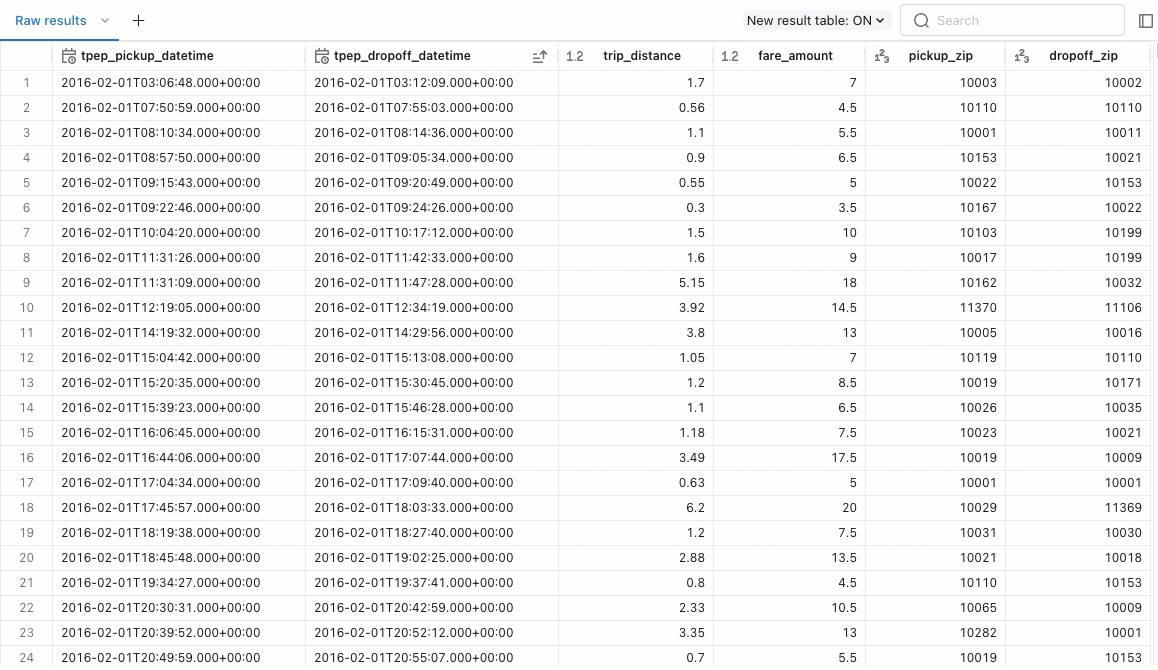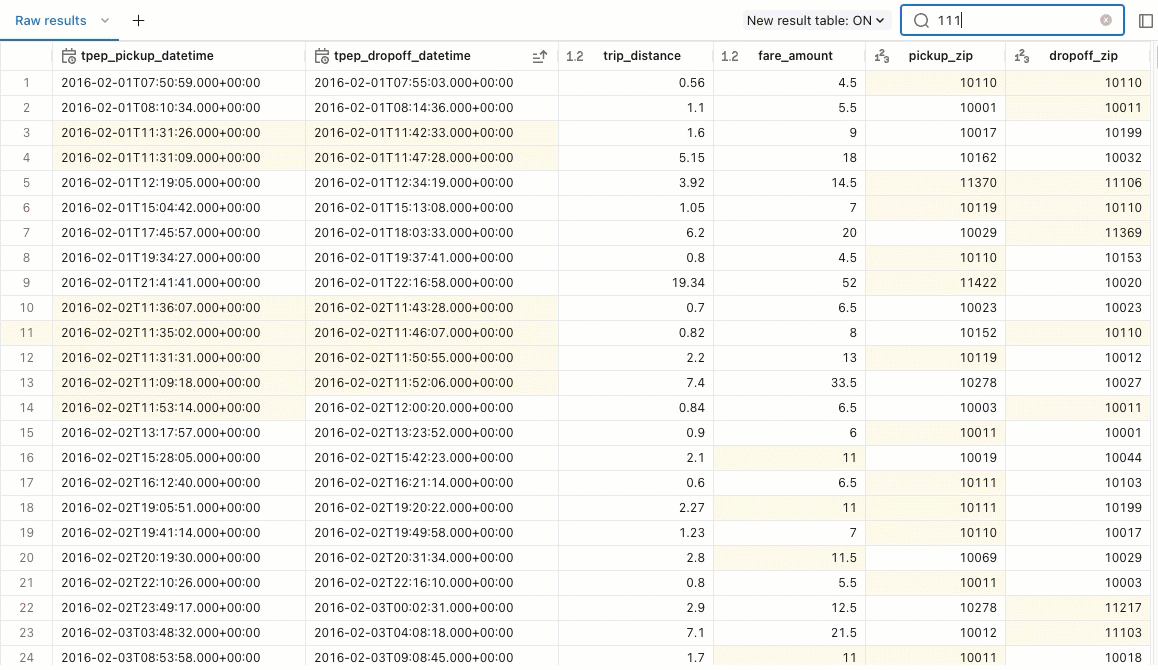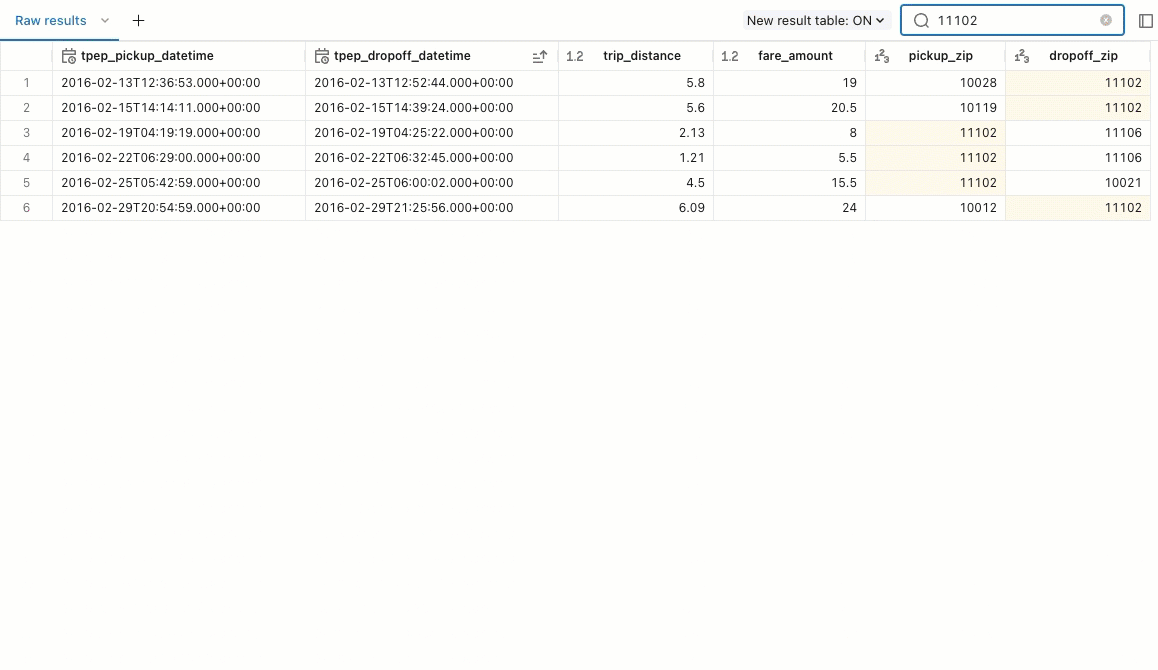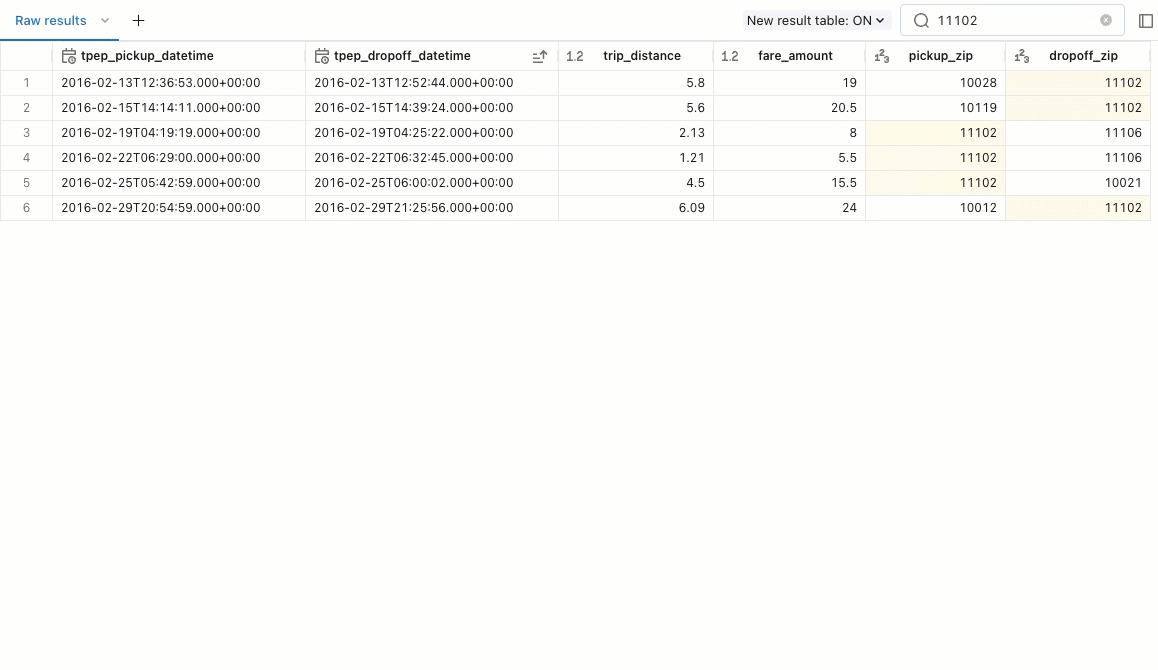
Eksplorowanie wyników
Zwrócone wyniki zapytania są wyświetlane poniżej zapytania. Karta Nieprzetworzone wyniki jest wypełniana zwracanymi wierszami. Za pomocą wbudowanych filtrów można zmienić kolejność wyników, rosnąco lub malejąco. Możesz również użyć filtru, aby wyszukać wiersze wyników, które zawierają określoną wartość.
Karty w okienku wyników umożliwiają dodawanie wizualizacji, filtrów i parametrów.

Filtrowanie listy zapisanych zapytań w oknie zapytania
W oknie zapytania można filtrować listę wszystkich zapytań według listy utworzonych zapytań (Moje zapytania), według ulubionych i według tagów.
Automatyzowanie aktualizacji
Możesz użyć przycisku Harmonogram, aby ustawić automatyczne cykle uruchamiania zapytań. Aktualizacje automatyczne mogą ułatwić aktualizowanie pulpitów nawigacyjnych i raportów przy użyciu najbardziej aktualnych danych. Zapytania schedueled mogą również włączać alerty SQL usługi Databricks, specjalny typ zaplanowanego zadania, które wysyła powiadomienia, gdy wartość osiągnie określony próg.
Zobacz Planowanie zapytania.
Zobacz Alerty SQL usługi Databricks.
Udostępnianie zapytań
Przycisk Udostępnij umożliwia udostępnianie zapytania innym użytkownikom w obszarze roboczym. Podczas udostępniania wybierz między następującymi opcjami:
- Uruchom jako właściciel (poświadczenia właściciela): to ustawienie oznacza, że osoby przeglądające mogą wyświetlać te same wyniki zapytania co właściciel zapytania. Dotyczy to zaplanowanych lub ręcznych przebiegów zapytań.
- Uruchom jako użytkownik (poświadczenia użytkowników oglądających): to ustawienie ogranicza wyniki do przypisanych uprawnień użytkowników oglądających.
Zobacz Konfigurowanie uprawnień zapytania.
Następny krok
Zobacz Uzyskiwanie dostępu do zapisanych zapytań i zarządzanie nimi, aby dowiedzieć się, jak pracować z zapytaniami za pomocą interfejsu użytkownika usługi Azure Databricks.