Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dowiedz się, jak używać ML.NET do wykrywania obiektów na obrazach przy użyciu modelu ONNX wytrenowanego w usłudze Microsoft Custom Vision.
Usługa Microsoft Custom Vision to usługa sztucznej inteligencji, która trenuje model na podstawie przekazanych obrazów. Następnie możesz wyeksportować model do formatu ONNX i użyć go w ML.NET w celu przewidywania.
W tym poradniku nauczysz się, jak:
- Tworzenie modelu ONNX przy użyciu usługi Custom Vision
- Dołączanie modelu ONNX do potoku ML.NET
- Trenowanie modelu ML.NET
- Wykrywanie logowań zatrzymania na obrazach testowych
Wymagania wstępne
- Program Visual Studio 2022 lub nowszy.
- Pobierz zestaw danych z 50 obrazów znaków Stop.
- Konto platformy Azure. Jeśli go nie masz, utwórz bezpłatne konto platformy Azure.
Tworzenie modelu
Tworzenie projektu usługi Custom Vision
Zaloguj się do usługi Microsoft Custom Vision i wybierz pozycję Nowy projekt.
W oknie dialogowym Nowy projekt wypełnij następujące wymagane elementy:
- Ustaw nazwę projektu Custom Vision jako StopSignDetection.
- Wybierz zasób , którego będziesz używać. Jest to zasób platformy Azure, który zostanie utworzony dla projektu usługi Custom Vision. Jeśli żadna z nich nie jest wyświetlana, można ją utworzyć, wybierając link Utwórz nowy .
- Ustaw typ projektu jako Wykrywanie obiektu.
- Ustaw typy klasyfikacji jako Multiklasy, ponieważ na każdy obraz przypada jedna klasa.
- Ustaw wartość Domena jako Ogólne (kompaktowa) [S1]. Domena kompaktowa umożliwia pobranie modelu ONNX.
- W obszarze Możliwości eksportu wybierz pozycję Podstawowe platformy , aby zezwolić na eksportowanie modelu ONNX.
Po wypełnieniu powyższych pól wybierz pozycję Utwórz projekt.
Dodawanie obrazów
- Po utworzeniu projektu wybierz pozycję Dodaj obrazy , aby rozpocząć dodawanie obrazów dla modelu do trenowania. Wybierz obrazy znaków stop, które pobrałeś.
- Wybierz pierwszy wyświetlony obraz. Możesz wybrać obiekty na obrazie, który ma zostać wykryty przez model. Wybierz pozycję Zatrzymaj logowanie na obrazie. Pojawia się okno podręczne i tag jest ustawiany jako stop-sign.
- Powtórz dla wszystkich pozostałych obrazów. Niektóre obrazy mają więcej niż jeden znak stop, dlatego pamiętaj, aby oznaczyć wszystkie, które są widoczne na obrazach.
Trenowanie modelu
Po przekazaniu i oznakowaniu obrazów można teraz wytrenować model. Wybierz pozycję Trenuj.
Zostanie wyświetlone okno podręczne z pytaniem, jakiego typu szkolenie użyć. Wybierz pozycję Szybkie szkolenie , a następnie wybierz pozycję Trenuj.
Pobieranie modelu ONNX
Po zakończeniu trenowania kliknij przycisk Eksportuj . Po wyświetleniu wyskakującego okienka wybierz pozycję ONNX , aby pobrać model ONNX.
Sprawdzanie modelu ONNX
Rozpakuj pobrany plik ONNX. Folder zawiera kilka plików, ale te dwa, których będziesz używać w tym samouczku, to:
- labels.txt, który jest plikiem tekstowym zawierającym etykiety zdefiniowane w usłudze Custom Vision.
- model.onnx, który jest modelem ONNX, którego użyjesz do tworzenia przewidywań w ML.NET.
Aby zbudować pipeline ML.NET, potrzebne będą nazwy kolumn wejściowych i wyjściowych. Aby uzyskać te informacje, użyj platformy Netron, aplikacji internetowej i klasycznej , która może analizować modele ONNX i wyświetlać ich architekturę.
Kiedy korzystasz z aplikacji internetowej lub klasycznej Netron, otwórz model ONNX w tej aplikacji. Po jego otworzie zostanie wyświetlony graf. Ten wykres dostarcza kilku informacji niezbędnych do zbudowania potoku ML.NET na potrzeby przewidywań.
Nazwa kolumny wejściowej — nazwa kolumny wejściowej wymagana podczas stosowania modelu ONNX w ML.NET.
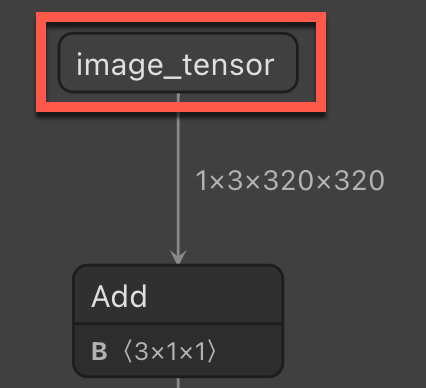
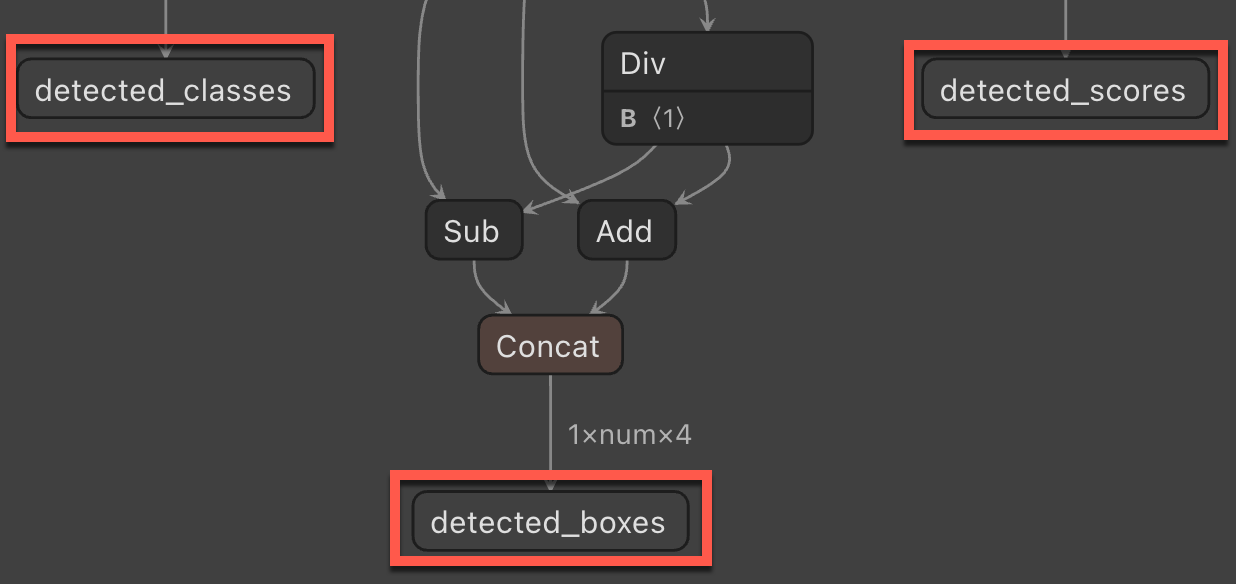
Nazwa kolumny wyjściowej — nazwa kolumny wyjściowej wymagana podczas stosowania modelu ONNX w ML.NET.
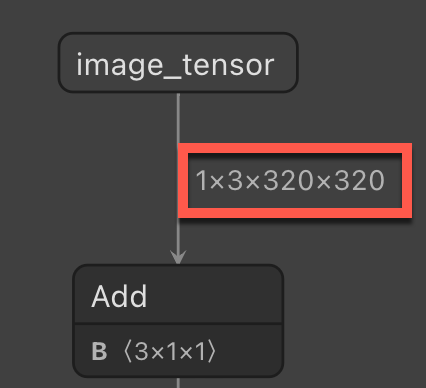
Rozmiar obrazu — rozmiar wymagany podczas zmiany rozmiaru obrazów w potoku ML.NET.
Tworzenie projektu konsoli języka C#
W programie Visual Studio utwórz aplikację konsolową języka C# o nazwie "StopSignDetection". Wybierz platformę .NET 8 jako platformę docelową.
Zainstaluj następujące pakiety NuGet dla projektu:
- Microsoft.ML
- Microsoft.ML.ImageAnalytics
- Microsoft.Onnx.Transformer
Uwaga / Notatka
W tym przykładzie użyto najnowszej stabilnej wersji pakietów NuGet wymienionych, chyba że określono inaczej.
Odwołanie do modelu ONNX
Znajdź dwa pliki z modelu ONNX (labels.txt i model.onnx) w Eksploratorze rozwiązań programu Visual Studio. Kliknij je prawym przyciskiem myszy i w oknie Właściwości ustaw opcję Kopiuj na katalog wyjściowy na Kopiuj, jeśli jest nowszy.
Tworzenie klas danych wejściowych i przewidywania
Dodaj nową klasę do projektu i nadaj jej
StopSignInputnazwę . Następnie dodaj następującą strukturę do klasy:public struct ImageSettings { public const int imageHeight = 320; public const int imageWidth = 320; }Następnie dodaj następującą właściwość do klasy.
public class StopSignInput { [ImageType(ImageSettings.imageHeight, ImageSettings.imageWidth)] public Bitmap Image { get; set; } }Właściwość
Imagezawiera mapę bitową obrazu używanego do przewidywania. AtrybutImageTypeinformuje ML.NET, że właściwość jest obrazem o wymiarach 320 na 320, co zostało określone przy użyciu Netron.Dodaj kolejną klasę do projektu i nadaj jej
StopSignPredictionnazwę . Następnie dodaj następujące właściwości do klasy .public class StopSignPrediction { [ColumnName("detected_classes")] public long[] PredictedLabels { get; set; } [ColumnName("detected_boxes")] public float[] BoundingBoxes { get; set; } [ColumnName("detected_scores")] public float[] Scores { get; set; } }Właściwość
PredictedLabelszawiera przewidywania etykiet dla każdego wykrytego obiektu. Typ jest tablicą zmiennoprzecinkową, więc każdy element w tablicy jest przewidywaniem każdej etykiety. AtrybutColumnNameinformuje ML.NET, że ta kolumna w modelu jest nazwą podaną, czylidetected_classes.Właściwość
BoundingBoxeszawiera pola ograniczenia dla każdego wykrytego obiektu. Typ jest tablicą zmiennoprzecinkową, a każdy wykryty obiekt zawiera cztery elementy w tablicy dla pola ograniczenia. AtrybutColumnNameinformuje ML.NET, że ta kolumna w modelu jest nazwą podaną, czylidetected_boxes.Właściwość
Scoreszawiera współczynniki ufności każdego przewidywanego obiektu i jego etykietę. Typ jest tablicą zmiennoprzecinkową, więc każdy element tablicy to stopień zaufania dla każdej etykiety. AtrybutColumnNameinformuje ML.NET, że ta kolumna w modelu jest nazwą podaną, czylidetected_scores.
Korzystanie z modelu do przewidywania
Dodaj dyrektywy using
W pliku Program.cs dodaj następujące using dyrektywy na początku pliku.
using Microsoft.ML;
using Microsoft.ML.Transforms.Image;
using System.Drawing;
using WeatherRecognition;
Utwórz obiekty
MLContextUtwórz obiekt.var context = new MLContext();Utwórz obiekt
IDataViewz nową pustąStopSignInputlistą.var data = context.Data.LoadFromEnumerable(new List<StopSignInput>());Aby uzyskać spójność, zapisz przewidywane obrazy w ścieżce zestawu.
var root = new FileInfo(typeof(Program).Assembly.Location); var assemblyFolderPath = root.Directory.FullName;
Kompilowanie potoku
Po utworzeniu pustego IDataView potok można skompilować w celu wykonania przewidywań wszystkich nowych obrazów. Pipeline składa się z kilku etapów:
Zmień rozmiar obrazów przychodzących.
Obraz wysyłany do modelu na potrzeby przewidywania często będzie miał inny współczynnik proporcji do obrazów, które zostały wytrenowane w modelu. Aby zachować spójność obrazu pod kątem dokładnych przewidywań, zmień rozmiar obrazu na 320x320. W tym celu należy użyć
ResizeImagesmetody i ustawićimageColumnNamejako nazwęStopSignInput.Imagewłaściwości.var pipeline = context.Transforms.ResizeImages(resizing: ImageResizingEstimator.ResizingKind.Fill, outputColumnName: "image_tensor", imageWidth: ImageSettings.imageWidth, imageHeight: ImageSettings.imageHeight, inputColumnName: nameof(StopSignInput.Image))Wyodrębnij piksele obrazu.
Po zmianie rozmiaru obrazu należy wyodrębnić piksele obrazu. Dołącz metodę
ExtractPixelsdo potoku i określ nazwę kolumny w celu wyprowadzenia pikseli do użycia parametruoutputColumnName..Append(context.Transforms.ExtractPixels(outputColumnName: "image_tensor"))Zastosuj model ONNX do obrazu, aby utworzyć przewidywanie. Przyjmuje to kilka parametrów:
- modelFile — ścieżka do pliku modelu ONNX
- outputColumnNames — tablica ciągów zawierająca nazwy wszystkich nazw kolumn wyjściowych, które można znaleźć podczas analizowania modelu ONNX w netron.
- inputColumnNames — tablica ciągów zawierająca nazwy wszystkich nazw kolumn wejściowych, które można również znaleźć podczas analizowania modelu ONNX w netron.
.Append(context.Transforms.ApplyOnnxModel(outputColumnNames: new string[] { "detected_boxes", "detected_scores", "detected_classes" }, inputColumnNames: new string[] { "image_tensor" }, modelFile: "./Model/model.onnx"));
Dopasuj model
Po zdefiniowaniu pipe'a możesz go użyć do utworzenia modelu ML.NET.
Fit Użyj metody w potoku i przekaż pusty IDataViewelement .
var model = pipeline.Fit(data);
Następnie, aby utworzyć aparat przewidywania, użyj modelu do utworzenia aparatu przewidywania. Jest to metoda ogólna, więc przyjmuje klasy StopSignInput i StopSignPrediction, które zostały utworzone wcześniej.
var predictionEngine = context.Model.CreatePredictionEngine<StopSignInput, StopSignPrediction>(model);
Wyodrębnij etykiety
Aby przyporządkować dane wyjściowe modelu do jego etykiet, należy wyodrębnić etykiety dostarczone przez Custom Vision. Etykiety te znajdują się w pliku labels.txt , który został uwzględniony w pliku zip z modelem ONNX.
Wywołaj metodę , ReadAllLines aby odczytać wszystkie etykiety w pliku.
var labels = File.ReadAllLines("./model/labels.txt");
Przewiduj na obrazie testowym
Teraz możesz użyć modelu do przewidywania nowych obrazów. W projekcie znajduje się folder testowy , którego można użyć do przewidywania. Ten folder zawiera dwa losowe obrazy ze znakiem stop z Unsplash. Jeden obraz ma jeden znak zatrzymania, podczas gdy drugi ma dwa znaki zatrzymania.
GetFiles Użyj metody , aby odczytać ścieżki plików obrazów w katalogu.
var testFiles = Directory.GetFiles("./test");
Przeprowadź pętlę przez ścieżki plików, aby utworzyć przewidywanie za pomocą modelu i wyświetlić wynik.
Utwórz pętlę
foreachdo pętli za pośrednictwem obrazów testowych.Bitmap testImage; foreach (var image in testFiles) { }foreachW pętli wygeneruj nazwę przewidywanego obrazu na podstawie nazwy oryginalnego obrazu testowego.var predictedImage = $"{Path.GetFileName(image)}-predicted.jpg";Ponadto w
foreachpętli utwórzFileStreamobraz i przekonwertuj go naBitmap.using (var stream = new FileStream(image, FileMode.Open)) { testImage = (Bitmap)Image.FromStream(stream); }Również w pętli wywołaj
foreachmetodęPredictw aucie przewidywania.var prediction = predictionEngine.Predict(new StopSignInput { Image = testImage });Za pomocą predykcji można uzyskać ramki ograniczające. Chunk Użyj metody , aby określić liczbę obiektów wykrytych przez model. Zrób to, biorąc pod uwagę liczbę przewidywanych ramek ograniczających i dzieląc ją przez liczbę przewidywanych etykiet. Jeśli na przykład na obrazie wykryto trzy obiekty, w
BoundingBoxestablicy będzie przewidywanych 12 elementów i trzy etykiety.ChunkNastępnie metoda daje trzy tablice z czterech do reprezentowania pól ograniczenia dla każdego obiektu.var boundingBoxes = prediction.BoundingBoxes.Chunk(prediction.BoundingBoxes.Count() / prediction.PredictedLabels.Count());Następnie przechwyć oryginalną szerokość i wysokość obrazów używanych do przewidywania.
var originalWidth = testImage.Width; var originalHeight = testImage.Height;Oblicz, gdzie na obrazie należy narysować prostokąty. W tym celu utwórz pętlę
forna podstawie liczby fragmentów pól ograniczenia.for (int i = 0; i < boundingBoxes.Count(); i++) { }forW pętli oblicz położenie współrzędnych x i y, a także szerokość i wysokość pola do narysowania na obrazie. Pierwszą rzeczą, którą należy wykonać, jest pobranie zestawu pól ograniczenia przy użyciuElementAtmetody .var boundingBox = boundingBoxes.ElementAt(i);Za pomocą bieżącej ramki ograniczającej można teraz obliczyć miejsce, gdzie narysować pole. Użyj oryginalnej szerokości obrazu dla pierwszych i trzecich elementów pola ograniczenia oraz oryginalnej wysokości obrazu dla drugich i czwartych elementów.
var left = boundingBox[0] * originalWidth; var top = boundingBox[1] * originalHeight; var right = boundingBox[2] * originalWidth; var bottom = boundingBox[3] * originalHeight;Oblicz szerokość i wysokość pola, aby rysować wokół wykrytego obiektu na obrazie. Elementy x i y są zmiennymi
leftitopz poprzednich obliczeń.Math.AbsUżyj metody , aby uzyskać wartość bezwzględną z obliczeń szerokości i wysokości, jeśli jest ujemna.var x = left; var y = top; var width = Math.Abs(right - left); var height = Math.Abs(top - bottom);Następnie pobierz przewidywaną etykietę z tablicy etykiet.
var label = labels[prediction.PredictedLabels[i]];Utwórz grafikę opartą na obrazie testowym
Graphics.FromImageprzy użyciu metody .using var graphics = Graphics.FromImage(testImage);Rysuj na obrazie przy użyciu informacji o polu ograniczenia. Najpierw narysuj prostokąt wokół wykrytych obiektów przy użyciu metody
DrawRectangle, która przyjmuje obiektPenw celu określenia koloru i szerokości prostokąta, a następnie przekaż zmiennex,y,widthiheight.graphics.DrawRectangle(new Pen(Color.NavajoWhite, 8), x, y, width, height);Następnie wyświetl przewidywaną etykietę wewnątrz pola za pomocą metody
DrawString, która pobiera ciąg do wyświetlenia i obiektFont, aby określić, jak narysować etykietę i gdzie ją umieścić.graphics.DrawString(label, new Font(FontFamily.Families[0], 18f), Brushes.NavajoWhite, x + 5, y + 5);forPo pętli sprawdź, czy przewidywany plik już istnieje. Jeśli tak, usuń go. Następnie zapisz go w zdefiniowanej ścieżce wyjściowej.if (File.Exists(predictedImage)) { File.Delete(predictedImage); } testImage.Save(Path.Combine(assemblyFolderPath, predictedImage));
Dalsze kroki
Wypróbuj jeden z innych samouczków dotyczących klasyfikacji obrazów:
Współpracuj z nami na GitHub
Źródło tej treści można znaleźć na GitHubie, gdzie można także tworzyć i przeglądać problemy oraz pull requesty. Więcej informacji znajdziesz w naszym przewodniku dla współautorów.