Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ten samouczek zajmuje 15 minut i opisuje, jak przyrostowo zgromadzić dane w usłudze Lakehouse przy użyciu usługi Dataflow Gen2.
Przyrostowe zbieranie danych w miejscu docelowym danych wymaga techniki ładowania tylko nowych lub zaktualizowanych danych do miejsca docelowego danych. Tę technikę można wykonać przy użyciu zapytania w celu filtrowania danych na podstawie miejsca docelowego danych. W tym samouczku pokazano, jak utworzyć przepływ danych w celu załadowania danych ze źródła OData do magazynu typu lakehouse oraz jak dodać zapytanie do przepływu danych w celu filtrowania danych na podstawie miejsca docelowego danych.
Główne kroki w tym samouczku są następujące:
- Utwórz przepływ danych, aby załadować dane ze źródła OData do magazynu danych typu lakehouse.
- Dodaj zapytanie do przepływu danych, aby filtrować dane na podstawie miejsca docelowego danych.
- (Opcjonalnie) załaduj ponownie dane przy użyciu notatników i potoków.
Wymagania wstępne
Musisz mieć obszar roboczy z włączoną usługą Microsoft Fabric. Jeśli jeszcze go nie masz, zapoznaj się z artykułem Tworzenie obszaru roboczego. Ponadto w samouczku założono, że używasz widoku diagramu w przepływie danych Gen2. Aby sprawdzić, czy używasz widoku diagramu, na górnej wstążce menu przejdź do pozycji Widok i upewnij się, że wybrano widok diagramu.
Utwórz przepływ danych w celu załadowania danych ze źródła OData do magazynu typu lakehouse
W tej sekcji utworzysz przepływ danych w celu załadowania danych ze źródła OData do magazynu typu lakehouse.
Utwórz nowy lakehouse w swoim środowisku pracy.

Utwórz nowy przepływ danych Gen2 w obszarze roboczym.
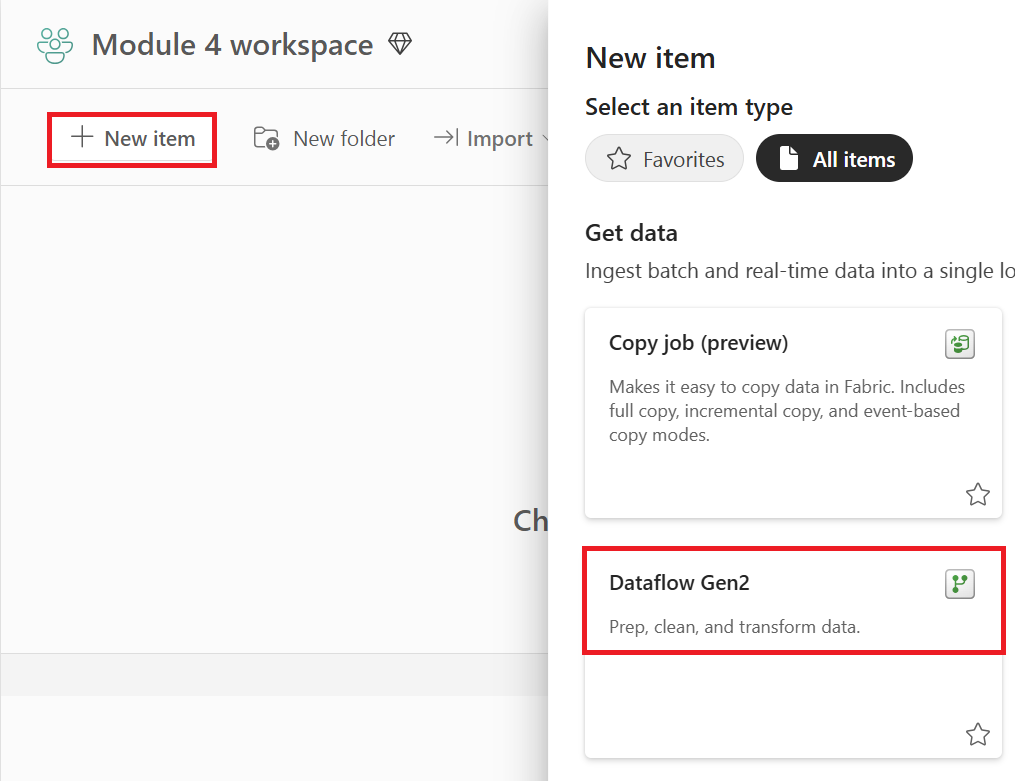
Dodaj nowe źródło do przepływu danych. Wybierz źródło OData i wprowadź następujący adres URL:
https://services.OData.org/V4/Northwind/Northwind.svc


Wybierz tabelę Orders (Zamówienia) i wybierz przycisk Next (Dalej).
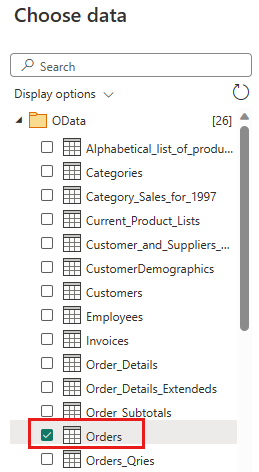
Wybierz następujące kolumny, aby zachować:
OrderIDCustomerIDEmployeeIDOrderDateRequiredDateShippedDateShipViaFreightShipNameShipAddressShipCityShipRegionShipPostalCodeShipCountry


Zmień typ danych ,
OrderDateRequiredDateiShippedDatenadatetime.
Skonfiguruj miejsce docelowe danych w usłudze Lakehouse przy użyciu następujących ustawień:
- Miejsce docelowe danych:
Lakehouse - Lakehouse: wybierz jezioro utworzone w kroku 1.
- Nowa nazwa tabeli:
Orders - Metoda aktualizacji:
Replace



- Miejsce docelowe danych:
wybierz pozycję Dalej i opublikuj przepływ danych.



Utworzyłeś teraz przepływ danych, aby załadować dane ze źródła OData do lakehouse. Ten przepływ danych jest używany w następnej sekcji, aby dodać zapytanie do przepływu danych w celu filtrowania danych na podstawie miejsca docelowego danych. Następnie możesz użyć przepływu danych do ponownego załadowania danych przy użyciu notatników i potoków.
Dodawanie zapytania do przepływu danych w celu filtrowania danych na podstawie miejsca docelowego danych
Ta sekcja dodaje zapytanie do przepływu danych, aby przefiltrować dane zgodnie z informacjami znajdującymi się w docelowym jeziorze danych. Zapytanie pobiera maksymalną wartość OrderID w Lakehouse na początku odświeżania przepływu danych i korzysta z maksymalnego OrderId, aby uzyskać tylko te zamówienia, które mają wyższy OrderId od źródła, a następnie dołącza je do miejsca docelowego danych. Przyjęto założenie, że zamówienia są dodawane do źródła w kolejności rosnącejOrderID. Jeśli tak nie jest, możesz użyć innej kolumny do filtrowania danych. Na przykład możesz użyć kolumny OrderDate do filtrowania danych.
Uwaga
Filtry OData są stosowane w ramach Fabric po odebraniu danych ze źródła danych. Jednak w przypadku źródeł baz danych, takich jak SQL Server, filtr jest stosowany w zapytaniu wysyłanym do źródła danych zaplecza i do usługi zwracane są tylko przefiltrowane wiersze.
Po odświeżeniu przepływu danych otwórz ponownie przepływ danych utworzony w poprzedniej sekcji.
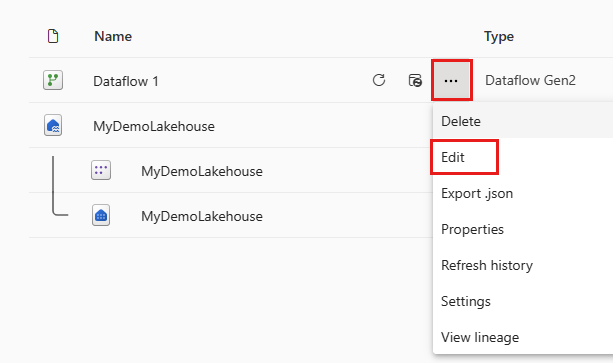
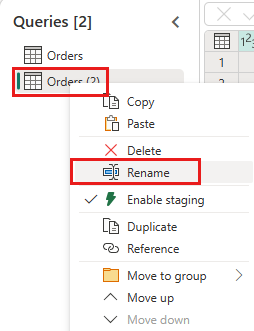
Utwórz nowe zapytanie o nazwie
IncrementalOrderIDi pobierz dane z tabeli zamówień w systemie Lakehouse utworzonym w poprzedniej sekcji.



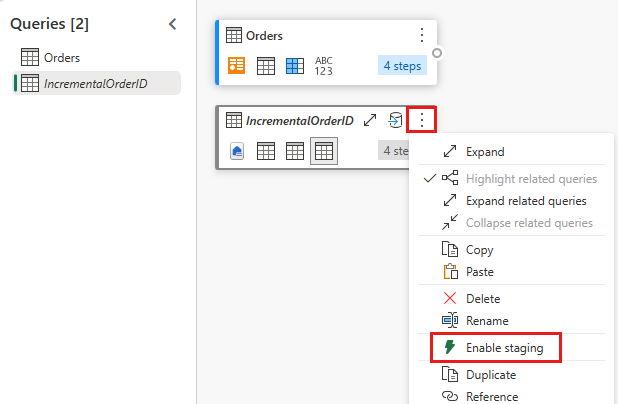
Wyłącz przemieszczanie tego zapytania.
W podglądzie danych kliknij prawym przyciskiem myszy kolumnę
OrderIDi wybierz pozycję Przejdź do szczegółów.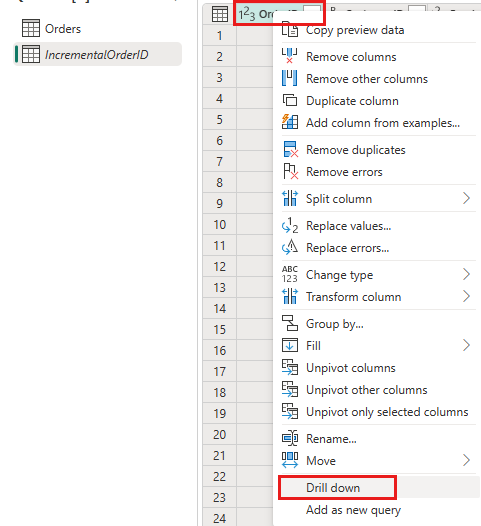
Na wstążce wybierz pozycję Narzędzia listy ->Statystyka ->Maksimum.
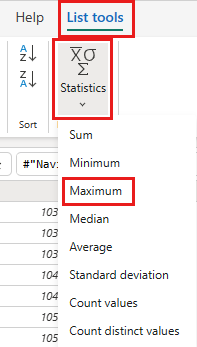
Masz teraz zapytanie, które zwraca maksymalny identyfikator OrderID w Lakehouse. To zapytanie służy do filtrowania danych ze źródła OData. W następnej sekcji dodano zapytanie do przepływu danych w celu filtrowania danych ze źródła OData na podstawie maksymalnego identyfikatora OrderID w magazynie typu lakehouse.
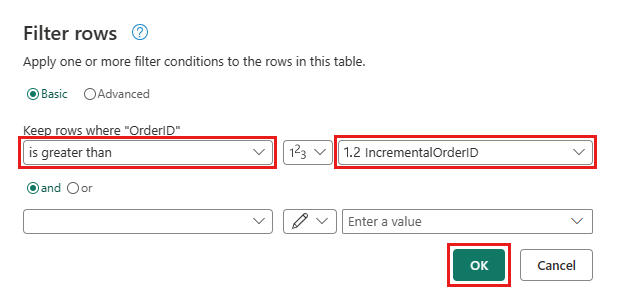
Wróć do zapytania Orders (Zamówienia) i dodaj nowy krok w celu filtrowania danych. Użyj następujących ustawień:
- Kolumna:
OrderID - Operacja:
Greater than - Wartość: parametr
IncrementalOrderID

- Kolumna:
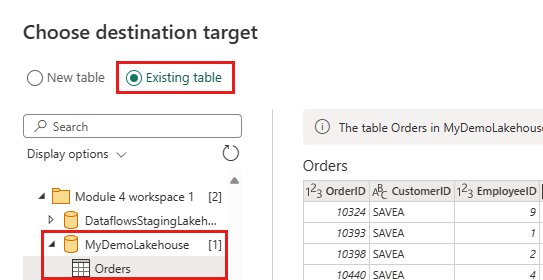
Zezwalaj na łączenie danych ze źródła OData i lakehouse, potwierdzając następujące okno dialogowe:

Zaktualizuj miejsce docelowe danych, aby użyć następujących ustawień:
- Metoda aktualizacji:
Append


- Metoda aktualizacji:
Opublikuj przepływ danych.
Przepływ danych zawiera teraz zapytanie, które filtruje dane ze źródła OData na podstawie maksymalnego identyfikatora OrderID w lakehouse. Oznacza to, że do lakehouse są ładowane tylko nowe lub zaktualizowane dane. W następnej sekcji, przepływ danych zostanie użyty do ponownego ładowania danych za pomocą notebooków i potoków.
(Opcjonalnie) ponownie załaduj dane za pomocą notatników i pipelines.
Opcjonalnie możesz ponownie załadować określone dane przy użyciu notesów i potoków. Za pomocą niestandardowego kodu w języku Python w notatniku usuwasz stare dane z lakehouse'u. Następnie utworzysz potok, w którym najpierw uruchomisz notes i sekwencyjnie uruchomisz przepływ danych, załadujesz ponownie dane ze źródła OData do usługi Lakehouse. Notesy obsługują wiele języków, ale w tym samouczku jest używany program PySpark. Pyspark to interfejs API języka Python dla platformy Spark i jest używany w tym samouczku do uruchamiania zapytań Spark SQL.
Utwórz nowy notatnik w swoim środowisku pracy.
Dodaj następujący kod PySpark do notesu:
### Variables LakehouseName = "YOURLAKEHOUSE" TableName = "Orders" ColName = "OrderID" NumberOfOrdersToRemove = "10" ### Remove Old Orders Reload = spark.sql("SELECT Max({0})-{1} as ReLoadValue FROM {2}.{3}".format(ColName,NumberOfOrdersToRemove,LakehouseName,TableName)).collect() Reload = Reload[0].ReLoadValue spark.sql("Delete from {0}.{1} where {2} > {3}".format(LakehouseName, TableName, ColName, Reload))Uruchom notatnik, aby sprawdzić, czy dane zostały usunięte z lakehouse.
Utwórz nowy potok w obszarze roboczym.

Dodaj nowe zadanie notesu do potoku danych i wybierz notes utworzony w poprzednim kroku.
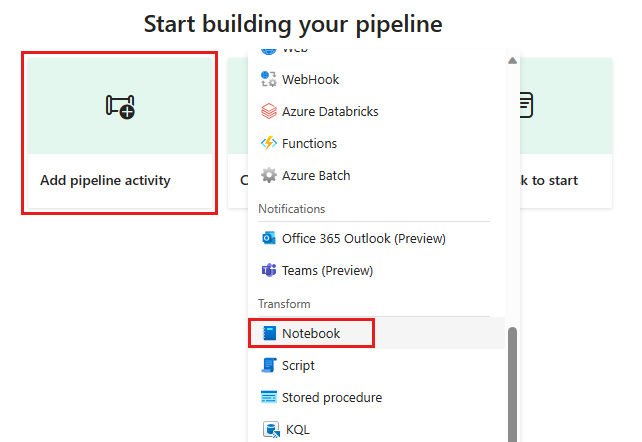
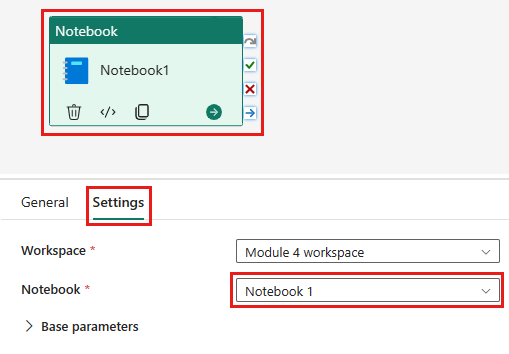
Dodaj nową aktywność przepływu danych do potoku i wybierz przepływ danych utworzony w poprzednim kroku.
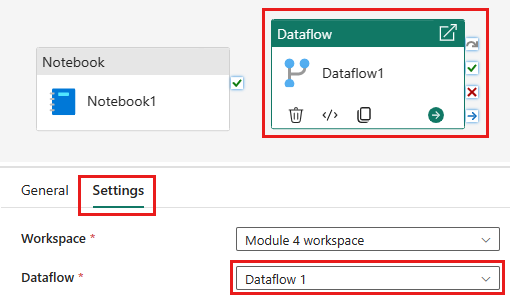
Połącz aktywność notesu z aktywnością przepływu danych za pomocą wyzwalacza powodzenia.

Zapisz i uruchom potok.


Masz teraz pipeline, który usuwa stare dane z lakehouse'u i ponownie ładuje dane ze źródła OData do lakehouse'u. Dzięki tej konfiguracji można regularnie przeładowywać dane ze źródła OData do Lakehouse.