Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Usługa Azure AI Search obsługuje importowanie, analizowanie i indeksowanie danych z wielu źródeł danych do jednego skonsolidowanego indeksu wyszukiwania.
Samouczek C# używa biblioteki klienckiej Azure.Search.Documents w zestawie Azure SDK dla .NET do indeksowania przykładowych danych hotelowych z instancji Azure Cosmos DB. Następnie scalisz dane ze szczegółami pokoju hotelowego pochodzącymi z dokumentów usługi Azure Blob Storage. Wynikiem jest połączony indeks wyszukiwania hotelowego zawierający dokumenty hotelowe z pokojami jako złożonymi typami danych.
W tym samouczku nauczysz się następujących rzeczy:
- Przekazywanie przykładowych danych do źródeł danych
- Identyfikowanie klucza dokumentu
- Definiowanie i tworzenie indeksu
- Indeksowanie danych hotelowych z usługi Azure Cosmos DB
- Scalanie danych pokoju hotelowego z Blob Storage
Omówienie
W tym samouczku użyto elementu Azure.Search.Documents do utworzenia i uruchomienia wielu indeksatorów. Przekazujesz przykładowe dane do dwóch źródeł danych platformy Azure i konfigurujesz indeksator, który pobiera dane z obu źródeł, aby wypełnić pojedynczy indeks wyszukiwania. Dwa zestawy danych muszą mieć wspólną wartość do obsługi scalania. W tym samouczku to pole jest identyfikatorem. Jeśli istnieje pole wspólne do obsługi mapowania, indeksator może scalić dane z różnych zasobów: dane ustrukturyzowane z usługi Azure SQL, dane bez struktury z usługi Blob Storage lub dowolną kombinację obsługiwanych źródeł danych na platformie Azure.
Ukończona wersja kodu w tym samouczku można znaleźć w następującym projekcie:
Wymagania wstępne
- Konto Azure z aktywną subskrypcją. Utwórz konto bezpłatnie.
- Konto usługi Azure Cosmos DB for NoSQL.
- Konto usługi Azure Storage.
- Usługa Azure AI Search.
- Visual Studio.
Uwaga
Możesz użyć bezpłatnej usługi wyszukiwania do tego samouczka. Warstwa Bezpłatna ogranicza do trzech indeksów, trzech indeksatorów i trzech źródeł danych. W ramach tego samouczka tworzony jest jeden element każdego z tych typów. Przed rozpoczęciem upewnij się, że masz wystarczającą ilość miejsca w swojej usłudze, aby przyjąć nowe zasoby.
Przygotowywanie usług
W tym samouczku użyto usługi Azure AI Search do indeksowania i zapytań, usługi Azure Cosmos DB dla pierwszego zestawu danych oraz usługi Azure Blob Storage dla drugiego zestawu danych.
Jeśli to możliwe, utwórz wszystkie usługi w tym samym regionie i grupie zasobów w celu zapewnienia zbliżenia i możliwości zarządzania. W praktyce usługi mogą znajdować się w dowolnym regionie.
W tym przykładzie użyto dwóch małych zestawów danych opisujących siedem fikcyjnych hoteli. Jeden zestaw opisuje same hotele i zostanie załadowany do bazy danych usługi Azure Cosmos DB. Drugi zestaw zawiera szczegóły pokoju hotelowego i jest dostarczany jako siedem oddzielnych plików JSON do przekazania do usługi Azure Blob Storage.
Rozpoczynanie pracy z usługą Azure Cosmos DB
Zaloguj się do witryny Azure Portal i wybierz swoje konto usługi Azure Cosmos DB.
W okienku po lewej stronie wybierz pozycję Eksplorator danych.
Wybierz Nowy kontener>Nowa baza danych.

Wprowadź hotel-rooms-db jako nazwę. Zaakceptuj wartości domyślne pozostałych ustawień.

Utwórz kontener przeznaczony dla utworzonej wcześniej bazy danych. Wprowadź hotels dla nazwy kontenera i /HotelId dla klucza partycji.

Wybierz pozycję hotele>, a następnie wybierz Elementy i Prześlij element na pasku poleceń.
Załaduj plik JSON w folderze
cosmosdbz wiele-źródeł-danych/v11.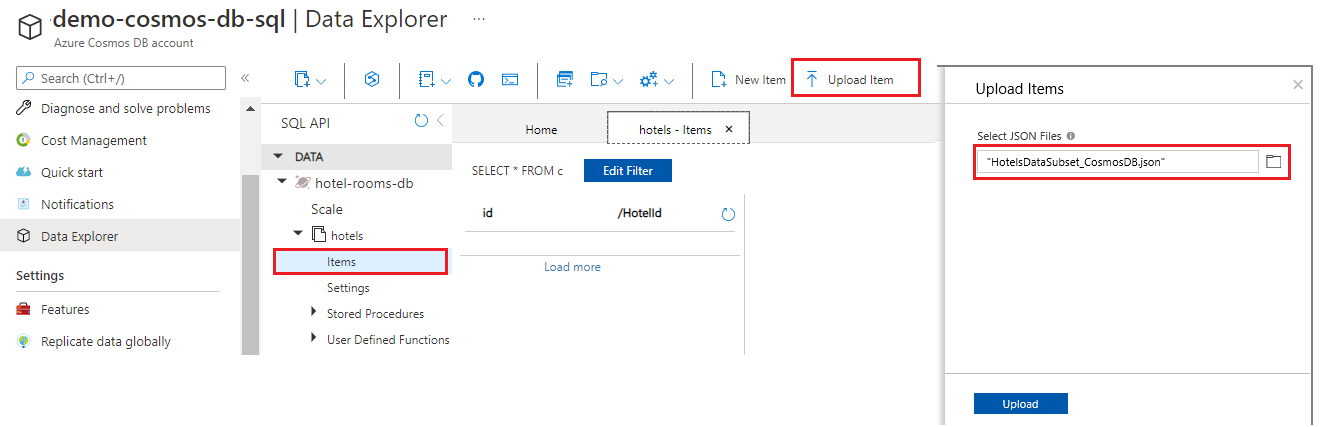
Użyj przycisku odświeżenia, aby odświeżyć widok elementów w kolekcji hoteli. Powinny zostać wyświetlone siedem nowych dokumentów bazy danych.
W okienku po lewej stronie wybierz Ustawienia>Klucze.
Zanotuj parametry połączenia. Ta wartość jest potrzebna dla appsettings.json w późniejszym kroku. Jeśli nie użyto sugerowanej nazwy bazy danych hotel-rooms-db , skopiuj również nazwę bazy danych.
Azure Blob Storage
Zaloguj się do witryny Azure Portal i wybierz swoje konto usługi Azure Storage.
W okienku po lewej stronie wybierz magazyn danych>Kontenery.
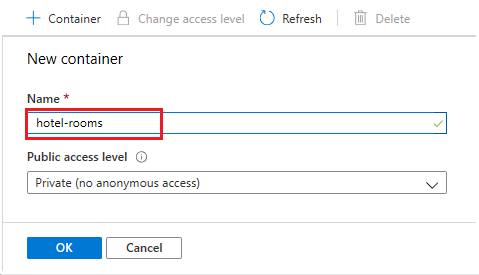
Utwórz kontener blob o nazwie hotel-rooms do przechowywania przykładowych plików JSON pokoi hotelowych. Poziom dostępu można ustawić na dowolną prawidłową wartość.
Otwórz kontener, a następnie wybierz pozycję Przekaż na pasku poleceń.
Prześlij siedem plików JSON z
blobfolderu wielu źródeł danych/v11.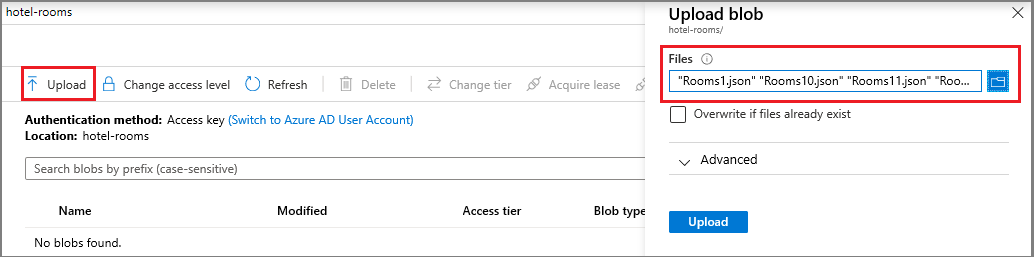
W okienku po lewej stronie wybierz pozycję Zabezpieczenia i klucze dostępu do sieci>.
Zanotuj nazwę konta i parametry połączenia. Obie wartości są potrzebne dla appsettings.json w późniejszym kroku.
Wyszukiwanie AI platformy Azure
Trzecim składnikiem jest usługa Azure AI Search, którą można utworzyć w witrynie Azure Portal lub znaleźć istniejącą usługę wyszukiwania w zasobach platformy Azure.
Kopiowanie klucza administratora i adresu URL usługi Azure AI Search
Aby uwierzytelnić się w usłudze wyszukiwania, potrzebny jest adres URL usługi i klucz dostępu. Posiadanie prawidłowego klucza ustanawia zaufanie na podstawie poszczególnych żądań między aplikacją wysyłającą żądanie a usługą, która go obsługuje.
Zaloguj się do witryny Azure Portal i wybierz usługę wyszukiwania.
W okienku po lewej stronie wybierz pozycję Przegląd.
Zanotuj adres URL, który powinien wyglądać następująco:
https://my-service.search.windows.net.W okienku po lewej stronie wybierz Ustawienia>Klucze.
Zanotuj klucz administratora w celu uzyskania pełnych praw w usłudze. Istnieją dwa zamienne klucze administratora, zapewniające ciągłość działania biznesu na wypadek konieczności wymiany jednego. Możesz użyć dowolnego klucza w żądaniach dodawania, modyfikowania i usuwania obiektów.
Konfigurowanie środowiska
Otwórz plik
AzureSearchMultipleDataSources.slnz lokalizacji multiple-data-sources/v11 w programie Visual Studio.W Eksploratorze rozwiązań kliknij projekt prawym przyciskiem myszy i wybierz polecenie Zarządzaj pakietami NuGet dla rozwiązania....
Na karcie Przeglądaj znajdź i zainstaluj następujące pakiety:
Azure.Search.Documents (wersja 11.0 lub nowsza)
Microsoft.Extensions.Configuration
Microsoft.Extensions.Configuration.Json
W Eksploratorze rozwiązań zmodyfikuj
appsettings.jsonplik przy użyciu informacji o połączeniu zebranych w poprzednich krokach.{ "SearchServiceUri": "<YourSearchServiceURL>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "BlobStorageAccountName": "<YourBlobStorageAccountName>", "BlobStorageConnectionString": "<YourBlobStorageConnectionString>", "CosmosDBConnectionString": "<YourCosmosDBConnectionString>", "CosmosDBDatabaseName": "hotel-rooms-db" }
Mapowanie pól kluczy
Scalanie zawartości wymaga, aby oba strumienie danych dotyczyły tych samych dokumentów w indeksie wyszukiwania.
W usłudze Azure AI Search pole klucza jednoznacznie identyfikuje każdy dokument. Każdy indeks wyszukiwania musi mieć dokładnie jedno pole klucza typu Edm.String. To pole klucza musi być obecne dla każdego dokumentu w źródle danych dodanym do indeksu. (W rzeczywistości jest to jedyne wymagane pole).
Podczas indeksowania danych z wielu źródeł danych upewnij się, że każdy przychodzący wiersz lub dokument zawiera wspólny klucz dokumentu. Dzięki temu można scalić dane z dwóch fizycznie odrębnych dokumentów źródłowych do nowego dokumentu wyszukiwania w połączonym indeksie.
Często wymaga pewnego planowania z góry, aby zidentyfikować znaczący klucz dokumentu dla indeksu i upewnić się, że istnieje on w obu źródłach danych. W tym pokazie klucz HotelId dla każdego hotelu w usłudze Azure Cosmos DB jest również obecny w obiektach blob JSON dla pokoi w usłudze Blob Storage.
Indeksatory usługi Azure AI Search mogą używać mapowań pól do zmieniania nazw, a nawet ponownego formatowania pól danych podczas procesu indeksowania, dzięki czemu dane źródłowe mogą być kierowane do poprawnego pola indeksu. Na przykład w usłudze Azure Cosmos DB identyfikator hotelu nosi nazwę HotelId, ale w plikach obiektów blob JSON dla pokoi hotelowych identyfikator hotelu nosi nazwę Id. Program obsługuje tę rozbieżność, mapując pole Id z blobów na pole klucza HotelId w indeksatorze.
Uwaga
W większości przypadków automatycznie wygenerowane klucze dokumentów, takie jak te utworzone domyślnie przez niektórych indeksatorów, nie tworzą dobrych kluczy dokumentów dla połączonych indeksów. Ogólnie rzecz biorąc, należy użyć znaczącej, unikatowej wartości klucza, która już istnieje w źródłach danych lub można ją łatwo dodać.
Eksplorowanie kodu
Kiedy dane i ustawienia konfiguracji są wprowadzone, przykładowy program w AzureSearchMultipleDataSources.sln powinien być gotowy do skompilowania i uruchomienia.
Ta prosta aplikacja konsolowa C#/.NET wykonuje następujące zadania:
- Tworzy nowy indeks na podstawie struktury danych klasy Hotel w języku C#, która również odwołuje się do klas Address i Room.
- Tworzy nowe źródło danych i indeksator mapujący dane usługi Azure Cosmos DB na pola indeksowania. Są to oba obiekty w usłudze Azure AI Search.
- Uruchamia indeksator, aby załadować dane hotelowe z usługi Azure Cosmos DB.
- Tworzy drugie źródło danych oraz indeksator, który mapuje dane w formacie blob JSON na pola indeksu.
- Uruchamia drugi indeksator, aby załadować dane pokoju hotelowego z usługi Blob Storage.
Zanim uruchomisz program, pośmiń minutę, aby zbadać kod, definicję indeksu i definicję indeksatora. Odpowiedni kod znajduje się w dwóch plikach:
-
Hotel.cszawiera schemat definiujący indeks. -
Program.csZawiera funkcje, które tworzą indeks usługi Azure AI Search, źródła danych i indeksatory oraz ładują połączone wyniki do indeksu.
Tworzenie indeksu
Ten przykładowy program używa metody CreateIndexAsync do definiowania i tworzenia indeksu usługi Azure AI Search. Korzysta z klasy FieldBuilder, aby wygenerować strukturę indeksu na podstawie klasy modelu danych języka C#.
Model danych jest definiowany przez klasę Hotel, która zawiera również odwołania do klas Address i Room. Narzędzie FieldBuilder szczegółowo analizuje wiele definicji klas, aby wygenerować złożoną strukturę danych do indeksowania. Tagi metadanych służą do definiowania atrybutów każdego pola, takich jak możliwość wyszukiwania lub sortowania.
Program usuwa dowolny istniejący indeks o tej samej nazwie przed utworzeniem nowego, jeśli chcesz uruchomić ten przykład więcej niż raz.
Poniższe fragmenty kodu z Hotel.cs pliku pokazują pojedyncze pola, a następnie odwołanie do innej klasy modelu danych Room[], które z kolei jest zdefiniowane w Room.cs pliku (nie pokazano).
. . .
[SimpleField(IsFilterable = true, IsKey = true)]
public string HotelId { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true)]
public string HotelName { get; set; }
. . .
public Room[] Rooms { get; set; }
. . .
W pliku Program.cs indeks SearchIndex jest definiowany z nazwą i listą pól, którą wygenerowano za pomocą metody FieldBuilder.Build, a następnie utworzony w następujący sposób:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address and Room classes are referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Tworzenie źródła danych i indeksatora usługi Azure Cosmos DB
Główny program obejmuje logikę tworzenia źródła danych usługi Azure Cosmos DB dla danych hoteli.
Najpierw łączy ona nazwę bazy danych usługi Azure Cosmos DB z parametrami połączenia. Następnie definiuje obiekt SearchIndexerDataSourceConnection .
private static async Task CreateAndRunCosmosDbIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
// Append the database name to the connection string
string cosmosConnectString =
configuration["CosmosDBConnectionString"]
+ ";Database="
+ configuration["CosmosDBDatabaseName"];
SearchIndexerDataSourceConnection cosmosDbDataSource = new SearchIndexerDataSourceConnection(
name: configuration["CosmosDBDatabaseName"],
type: SearchIndexerDataSourceType.CosmosDb,
connectionString: cosmosConnectString,
container: new SearchIndexerDataContainer("hotels"));
// The Azure Cosmos DB data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(cosmosDbDataSource);
Po utworzeniu źródła danych program konfiguruje indeksator usługi Azure Cosmos DB o nazwie hotel-rooms-cosmos-indexer.
Program aktualizuje wszystkie istniejące indeksatory o tej samej nazwie, zastępując istniejący indeksator zawartością poprzedniego kodu. Obejmuje również akcje resetowania i uruchamiania, jeśli chcesz uruchomić ten przykład więcej niż raz.
W poniższym przykładzie zdefiniowano harmonogram indeksatora, aby był uruchamiany raz dziennie. Możesz usunąć właściwość harmonogram z tego wywołania, jeśli nie chcesz, aby indeksator uruchamiał się ponownie automatycznie w przyszłości.
SearchIndexer cosmosDbIndexer = new SearchIndexer(
name: "hotel-rooms-cosmos-indexer",
dataSourceName: cosmosDbDataSource.Name,
targetIndexName: indexName)
{
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Indexers keep metadata about how much they have already indexed.
// If we already ran the indexer, it "remembers" and does not run again.
// To avoid this, reset the indexer if it exists.
try
{
await indexerClient.GetIndexerAsync(cosmosDbIndexer.Name);
// Reset the indexer if it exists.
await indexerClient.ResetIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
// If the indexer does not exist, 404 will be thrown.
}
await indexerClient.CreateOrUpdateIndexerAsync(cosmosDbIndexer);
Console.WriteLine("Running Azure Cosmos DB indexer...\n");
try
{
// Run the indexer.
await indexerClient.RunIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 429)
{
Console.WriteLine("Failed to run indexer: {0}", ex.Message);
}
Ten przykład zawiera prosty blok try-catch umożliwiający zgłaszanie błędów, które mogą wystąpić podczas wykonywania.
Po uruchomieniu indeksatora usługi Azure Cosmos DB indeks wyszukiwania zawiera pełny zestaw przykładowych dokumentów hotelowych. Jednak pole pokoi dla każdego hotelu jest pustą tablicą, ponieważ źródło danych usługi Azure Cosmos DB pomija szczegóły pokoi. Następnie program pobiera dane z usługi Blob Storage, aby załadować i scalić dane pomieszczenia.
Tworzenie źródła danych i indeksatora usługi Blob Storage
Aby uzyskać szczegóły pomieszczenia, program najpierw konfiguruje źródło danych Blob Storage, aby odwoływać się do zestawu pojedynczych plików blobów JSON.
private static async Task CreateAndRunBlobIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
SearchIndexerDataSourceConnection blobDataSource = new SearchIndexerDataSourceConnection(
name: configuration["BlobStorageAccountName"],
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["BlobStorageConnectionString"],
container: new SearchIndexerDataContainer("hotel-rooms"));
// The blob data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(blobDataSource);
Po utworzeniu źródła danych program konfiguruje indeksator obiektów blob o nazwie hotel-rooms-blob-indexer, jak pokazano poniżej.
Obiekty blob JSON zawierają pole klucza o nazwie Id zamiast HotelId. Kod używa FieldMapping klasy do przekazania indeksatorowi Id wartości pola do HotelId klucza dokumentu w indeksie.
Indeksatory usługi Blob Storage mogą używać IndexingParameters do określenia trybu analizowania. Należy ustawić różne tryby analizowania w zależności od tego, czy obiekty blob reprezentują pojedynczy dokument, czy wiele dokumentów w ramach tego samego obiektu blob. W tym przykładzie każdy obiekt blob reprezentuje pojedynczy dokument JSON, więc kod używa json trybu parsowania. Aby uzyskać więcej informacji na temat parametrów analizowania indeksatora dla obiektów blob JSON, zobacz Indeksowanie obiektów blob JSON.
W tym przykładzie zdefiniowano harmonogram indeksatora, aby był uruchamiany raz dziennie. Możesz usunąć właściwość harmonogram z tego wywołania, jeśli nie chcesz, aby indeksator uruchamiał się ponownie automatycznie w przyszłości.
IndexingParameters parameters = new IndexingParameters();
parameters.Configuration.Add("parsingMode", "json");
SearchIndexer blobIndexer = new SearchIndexer(
name: "hotel-rooms-blob-indexer",
dataSourceName: blobDataSource.Name,
targetIndexName: indexName)
{
Parameters = parameters,
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Map the Id field in the Room documents to the HotelId key field in the index
blobIndexer.FieldMappings.Add(new FieldMapping("Id") { TargetFieldName = "HotelId" });
// Reset the indexer if it already exists
try
{
await indexerClient.GetIndexerAsync(blobIndexer.Name);
await indexerClient.ResetIndexerAsync(blobIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404) { }
await indexerClient.CreateOrUpdateIndexerAsync(blobIndexer);
try
{
// Run the indexer.
await searchService.Indexers.RunAsync(blobIndexer.Name);
}
catch (CloudException e) when (e.Response.StatusCode == (HttpStatusCode)429)
{
Console.WriteLine("Failed to run indexer: {0}", e.Response.Content);
}
Ponieważ indeks jest już wypełniony danymi hotelowymi z bazy danych usługi Azure Cosmos DB, indeksator obiektów blob aktualizuje istniejące dokumenty w indeksie i dodaje szczegóły pokoju.
Uwaga
Jeśli masz te same pola inne niż kluczowe w obu źródłach danych, a dane w tych polach nie są zgodne, indeks zawiera wartości z ostatniego uruchomienia indeksatora. W naszym przykładzie oba źródła danych zawierają HotelName pole. Jeśli z jakiegoś powodu dane w tym polu są inne, w przypadku dokumentów o tej samej wartości HotelName klucza dane z ostatnio indeksowanego źródła danych są wartością przechowywaną w indeksie.
Search
Po uruchomieniu programu możesz eksplorować wypełniony indeks wyszukiwania przy użyciu Eksploratora wyszukiwania w witrynie Azure Portal.
Zaloguj się do witryny Azure Portal i wybierz usługę wyszukiwania.
W okienku po lewej stronie wybierz zarządzanie wyszukiwaniem>Indeksy.
Wybierz hotel-rooms-sample z listy indeksów.
Na karcie Eksplorator wyszukiwania wprowadź zapytanie dotyczące terminu, takiego jak
Luxury.W wynikach powinien zostać wyświetlony co najmniej jeden dokument. Ten dokument powinien zawierać listę obiektów pomieszczeń w tablicy
Rooms.
Resetowanie i ponowne uruchamianie
Na wczesnym etapie eksperymentalnym programowania najbardziej praktycznym podejściem do iteracji projektowej jest usunięcie obiektów z usługi Azure AI Search i umożliwienie ponownego kompilowania kodu. Nazwy zasobów są unikatowe. Usunięcie obiektu umożliwia jego ponowne utworzenie przy użyciu tej samej nazwy.
Przykładowy kod sprawdza istniejące obiekty i usuwa lub aktualizuje je, aby można było ponownie uruchomić program. Za pomocą witryny Azure Portal można również usuwać indeksy, indeksatory i źródła danych.
Czyszczenie zasobów
Gdy pracujesz we własnej subskrypcji, na końcu projektu warto usunąć zasoby, których już nie potrzebujesz. Zasoby pozostawione w działaniu mogą generować koszty. Zasoby możesz usuwać pojedynczo lub jako grupę zasobów, usuwając cały zestaw zasobów.
Zasoby można znaleźć w witrynie Azure Portal i zarządzać nimi przy użyciu linku Wszystkie zasoby lub Grupy zasobów w okienku po lewej stronie.
Następny krok
Teraz, gdy znasz już pozyskiwanie danych z wielu źródeł, przyjrzyj się bliżej konfiguracji indeksatora, zaczynając od usługi Azure Cosmos DB: