Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Aby uzyskać ogólne informacje na temat wielowariancyjnego wykrywania anomalii w analizie w czasie rzeczywistym, zobacz Multivariate anomaly detection in Microsoft Fabric - overview (Wykrywanie anomalii wielowariancyjnych w usłudze Microsoft Fabric — omówienie). W tym samouczku użyjesz przykładowych danych do wytrenowania wielowymiarowego modelu wykrywania anomalii przy użyciu aparatu Spark w notatniku Pythona. Następnie przewidujesz anomalie, stosując wytrenowany model do nowych danych przy użyciu silnika usługi Eventhouse. Te pierwsze kroki konfigurują środowiska, a następujące kroki przeszkalają model i przewidują anomalie.
Wymagania wstępne
- Obszar roboczy z włączoną pojemnością usługi Microsoft Fabric
- Rola administratora, współautora lub członkaw obszarze roboczym. Ten poziom uprawnień jest wymagany do tworzenia elementów, takich jak środowisko.
- Magazyn zdarzeń w obszarze roboczym z bazą danych.
- Pobieranie przykładowych danych z repozytorium GitHub
- Pobierz notatnik z repozytorium GitHub
Część 1. Włączanie dostępności usługi OneLake
Przed pobraniem danych w magazynie zdarzeń należy włączyć dostępność usługi OneLake. Ten krok jest ważny, ponieważ umożliwia, aby dane, które wprowadzasz, stały się dostępne w usłudze OneLake. W późniejszym kroku uzyskujesz dostęp do tych samych danych z notesu platformy Spark, aby wytrenować model.
W obszarze roboczym wybierz Eventhouse, który utworzyłeś w ramach wymagań wstępnych. Wybierz bazę danych, w której chcesz przechowywać dane.
W okienku Szczegóły bazy danych przełącz przycisk dostępności OneLake na Włączony.

Część 2. Włączanie wtyczki Python KQL
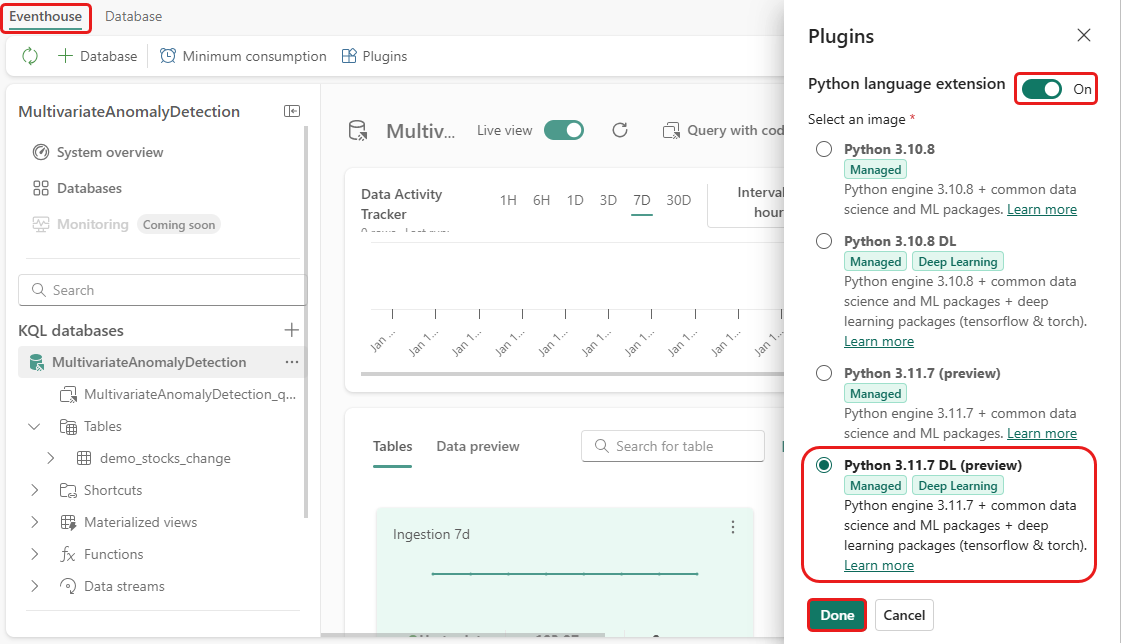
W tym kroku włączysz wtyczkę języka Python w usłudze Eventhouse. Ten krok jest wymagany do uruchomienia kodu Pythona do przewidywania anomalii w zestawie zapytań KQL. Ważne jest, aby wybrać prawidłowy obraz zawierający pakiet detektora anomalii szeregów czasowych .
Na ekranie Eventhouse wybierz Eventhouse Wtyczki na wstążce.
W okienku Wtyczki przełącz rozszerzenie języka Python nawłączony.
Wybierz pozycję Python 3.11.7 DL (wersja zapoznawcza).
Wybierz pozycję Gotowe.

Część 3. Tworzenie środowiska Spark
W tym kroku utworzysz środowisko Spark, aby uruchomić notebook języka Python, który trenuje wielowariantowy model wykrywania anomalii przy użyciu silnika Spark. Aby uzyskać więcej informacji na temat tworzenia środowisk, zobacz Tworzenie środowisk i zarządzanie nimi.
W obszarze roboczym wybierz pozycję + Nowy element , a następnie pozycję Środowisko.

Wprowadź nazwę MVAD_ENV dla środowiska, a następnie wybierz Utwórz.
W obszarze Biblioteki wybierz pozycję Biblioteki publiczne.
Wybierz Dodaj z PyPI.
W polu wyszukiwania wprowadź time-series-anomaly-detector. Pole wersji jest wypełniane automatycznie najnowszą wersją. Zmień na wersję 0.3.9, która jest najnowszą wersją zgodną z biblioteką MLflow 2.19.0 (aktualna wersja w obrazie języka Python)
Wybierz pozycję Zapisz.

Wybierz kartę Narzędzia główne w środowisku.
Wybierz ikonę Publikuj na wstążce.

Wybierz opcję Publikuj wszystko. Wykonanie tego kroku może potrwać kilka minut.



Część 4. Pobieranie danych do usługi Eventhouse
Umieść kursor na bazie danych KQL, w której chcesz przechowywać dane. Wybierz menu Więcej [...]>Pobierz dane>Plik lokalny.

Wybierz pozycję + Nowa tabela i wprowadź demo_stocks_change jako nazwę tabeli.
W okienku dialogowym przekazywania danych wybierz opcję Przeglądaj pliki i prześlij przykładowy plik danych pobrany w sekcji Wymagania wstępne.
Wybierz Dalej.
W sekcji Inspekcja danych sprawdź, czy Pierwszy wiersz to nagłówek kolumny jest ustawiony na Włącz.
Wybierz Zakończ.
Po przekazaniu danych wybierz pozycję Zamknij.
Część 5 - Skopiuj ścieżkę OneLake do tabeli
Upewnij się, że wybrano tabelę demo_stocks_change. W okienku Szczegóły tabeli wybierz folder OneLake, aby skopiować ścieżkę OneLake do schowka. Zapisz ten skopiowany tekst w edytorze tekstów, który ma być używany w późniejszym kroku.

Część 6. Przygotuj notatnik
Wybierz obszar roboczy.
Wybierz Importuj, Notatnik, a następnie Z tego komputera.
Wybierz Prześlij, a następnie wybierz notes pobrany w ramach wymagań wstępnych.
Po przesłaniu notatnika możesz znaleźć i otworzyć go ze swojego obszaru roboczego.
Na górnej wstążce wybierz listę rozwijaną domyślny obszar roboczy i wybierz środowisko utworzone w poprzednim kroku.

Część 7. Uruchamianie notatnika
Importuj standardowe pakiety.
import numpy as np import pandas as pdPlatforma Spark wymaga identyfikatora URI ABFSS, aby bezpiecznie nawiązać połączenie z magazynem OneLake, więc następny krok definiuje tę funkcję w celu przekonwertowania identyfikatora URI usługi OneLake na identyfikator URI ABFSS.
def convert_onelake_to_abfss(onelake_uri): if not onelake_uri.startswith('https://'): raise ValueError("Invalid OneLake URI. It should start with 'https://'.") uri_without_scheme = onelake_uri[8:] parts = uri_without_scheme.split('/') if len(parts) < 3: raise ValueError("Invalid OneLake URI format.") account_name = parts[0].split('.')[0] container_name = parts[1] path = '/'.join(parts[2:]) abfss_uri = f"abfss://{container_name}@{parts[0]}/{path}" return abfss_uriZastąp symbol zastępczy OneLakeTableURI ścieżką URI OneLake skopiowaną z Część 5 - Skopiuj ścieżkę OneLake do tabeli, aby załadować tabelę demo_stocks_change do pandas DataFrame.
onelake_uri = "OneLakeTableURI" # Replace with your OneLake table URI abfss_uri = convert_onelake_to_abfss(onelake_uri) print(abfss_uri)df = spark.read.format('delta').load(abfss_uri) df = df.toPandas().set_index('Date') print(df.shape) df[:3]Uruchom następujące komórki, aby przygotować ramki danych trenowania i przewidywania.
Uwaga
Rzeczywiste przewidywania zostaną uruchomione na danych przez Eventhouse w części 9 - Przewidywanie-anomalii-w-zbiorze-zapytań-kql. W scenariuszu produkcyjnym w przypadku przesyłania strumieniowego danych do magazynu zdarzeń przewidywania będą wykonywane na nowych danych przesyłanych strumieniowo. Na potrzeby samouczka zestaw danych został podzielony według daty na dwie sekcje na potrzeby trenowania i przewidywania. Jest to symulacja danych historycznych i nowych danych przesyłanych strumieniowo.
features_cols = ['AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'] cutoff_date = pd.to_datetime('2023-01-01')train_df = df[df.Date < cutoff_date] print(train_df.shape) train_df[:3]train_len = len(train_df) predict_len = len(df) - train_len print(f'Total samples: {len(df)}. Split to {train_len} for training, {predict_len} for testing')Uruchom komórki, aby wytrenować model i zapisać go w rejestrze modeli Fabric MLflow.
from anomaly_detector import MultivariateAnomalyDetector model = MultivariateAnomalyDetector()sliding_window = 200 param s = {"sliding_window": sliding_window}model.fit(train_df, params=params)model_name = "mvad_5_stocks_model"import mlflow with mlflow.start_run(): mlflow.log_params(params) mlflow.set_tag("Training Info", "MVAD on 5 Stocks Dataset") model_info = mlflow.pyfunc.log_model( python_model=model, artifact_path="mvad_artifacts", registered_model_name=model_name, )Uruchom następującą komórkę, aby wyodrębnić zarejestrowaną ścieżkę modelu do użycia w przewidywaniu w piaskownicy Kusto dla Pythona.
from mlflow.tracking import MlflowClient client = MlflowClient() mvs = client.search_model_versions(f"name='{model_name}'") latest = max(mvs, key=lambda v: v.creation_timestamp) model_abfss = latest.source print(model_abfss)Skopiuj identyfikator URI modelu z ostatnich danych wyjściowych komórki do użycia w późniejszym kroku.
Część 8. Konfigurowanie zestawu zapytań KQL
Aby uzyskać ogólne informacje, zobacz Tworzenie zestawu zapytań KQL.
- W obszarze roboczym wybierz +Nowy element>zestaw zapytań KQL.
- Wprowadź nazwę MultivariateAnomalyDetectionTutorial, a następnie wybierz pozycję Utwórz.
- W oknie centrum danych OneLake wybierz bazę danych KQL, w której są przechowywane dane.
- Wybierz pozycję Połącz.
Część 9. Przewidywanie anomalii w zestawie zapytań KQL
Uruchom następujące zapytanie ".create-or-alter function", aby zdefiniować funkcję przechowywaną
predict_fabric_mvad_fl():.create-or-alter function with (folder = "Packages\\ML", docstring = "Predict MVAD model in Microsoft Fabric") predict_fabric_mvad_fl(samples:(*), features_cols:dynamic, artifacts_uri:string, trim_result:bool=false) { let s = artifacts_uri; let artifacts = bag_pack('MLmodel', strcat(s, '/MLmodel;impersonate'), 'conda.yaml', strcat(s, '/conda.yaml;impersonate'), 'requirements.txt', strcat(s, '/requirements.txt;impersonate'), 'python_env.yaml', strcat(s, '/python_env.yaml;impersonate'), 'python_model.pkl', strcat(s, '/python_model.pkl;impersonate')); let kwargs = bag_pack('features_cols', features_cols, 'trim_result', trim_result); let code = ```if 1: import os import shutil import mlflow model_dir = 'C:/Temp/mvad_model' model_data_dir = model_dir + '/data' os.mkdir(model_dir) shutil.move('C:/Temp/MLmodel', model_dir) shutil.move('C:/Temp/conda.yaml', model_dir) shutil.move('C:/Temp/requirements.txt', model_dir) shutil.move('C:/Temp/python_env.yaml', model_dir) shutil.move('C:/Temp/python_model.pkl', model_dir) features_cols = kargs["features_cols"] trim_result = kargs["trim_result"] test_data = df[features_cols] model = mlflow.pyfunc.load_model(model_dir) predictions = model.predict(test_data) predict_result = pd.DataFrame(predictions) samples_offset = len(df) - len(predict_result) # this model doesn't output predictions for the first sliding_window-1 samples if trim_result: # trim the prefix samples result = df[samples_offset:] result.iloc[:,-4:] = predict_result.iloc[:, 1:] # no need to copy 1st column which is the timestamp index else: result = df # output all samples result.iloc[samples_offset:,-4:] = predict_result.iloc[:, 1:] ```; samples | evaluate python(typeof(*), code, kwargs, external_artifacts=artifacts) }Uruchom następujące zapytanie przewidywania, zastępując identyfikator URI modelu wynikowego identyfikatorem URI skopiowanym na końcu kroku 7.
Zapytanie wykrywa anomalie wielowymiarowe w pięciu akcjach na podstawie wytrenowanego modelu i renderuje wyniki jako
anomalychart. Nietypowe punkty są renderowane na pierwszej akcji (AAPL), choć reprezentują anomalie wielowymiarowe (innymi słowy, anomalie wspólnych zmian pięciu akcji w określonej dacie).let cutoff_date=datetime(2023-01-01); let num_predictions=toscalar(demo_stocks_change | where Date >= cutoff_date | count); // number of latest points to predict let sliding_window=200; // should match the window that was set for model training let prefix_score_len = sliding_window/2+min_of(sliding_window/2, 200)-1; let num_samples = prefix_score_len + num_predictions; demo_stocks_change | top num_samples by Date desc | order by Date asc | extend is_anomaly=bool(false), score=real(null), severity=real(null), interpretation=dynamic(null) | invoke predict_fabric_mvad_fl(pack_array('AAPL', 'AMZN', 'GOOG', 'MSFT', 'SPY'), // NOTE: Update artifacts_uri to model path artifacts_uri='enter your model URI here', trim_result=true) | summarize Date=make_list(Date), AAPL=make_list(AAPL), AMZN=make_list(AMZN), GOOG=make_list(GOOG), MSFT=make_list(MSFT), SPY=make_list(SPY), anomaly=make_list(toint(is_anomaly)) | render anomalychart with(anomalycolumns=anomaly, title='Stock Price Changest in % with Anomalies')
Wynikowy wykres anomalii powinien wyglądać jak na poniższej ilustracji:

Czyszczenie zasobów
Po ukończeniu samouczka możesz usunąć utworzone zasoby, aby uniknąć ponoszenia innych kosztów. Aby usunąć zasoby, wykonaj następujące kroki:
- Wejdź na stronę główną obszaru roboczego.
- Usuń środowisko utworzone w tym samouczku.
- Usuń notatnik utworzony w tym samouczku.
- Usuń magazyn zdarzeń lub bazę danych używaną w tym samouczku.
- Usuń zestaw zapytań KQL utworzony w tym samouczku.