Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Wskazówka
Ta zawartość jest fragmentem e-książki, Architektura Cloud Native .NET Applications for Azure, dostępnej w .NET Docs lub jako bezpłatny plik PDF do pobrania, który można czytać offline.

Ulubioną mantrą konsultantów oprogramowania jest odpowiedź "To zależy" od dowolnego pytania zadanego. Nie dlatego, że konsultantzy oprogramowania lubią nie zajmować stanowiska. To dlatego, że nie ma żadnej prawdziwej odpowiedzi na pytania w oprogramowaniu. Nie ma absolutnej słusznej i złej, ale raczej równowagi między przeciwieństwami.
Weźmy na przykład dwie główne szkoły tworzenia aplikacji internetowych: aplikacje jednostronicowe (SPA) w porównaniu z aplikacjami po stronie serwera. Z jednej strony doświadczenie użytkownika wydaje się być lepsze w przypadku aplikacji jednokartkowych (SPA), a ilość ruchu do serwera internetowego można zminimalizować, umożliwiając hostowanie ich na czymś tak prostym jak statyczny hosting. Z drugiej strony, SPA wydają się być wolniejsze do rozwoju i trudniejsze do testowania. Który z nich jest właściwym wyborem? Cóż, zależy to od twojej sytuacji.
Aplikacje natywne dla chmury nie są odporne na tę samą dichotomię. Mają one wyraźne zalety pod względem szybkości rozwoju, stabilności i skalowalności, ale zarządzanie nimi może być nieco trudniejsze.
Wiele lat temu nie było niczym niezwykłym, że proces przenoszenia aplikacji z etapu rozwoju do środowiska produkcyjnego trwał miesiąc, a nawet dłużej. Firmy wydają oprogramowanie regularnie co 6 miesięcy lub nawet co rok. Należy spojrzeć nie dalej niż Microsoft Windows, aby uzyskać pomysł na cykl wydań, które były akceptowalne przed wiecznie zielonymi dniami systemu Windows 10. Pięć lat minęło między Windows XP i Vista, kolejne trzy między Vista i Windows 7.
Jest już dobrze ustalone, że możliwość szybkiego wydawania oprogramowania daje dynamicznym firmom ogromną przewagę rynkową nad ich bardziej powolnymi konkurentami. Z tego powodu główne aktualizacje systemu Windows 10 są teraz mniej więcej co sześć miesięcy.
Wzorce i praktyki, które umożliwiają szybsze, bardziej niezawodne wydania zapewniające wartość firmie, są wspólnie znane jako DevOps. Składają się one z szerokiej gamy pomysłów obejmujących cały cykl życia tworzenia oprogramowania od określenia aplikacji aż do dostarczania i obsługi tej aplikacji.
Metodyka DevOps pojawiła się przed mikrousługami, i prawdopodobnie ruch w kierunku mniejszych, bardziej dostosowanych do celu usług nie byłby możliwy bez DevOps, aby umożliwić łatwiejsze wdrażanie i obsługę nie tylko jednej, ale wielu aplikacji w produkcji.
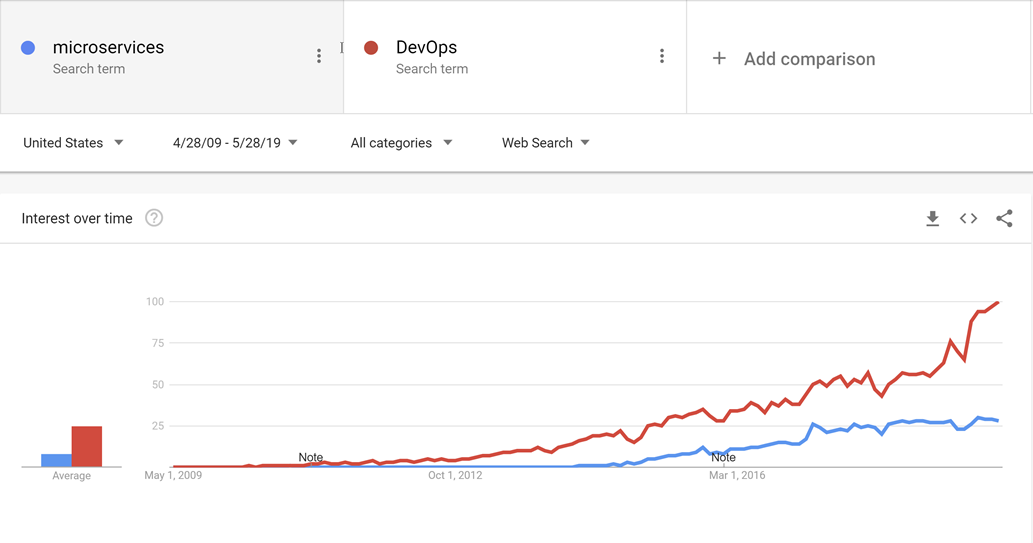
Rysunek 10–1 — Metodyka DevOps i mikrousługi.
Dzięki dobrym praktykom DevOps można dokonać korzyści aplikacji natywnych dla chmury bez duszenia się pod nawałem pracy związanej z faktycznym działaniem aplikacji.
Nie ma złotego młotka, jeśli chodzi o DevOps. Nikt nie może sprzedać kompletnego i kompleksowego rozwiązania do wydawania i obsługi aplikacji wysokiej jakości. Jest to spowodowane tym, że każda aplikacja jest szalenie inna niż wszystkie inne. Istnieją jednak narzędzia, które mogą sprawić, że metodyka DevOps stanie się znacznie mniej trudna. Jedno z tych narzędzi jest nazywane usługą Azure DevOps.
Azure DevOps
Usługa Azure DevOps ma długą rodowód. Może prześledzić swoje korzenie od czasu, gdy Team Foundation Server po raz pierwszy przeszedł na tryb online, poprzez różne zmiany nazw: Visual Studio Online oraz Visual Studio Team Services. Przez lata stało się to jednak czymś znacznie więcej niż jego poprzedniki.
Usługa Azure DevOps jest podzielona na pięć głównych składników:

Rysunek 10–2 — Azure DevOps.
Azure Repos — zarządzanie kodem źródłowym, które obsługuje venerable Team Foundation Version Control (TFVC) i ulubioną w branży usługę Git. Pull requesty wspomagają kodowanie społecznościowe poprzez ułatwianie dyskusji nad wprowadzanymi zmianami.
Azure Boards — udostępnia narzędzie do śledzenia problemów i elementów roboczych, które dąży do umożliwienia użytkownikom wybierania przepływów pracy, które najlepiej dla nich działają. Jest on dostarczany z wieloma wstępnie skonfigurowanymi szablonami, w tym tymi, które obsługują style programowania SCRUM i Kanban.
Azure Pipelines — system zarządzania kompilacjami i wydaniami, który obsługuje ścisłą integrację z platformą Azure. Kompilacje można uruchamiać na różnych platformach z systemu Windows do systemu Linux do systemu macOS. Agenci kompilacji mogą być aprowizowani w chmurze lub lokalnie.
Plany testów platformy Azure — żadna osoba qa nie pozostanie w tyle dzięki obsłudze zarządzania testami i testowania eksploracyjnego oferowanej przez funkcję Planów testów.
Azure Artifacts — źródło artefaktów, które umożliwia firmom tworzenie własnych, wewnętrznych, wersji pakietów NuGet, npm i innych. Służy on podwójnemu celowi działania jako pamięci podręcznej pakietów nadrzędnych, jeśli wystąpi awaria scentralizowanego repozytorium.
Jednostka organizacyjna najwyższego poziomu w usłudze Azure DevOps jest nazywana projektem. W każdym projekcie różne składniki, takie jak Azure Artifacts, można włączać i wyłączać. Każdy z tych składników zapewnia różne korzyści dla aplikacji natywnych dla chmury. Trzy najbardziej przydatne to repozytoria, tablice i potoki. Jeśli użytkownicy chcą zarządzać kodem źródłowym w innym stosie repozytorium, takim jak GitHub, ale nadal korzystają z usługi Azure Pipelines i innych składników, jest to całkowicie możliwe.
Na szczęście zespoły programistyczne mają wiele opcji podczas wybierania repozytorium. Jednym z nich jest usługa GitHub.
Działania GitHub
Założona w 2009 r. usługa GitHub jest powszechnie popularnym internetowym repozytorium do hostowania projektów, dokumentacji i kodu. Wiele dużych firm technologicznych, takich jak Apple, Amazon, Google i główne korporacje korzystają z usługi GitHub. Usługa GitHub używa rozproszonego systemu kontroli wersji typu open source o nazwie Git jako jego podstawy. Następnie dodaje własny zestaw funkcji, w tym śledzenie wad, żądania funkcji i ściągnięcia, zarządzanie zadaniami i witryny typu wiki dla każdej bazy kodu.
W miarę rozwoju usługi GitHub również dodaje ona funkcje metodyki DevOps. Na przykład GitHub posiada własny pipeline ciągłej integracji/ciągłego dostarczania (CI/CD) o nazwie GitHub Actions. GitHub Actions jest narzędziem do automatyzacji przepływu pracy napędzanym przez społeczność. Umożliwia ona zespołom DevOps integrację z istniejącymi narzędziami, zestawianie i dopasowywanie nowych produktów oraz wpięcie się w cykl życia oprogramowania, w tym współpracę z istniejącymi partnerami CI/CD.
Usługa GitHub ma ponad 40 milionów użytkowników, co czyni go największym hostem kodu źródłowego na świecie. W październiku 2018 r. firma Microsoft zakupiła usługę GitHub. Firma Microsoft zobowiązała się, że usługa GitHub pozostanie otwartą platformą , którą każdy deweloper może podłączyć i rozszerzyć. Nadal działa jako niezależna firma. Usługa GitHub oferuje plany dla przedsiębiorstw, zespołów, profesjonalistów i bezpłatnych kont.
Kontrola źródła
Organizowanie kodu dla aplikacji natywnej dla chmury może być trudne. Zamiast jednej gigantycznej aplikacji aplikacje natywne dla chmury zwykle składają się z internetu mniejszych aplikacji, które komunikują się ze sobą. Podobnie jak w przypadku wszystkich elementów informatyki, najlepsza aranżacja kodu pozostaje otwartym pytaniem. Istnieją przykłady pomyślnych aplikacji korzystających z różnych rodzajów układów, ale dwa warianty wydają się mieć największą popularność.
Przed przejściem do samej kontroli źródła warto zdecydować, ile projektów jest odpowiednich. W ramach jednego projektu istnieje obsługa wielu repozytoriów i potoków kompilacji. Tablice są nieco bardziej skomplikowane, ale zadania również można łatwo przypisać wielu zespołom w ramach jednego projektu. Istnieje możliwość obsługi setek, nawet tysięcy deweloperów, z jednego projektu usługi Azure DevOps. Jest to prawdopodobnie najlepsze podejście, ponieważ zapewnia pojedyncze miejsce dla wszystkich deweloperów do pracy i zmniejsza zamieszanie w znalezieniu jednej aplikacji, gdy deweloperzy nie są pewni, w którym projekcie, w którym się znajduje.
Dzielenie kodu dla mikrousług w projekcie usługi Azure DevOps może być nieco trudniejsze.
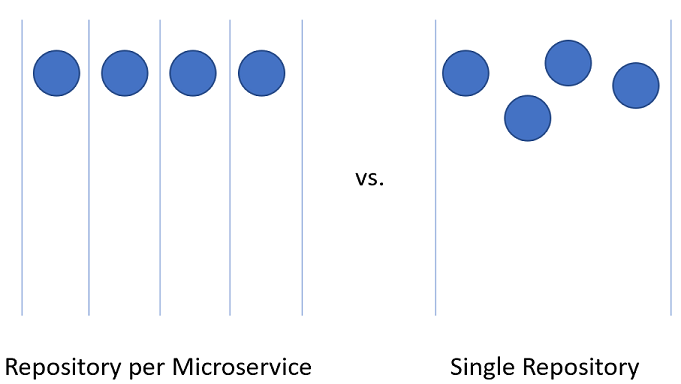
Rysunek 10–3 — jedno kontra wiele repozytoriów.
Repozytorium dla każdej mikrousługi
Na pierwszy rzut oka takie podejście wydaje się najbardziej logiczne podejście do dzielenia kodu źródłowego dla mikrousług. Każde repozytorium może zawierać kod potrzebny do utworzenia jednej mikrousługi. Zalety tego podejścia są łatwo widoczne:
- Instrukcje dotyczące kompilowania i obsługi aplikacji można dodać do pliku README w katalogu głównym każdego repozytorium. Podczas przeglądania repozytoriów można łatwo znaleźć te instrukcje, skracając czas uruchamiania dla programistów.
- Każda usługa znajduje się w logicznym miejscu, łatwo odnajdując nazwę usługi.
- Można łatwo skonfigurować buildy tak, aby były uruchamiane tylko po wprowadzeniu zmiany w repozytorium właściciela.
- Liczba zmian przychodzących do repozytorium jest ograniczona do niewielkiej liczby deweloperów pracujących nad projektem.
- Zabezpieczenia można łatwo skonfigurować, ograniczając repozytoria, do których deweloperzy mają uprawnienia do odczytu i zapisu.
- Ustawienia na poziomie repozytorium mogą być zmieniane przez zespół z minimalną koniecznością konsultacji z innymi.
Jednym z kluczowych pomysłów dotyczących mikrousług jest to, że usługi powinny być silosowane i oddzielone od siebie. W przypadku korzystania z projektu opartego na domenie do decydowania o granicach usług usługi działają jako granice transakcyjne. Aktualizacje bazy danych nie powinny obejmować wielu usług. Ta kolekcja powiązanych danych jest określana jako ograniczony kontekst. Ten pomysł jest odzwierciedlany przez izolację danych mikrousług do bazy danych oddzielnie i autonomicznie od pozostałych usług. To ma duży sens, aby wdrożyć ten pomysł w całości do kodu źródłowego.
Jednak takie podejście nie jest bez problemów. Jednym z bardziej skomplikowanych problemów związanych z rozwojem oprogramowania w naszych czasach jest zarządzanie zależnościami. Rozważ liczbę plików tworzących średni node_modules katalog. Nowa instalacja czegoś takiego jak create-react-app może zawierać tysiące pakietów. Kwestia zarządzania tymi zależnościami jest trudna.
Jeśli zależność zostanie zaktualizowana, pakiety podrzędne muszą również zaktualizować tę zależność. Niestety, wymaga to pracy programistycznej, więc niezmiennie node_modules katalog kończy się wieloma wersjami pojedynczego pakietu, z których każdy jest zależnością innego pakietu, który jest wersjonowany w nieco innym tempie. Której wersji zależności należy użyć podczas wdrażania aplikacji? Wersja, która jest obecnie na produkcji? Wersja, która jest obecnie w wersji beta, ale prawdopodobnie zostanie wdrożona do produkcji, zanim produkt trafi do konsumentów. Trudne problemy, które nie są rozwiązywane tylko przy użyciu mikrousług.
Istnieją biblioteki, które są zależne od wielu różnych projektów. Dzieląc mikrousługi na jedno w każdym repozytorium, zależności wewnętrzne można rozwiązać przy użyciu wewnętrznego repozytorium Azure Artifacts. Kompilacje dla bibliotek będą przekazywać najnowsze wersje do platformy Azure Artifacts do użytku wewnętrznego. Projekt podrzędny musi być nadal aktualizowany ręcznie, aby mieć zależność od nowo zaktualizowanych pakietów.
Kolejna wada przedstawia się podczas przenoszenia kodu między usługami. Chociaż miło byłoby uwierzyć, że pierwszy podział aplikacji na mikrousługi jest 100% poprawny, rzeczywistość jest taka, że rzadko jesteśmy tak wstępnie, aby nie popełniać błędów podziału usług. W związku z tym funkcjonalność i kod, które ją napędzają, będą musiały przemieszczać się z usługi do usługi, z repozytorium do repozytorium. Podczas skoku z jednego repozytorium do drugiego kod traci jego historię. Istnieje wiele przypadków, szczególnie w przypadku inspekcji, w których pełna historia na kawałku kodu jest bezcenna.
Ostatnia i najważniejsza wadą jest koordynowanie zmian. W prawdziwej aplikacji mikrousług nie powinno istnieć żadne zależności wdrażania między usługami. Powinno być możliwe wdrożenie usług A, B i C w dowolnej kolejności, ponieważ mają luźne sprzężenia. W rzeczywistości jednak czasami pożądane jest wprowadzenie zmiany obejmującej wiele repozytoriów w tym samym czasie. Niektóre przykłady obejmują aktualizowanie biblioteki w celu zamknięcia zabezpieczeń lub zmiany protokołu komunikacyjnego używanego przez wszystkie usługi.
Aby przeprowadzić zmianę między repozytoriami, konieczne jest wykonanie zatwierdzenia w każdym repozytorium kolejno. Każda zmiana w każdym repozytorium musi być złożona jako pull request i przeglądana oddzielnie. To działanie może być trudne do koordynowania.
Alternatywą dla korzystania z wielu repozytoriów jest umieszczenie całego kodu źródłowego w jednym, wszechstronnym repozytorium.
Pojedyncze repozytorium
W tym podejściu czasami nazywane monorepository cały kod źródłowy dla każdej usługi jest umieszczany w tym samym repozytorium. Na początku takie podejście wydaje się strasznym pomysłem, który może sprawić, że radzenie sobie z kodem źródłowym jest niewygodne. Istnieją jednak pewne wyraźne zalety pracy w ten sposób.
Pierwszą zaletą jest to, że łatwiej jest zarządzać zależnościami między projektami. Zamiast polegać na zewnętrznym źródle artefaktów, projekty mogą bezpośrednio importować się wzajemnie. Oznacza to, że aktualizacje są natychmiastowe, a wersje powodujące konflikty prawdopodobnie zostaną znalezione w czasie kompilacji na stacji roboczej dewelopera. W efekcie przesunięcie niektórych testów integracji w lewo.
Podczas przenoszenia kodu między projektami teraz łatwiej jest zachować historię, ponieważ pliki zostaną wykryte jako przeniesione, a nie odpisane.
Kolejną zaletą jest to, że szerokie zmiany, które przekraczają granice usług, można wprowadzić w jednym zatwierdzeniu. To działanie zmniejsza obciążenie związane z przeglądaniem potencjalnie dziesiątek zmian indywidualnie.
Istnieje wiele narzędzi, które umożliwiają przeprowadzanie statycznej analizy kodu w celu wykrywania niezabezpieczonych praktyk programistycznych lub problematycznego używania interfejsów API. W świecie z wieloma repozytoriami każde repozytorium będzie musiało zostać przetworzone, aby znaleźć w nim problemy. Pojedyncze repozytorium umożliwia uruchamianie analizy w jednym miejscu.
Istnieje również wiele wad podejścia do pojedynczego repozytorium. Jednym z najbardziej niepokojących jest to, że posiadanie jednego repozytorium budzi obawy dotyczące zabezpieczeń. Jeśli zawartość repozytorium zostanie ujawniona w modelu repozytorium per usługa, ilość utraconego kodu jest minimalna. Przy jednym repozytorium wszystko, co należy do firmy, mogłoby zostać utracone. W przeszłości istniało wiele przykładów, gdy to się działo i pokrzyżowało całe prace nad tworzeniem gier. Posiadanie wielu repozytoriów uwidacznia mniej obszaru powierzchni, co jest pożądaną cechą w większości praktyk w zakresie zabezpieczeń.
Rozmiar pojedynczego repozytorium może stać się szybko niezarządzany. Przedstawia to pewne interesujące implikacje dotyczące wydajności. Może być konieczne użycie wyspecjalizowanych narzędzi, takich jak wirtualny system plików dla usługi Git, który został pierwotnie zaprojektowany w celu poprawy środowiska dla deweloperów w zespole systemu Windows.
Często argument użycia pojedynczego repozytorium sprowadza się do argumentu, że Facebook lub Google używają tej metody do rozmieszczenia kodu źródłowego. Jeśli podejście jest wystarczająco dobre dla tych firm, to z pewnością jest to właściwe podejście dla wszystkich firm. Prawda jest taka, że niewiele firm działa na skalę Facebooka lub Google. Problemy występujące na tych skalach różnią się od tych, z którymi borykają się większość deweloperów. Co jest dobre dla gęsi może nie być dobre dla gandera.
W końcu można użyć dowolnego rozwiązania do hostowania kodu źródłowego dla mikrousług. Jednak w większości przypadków nakłady związane z zarządzaniem i inżynierią wynikające z działania w jednym repozytorium nie są warte niewielkich korzyści. Dzielenie kodu na wiele repozytoriów zachęca do lepszego rozdzielenia obaw i zachęca do autonomii między zespołami deweloperów.
Standardowa struktura katalogów
Niezależnie od debaty na temat pojedynczego a wielokrotnego repozytorium, każda usługa będzie miała własny katalog. Jedną z najlepszych optymalizacji umożliwiających deweloperom szybkie przekraczanie między projektami jest utrzymanie standardowej struktury katalogów.
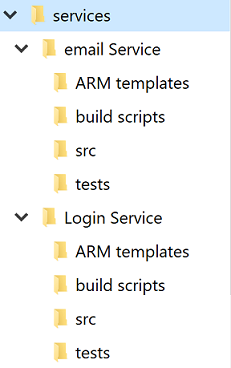
Rysunek 10-4 — Standardowa struktura katalogów.
Za każdym razem, gdy zostanie utworzony nowy projekt, należy użyć szablonu, który umieszcza prawidłową strukturę. Ten szablon może również zawierać takie przydatne elementy jak szkieletowy plik README i element azure-pipelines.yml. W każdej architekturze mikrousług wysoki stopień wariancji między projektami sprawia, że operacje zbiorcze względem usług są trudniejsze.
Istnieje wiele narzędzi, które umożliwiają tworzenie szablonów dla całego katalogu zawierającego kilka katalogów kodu źródłowego. Narzędzie Yeoman jest popularne w świecie języka JavaScript, a usługa GitHub opublikowała niedawno szablony repozytorium, które zapewniają wiele tych samych funkcji.
Zarządzanie zadaniami
Zarządzanie zadaniami w dowolnym projekcie może być trudne. Na początku istnieje niezliczona liczba pytań, na które należy odpowiedzieć na temat rodzaju przepływów pracy do skonfigurowania dla optymalnej produktywności deweloperów.
Aplikacje natywne dla chmury są zwykle mniejsze niż tradycyjne produkty programowe lub przynajmniej są podzielone na mniejsze usługi. Śledzenie problemów lub zadań związanych z tymi usługami pozostaje tak ważne, jak w przypadku każdego innego projektu oprogramowania. Nikt nie chce stracić kontroli nad niektórymi zadaniami ani wyjaśniać klientowi, że ich problem nie został odpowiednio zapisany. Tablice są konfigurowane na poziomie projektu, ale w ramach każdego projektu można zdefiniować obszary. Umożliwiają one podzielenie problemów między kilkoma składnikami. Zaletą utrzymania całej pracy dla całej aplikacji w jednym miejscu jest łatwe przenoszenie elementów roboczych z jednego zespołu do drugiego, ponieważ są one lepiej zrozumiałe.
Usługa Azure DevOps jest dostarczana ze wstępnie skonfigurowanymi popularnymi szablonami. W najbardziej podstawowej konfiguracji potrzebne jest jedynie wiedzieć, co znajduje się na liście zaległych zadań, nad czym pracują ludzie i co zostało ukończone. Ważne jest, aby mieć ten wgląd w proces tworzenia oprogramowania, dzięki czemu praca może być priorytetowo rozpatrywana, a ukończone zadania zgłaszane klientowi. Oczywiście kilka projektów oprogramowania trzyma się procesu tak prostego, jak to do, doingi done. Nie trzeba długo czekać, aby ludzie zaczęli dodawać kroki, takie jak QA lub Detailed Specification do procesu.
Jedną z ważniejszych części metodologii Agile jest samointerspekcja w regularnych odstępach czasu. Te przeglądy mają na celu zapewnienie wglądu w problemy, przed którymi stoi zespół i jak można je ulepszyć. Często oznacza to zmianę przepływu problemów i funkcji przez proces programowania. Jest więc całkowicie w porządku rozszerzać układy plansz o dodatkowe etapy.
Etapy w tablicach nie są jedynym narzędziem organizacyjnym. W zależności od konfiguracji tablicy istnieje hierarchia elementów roboczych. Najbardziej szczegółowym elementem, który może pojawić się na tablicy, jest zadanie. Zadanie domyślnie zawiera pola dla tytułu, opisu, priorytetu, oszacowania pozostałej ilości pracy oraz funkcję łączenia z innymi elementami roboczymi lub programistycznymi (gałęziami, commitami, pull requestami, kompilacjami itp.). Elementy robocze można podzielić na różne obszary aplikacji i różne iteracji (przebiegi), aby ułatwić ich znalezienie.
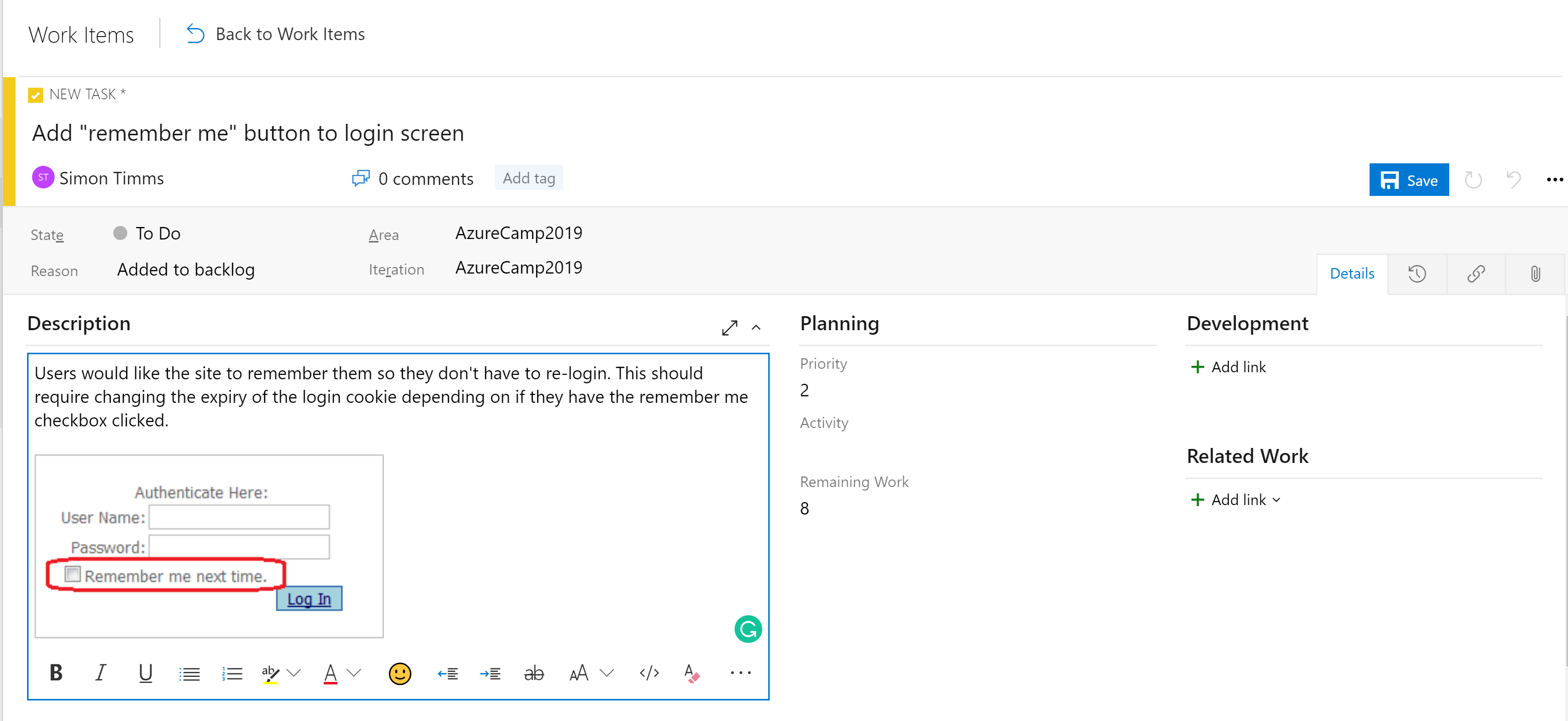
Rysunek 10–5 — zadanie w usłudze Azure DevOps.
Pole opisu obsługuje normalne style, których można oczekiwać (pogrubienie, kursywa, podkreślenie i przekreślenie) oraz umożliwia wstawianie obrazów. Dzięki temu jest to zaawansowane narzędzie do użycia podczas określania pracy lub usterek.
Zadania można podzielić na funkcje, które definiują większą jednostkę pracy. Funkcje można z kolei łączyć w epiki. Klasyfikowanie zadań w tej hierarchii znacznie ułatwia zrozumienie, jak blisko wdrożenia jest duża funkcja.

Rysunek 10–6 — element roboczy w usłudze Azure DevOps.
W usłudze Azure Boards istnieją różne rodzaje widoków na problemy. Elementy, które nie zostały jeszcze zaplanowane, są wyświetlane na liście prac. Z tego miejsca można je przypisać do sprintu. Sprint to okres czasu, w którym oczekuje się, że zostanie ukończona określona ilość pracy. Ta praca może obejmować zadania, ale także rozwiązanie biletów. Po dotarciu tam, całym sprintem można zarządzać z sekcji Tablica sprintu. W tym widoku pokazano, jak postępują prace i zawiera wykres spalania, aby dostarczyć ciągle aktualizowaną prognozę, czy sprint zakończy się sukcesem.

Rysunek 10–7 — tablica w usłudze Azure DevOps.
Do tej pory powinno być oczywiste, że funkcja Boards w Azure DevOps ma dużą siłę. Dla deweloperów dostępne są łatwe widoki na to, nad czym pracują. Dla menedżerów projektów oferujemy wgląd w nadchodzące prace oraz pełny przegląd istniejących prac. Dla menedżerów istnieje wiele raportów na temat zasobów i zdolności produkcyjnych. Niestety, nie ma nic magicznego w aplikacjach natywnych dla chmury, które eliminują konieczność śledzenia pracy. Istnieje kilka miejsc, w których doświadczenie jest lepsze niż w usłudze Azure DevOps, jeśli jednak musisz śledzić pracę.
Potoki CI/CD
Prawie żadna zmiana w cyklu rozwoju oprogramowania nie była tak rewolucyjna, jak pojawiło się ciągła integracja (CI) i ciągłe dostarczanie (CD). Kompilowanie i uruchamianie testów automatycznych względem kodu źródłowego projektu, jak tylko zmiana zostanie wprowadzona, pozwala wcześnie wychwycić błędy. Przed pojawieniem się procesów ciągłej integracji, nie było niczym wyjątkowym pobrać kod z repozytorium i stwierdzić, że nie przechodził testów lub że nie dało się go nawet skompilować. Doprowadziło to do zlokalizowania źródła awarii.
Tradycyjnie dostarczanie oprogramowania do środowiska produkcyjnego wymagało obszernej dokumentacji i listy kroków. Każdy z tych kroków należy wykonać ręcznie w procesie podatnym na błędy.

Rysunek 10–8 — lista kontrolna.
Siostra ciągłej integracji to ciągłe dostarczanie, w którym świeżo utworzone pakiety są wdrażane do środowiska. Proces ręczny nie może być skalowany w celu dopasowania do szybkości opracowywania, dzięki czemu automatyzacja staje się ważniejsza. Listy kontrolne są zastępowane przez skrypty, które mogą wykonywać te same zadania szybciej i dokładniej niż jakikolwiek człowiek.
Środowisko, do którego jest dostarczane w sposób ciągły, może być środowiskiem testowym lub, podobnie jak w przypadku wielu dużych firm technologicznych, może to być środowisko produkcyjne. Ten ostatni wymaga inwestycji w testy wysokiej jakości, które mogą dać pewność, że zmiana nie spowoduje przerwania produkcji dla użytkowników. W taki sam sposób, jak ciągła integracja wcześnie wychwytuje problemy w kodzie, ciągłe dostarczanie wcześnie wychwytuje problemy w procesie wdrażania.
Znaczenie automatyzacji procesu kompilowania i dostarczania jest akcentowane przez aplikacje natywne dla chmury. Wdrożenia odbywają się częściej i do większej liczby środowisk, więc ręczne wdrażanie jest prawie niemożliwe.
Kompilacje platformy Azure
Usługa Azure DevOps udostępnia zestaw narzędzi, które ułatwiają ciągłą integrację i ciągłe wdrażanie niż kiedykolwiek wcześniej. Te narzędzia znajdują się w obszarze Azure Pipelines. Pierwszą z nich jest usługa Azure Builds, która jest narzędziem do uruchamiania definicji kompilacji opartych na języku YAML na dużą skalę. Użytkownicy mogą korzystać z własnych maszyn kompilacji (jeśli kompilacja wymaga skrupulatnie skonfigurowanego środowiska) lub używać maszyny z stale odświeżonej puli maszyn wirtualnych hostowanych na platformie Azure. Agenci kompilacji działający w chmurze są wyposażeni w szeroką gamę narzędzi programistycznych nie tylko dla programowania w .NET, ale również od języka Java do Python aż po rozwój aplikacji na iPhone'y.
Metodyka DevOps zawiera szeroką gamę wbudowanych definicji kompilacji, które można dostosować dla dowolnej kompilacji. Definicje kompilacji są definiowane w pliku o nazwie azure-pipelines.yml i zaewidencjonowane w repozytorium, aby można je było wersjonować wraz z kodem źródłowym. Ułatwia to wprowadzanie zmian w potoku kompilacji w gałęzi, ponieważ zmiany można zaewidencjonować tylko w tej gałęzi. Przykład azure-pipelines.yml tworzenia aplikacji internetowej ASP.NET w pełnej strukturze przedstawiono na rysunku 10–9.
name: $(rev:r)
variables:
version: 9.2.0.$(Build.BuildNumber)
solution: Portals.sln
artifactName: drop
buildPlatform: any cpu
buildConfiguration: release
pool:
name: Hosted VisualStudio
demands:
- msbuild
- visualstudio
- vstest
steps:
- task: NuGetToolInstaller@0
displayName: 'Use NuGet 4.4.1'
inputs:
versionSpec: 4.4.1
- task: NuGetCommand@2
displayName: 'NuGet restore'
inputs:
restoreSolution: '$(solution)'
- task: VSBuild@1
displayName: 'Build solution'
inputs:
solution: '$(solution)'
msbuildArgs: '-p:DeployOnBuild=true -p:WebPublishMethod=Package -p:PackageAsSingleFile=true -p:SkipInvalidConfigurations=true -p:PackageLocation="$(build.artifactstagingdirectory)\\"'
platform: '$(buildPlatform)'
configuration: '$(buildConfiguration)'
- task: VSTest@2
displayName: 'Test Assemblies'
inputs:
testAssemblyVer2: |
**\$(buildConfiguration)\**\*test*.dll
!**\obj\**
!**\*testadapter.dll
platform: '$(buildPlatform)'
configuration: '$(buildConfiguration)'
- task: CopyFiles@2
displayName: 'Copy UI Test Files to: $(build.artifactstagingdirectory)'
inputs:
SourceFolder: UITests
TargetFolder: '$(build.artifactstagingdirectory)/uitests'
- task: PublishBuildArtifacts@1
displayName: 'Publish Artifact'
inputs:
PathtoPublish: '$(build.artifactstagingdirectory)'
ArtifactName: '$(artifactName)'
condition: succeededOrFailed()
Rysunek 10–9 — przykładowy azure-pipelines.yml
Ta definicja kompilacji używa wielu wbudowanych zadań, które sprawiają, że tworzenie kompilacji jest tak proste, jak tworzenie zestawu Lego (prostsze niż gigantyczny Millennium Falcon). Na przykład zadanie NuGet przywraca pakiety NuGet, podczas gdy zadanie VSBuild wywołuje narzędzia kompilacji programu Visual Studio w celu wykonania rzeczywistej kompilacji. W usłudze Azure DevOps są dostępne setki różnych zadań, a tysiące innych zadań jest obsługiwanych przez społeczność. Prawdopodobnie, niezależnie od tego, jakie zadania kompilacji chcesz uruchomić, ktoś już je opracował.
Kompilacje można wyzwalać ręcznie, za pomocą ewidencjonowania, harmonogramu lub ukończenia innej kompilacji. W większości przypadków pożądane jest utworzenie każdego zaewidencjonowania. Kompilacje można filtrować, aby różne kompilacje działały w różnych częściach repozytorium lub w różnych gałęziach. Pozwala to na scenariusze, takie jak uruchamianie szybkich kompilacji z ograniczonymi testami żądań ściągnięcia i uruchamianie pełnego zestawu regresji względem magistrali w nocy.
Wynikiem końcowym kompilacji jest kolekcja plików nazywanych artefaktami kompilacji. Te artefakty można przekazać do następnego kroku w procesie kompilacji lub dodać do źródła danych usługi Azure Artifacts, aby mogły być używane przez inne kompilacje.
Wydania usługi Azure DevOps
Kompilacje zajmują się przekształcaniem oprogramowania do pakietu gotowego do wysyłki, ale artefakty nadal muszą zostać przesłane do środowiska testowego, aby ukończyć proces ciągłego dostarczania. Do tego Azure DevOps używa osobnego narzędzia, które nazywa się Releases. Narzędzie do wydawania wersji korzysta z tej samej biblioteki zadań, które były dostępne w kompilacji, ale wprowadza koncepcję "etapów". Etap to izolowane środowisko, w którym jest instalowany pakiet. Na przykład produkt może korzystać z programowania, kontroli jakości i środowiska produkcyjnego. Kod jest stale dostarczany do środowiska deweloperskiego, w którym można uruchamiać testy automatyczne. Po przejściu tych testów wydanie zostanie przeniesione do środowiska QA na potrzeby testowania ręcznego. Na koniec kod jest wypychany do środowiska produkcyjnego, gdzie jest widoczny dla wszystkich.

Rysunek 10–10 — potok wydania
Każdy etap kompilacji może zostać automatycznie wyzwolony przez ukończenie poprzedniej fazy. Jednak w wielu przypadkach nie jest to pożądane. Przeniesienie kodu do środowiska produkcyjnego może wymagać zatwierdzenia od kogoś. Narzędzie wspomaga to, zezwalając osobom zatwierdzającym na każdym etapie potoku wydawniczego. Reguły można skonfigurować tak, aby określona osoba lub grupa osób musiała wyrazić zgodę na wydanie, zanim zostanie wdrożone do produkcji. Bramy te umożliwiają ręczne kontrole jakości, a także zgodność z wszelkimi wymaganiami prawnymi związanymi z kontrolą tego, co wchodzi w produkcję.
Każdy otrzymuje potok kompilacji
Konfigurowanie wielu potoków kompilacji nie jest kosztowne, dlatego korzystne jest posiadanie co najmniej jednego potoku kompilacji na mikrousługę. W idealnym przypadku mikrousługi są niezależnie wdrążane w dowolnym środowisku, dzięki czemu każdy z nich może być wydany za pośrednictwem własnego potoku, bez konieczności uwalniania zbędnego kodu, co jest doskonałym rozwiązaniem. Każdy pipeline może mieć własny zestaw zatwierdzeń, pozwalającą na zmianę procesu kompilacji dla każdej usługi.
Wydania wersji
Jedną wadą korzystania z funkcji wydania jest to, że nie można jej zdefiniować w zaewidencjonowanym pliku azure-pipelines.yml. Istnieje wiele powodów, dla których warto to zrobić, począwszy od posiadania definicji wydań dla poszczególnych gałęzi, a skończywszy na włączeniu szkieletu wydania w szablon projektu. Na szczęście trwają prace nad przeniesieniem obsługi niektórych etapów do składnika Kompilacja. Będzie to znane jako kompilacja wieloetapowa, a pierwsza wersja jest teraz dostępna!
Współpracuj z nami na GitHub
Źródło tej treści można znaleźć na GitHubie, gdzie można także tworzyć i przeglądać problemy oraz pull requesty. Więcej informacji znajdziesz w naszym przewodniku dla współautorów.