Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym samouczku utworzysz potok, aby przenieść dane OData ze źródła Northwind do miejsca docelowego Lakehouse i wysłać powiadomienie e-mail po zakończeniu potoku.
Wymagania wstępne
Aby rozpocząć pracę, należy spełnić następujące wymagania wstępne:
- Upewnij się, że masz obszar roboczy z włączoną usługą Microsoft Fabric, który nie jest domyślnym obszarem Mój obszar roboczy.
Tworzenie usługi Lakehouse
Aby rozpocząć, musisz najpierw utworzyć jezioro. Lakehouse to usługa data lake, która jest zoptymalizowana pod kątem analizy. W tym samouczku utworzysz magazyn lakehouse, który jest używany jako miejsce docelowe dla przepływu danych.
Przejdź do obszaru roboczego z obsługą sieci szkieletowej.

Wybierz pozycję Lakehouse w menu tworzenia.

Wprowadź nazwę dla jeziora.
Wybierz pozycję Utwórz.

Teraz utworzono magazyn lakehouse i możesz teraz skonfigurować przepływ danych.
Utwórz przepływ danych
Przepływ danych to transformacja danych wielokrotnego użytku, która może być używana w potoku. W tym samouczku utworzysz przepływ danych, który pobiera dane ze źródła OData i zapisuje dane w miejscu docelowym usługi Lakehouse.
Przejdź do obszaru roboczego z obsługą sieci szkieletowej.
Wybierz pozycję Dataflow Gen2 w menu tworzenia.

Pozyskiwanie danych ze źródła OData.
Wybierz pozycję Pobierz dane, a następnie wybierz pozycję Więcej.

W obszarze Wybierz źródło danych wyszukaj pozycję OData, a następnie wybierz łącznik OData.

Wprowadź adres URL źródła OData. Na potrzeby tego samouczka użyj przykładowej usługi OData.
Wybierz Dalej.
Wybierz jednostkę, którą chcesz pozyskać. W tym samouczku użyj jednostki Orders .

Wybierz pozycję Utwórz.


Po pozyskaniu danych ze źródła OData możesz skonfigurować miejsce docelowe usługi Lakehouse.
Aby pozyskać dane do miejsca docelowego lakehouse:
Wybierz pozycję Dodaj miejsce docelowe danych.
Wybierz pozycję Lakehouse.

Skonfiguruj połączenie, którego chcesz użyć do nawiązania połączenia z usługą Lakehouse. Ustawienia domyślne są poprawne.
Wybierz Dalej.
Przejdź do obszaru roboczego, w którym utworzono magazyn lakehouse.
Wybierz usługę Lakehouse utworzoną w poprzednich krokach.

Potwierdź nazwę tabeli.
Wybierz Dalej.
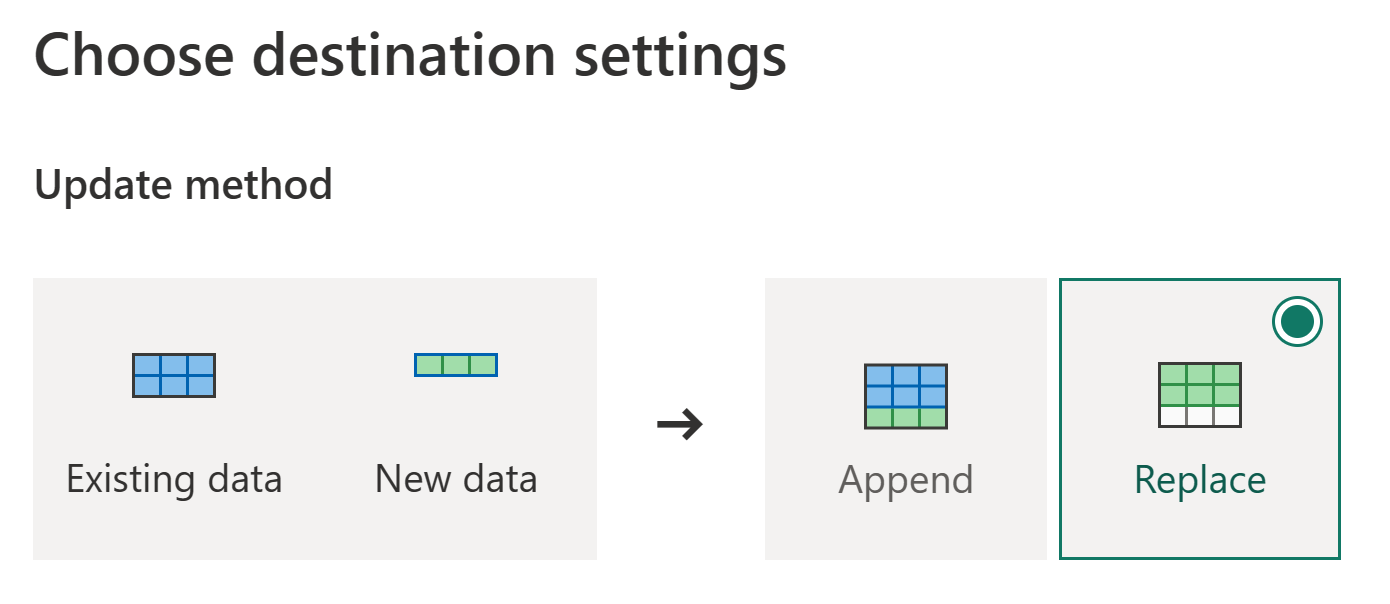
Potwierdź metodę aktualizacji i wybierz pozycję Zapisz ustawienia.
Opublikuj przepływ danych.
Ważne
Po utworzeniu pierwszego przepływu danych Gen2 w obszarze roboczym elementy usługi Lakehouse i Warehouse są aprowizowane wraz z powiązanymi punktami końcowymi i semantycznymi modelami analizy SQL. Te elementy są współużytkowane przez wszystkie przepływy danych w obszarze roboczym i są wymagane, aby przepływ danych Gen2 działał, nie powinien być usuwany i nie jest przeznaczony do bezpośredniego użycia przez użytkowników. Elementy są szczegółami implementacji usługi Dataflow Gen2. Elementy nie są widoczne w obszarze roboczym, ale mogą być dostępne w innych środowiskach, takich jak notes, punkt końcowy SQL, usługa Lakehouse i magazyn. Elementy można rozpoznać według ich prefiksu w nazwie. Prefiks elementów to "Przepływy danychStaging".
Po wprowadzeniu danych do miejsca docelowego Lakehouse, możesz skonfigurować potok.
Stwórz potok
Pipeline to ciąg operacji, który może służyć do automatyzowania przetwarzania danych. W tym samouczku utworzysz potok, który uruchamia przepływ danych Gen2 utworzony w poprzedniej procedurze.
Wróć do strony przeglądu obszaru roboczego i w menu tworzenia wybierz pozycję Potoki.

Podaj nazwę rury.
Wybierz działanie Przepływ danych.

Wybierz przepływ danych utworzony w poprzedniej procedurze na liście rozwijanej Przepływ danych w obszarze Ustawienia.

Dodaj działanie usługi Office 365 Outlook.

Skonfiguruj działanie usługi Office 365 Outlook w celu wysyłania powiadomień e-mail.
Uwierzytelnij się przy użyciu konta usługi Office 365.
Wybierz adres e-mail, do którego chcesz wysłać powiadomienie.
Wprowadź temat wiadomości e-mail.
Wprowadź treść wiadomości e-mail.


Uruchamianie i planowanie pipeline'u
W tej części uruchomisz i zaplanujesz pipeline. Ten harmonogram umożliwia uruchamianie potoku w ustalonym czasie.
Przejdź do swojego obszaru roboczego.
Otwórz rozwijaną listę rurociągu utworzonego w poprzedniej procedurze, a następnie wybierz pozycję Harmonogram.

W obszarze Zaplanowane uruchamianie wybierz pozycję Włączone.

Podaj harmonogram, którego chcesz użyć do uruchomienia potoku.
- Powtarzaj, na przykład codziennie lub co minutę.
- Po wybraniu opcji Codziennie możesz również wybrać pozycję Godzina.
- Rozpocznij od określonej daty.
- Koniec w określonej dacie.
- Wybierz strefę czasową.
Wybierz pozycję Zastosuj , aby zastosować zmiany.

Utworzono potok uruchamiany zgodnie z harmonogramem, który odświeża dane w Lakehouse i wysyła powiadomienie e-mail. Stan potoku danych można sprawdzić, przechodząc do Monitor Hub. Możesz również sprawdzić stan pipeline'u, przechodząc do pozycji Pipeline i wybierając kartę Historia wykonywania w menu rozwijanym.
Powiązana zawartość
W tym przykładzie pokazano, jak używać przepływu danych w potoku z usługą Data Factory w usłudze Microsoft Fabric. W tym samouczku omówiono:
- Utwórz przepływ danych.
- Utwórz potok wywołujący przepływ danych.
- Uruchom i zaplanuj swój rurociąg.
Następnie przejdź dalej, aby dowiedzieć się więcej na temat monitorowania przebiegów potoku.