Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Azure DevOps Services | Azure DevOps Server | Azure DevOps Server 2022
Zadania usługi Azure Pipelines składają się z kroków, które mogą być zadaniami lub skryptami. Zadanie to wstępnie spakowany skrypt lub procedura, która wykonuje akcję lub używa zestawu danych wejściowych do zdefiniowania automatyzacji potoku. W tym artykule opisano zadania potoku i sposób ich używania. Aby uzyskać informacje o schemacie, zobacz definicję steps.task .
Usługa Azure Pipelines obejmuje wiele wbudowanych zadań, które umożliwiają podstawowe scenariusze kompilacji i wdrażania. Aby uzyskać listę dostępnych wbudowanych zadań usługi Azure Pipelines, zobacz dokumentację zadań usługi Azure Pipelines. Możesz również instalować zadania z witryny Visual Studio Marketplace lub tworzyć zadania niestandardowe.
Domyślnie wszystkie kroki w zadaniu są uruchamiane w sekwencji w tym samym kontekście, zarówno na hoście, jak i w kontenerze zadań. Opcjonalnie możesz użyć elementów docelowych kroków , aby kontrolować kontekst poszczególnych zadań. Aby uruchomić niektóre zadania równolegle na wielu agentach lub bez użycia agenta, zobacz Określanie zadań w potoku.
Zarządzanie zadaniami
Zadania są dostępne i instalowane na poziomie organizacji usługi Azure DevOps. W organizacji można używać tylko zadań i wersji zadań, które istnieją.
Wbudowane zadania, zadania witryny Marketplace lub oba te zadania można wyłączyć w obszarzeUstawienia>> organizacji w obszarze Ograniczenia zadań. Jeśli wyłączysz zarówno zadania wbudowane, jak i zadania witryny Marketplace, dostępne są tylko zadania instalowane przy użyciu interfejsu wiersza polecenia węzła dla usługi Azure DevOps .
Wyłączenie zadań witryny Marketplace może pomóc zwiększyć bezpieczeństwo potoku. W większości przypadków nie należy wyłączać wbudowanych zadań. Aby uzyskać więcej informacji, zobacz Kontrolowanie dostępnych zadań.
Zadania niestandardowe
Witryna Visual Studio Marketplace oferuje wiele rozszerzeń, które można zainstalować, aby rozszerzyć katalog zadań usługi Azure Pipelines. Można również tworzyć zadania niestandardowe. Aby uzyskać więcej informacji, zobacz Dodawanie rozszerzenia zadania potoków niestandardowych.
W potokach YAML odwołujesz się do zadań według nazwy. Jeśli niestandardowa nazwa zadania jest zgodna z wbudowaną nazwą zadania, potok używa wbudowanego zadania. Aby uniknąć takiej sytuacji, możesz odwołać się do zadania niestandardowego przy użyciu unikatowego identyfikatora GUID zadania przydzielonego podczas tworzenia zadania. Aby uzyskać więcej informacji, zobacz Omówienie składników task.json.
Wersje zadań
Zadania są wersjonowane i należy określić wersję główną zadań używanych w potoku. Określenie wersji pomaga zapobiegać problemom podczas wydawania nowych wersji zadania.
Potoki są automatycznie aktualizowane w celu używania nowych wersji zadań pomocniczych, takich jak 1.2 do 1.3. Wersje zadań pomocniczych są zwykle zgodne z poprzednimi wersjami, ale w niektórych scenariuszach mogą wystąpić nieprzewidywalne błędy, gdy zadanie zostanie automatycznie zaktualizowane.
Jeśli nowa wersja zadania głównego, taka jak wersja 2.0, potok będzie nadal używać określonej wersji głównej, dopóki potok nie zostanie edytowany, aby ręcznie zmienić nową wersję główną. Dzienniki kompilacji udostępniają alerty, gdy są dostępne nowe wersje główne. W organizacji można używać tylko wersji zadań, które istnieją.
W języku YAML należy określić wersję główną przy użyciu w @ nazwie zadania. Aby na przykład użyć wersji 2 PublishTestResults zadania, określ wartość PublishTestResults@2. Możesz określić, która wersja pomocnicza ma być używana, podając pełny numer wersji zadania po pliku @, na przykład GoTool@0.3.1.
Opcje zadań
Poniższe właściwości są dostępne dla kroków potoku task YAML. Aby uzyskać więcej informacji, zobacz definicję steps.task .
| Majątek | Typ | Description |
|---|---|---|
task |
ciąg | Wymagane jako pierwsza właściwość. Nazwa zadania do uruchomienia. |
inputs |
ciąg | Dane wejściowe zadania przy użyciu par name/value. |
condition |
ciąg | Warunki, w których jest uruchamiane zadanie. |
continueOnError |
typ logiczny (boolowski) | Czy kontynuować działanie nawet w przypadku awarii. |
displayName |
ciąg | Czytelna dla człowieka nazwa zadania. |
enabled |
typ logiczny (boolowski) | Czy uruchamiać to zadanie po uruchomieniu zadania. |
env |
ciąg | Zmienne do mapowania w środowisku przetwarzania przy użyciu par nazwa/wartość. |
name |
ciąg | Identyfikator kroku. |
retryCountOnTaskFailure |
ciąg | Liczba ponownych prób w przypadku niepowodzenia zadania. |
target |
ciąg | Środowisko do uruchamiania tego zadania w programie. |
timeoutInMinutes |
ciąg | Maksymalny czas uruchomienia zadania przed automatycznym anulowaniem. |
Warunki
Zadanie nie może określić, czy kontynuować zadanie potoku po zakończeniu zadania, tylko podać stan zakończenia, taki jak succeeded lub failed. Podrzędne zadania i zadania można następnie ustawić condition na podstawie tego stanu, aby określić, czy należy uruchomić.
Właściwość conditions określa warunki, w których to zadanie jest uruchamiane. Domyślnie krok jest uruchamiany, jeśli jeszcze nic nie powiodło się, a krok bezpośrednio poprzedzający jego ukończenie.
Możesz zastąpić lub dostosować te wartości domyślne, ustawiając krok do uruchomienia nawet wtedy, gdy poprzednia zależność zakończy się niepowodzeniem lub ma inny wynik. Można również zdefiniować warunki niestandardowe, które składają się z wyrażeń.
Uwaga
Warunki mają zastosowanie do wszystkich poprzednich zależności bezpośrednich i pośrednich z tą samą pulą agentów. Etapy lub zadania w różnych pulach agentów są uruchamiane współbieżnie.
Warunki oparte na poprzednim stanie zależności obejmują:
-
Powodzenie: uruchom polecenie tylko wtedy, gdy wszystkie poprzednie zależności powiedzie się. To zachowanie jest domyślne, jeśli w YAML nie ustawiono żadnego warunku. Aby zastosować ten warunek, określ wartość
condition: succeeded(). -
Powodzenie lub niepowodzenie: uruchom polecenie, nawet jeśli poprzednia zależność zakończy się niepowodzeniem, chyba że przebieg zostanie anulowany. Aby zastosować ten warunek, określ wartość
condition: succeededOrFailed(). -
Zawsze: uruchom polecenie, nawet jeśli poprzednia zależność zakończy się niepowodzeniem, nawet jeśli przebieg zostanie anulowany. Aby zastosować ten warunek, określ wartość
condition: always(). -
Niepowodzenie: uruchom polecenie tylko wtedy, gdy poprzednia zależność zakończy się niepowodzeniem. Aby zastosować ten warunek, określ wartość
condition: failed().
W poniższym przykładzie YAML jest uruchamiany nawet wtedy, PublishTestResults@2 gdy poprzedni krok zakończył się niepowodzeniem ze względu na jego warunek succeededOrFailed .
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
architecture: 'x64'
- task: PublishTestResults@2
inputs:
testResultsFiles: "**/TEST-*.xml"
condition: succeededOrFailed()
Kontynuuj przy błędzie
Właściwość continueOnError informuje zadanie, czy kontynuować uruchamianie i zgłaszać powodzenie niezależnie od niepowodzeń. Jeśli ustawiono truewartość , ta właściwość informuje zadanie o zignorowaniu stanu i kontynuowaniu failed działania. Kroki podrzędne i zadania traktują wynik zadania, gdy success podejmują decyzje dotyczące uruchamiania.
Włączona
Domyślnie zadanie jest uruchamiane za każdym razem, gdy zadanie jest uruchamiane. Możesz ustawić wartość enabled , false aby wyłączyć zadanie. Tymczasowe wyłączenie zadania jest przydatne do usunięcia zadania z procesu na potrzeby testowania lub dla określonych wdrożeń.
Liczba ponownych prób w przypadku niepowodzenia zadania
Właściwość retryCountOnTaskFailure określa liczbę ponownych prób wykonania zadania w przypadku niepowodzenia. Wartość domyślna to zero ponownych prób.
- Maksymalna dozwolona liczba ponownych prób wynosi 10.
- Czas oczekiwania przed ponowieniem próby zwiększa się po każdej nieudanej próbie, zgodnie ze strategią wycofywania wykładniczego. Pierwsza ponowna próba następuje po 1 sekundzie, druga ponawianie po 4 sekundach, a dziesiąta ponowna próba po 100 sekundach.
- Ponawianie próby zadania nie zapewnia idempotentności. Skutki uboczne pierwszej próby, takie jak częściowe tworzenie zasobu zewnętrznego, mogą powodować ponawianie prób.
- Dla zadania nie są udostępniane żadne informacje o liczbie ponownych prób.
- Niepowodzenie zadania dodaje ostrzeżenie do dzienników zadań wskazujących, że nie powiodło się przed ponowieniu próby wykonania zadania.
- Wszystkie próby ponawiania prób są wyświetlane w interfejsie użytkownika w ramach tego samego węzła zadania.
Uwaga
Właściwość retryCountOnTaskFailure wymaga agenta w wersji 2.194.0 lub nowszej. W usłudze Azure DevOps Server 2022 ponowne próby nie są obsługiwane w przypadku zadań bez agenta. Aby uzyskać więcej informacji, zobacz Aktualizacja usługi Azure DevOps 16 listopada 2021 r. — automatyczne ponawianie prób dla zadania i aktualizacja usługi Azure DevOps 14 czerwca 2025 r. — ponowne próby dla zadań serwera.
Target
Zadania są uruchamiane w kontekście wykonawczym, który stanowi host agent lub kontener. Zadanie może przesłonić jego kontekst, określając targetelement . Dostępne opcje są host przeznaczone dla hosta agenta i wszystkich kontenerów zdefiniowanych w potoku. W poniższym przykładzie SampleTask@1 działa na hoście i AnotherTask@1 działa w kontenerze.
resources:
containers:
- container: pycontainer
image: python:3.11
steps:
- task: SampleTask@1
target: host
- task: AnotherTask@1
target: pycontainer
Timeout
Okres przekroczenia limitu czasu rozpoczyna się od uruchomienia zadania i nie obejmuje czasu, w którym zadanie jest w kolejce lub oczekuje na agenta.
Uwaga
Potoki mogą określać limit czasu na poziomie zadania oprócz limitu czasu na poziomie zadania. Jeśli interwał limitu czasu na poziomie zadania upłynie przed ukończeniem zadania, zadanie uruchomione zakończy się, nawet jeśli zadanie jest skonfigurowane z dłuższym interwałem limitu czasu. Aby uzyskać więcej informacji, zobacz Limity czasowe.
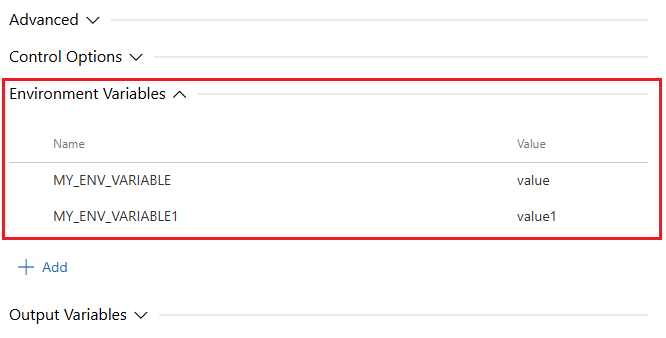
Zmienne środowiskowe
Zmienne środowiskowe umożliwiają mapowania informacji systemowych lub zdefiniowanych przez użytkownika do procesu zadania.
Zadanie potoku YAML może określać właściwość zawierającą env ciągi nazw/wartości reprezentujące zmienne środowiskowe.
- task: AzureCLI@2
env:
ENV_VARIABLE_NAME: value
ENV_VARIABLE_NAME2: value
...
Zmienne środowiskowe można ustawić przy użyciu script kroków lub skryptów w wierszu polecenia, powłoce Bash lub PowerShell.
Poniższy przykład uruchamia script krok, który przypisuje wartość do zmiennej środowiskowej ENV_VARIABLE_NAME i odzwierciedla wartość.
- script: echo "This is " $ENV_VARIABLE_NAME
env:
ENV_VARIABLE_NAME: value
displayName: 'echo environment variable'
Powyższy skrypt jest funkcjonalnie taki sam jak uruchamianie zadania Bash@3 z danymi wejściowymi script . W poniższym przykładzie użyto task składni .
- task: Bash@3
inputs:
script: echo "This is " $ENV_VARIABLE_NAME
env:
ENV_VARIABLE_NAME: value
displayName: 'echo environment variable'
Zadania instalatora narzędzi kompilacji
Zadania instalatora narzędzi kompilacji umożliwiają potokowi kompilacji instalowanie i kontrolowanie zależności. Za pomocą zadań instalatora narzędzi kompilacji można wykonywać następujące czynności:
- Zainstaluj narzędzie lub środowisko uruchomieniowe kompilacji, w tym na agentach hostowanych przez firmę Microsoft.
- Zweryfikuj aplikację lub bibliotekę dla wielu wersji zależności, takich jak Node.js.
Aby uzyskać listę zadań instalatora narzędzi, zobacz Zadania narzędzi.
Przykład: testowanie i weryfikowanie aplikacji w wielu wersjach Node.js
Poniższy przykład umożliwia skonfigurowanie potoku kompilacji w celu uruchomienia i zweryfikowania aplikacji w wielu wersjach Node.js.
Utwórz plik azure-pipelines.yml zawierający następującą zawartość w katalogu podstawowym projektu.
pool:
vmImage: 'windows-latest'
jobs:
- job: NodeJS
strategy:
matrix:
node14:
nodeVersion: '14.x'
node16:
nodeVersion: '16.x'
maxParallel: 2
steps:
- task: NodeTool@0
displayName: 'Install Node.js $(nodeVersion)'
inputs:
versionSpec: '$(nodeVersion)'
checkLatest: true
- script: |
echo Using Node version $(nodeVersion)
node --version
displayName: 'Verify Node Installation'
Zapisz i uruchom potok. Zadanie jest uruchamiane dwa razy, po jednym dla każdej wersji Node.js określonego w zmiennej nodeVersion .
Instalator narzędzi Node.js pobiera odpowiednią wersję Node.js, jeśli nie jest ona już zainstalowana na agencie. Skrypt wiersza polecenia zapisuje zainstalowaną wersję w wierszu polecenia.
Treści powiązane
Pomoc i obsługa techniczna
- Zapoznaj się z poradami dotyczącymi rozwiązywania problemów.
- Uzyskaj porady na temat Stack Overflow.
- Opublikuj swoje pytania, wyszukaj odpowiedzi lub zasugeruj funkcję w społeczności deweloperów usługi Azure DevOps.
- Uzyskaj pomoc techniczną dotyczącą usługi Azure DevOps.