Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Wskazówka
Ta zawartość jest fragmentem e-książki, Architektura Cloud Native .NET Applications for Azure, dostępnej w .NET Docs lub jako bezpłatny plik PDF do pobrania, który można czytać offline.

Podobnie jak wzorce zostały opracowane w celu pomocy w układzie kodu w aplikacjach, istnieją wzorce dla aplikacji operacyjnych w niezawodny sposób. Pojawiły się trzy przydatne wzorce obsługi aplikacji: rejestrowanie, monitorowanie i alerty.
Kiedy należy używać logowania
Bez względu na to, jak jesteśmy ostrożni, aplikacje prawie zawsze zachowują się w nieoczekiwany sposób w środowisku produkcyjnym. Gdy użytkownicy zgłaszają problemy z aplikacją, warto zobaczyć, co się dzieje z aplikacją po wystąpieniu problemu. Jednym z najbardziej wypróbowanych i prawdziwych sposobów przechwytywania informacji o tym, co robi aplikacja podczas jej działania, jest zapisanie aplikacji, co robi. Ten proces jest nazywany rejestrowaniem. Za każdym razem, gdy wystąpią awarie lub problemy w środowisku produkcyjnym, należy odtworzyć warunki, w których wystąpiły awarie w środowisku nieprodukcyjnym. Dobre logowanie stanowi instrukcję postępowania dla deweloperów, którą należy wykonać, aby zduplikować problemy w środowisku, w którym można przeprowadzać testy i eksperymenty.
Wyzwania związane z rejestrowaniem za pomocą aplikacji natywnych dla chmury
W tradycyjnych aplikacjach pliki dziennika są zwykle przechowywane na komputerze lokalnym. W rzeczywistości w systemach operacyjnych podobnych do unix istnieje struktura folderów zdefiniowana do przechowywania wszystkich dzienników, zwykle w obszarze /var/log.
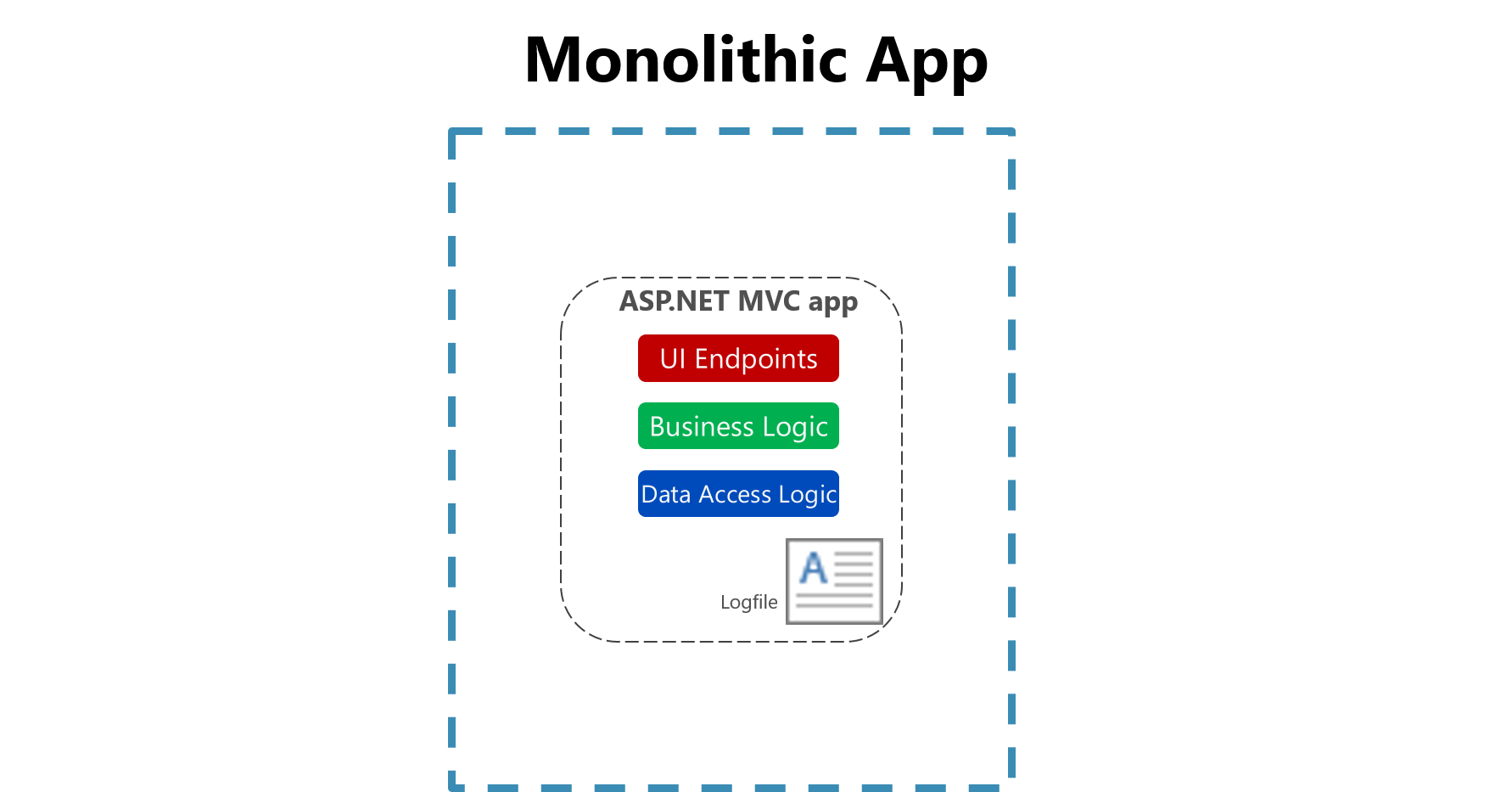 Rysunek 7–1. Rejestrowanie do pliku w aplikacji monolitycznej.
Rysunek 7–1. Rejestrowanie do pliku w aplikacji monolitycznej.
Użyteczność logowania do pliku płaskiego na jednej maszynie jest znacznie zmniejszona w środowisku chmurowym. Aplikacje produkujące dzienniki mogą nie mieć dostępu do dysku lokalnego lub dysk lokalny może być bardzo przejściowy, ponieważ kontenery są przetasowane wokół maszyn fizycznych. Nawet proste zwiększanie skali aplikacji monolitycznych w wielu węzłach może utrudnić zlokalizowanie odpowiednich plików dziennika opartych na plikach.
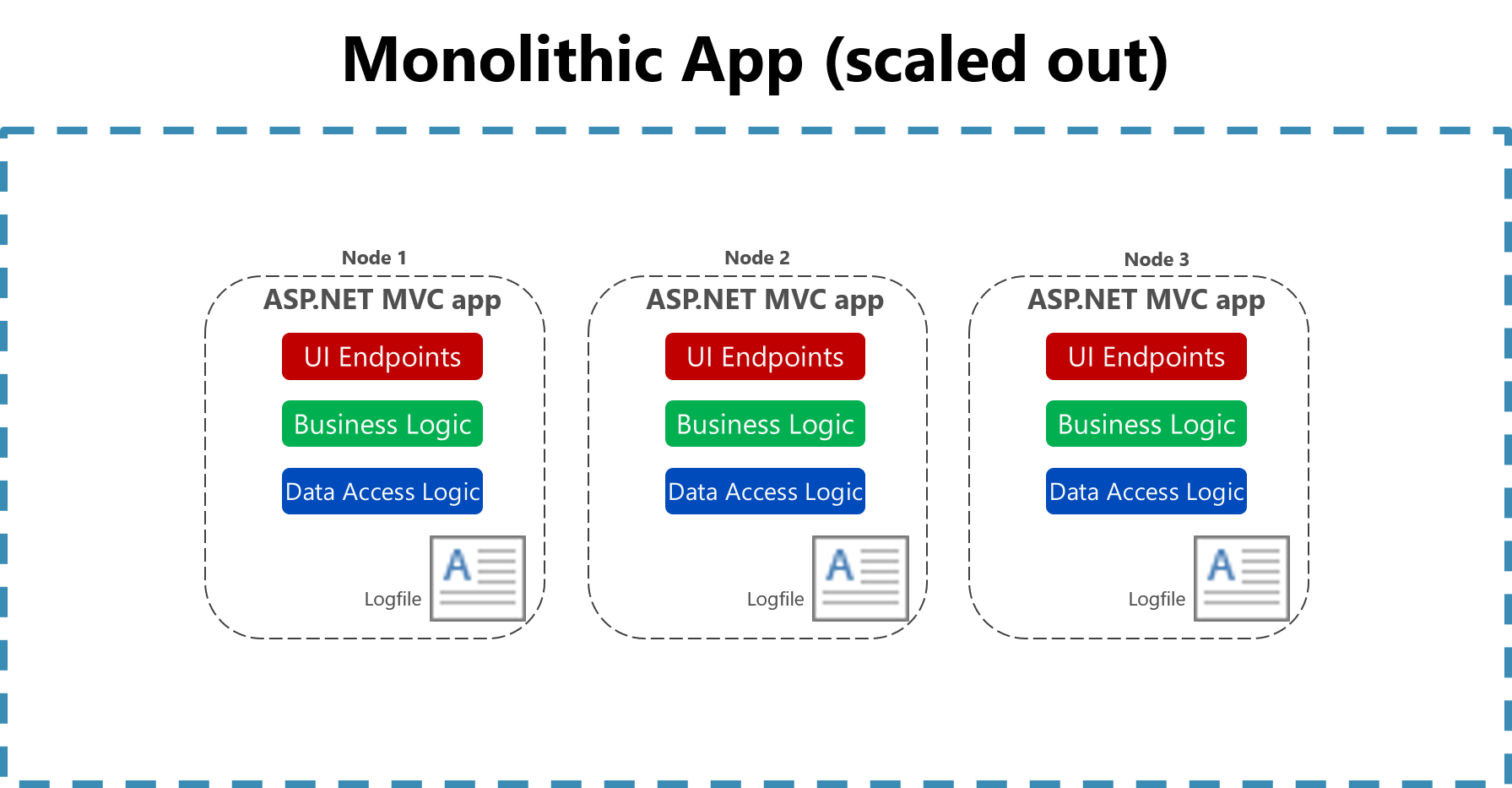 Rysunek 7–2. Rejestrowanie plików w skalowanej aplikacji monolitycznej.
Rysunek 7–2. Rejestrowanie plików w skalowanej aplikacji monolitycznej.
Aplikacje natywne dla chmury opracowane przy użyciu architektury mikrousług stanowią również pewne wyzwania dla rejestratorów opartych na plikach. Żądania użytkowników mogą teraz obejmować wiele usług, które są uruchamiane na różnych maszynach i mogą obejmować funkcje bezserwerowe bez dostępu do lokalnego systemu plików w ogóle. Bardzo trudne byłoby skorelowanie dzienników z użytkownika lub sesji między tymi wieloma usługami i maszynami.
 Rysunek 7–3. Logowanie do lokalnych plików w aplikacji mikrousług.
Rysunek 7–3. Logowanie do lokalnych plików w aplikacji mikrousług.
Na koniec liczba użytkowników w niektórych aplikacjach natywnych dla chmury jest wysoka. Załóżmy, że każdy użytkownik generuje setki wierszy komunikatów dziennika podczas logowania się do aplikacji. W izolacji jest to możliwe do zarządzania, ale gdy liczba użytkowników przekracza 100,000, ilość dzienników staje się na tyle duża, że potrzebne są wyspecjalizowane narzędzia do efektywnego korzystania z nich.
Rejestrowanie w aplikacjach natywnych dla chmury
Każdy język programowania ma narzędzia, które zezwalają na pisanie dzienników i zazwyczaj obciążenie związane z pisaniem tych dzienników jest niskie. Wiele bibliotek rejestrowania umożliwia logowanie różnych poziomów ważności, które można dostosować w trakcie działania. Na przykład biblioteka Serilog jest popularną biblioteką rejestrowania strukturalnego dla platformy .NET, która zapewnia następujące poziomy rejestrowania:
- Pełne informacje
- Debugowanie
- Informacja
- Ostrzeżenie
- Błąd
- Śmiertelny
Te różne poziomy dzienników zapewniają stopień szczegółowości rejestrowania. Gdy aplikacja działa prawidłowo w środowisku produkcyjnym, może być skonfigurowana tak, aby rejestrowała tylko ważne komunikaty. Gdy aplikacja działa nieprawidłowo, można zwiększyć poziom dziennika, aby zebrać więcej szczegółowych danych. Równoważy to wydajność w stosunku do łatwości debugowania.
Wysoka wydajność narzędzi rejestrowania i możliwość dostosowania szczegółowości powinna zachęcić deweloperów do częstego rejestrowania. Wiele osób preferuje sposób rejestrowania wejścia i wyjścia każdej metody. Takie podejście może brzmieć jak przesada, ale rzadko zdarza się, by programiści chcieli mniej rejestrowania zdarzeń. W rzeczywistości często przeprowadza się wdrożenia wyłącznie po to, aby dodać rejestrowanie wokół problematycznej metody. Wybieraj raczej zbyt dużą ilość rejestrowania niż zbyt małą. Niektóre narzędzia mogą być używane do automatycznego rejestrowania tego rodzaju danych.
Ze względu na wyzwania związane z używaniem dzienników opartych na plikach w aplikacjach natywnych dla chmury preferowane są scentralizowane dzienniki. Dzienniki są zbierane przez aplikacje i wysyłane do centralnej aplikacji rejestrowania, która indeksuje i przechowuje dzienniki. Ta klasa systemu może pozyskiwać dziesiątki gigabajtów dzienników każdego dnia.
Warto również przestrzegać niektórych standardowych praktyk podczas tworzenia logowania obejmującego wiele usług. Na przykład wygenerowanie identyfikatora korelacji na początku długiej interakcji, a następnie zalogowanie go w każdym komunikacie powiązanym z tym interakcją ułatwia wyszukiwanie wszystkich powiązanych komunikatów. Wystarczy znaleźć tylko jeden komunikat i wyodrębnić identyfikator korelacji, aby znaleźć wszystkie powiązane komunikaty. Innym przykładem jest zapewnienie, że format dziennika jest taki sam dla każdej usługi, niezależnie od języka lub biblioteki rejestrowania, która jest używana. Ta standaryzacja znacznie ułatwia odczytywanie dzienników. Rysunek 7–4 pokazuje, jak architektura mikrousług może korzystać ze scentralizowanego rejestrowania w ramach przepływu pracy.
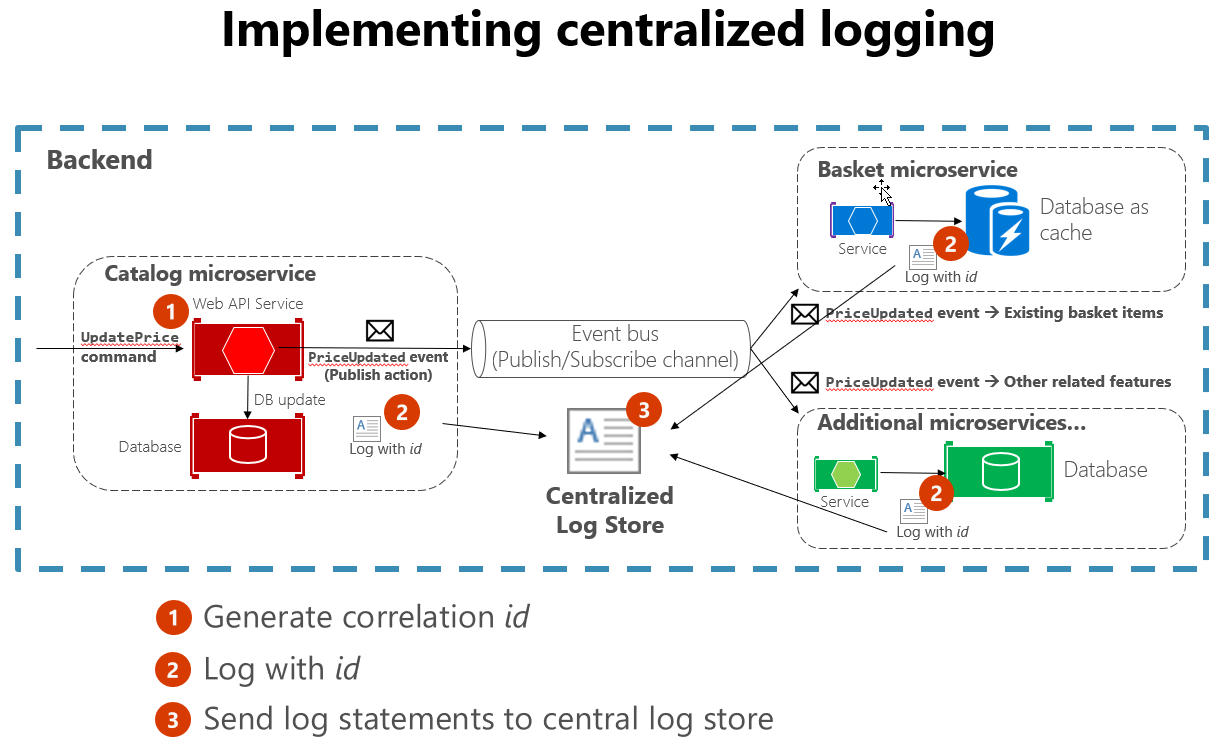 Rysunek 7–4. Dzienniki z różnych źródeł są przesyłane do scentralizowanego magazynu dzienników.
Rysunek 7–4. Dzienniki z różnych źródeł są przesyłane do scentralizowanego magazynu dzienników.
Wyzwania związane z wykrywaniem potencjalnych problemów z kondycją aplikacji i reagowaniem na nie
Niektóre aplikacje nie są kluczowe dla realizacji misji. Być może są one używane tylko wewnętrznie, a gdy wystąpi problem, użytkownik może skontaktować się z zespołem odpowiedzialnym i aplikację można ponownie uruchomić. Jednak klienci często mają wyższe oczekiwania dotyczące używanych aplikacji. Należy wiedzieć, kiedy występują problemy z aplikacją przed wykonaniem czynności przez użytkowników lub przed powiadomieniem użytkownika. W przeciwnym razie pierwszym sygnałem o problemie może być gniewny zalew postów w mediach społecznościowych wyśmiewających Twoją aplikację lub nawet Twoją organizację.
Niektóre scenariusze, które można rozważyć, to:
- Jedna usługa w aplikacji stale kończy się niepowodzeniem i ponownym uruchamianiem, co powoduje sporadyczne powolne odpowiedzi.
- W niektórych porach dnia czas odpowiedzi aplikacji jest powolny.
- Po ostatnim wdrożeniu obciążenie bazy danych potroiło się.
Zaimplementowane prawidłowo, monitorowanie może poinformować Cię o warunkach, które będą prowadzić do problemów, umożliwiając rozwiązywanie podstawowych warunków, zanim spowodują one znaczący wpływ na użytkownika.
Monitorowanie aplikacji natywnych dla chmury
Niektóre scentralizowane systemy rejestrowania pełnią dodatkową rolę zbierania danych telemetrycznych poza czystymi dziennikami. Mogą zbierać metryki, takie jak czas uruchamiania zapytania bazy danych, średni czas odpowiedzi z serwera internetowego, a nawet średnie obciążenie procesora CPU i ciśnienie pamięci zgłoszone przez system operacyjny. W połączeniu z dziennikami te systemy mogą zapewnić całościowy widok kondycji węzłów w systemie i aplikacji jako całości.
Możliwości zbierania metryk narzędzi do monitorowania mogą być również przekazywane ręcznie z poziomu aplikacji. Przepływy biznesowe, które są szczególnie interesujące, takie jak zarejestrowanie się nowych użytkowników lub złożone zamówienia, mogą być instrumentowane w taki sposób, aby zwiększały licznik w centralnym systemie monitorowania. Ten aspekt odblokowuje narzędzia, które pozwalają monitorować nie tylko kondycję aplikacji, ale również kondycję firmy.
Zapytania można tworzyć w narzędziach agregacji dzienników, aby wyszukać pewne statystyki lub wzorce, które następnie mogą być wyświetlane w formie graficznej na niestandardowych pulpitach nawigacyjnych. Często zespoły inwestują w duże, montowane na ścianie wyświetlacze, które obracają się przez statystyki związane z aplikacją. W ten sposób łatwo jest zobaczyć problemy w miarę ich występowania.
Natywne dla chmury narzędzia do monitorowania zapewniają dane telemetryczne w czasie rzeczywistym i wgląd w aplikacje niezależnie od tego, czy są to aplikacje monolityczne jednoprocesowe, czy rozproszone architektury mikrousług. Obejmują one narzędzia, które umożliwiają zbieranie danych z aplikacji, a także narzędzia do wykonywania zapytań i wyświetlania informacji o kondycji aplikacji.
Wyzwania związane z reagowaniem na krytyczne problemy w aplikacjach natywnych dla chmury
Jeśli musisz reagować na problemy z aplikacją, musisz w jakiś sposób zaalarmować odpowiedni personel. Jest to trzeci wzorzec obserwacji aplikacji natywnej dla chmury i zależy od rejestrowania i monitorowania. Aplikacja musi mieć prowadzenie logów, aby pomóc w diagnozowaniu problemów, a w niektórych przypadkach logi mogą być używane w narzędziach do monitorowania. Wymaga monitorowania w celu agregowania metryk aplikacji i danych kondycji w jednym miejscu. Po ustanowieniu tej metody można utworzyć reguły, które będą wyzwalać alerty, gdy niektóre metryki spadną poza akceptowalne poziomy.
Ogólnie rzecz biorąc, alerty są nakładane na warstwy monitorowania, tak aby niektóre warunki wyzwalały odpowiednie alerty w celu powiadamiania członków zespołu o pilnych problemach. Niektóre scenariusze, które mogą wymagać alertów, obejmują:
- Jedna z usług aplikacji nie odpowiada po upływie 1 minuty przestoju.
- Aplikacja zwraca nieudane odpowiedzi HTTP dla ponad 1% żądań.
- Średni czas odpowiedzi aplikacji dla kluczowych punktów końcowych przekracza 2000 ms.
Alerty w aplikacjach natywnych dla chmury
Zapytania można tworzyć względem narzędzi do monitorowania, aby wyszukać znane warunki awarii. Na przykład zapytania mogą przeszukiwać dzienniki przychodzące pod kątem wskazania kodu stanu HTTP 500, co oznacza problem na serwerze internetowym. Po wykryciu jednego z nich można wysłać wiadomość e-mail lub sms do właściciela usługi źródłowej, który może rozpocząć badanie.
Zazwyczaj jednak pojedynczy błąd 500 nie wystarczy, aby ustalić, że wystąpił problem. Może to oznaczać, że użytkownik błędnie wpisał swoje hasło lub wprowadził źle sformułowane dane. Zapytania alertów mogą być skonstruowane tak, aby uruchamiały się tylko wtedy, gdy zostanie wykryta większa niż średnia liczba błędów 500.
Jednym z najbardziej szkodliwych wzorców w zgłaszaniu alertów jest wyzwolenie zbyt wielu alertów, które muszą zostać zbadane przez ludzi. Właściciele usług szybko staną się niewrażliwi na błędy, które zostały wcześniej zbadane i okazały się łagodne. Następnie, gdy wystąpią prawdziwe błędy, zostaną one utracone w szumie setek wyników fałszywie dodatnich. Przypowieść o chłopcu, który wołał wilka jest często opowiadana dzieciom, aby ostrzec ich przed tym zagrożeniem. Ważne jest, aby upewnić się, że alerty, które są uruchamiane, wskazują na rzeczywisty problem.
Współpracuj z nami na GitHub
Źródło tej treści można znaleźć na GitHubie, gdzie można także tworzyć i przeglądać problemy oraz pull requesty. Więcej informacji znajdziesz w naszym przewodniku dla współautorów.