Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Wskazówka
Ta zawartość jest fragmentem e-książki, Architektura Cloud Native .NET Applications for Azure, dostępnej w .NET Docs lub jako bezpłatny plik PDF do pobrania, który można czytać offline.

Pierwsza linia obrony to odporność aplikacji.
Chociaż możesz zainwestować dużo czasu na pisanie własnej struktury odporności, takie produkty już istnieją.
Polly to kompleksowa biblioteka odporności i obsługi błędów przejściowych dla platformy .NET, która umożliwia deweloperom wyrażanie zasad odporności w sposób płynny i bezpieczny wątkowo. Aplikacja Polly jest przeznaczona dla aplikacji utworzonych przy użyciu programu .NET Framework lub .NET 7. W poniższej tabeli opisano funkcje odporności o nazwie policies, dostępne w bibliotece Polly. Można je stosować pojedynczo lub grupować razem.
| Polityka | Doświadczenie |
|---|---|
| Ponów próbę | Konfiguruje operacje ponawiania prób dla wyznaczonych operacji. |
| Wyłącznik obwodu | Blokuje żądane operacje dla wstępnie zdefiniowanego okresu, gdy błędy przekraczają skonfigurowany próg |
| Przerwa czasowa | Określa limit czasu trwania, przez który obiekt wywołujący może czekać na odpowiedź. |
| Gródź | Ogranicza działania do puli zasobów o stałym rozmiarze, aby zapobiec przeciążeniu zasobu przez nieudane wywołania. |
| Pamięć podręczna | Automatycznie przechowuje odpowiedzi. |
| Rezerwowej | Definiuje zachowanie strukturalne po awarii. |
Zwróć uwagę, jak na poprzedniej ilustracji zasady dotyczące odporności systemu mają zastosowanie do wiadomości żądań, niezależnie od tego, czy pochodzą od zewnętrznego klienta, czy też z usługi backendowej. Celem jest zrekompensowanie żądania usługi, która może być chwilowo niedostępna. Te krótkotrwałe przerwy zwykle manifestują się przy użyciu kodów stanu HTTP przedstawionych w poniższej tabeli.
| Kod stanu HTTP | Przyczyna |
|---|---|
| 404 | Nie znaleziono |
| 408 | Przekroczono limit czasu żądania |
| 429 | Zbyt wiele żądań (najprawdopodobniej zostałeś ograniczony) |
| 502 | Zła brama |
| 503 | Usługa niedostępna |
| 504 | Limit czasu bramy |
Pytanie: Czy ponowisz próbę kodu stanu HTTP 403 — Zabronione? Nie. W tym miejscu system działa prawidłowo, ale informuje obiekt wywołujący, że nie ma autoryzacji do wykonania żądanej operacji. Należy zachować ostrożność, aby ponowić próbę wykonania tylko tych operacji spowodowanych awariami.
Jak zaleca rozdział 1, deweloperzy Microsoft, tworząc aplikacje natywne dla chmury, powinni celować w platformę .NET. W wersji 2.1 wprowadzono bibliotekę HTTPClientFactory służącą do tworzenia wystąpień klienta HTTP na potrzeby interakcji z zasobami opartymi na adresach URL. Zastępując oryginalną klasę HTTPClient, klasa fabryczna obsługuje wiele rozszerzonych funkcji, z których jedną jest ścisła integracja z biblioteką odporności Polly. Dzięki niemu można łatwo zdefiniować zasady odporności w klasie uruchamiania aplikacji w celu obsługi częściowych awarii i problemów z łącznością.
Następnie rozszerzmy wzorce ponawiania prób i wyłącznika.
Wzorzec ponawiania
W rozproszonym środowisku natywnym dla chmury wywołania usług i zasobów w chmurze mogą zakończyć się niepowodzeniem z powodu przejściowych (krótkotrwałych) awarii, które zwykle korygują się po krótkim czasie. Zaimplementowanie strategii ponawiania prób pomaga usłudze natywnej dla chmury ograniczyć te scenariusze.
Wzorzec ponawiania umożliwia usłudze ponowienie próby wykonania operacji żądania, która zakończyła się niepowodzeniem (konfigurowalna) liczbą razy z wykładniczo rosnącym czasem oczekiwania. Rysunek 6–2 przedstawia ponowienie próby w akcji.
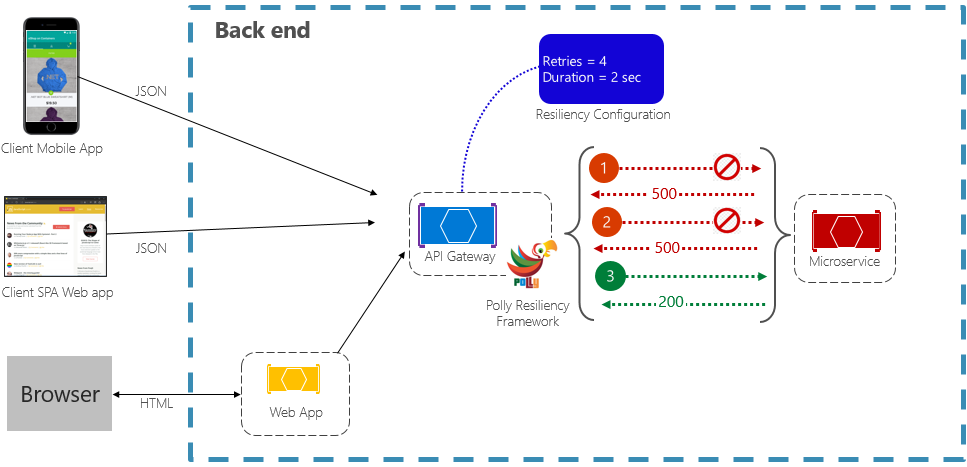
Rysunek 6–2. Wzorzec ponawiania działań w praktyce
Na poprzednim rysunku zaimplementowano wzorzec ponawiania prób dla operacji związanej z żądaniami. Jest on skonfigurowany tak, aby umożliwić maksymalnie cztery ponawianie prób przed niepowodzeniem z interwałem wycofywania (czas oczekiwania) rozpoczynającym się od dwóch sekund, co wykładniczo podwaja się dla każdej kolejnej próby.
- Pierwsze wywołanie kończy się niepowodzeniem i zwraca kod stanu HTTP 500. Aplikacja czeka na dwie sekundy i ponawia próbę wywołania.
- Drugie wywołanie również kończy się niepowodzeniem i zwraca kod stanu HTTP 500. Aplikacja podwoi teraz interwał wycofywania do czterech sekund i ponawia próbę wywołania.
- W końcu trzecie wywołanie powiedzie się.
- W tym scenariuszu operacja ponawiania prób wykonałaby do czterech ponownych prób, podwajając czas opóźnienia przed niepowodzeniem połączenia.
- Gdyby czwarta próba ponowienia zawiodła, zostałaby uruchomiona procedura awaryjna, aby bezpiecznie poradzić sobie z problemem.
Ważne jest, aby zwiększyć czas oczekiwania przed ponowną próbą wywołania, aby dać usługom czas na samodzielną korektę. Najlepszym rozwiązaniem jest zaimplementowanie wykładniczo rosnącego wycofywania (podwojenie okresu ponawiania próby) w celu umożliwienia odpowiedniego czasu korekty.
Wzorzec wyłącznika
Chociaż wzorzec ponawiania prób może pomóc uratować żądanie splątane w częściowym błędzie, istnieją sytuacje, w których awarie mogą być spowodowane przez nieprzewidziane zdarzenia, które będą wymagać dłuższych okresów czasu do rozwiązania. Takie błędy mogą mieć różny stopień ważności — od częściowej utraty łączności do całkowitej awarii usługi. W takich sytuacjach nie ma sensu, aby aplikacja stale ponawiała próbę wykonania operacji, która prawdopodobnie nie powiedzie się.
Co gorsza, wykonywanie ciągłych operacji ponawiania prób w usłudze niereponsywnej może spowodować przejście do scenariusza samodzielnej odmowy usługi, w którym usługa jest zalana ciągłymi wywołaniami wyczerpującymi zasobami, takimi jak pamięć, wątki i połączenia bazy danych, powodując awarię niepowiązanych części systemu, które korzystają z tych samych zasobów.
W takich sytuacjach preferowane byłoby natychmiastowe niepowodzenie operacji i próba wywołania usługi tylko wtedy, gdy prawdopodobnie powiedzie się.
Wzorzec wyłącznika może zapobiec wielokrotnym próbom wykonania przez aplikację operacji, która prawdopodobnie zakończy się niepowodzeniem. Po wstępnie zdefiniowanej liczbie wywołań zakończonych niepowodzeniem blokuje cały ruch do usługi. W określonych odstępach czasu umożliwi połączenie testowe w celu ustalenia, czy usterka została rozwiązana. Rysunek 6–3 przedstawia wzorzec wyłącznika w działaniu.

Rysunek 6–3. Wzorzec wyłącznika w działaniu
Na poprzedniej ilustracji do oryginalnego wzorca ponawiania prób dodano wzorzec Circuit Breaker. Zwróć uwagę, jak po 100 żądaniach, które zakończyły się niepowodzeniem, wyłącznik otwiera się i nie zezwala już na wywołania usługi. Wartość CheckCircuit ustawiona na 30 sekund określa, jak często biblioteka zezwala na zrealizowanie przez usługę jednego żądania. Jeśli to wywołanie powiedzie się, obwód zostanie zamknięty, a usługa będzie raz jeszcze dostępna dla ruchu.
Należy pamiętać, że cel wzorca wyłącznika różni się od celu wzorca ponawiania. Wzorzec ponawiania umożliwia aplikacji ponawianie próby wykonania operacji w oczekiwaniu, że zakończy się powodzeniem. Wzorzec wyłącznika uniemożliwia aplikacji wykonywanie operacji, która może zakończyć się niepowodzeniem. Zazwyczaj aplikacja łączy te dwa wzorce przy użyciu wzorca ponawiania w celu wywołania operacji za pośrednictwem wyłącznika.
Testowanie pod kątem odporności
Testowanie odporności nie zawsze może odbywać się w taki sam sposób, w jaki testujesz funkcjonalność aplikacji (uruchamiając testy jednostkowe, testy integracji itd.). Zamiast tego należy przetestować sposób działania kompleksowego obciążenia w warunkach awarii, które występują tylko sporadycznie. Na przykład: wprowadzanie błędów przez awarie procesów, wygasłych certyfikatów, niedostępność usług zależnych itp. Struktury takie jak chaos-monkey mogą być używane do takich testów chaosu.
Odporność aplikacji jest koniecznością obsługi problematycznych żądanych operacji. Ale to tylko połowa historii. Następnie omówimy funkcje odporności dostępne w chmurze platformy Azure.
Współpracuj z nami na GitHub
Źródło tej treści można znaleźć na GitHubie, gdzie można także tworzyć i przeglądać problemy oraz pull requesty. Więcej informacji znajdziesz w naszym przewodniku dla współautorów.