Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Użyj zależności funkcjonalnych, aby wyczyścić dane. Zależność funkcjonalna istnieje, gdy jedna kolumna w modelu semantycznym (zestawie danych usługi Power BI) zależy od innej kolumny. Na przykład kolumna ZIP code może określić wartość w kolumnie city . Zależność funkcjonalna jest wyświetlana jako relacja jeden do wielu między wartościami w co najmniej dwóch kolumnach w obiekcie DataFrame. W tym samouczku użyto zestawu danych Synthea, aby pokazać, jak zależności funkcjonalne pomagają wykrywać problemy z jakością danych.
Z tego samouczka dowiesz się, jak wykonywać następujące działania:
- Zastosuj wiedzę o domenie, aby utworzyć hipotezy dotyczące zależności funkcjonalnych w modelu semantycznym.
- Zapoznaj się ze składnikami biblioteki języka Python semantic Link (SemPy), która automatyzuje analizę jakości danych. Te składniki obejmują:
-
FabricDataFrame— struktura podobna do biblioteki pandas z dodatkowymi informacjami semantycznymi. - Funkcje, które automatyzują ocenianie hipotez dotyczących zależności funkcjonalnych i identyfikują naruszenia w modelach semantycznych.
-
Warunki wstępne
Pobierz subskrypcję usługi Microsoft Fabric . Możesz też utworzyć bezpłatne konto wersji próbnej usługi Microsoft Fabric.
Zaloguj się do usługi Microsoft Fabric.
Przełącz się na Fabric, używając przełącznika nawigacji w lewej dolnej części strony głównej.

- Wybierz pozycję Obszary robocze w okienku nawigacji, a następnie wybierz obszar roboczy, aby ustawić go jako bieżący obszar roboczy.
Postępuj zgodnie z instrukcjami w notesie
Użyj notesu data_cleaning_functional_dependencies_tutorial.ipynb , aby wykonać czynności opisane w tym samouczku.
Aby otworzyć towarzyszący notes na potrzeby tego samouczka, postępuj zgodnie z instrukcjami w temacie Przygotowywanie systemu do celów nauki o danych, aby zaimportować notes do obszaru roboczego.
Jeśli wolisz skopiować i wkleić kod z tej strony, możesz utworzyć nowy notes.
Przed rozpoczęciem uruchamiania kodu pamiętaj, aby dołączyć usługę Lakehouse do notesu .
Konfigurowanie notesu
W tej sekcji skonfigurujesz środowisko notesu.
Sprawdź wersję platformy Spark. Jeśli używasz platformy Spark 3.4 lub nowszej w usłudze Microsoft Fabric, link semantyczny jest domyślnie dołączany, więc nie musisz go instalować. Jeśli używasz platformy Spark 3.3 lub starszej lub chcesz zaktualizować do najnowszego linku semantycznego, uruchom następujące polecenie.
%pip install -U semantic-linkZaimportuj moduły używane w tym notesie.
import pandas as pd import sempy.fabric as fabric from sempy.fabric import FabricDataFrame from sempy.dependencies import plot_dependency_metadataPobierz przykładowe dane. W tym samouczku użyj zestawu danych Synthea syntetycznych dokumentacji medycznej (mała wersja dla uproszczenia).
download_synthea(which='small')
Eksplorowanie danych
Zainicjuj element
FabricDataFramez zawartością pliku providers.csv .providers = FabricDataFrame(pd.read_csv("synthea/csv/providers.csv")) providers.head()Sprawdź, czy występują problemy z jakością danych z funkcją SemPy
find_dependencies, wykreślijąc wykres automatycznie wykrywanych zależności funkcjonalnych.deps = providers.find_dependencies() plot_dependency_metadata(deps)
Wykres pokazuje, że
IdokreślaNAMEiORGANIZATION. Ten wynik jest oczekiwany, ponieważIdjest unikatowy.Upewnij się, że
Idjest to unikatowe.providers.Id.is_uniqueKod zwraca
True, aby potwierdzić, żeIdjest unikatowa.

Analizowanie zależności funkcjonalnych wnikliwie
Wykres zależności funkcjonalnych pokazuje również, że ORGANIZATION określa ADDRESS i ZIP, zgodnie z oczekiwaniami. Można jednak oczekiwać, że ZIP może również określić CITY, ale strzałka kreskowana wskazuje, że zależność jest jedynie przybliżona, co wskazuje na problem z jakością danych.
Na wykresie istnieją inne osobliwości. Na przykład NAME nie określa GENDER, Id, SPECIALITYlub ORGANIZATION. Każda z tych osobliwości może być warta zbadania.
- Przyjrzyj się bliżej przybliżonej relacji między elementami
ZIPiCITYprzy użyciu funkcji SemPylist_dependency_violationsw celu wyświetlenia listy naruszeń:
providers.list_dependency_violations('ZIP', 'CITY')
- Rysuj graf za pomocą funkcji wizualizacji
plot_dependency_violationsSemPy. Ten wykres jest przydatny, jeśli liczba naruszeń jest mała:
providers.plot_dependency_violations('ZIP', 'CITY')
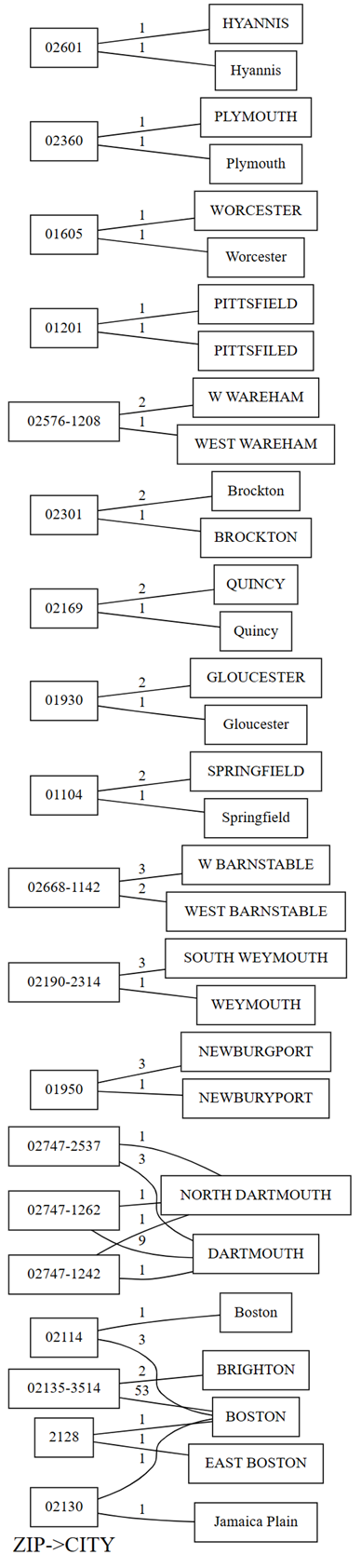
Wykres naruszeń zależności przedstawia wartości po ZIP lewej stronie i wartości dla CITY po prawej stronie. Krawędź łączy kod pocztowy po lewej stronie wykresu z miastem po prawej stronie, jeśli istnieje wiersz zawierający te dwie wartości. Krawędzie są oznaczone adnotacjami z liczbą takich wierszy. Na przykład istnieją dwa wiersze z kodem pocztowym 02747-1242, jeden wiersz z miastem "NORTH DARTHMOUTH", a drugi z miastem "DARTHMOUTH", jak pokazano na poprzednim wykresie i następującym kodzie:
- Potwierdź obserwacje z wykresu, uruchamiając następujący kod:
providers[providers.ZIP == '02747-1242'].CITY.value_counts()
Wykres pokazuje również, że wśród wierszy, które mają
CITYjako "DARTHMOUTH", dziewięć wierszy maZIP02747-1262. Jeden wiersz maZIPwartość 02747-1242. Jeden wiersz maZIPwartość 02747-2537. Potwierdź te obserwacje przy użyciu następującego kodu:providers[providers.CITY == 'DARTHMOUTH'].ZIP.value_counts()Istnieją inne kody pocztowe skojarzone z "DARTMOUTH", ale te kody pocztowe nie są wyświetlane na wykresie naruszeń zależności, ponieważ nie wskazują na problemy z jakością danych. Na przykład kod pocztowy "02747-4302" jest jednoznacznie skojarzony z "DARTMOUTH" i nie jest wyświetlany na wykresie naruszeń zależności. Potwierdź, uruchamiając następujący kod:
providers[providers.ZIP == '02747-4302'].CITY.value_counts()
Podsumowywanie problemów z jakością danych wykrytych za pomocą rozwiązania SemPy
Wykres naruszeń zależności przedstawia kilka problemów z jakością danych w tym modelu semantycznym:
- Niektóre nazwy miast to wielkie litery. Użyj metod ciągów, aby rozwiązać ten problem.
- Niektóre nazwy miast mają kwalifikatory (lub prefiksy), takie jak "Północ" i "Wschód". Na przykład kod pocztowy "2128" mapuje raz na "EAST BOSTON" i na "BOSTON". Podobny problem występuje między "NORTH DARTMOUTH" i "DARTMOUTH". Upuść te kwalifikatory lub zamapuj kody pocztowe na miasto z najczęstszym wystąpieniem.
- W niektórych nazwach miast istnieją literówki, takie jak "PITTSFIELD" a "PITTSFILED" i "NEWBURGPORT" vs. "NEWBURYPORT". W przypadku polecenia "NEWBURGPORT" napraw tę literówkę, używając najbardziej typowego wystąpienia. W przypadku "PITTSFIELD", z tylko jednym wystąpieniem każdego, automatyczne uściślanie jest znacznie trudniejsze bez wiedzy zewnętrznej lub modelu językowego.
- Czasami prefiksy takie jak "Zachód" są skracane do pojedynczej litery "W". Zastąp wartość "W" wartością "West", jeśli wszystkie wystąpienia "W" będą oznaczać wartość "West".
- Kod pocztowy "02130" mapuje na "BOSTON" raz i "Jamajka Plain" raz. Ten problem nie jest łatwy do rozwiązania. Przy użyciu większej ilości danych zamapuj na najbardziej typowe wystąpienie.
Czyszczenie danych
Napraw wielkość liter, zmieniając wartości na wielkość liter tytułu.
providers['CITY'] = providers.CITY.str.title()Uruchom ponownie wykrywanie naruszeń, aby potwierdzić, że istnieje mniej niejednoznaczności.
providers.list_dependency_violations('ZIP', 'CITY')
Uściślij dane ręcznie lub upuść wiersze naruszające ograniczenia funkcjonalne między kolumnami przy użyciu funkcji SemPy drop_dependency_violations .
Dla każdej wartości zmiennej drop_dependency_violations determinant wybiera najbardziej typową wartość zmiennej zależnej i usuwa wszystkie wiersze z innymi wartościami. Zastosuj tę operację tylko wtedy, gdy masz pewność, że ta statystyczna heurystyka prowadzi do poprawnych wyników dla danych. W przeciwnym razie napisz własny kod, aby obsłużyć wykryte naruszenia.
drop_dependency_violationsUruchom funkcję w kolumnachZIPi .CITYproviders_clean = providers.drop_dependency_violations('ZIP', 'CITY')Wyświetl wszystkie naruszenia zależności między
ZIPiCITY.providers_clean.list_dependency_violations('ZIP', 'CITY')
Kod zwraca pustą listę, aby wskazać, że nie ma więcej naruszeń ograniczenia ZIP -> CITYfunkcjonalnego .
Powiązana zawartość
Zobacz inne samouczki dotyczące linku semantycznego lub biblioteki SemPy:
- Samouczek: analizowanie zależności funkcjonalnych w przykładowym modelu semantycznym
- Samouczek : Wyodrębnianie i obliczanie miar Power BI z notesu Jupyter
- Samouczek: odnajdywanie relacji w modelu semantycznym przy użyciu linku semantycznego
- Samouczek: odnajdywanie relacji w zestawie danych Synthea przy użyciu linku semantycznego
- Samouczek: weryfikowanie danych przy użyciu bibliotekI SemPy i wielkich oczekiwań (GX)