Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym samouczku wykonasz zapytanie dotyczące replikowanej bazy danych Fabric z istniejącej bazy danych Cosmos DB w bazie danych Fabric. Dowiesz się, jak włączyć dublowanie w bazie danych, zweryfikować stan dublowania, a następnie użyć zarówno danych źródłowych, jak i dublowanych na potrzeby analizy.
Wymagania wstępne
Istniejąca zdolność sieci Fabric
- Jeśli nie masz pojemności Fabric, uruchom wersję próbną Fabric.
Istniejąca baza danych Cosmos DB w Fabric
- Jeśli jeszcze go nie masz, utwórz nową bazę danych Cosmos DB w usłudze Fabric.
Skonfiguruj swoją bazę danych Cosmos DB w bazie danych Fabric
Najpierw upewnij się, że baza danych Cosmos DB w platformie Fabric jest prawidłowo skonfigurowana i zawiera dane do replikacji.
Otwórz portal Fabric (https://app.fabric.microsoft.com).
Przejdź do istniejącej bazy danych Cosmos DB.
Ważne
Na potrzeby tego samouczka istniejąca baza danych Cosmos DB powinna mieć już załadowany przykładowy zestaw danych . W pozostałych krokach w tym samouczku założono, że używasz tego samego zestawu danych dla tej bazy danych.
Sprawdź, czy baza danych zawiera co najmniej jeden kontener z danymi. Wykonaj tę weryfikację, rozwijając kontener w okienku nawigacji i obserwując, że elementy istnieją.
Na pasku menu wybierz pozycję Ustawienia , aby uzyskać dostęp do konfiguracji bazy danych.
W oknie dialogowym Ustawienia przejdź do sekcji Dublowanie , aby sprawdzić, czy dublowanie jest włączone dla tej bazy danych.
Uwaga / Notatka
Duplikowanie jest automatycznie włączone dla wszystkich baz danych Cosmos DB w Fabric. Ta funkcja nie wymaga żadnej dodatkowej konfiguracji i zapewnia, że dane są zawsze gotowe do analizy w usłudze OneLake.
Nawiązywanie połączenia z źródłową bazą danych
Następnie upewnij się, że możesz nawiązać połączenie z źródłową bazą danych Cosmos DB i wykonać zapytanie bezpośrednio.
Przejdź z powrotem do istniejącej bazy danych Cosmos DB w Fabric portal.
Wybierz i rozwiń istniejący kontener, aby wyświetlić jego zawartość.
Wybierz pozycję Elementy , aby przeglądać dane bezpośrednio w bazie danych.
Upewnij się, że możesz zobaczyć przedmioty w swoim kontenerze. Jeśli na przykład używasz przykładowego zestawu danych, powinny zostać wyświetlone elementy z właściwościami takimi jak
name,categoryicountryOfOrigin.Wybierz pozycję Nowe zapytanie z menu, aby otworzyć edytor zapytań NoSQL.
Uruchom zapytanie testowe, aby zweryfikować łączność i dostępność danych:
SELECT COUNT(1) AS itemCount FROM containerTo zapytanie powinno zwrócić całkowitą liczbę elementów w kontenerze.
Nawiązywanie połączenia z lustrzaną bazą danych
Teraz uzyskaj dostęp do dublowanej wersji bazy danych za pośrednictwem punktu końcowego analizy SQL, aby wykonywać zapytania dotyczące tych samych danych przy użyciu języka T-SQL.
Na pasku menu wybierz listę Cosmos DB, a następnie wybierz adres końcowy analizy SQL, aby przełączyć się do widoku zreplikowanej bazy danych.
Sprawdź, czy kontener jest wyświetlany jako tabela w punkcie końcowym analizy SQL. Tabela powinna mieć taką samą nazwę jak kontener.
Wybierz pozycję Nowe zapytanie SQL z menu, aby otworzyć edytor zapytań języka T-SQL.
Uruchom zapytanie testowe, aby sprawdzić, czy dublowanie działa poprawnie:
SELECT COUNT(*) AS itemCount FROM [dbo].[SampleData]Uwaga / Notatka
Zastąp
[SampleData]nazwą swojego kontenera, jeśli nie używasz przykładowego zestawu danych.Zapytanie powinno zwrócić tę samą liczbę co zapytanie NoSQL, potwierdzając, że mirroring pomyślnie replikuje dane.
Wykonywanie zapytań względem źródłowej bazy danych z sieci szkieletowej
Użyj portalu sieci szkieletowej, aby eksplorować dane, które już istnieją na koncie usługi Azure Cosmos DB, odpytując źródłową bazę danych Cosmos DB.
Przejdź do dublowanej bazy danych w portalu sieci szkieletowej.
Wybierz pozycję Widok, a następnie źródłową bazę danych. Ta akcja powoduje otwarcie eksploratora danych usługi Azure Cosmos DB z widokiem tylko do odczytu źródłowej bazy danych.

Wybierz kontener, a następnie otwórz menu kontekstowe i wybierz pozycję Nowe zapytanie SQL.
Uruchom dowolne zapytanie. Na przykład użyj polecenia
SELECT COUNT(1) FROM container, aby zliczyć liczbę elementów w kontenerze.Uwaga / Notatka
Wszystkie operacje odczytu w źródłowej bazie danych są kierowane do Azure i konsumują jednostki żądań (RUs) przydzielone na koncie.

Analizowanie docelowej dublowanej bazy danych
Teraz użyj języka T-SQL, aby wysłać zapytanie do danych NoSQL, które są teraz przechowywane w usłudze Fabric OneLake.
Przejdź do dublowanej bazy danych w portalu sieci szkieletowej.
Przełącz się z dublowanej usługi Azure Cosmos DB do punktu końcowego analizy SQL.
Każdy kontener w źródłowej bazie danych powinien być reprezentowany w punkcie końcowym analizy SQL jako tabeli magazynu.
Wybierz dowolną tabelę, otwórz menu kontekstowe, a następnie wybierz pozycję Nowe zapytanie SQL, a na koniec wybierz pozycję Wybierz 100 pierwszych.
Zapytanie wykonuje i zwraca 100 rekordów w wybranej tabeli.
Otwórz menu kontekstowe dla tej samej tabeli i wybierz pozycję Nowe zapytanie SQL. Napisz przykładowe zapytanie, które używa agregacji, takich jak
SUM,COUNT,MINlubMAX. Połącz wiele tabel w magazynie, aby wykonać zapytanie w wielu kontenerach.Uwaga / Notatka
Na przykład to zapytanie będzie wykonywane w wielu kontenerach:
SELECT d.[product_category_name], t.[order_status], c.[customer_country], s.[seller_state], p.[payment_type], sum(o.[price]) as price, sum(o.[freight_value]) freight_value FROM [dbo].[products] p INNER JOIN [dbo].[OrdersDB_order_payments] p on o.[order_id] = p.[order_id] INNER JOIN [dbo].[OrdersDB_order_status] t ON o.[order_id] = t.[order_id] INNER JOIN [dbo].[OrdersDB_customers] c on t.[customer_id] = c.[customer_id] INNER JOIN [dbo].[OrdersDB_productdirectory] d ON o.product_id = d.product_id INNER JOIN [dbo].[OrdersDB_sellers] s on o.seller_id = s.seller_id GROUP BY d.[product_category_name], t.[order_status], c.[customer_country], s.[seller_state], p.[payment_type]W tym przykładzie przyjęto założenie, że nazwa tabeli i kolumn. Użyj własnej tabeli i kolumn podczas pisania zapytania SQL.
Wybierz zapytanie, a następnie wybierz pozycję Zapisz jako widok. Nadaj widokowi unikatową nazwę. Dostęp do tego widoku można uzyskać w dowolnym momencie w portalu sieci szkieletowej.
Wróć do dublowanej bazy danych w portalu sieci szkieletowej.
Wybierz pozycję Nowe zapytanie wizualne. Użyj edytora zapytań, aby tworzyć złożone zapytania.
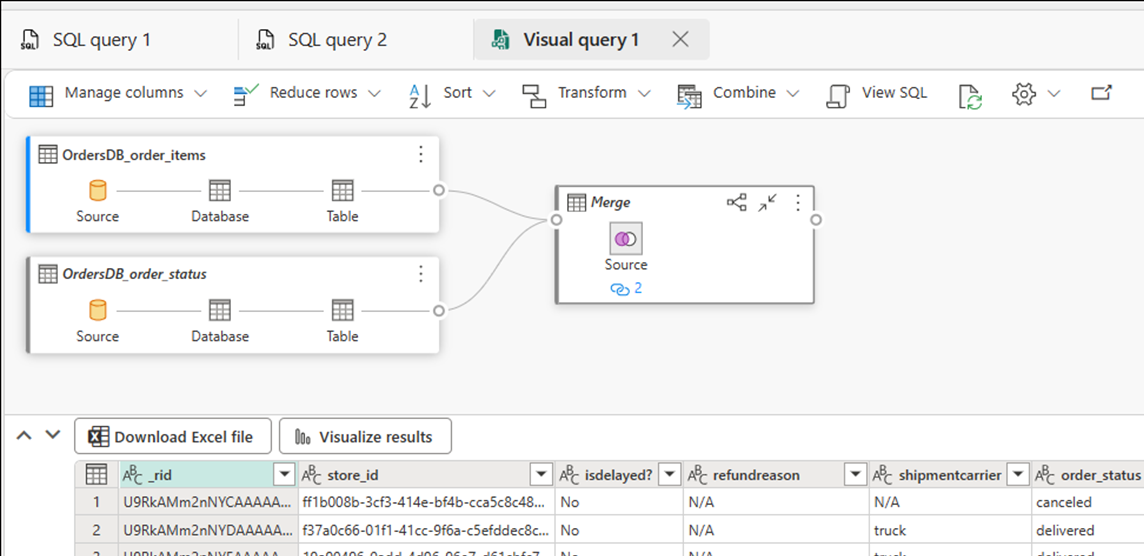


Tworzenie raportów analizy biznesowej dotyczących zapytań LUB widoków SQL
- Wybierz zapytanie lub widok, a następnie wybierz pozycję Eksploruj te dane (wersja zapoznawcza). Ta akcja eksploruje zapytanie w usłudze Power BI bezpośrednio przy użyciu usługi Direct Lake w danych dublowanych w usłudze OneLake.
- Edytuj wykresy zgodnie z potrzebami i zapisz raport.
Wskazówka
Opcjonalnie możesz również użyć narzędzia Copilot lub innych ulepszeń do tworzenia pulpitów nawigacyjnych i raportów bez dalszego przenoszenia danych.
Treści powiązane
- Dowiedz się więcej o usłudze Cosmos DB w usłudze Microsoft Fabric
- Odwzorowanie OneLake w bazie danych Cosmos DB w Microsoft Fabric
- Uzyskiwanie dostępu do danych odwzorowanych z Cosmos DB w usłudze Lakehouse w Microsoft Fabric
- Zapytania dotyczące danych między bazami danych w Cosmos DB w Microsoft Fabric