Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Działanie usługi Azure Databricks w usłudze Data Factory dla usługi Microsoft Fabric umożliwia organizowanie następujących zadań usługi Azure Databricks:
- Notatnik
- Słoik
- Python
- Job
Ten artykuł zawiera szczegółowy przewodnik opisujący sposób tworzenia działania usługi Azure Databricks przy użyciu interfejsu usługi Data Factory.
Wymagania wstępne
Aby rozpocząć pracę, należy spełnić następujące wymagania wstępne:
- Konto najemcy z aktywną subskrypcją. Utwórz konto bezpłatnie.
- Zostanie utworzony obszar roboczy.
Konfigurowanie działania usługi Azure Databricks
Aby użyć działania usługi Azure Databricks w potoku, wykonaj następujące kroki:
Konfigurowanie połączenia
Utwórz nowy rurociąg w środowisku pracy.
Wybierz Dodaj działanie potoku i wyszukaj Azure Databricks.

Alternatywnie możesz wyszukać usługę Azure Databricks w okienku Działania potoku i wybrać ją, aby dodać ją do kanwy potoku.

Wybierz nowe działanie usługi Azure Databricks na kanwie, jeśli nie zostało jeszcze wybrane.

Zapoznaj się ze wskazówkami dotyczącymi ustawień ogólnych, aby skonfigurować kartę Ustawienia ogólne.
Konfigurowanie klastrów
Wybierz kartę Klaster. Następnie możesz wybrać istniejące lub utworzyć nowe połączenie usługi Azure Databricks, a następnie wybrać nowy klaster zadań, istniejący klaster interaktywny lub istniejącą pulę wystąpień.
W zależności od wybranego klastra wypełnij odpowiednie pola, jak pokazano.
- W obszarze nowego zestawu zadań i istniejącej puli wystąpień masz również możliwość skonfigurowania liczby pracowników i włączenia wystąpień typu spot.
Możesz również określić inne ustawienia klastra, takie jak zasady klastra, konfiguracja platformy Spark, zmienne środowiskowe platformy Spark i tagi niestandardowe, zgodnie z wymaganiami dotyczącymi klastra, z którym nawiązujesz połączenie. Skrypty inicjowania usługi Databricks i ścieżka docelowa logów klastra mogą również być dodane pod dodatkowymi ustawieniami klastra.
Uwaga
Wszystkie zaawansowane właściwości klastra i wyrażenia dynamiczne obsługiwane w połączonej usłudze Azure Databricks w Azure Data Factory są teraz również obsługiwane w działaniu usługi Azure Databricks w usłudze Microsoft Fabric w sekcji "Dodatkowa konfiguracja klastra" w interfejsie użytkownika. Ponieważ te właściwości są teraz uwzględniane w interfejsie użytkownika działania, można ich używać z wyrażeniem (zawartość dynamiczna) bez konieczności specyfikacji Advanced JSON.

Działanie usługi Azure Databricks teraz również obsługuje zasady klastra i Unity Catalog.
- W obszarze ustawienia zaawansowane można wybrać zasady klastra , aby określić, które konfiguracje klastra są dozwolone.
- Ponadto w obszarze ustawień zaawansowanych można skonfigurować tryb dostępu katalogu Unity dla zwiększonego bezpieczeństwa. Dostępne typy trybu dostępu to:
- Tryb dostępu dla pojedynczego użytkownika Ten tryb jest przeznaczony dla scenariuszy, w których każdy klaster jest używany przez jednego użytkownika. Gwarantuje to, że dostęp do danych w klastrze jest ograniczony tylko do tego użytkownika. Ten tryb jest przydatny w przypadku zadań wymagających izolacji i indywidualnej obsługi danych.
- Tryb dostępu współdzielonego W tym trybie wielu użytkowników może uzyskać dostęp do tego samego klastra. Łączy zarządzanie danymi Katalogu Unity ze starymi listami kontroli dostępu do tabel (ACL). Ten tryb umożliwia współpracę przy dostępie do danych, jednocześnie zachowując protokoły zarządzania i zabezpieczeń. Jednak ma pewne ograniczenia, takie jak brak obsługi środowiska Databricks Runtime ML, zadań Spark-submit oraz określonych interfejsów API platformy Spark i funkcji zdefiniowanych przez użytkownika.
- Tryb braku dostępu Ten tryb wyłącza interakcję z Unity Catalog, co oznacza, że klastry nie mają dostępu do danych zarządzanych przez Unity Catalog. Ten tryb jest przydatny w przypadku obciążeń, które nie wymagają funkcji zarządzania w katalogu Unity.

Konfigurowanie ustawień
Wybierając kartę Ustawienia, możesz wybrać spośród 4 opcji, którym typem usługi Azure Databricks chcesz zarządzać.

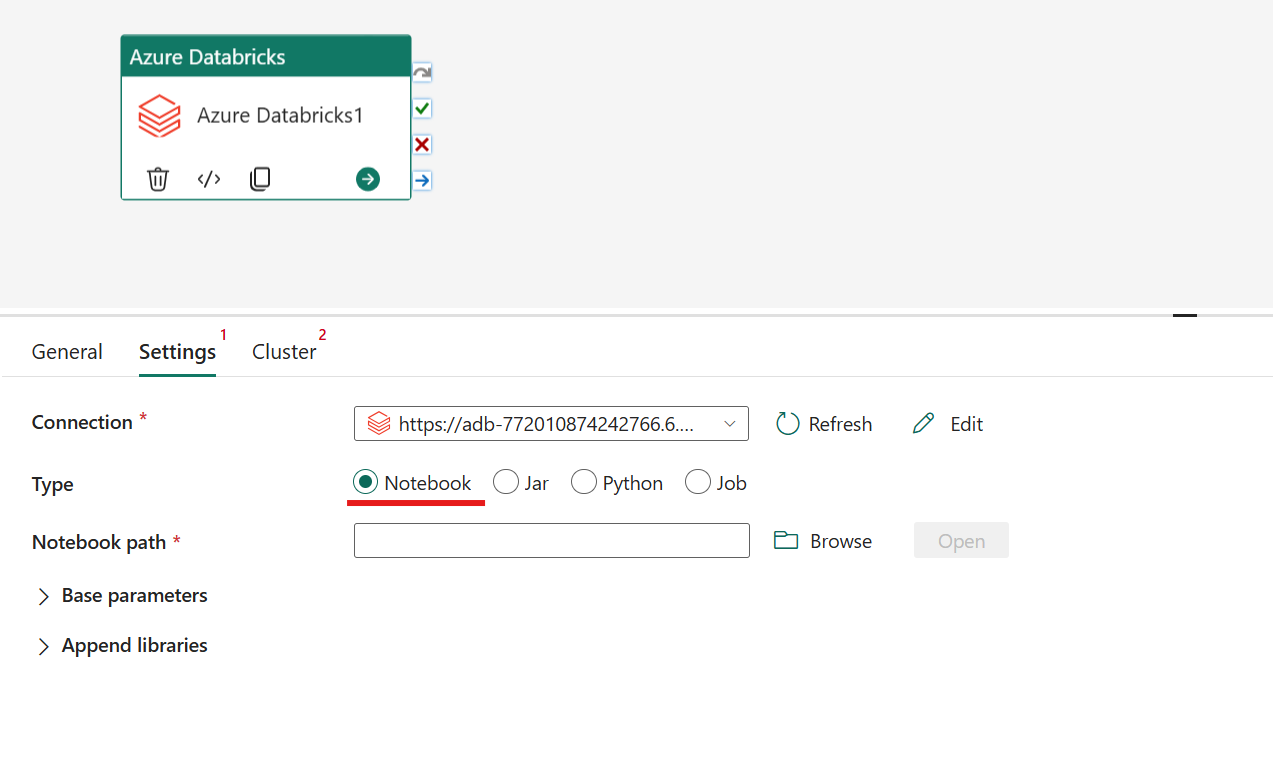
Zarządzanie typem notebooka w działaniu usługi Azure Databricks:
Na karcie Ustawienia możesz wybrać przycisk opcji Notebook, aby uruchomić Notebook. Należy określić ścieżkę notatnika do wykonania w usłudze Azure Databricks, opcjonalne parametry bazowe, które mają zostać przekazane do notatnika, oraz wszelkie dodatkowe biblioteki do zainstalowania w klastrze w celu wykonania procesu.
Orkiestracja typu Jar w działaniu usługi Azure Databricks:
Na karcie Ustawienia możesz wybrać przycisk radiowy Jar, aby uruchomić plik Jar. Należy określić nazwę klasy do wykonania w usłudze Azure Databricks, opcjonalne parametry podstawowe, które mają zostać przekazane do pliku Jar, oraz wszelkie dodatkowe biblioteki, które mają zostać zainstalowane w klastrze w celu wykonania zadania.

Koordynowanie typu Python w działaniach Azure Databricks:
Na karcie Ustawienia możesz wybrać przycisk radiowy Języka Python, aby uruchomić plik w języku Python. Należy określić ścieżkę w usłudze Azure Databricks do pliku w języku Python, który ma zostać wykonany, opcjonalne parametry podstawowe, które mają zostać przekazane, oraz wszelkie dodatkowe biblioteki, które mają zostać zainstalowane w klastrze w celu wykonania zadania.

Organizowanie typu zadania w działaniu usługi Azure Databricks:
Na karcie Ustawienia możesz wybrać przycisk radiowy Zadanie , aby uruchomić zadanie usługi Databricks. Należy określić zadanie za pomocą listy rozwijanej do wykonania w usłudze Azure Databricks oraz dowolne opcjonalne parametry zadania, które mają zostać przekazane. Za pomocą tej opcji można uruchamiać zadania bezserwerowe.

Obsługiwane biblioteki dla działania usługi Azure Databricks
W powyższej definicji działania usługi Databricks można określić następujące typy bibliotek: jar, egg, whl, maven, pypi, cran.
Aby uzyskać więcej informacji, zobacz dokumentację usługi Databricks dotyczącą typów bibliotek.
Przekazywanie parametrów między działaniem usługi Azure Databricks i potokami
Parametry można przekazać do notesów przy użyciu właściwości baseParameters w działaniu usługi Databricks.

Czasami możesz potrzebować zwrócenia wartości z notesu do usługi w celu sterowania przepływem lub ich użycia w działaniach podrzędnych (z limitem rozmiaru wynoszącym 2 MB).
Na przykład w notesie możesz wywołać metodę dbutils.notebook.exit("returnValue"), a odpowiednia wartość "returnValue" zostanie zwrócona do usługi.
Dane wyjściowe w usłudze można wykorzystać, używając wyrażenia takiego jak
@{activity('databricks activity name').output.runOutput}.
Zapisz i uruchom lub zaplanuj pipeline
Po skonfigurowaniu innych działań wymaganych dla potoku przejdź do karty Narzędzia główne w górnej części edytora potoków i wybierz przycisk zapisz, aby zapisać potok. Wybierz pozycję Uruchom , aby uruchomić go bezpośrednio lub Zaplanuj , aby go zaplanować. Historię uruchamiania można również wyświetlić tutaj lub skonfigurować inne ustawienia.
