Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Język zapytań Kusto (KQL) ma wbudowane funkcje wykrywania anomalii i prognozowania w celu sprawdzania nietypowego zachowania. Po wykryciu takiego wzorca można uruchomić analizę głównej przyczyny w celu ograniczenia lub rozwiązania anomalii.
Proces diagnostyki jest złożony i długotrwały i wykonywany przez ekspertów z dziedziny. Proces obejmuje:
- Pobieranie i dołączanie większej ilości danych z różnych źródeł dla tego samego przedziału czasu
- Wyszukiwanie zmian w rozkładie wartości w wielu wymiarach
- Wykresowanie większej liczby zmiennych
- Inne techniki oparte na wiedzy i intuicji domeny
Ponieważ te scenariusze diagnostyczne są typowe, dostępne są wtyczki do uczenia maszynowego z myślą o ułatwieniu fazy diagnostycznej i skróceniu czasu trwania analizy przyczyn źródłowych.
Wszystkie trzy z następujących wtyczek usługi Machine Learning implementują algorytmy klastrowania: autocluster, basketi diffpatterns. Wtyczki autocluster i basket klastrują jeden zestaw rekordów, a wtyczka diffpatterns klastruje różnice między dwoma zestawami rekordów.
Klastrowanie pojedynczego zestawu rekordów
Typowy scenariusz obejmuje zestaw danych wybrany przez określone kryteria, takie jak:
- Przedział czasu pokazujący nietypowe zachowanie
- Odczyty urządzeń o wysokiej temperaturze
- Polecenia o długim czasie trwania
- Użytkownicy z najwyższymi wydatkami
Potrzebujesz szybkiego i łatwego sposobu znajdowania typowych wzorców (segmentów) w danych. Wzorce to podzbiór zestawu danych, którego rekordy współdzielą te same wartości w wielu wymiarach (kolumny podzielone na kategorie).
Następujące zapytanie buduje i przedstawia szereg czasowy wyjątków serwisowych w okresie tygodnia, w przedziałach dziesięciominutowych.
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m
| render timechart with(title="Service exceptions over a week, 10 minutes resolution")

Liczba wyjątków usługi jest skorelowana z ogólnym ruchem usługi. Można wyraźnie zobaczyć dzienny wzorzec dni roboczych, od poniedziałku do piątku. Odnotowuje się wzrost liczby wyjątków w usługach w południe i spadki liczby w nocy. Stałe niskie liczby są widoczne podczas weekendu. Skoki wyjątków można wykryć za pomocą wykrywania anomalii szeregów czasowych.
Drugi skok w danych występuje we wtorek po południu. Poniższe zapytanie służy do dalszej diagnostyki i sprawdzania, czy jest to gwałtowny wzrost. Zapytanie ponownie rysuje wykres wokół skoku w wyższej rozdzielczości ośmiu godzin w jednominutowych przedziałach. Następnie możesz zbadać granice wykresu.
let min_t=datetime(2016-08-23 11:00);
demo_clustering1
| make-series num=count() on PreciseTimeStamp from min_t to min_t+8h step 1m
| render timechart with(title="Zoom on the 2nd spike, 1 minute resolution")

Zobaczysz wąski skok trwający dwie minuty, od 15:00 do 15:02. W poniższym zapytaniu zlicz wyjątki w tym dwuminutowym oknie:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| count
| Liczba |
|---|
| 972 |
W poniższym zapytaniu wybierz 20 próbnych wyjątków z 972:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| take 20
| PrecyzyjnyZnacznikCzasu | Rejon | ScaleUnit | Identyfikator wdrożenia | Punkt śledzenia | ServiceHost |
|---|---|---|---|---|---|
| 2016-08-23 15:00:08.7302460 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:09.9496584 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 8d257da1-7a1c-44f5-9acd-f9e02ff507fd |
| 2016-08-23 15:00:10.5911748 | brak kontekstu dla terminu 'scus' (potrzebne wyjaśnienie lub tłumaczenie) | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 100005 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:12.2957912 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | f855fcef-ebfe-405d-aaf8-9c5e2e43d862 |
| 2016-08-23 15:00:18.5955357 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 9d390e07-417d-42eb-bebd-793965189a28 |
| 2016-08-23 15:00:20.7444854 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 6e54c1c8-42d3-4e4e-8b79-9bb076ca71f1 |
| 2016-08-23 15:00:23.8694999 | eus2 | su2 | 89e2f62a73bb4efd8f545aee40d7e51 | 36109 | 1942243-19b9-4d85-9ca6-bc961861d287 |
| 2016-08-23 15:00:26.4271786 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 36109 | 3271bae4-1c5b-4f73-98ef-cc117e9be914 |
| 2016-08-23 15:00:27.8958124 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 904498 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:32.9884969 | Since "scus" lacks sufficient context, no definitive improved translation can be proposed without further clarification. If more information is provided, a suitable improvement might be suggested. | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007007 | d5c7c825-9d46-4ab7-a0c1-8e2ac1d83ddb |
| 2016-08-23 15:00:34.5061623 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:37.4490273 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | f2ee8254-173c-477d-a1de-4902150ea50d |
| 2016-08-23 15:00:41.2431223 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 103200 | 8cf38575-fca9-48ca-bd7c-21196f6d6765 |
| 2016-08-23 15:00:47.2983975 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | 423690590 | 00000000-0000-0000-0000-000000000000 |
| 2016-08-23 15:00:50.5932834 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007006 | 2a41b552-aa19-4987-8cdd-410a3af016ac |
| 2016-08-23 15:00:50.8259021 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 1002110 | 0d56b8e3-470d-4213-91da-97405f8d005e |
| 2016-08-23 15:00:53.2490731 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 36109 | 55a71811-5ec4-497a-a058-140fb0d611ad |
| 2016-08-23 15:00:57.0000946 | eus2 | su2 | 89e2f62a73bb4efd8f545aee40d7e51 | 64038 | cb55739e-4afe-46a3-970f-1b49d8ee7564 |
| 2016-08-23 15:00:58.2222707 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | 10007007 | 8215dcf6-2de0-42bd-9c90-181c70486c9c |
| 2016-08-23 15:00:59.9382620 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | 10007006 | 451e3c4c-0808-4566-a64d-84d85cf30978 |
Mimo że istnieje mniej niż tysiąc wyjątków, nadal trudno jest znaleźć typowe segmenty, ponieważ w każdej kolumnie istnieje wiele wartości. Możesz użyć wtyczki autocluster(), aby natychmiast wyodrębnić krótką listę typowych segmentów i znaleźć interesujące klastry w przeciągu dwóch minut szczytu, jak pokazano w poniższym zapytaniu:
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate autocluster()
| Identyfikator segmentu | Liczba | Procent | Rejon | ScaleUnit | Identyfikator wdrożenia | ServiceHost |
|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 1 | 94 | 9.67078189300411 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | |
| 2 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 3 | 68 | 6.99588477366255 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | |
| 4 | 55 | 5,65843621399177 | Uze | su4 | be1d6d7ac9574cbc9a22cb8eee20f16fc |
W powyższych wynikach widać, że najbardziej dominujący segment zawiera 65,74% wszystkich rekordów wyjątków i ma cztery wymiary wspólne. Następny segment jest znacznie mniej popularny. Zawiera tylko 9,67% spośród wszystkich rekordów i współdzieli trzy wymiary. Inne segmenty są jeszcze mniej powszechne.
Autocluster wykorzystuje zastrzeżony algorytm do eksploracji wielowymiarowych danych i wyodrębniania ciekawych segmentów. "Interesujące" oznacza, że każdy segment ma znaczne pokrycie zarówno zestawu rekordów, jak i zestawu funkcji. Segmenty są również rozbieżne, co oznacza, że każdy z nich różni się od innych. Co najmniej jeden z tych segmentów może być odpowiedni dla procesu analizy przyczyny źródłowej. Aby zminimalizować przegląd segmentów i ocenę, funkcja autoklastrowania wyodrębnia tylko małą listę segmentów.
Możesz również skorzystać z wtyczki basket(), jak pokazano w poniższym zapytaniu.
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
demo_clustering1
| where PreciseTimeStamp between(min_peak_t..max_peak_t)
| evaluate basket()
| Identyfikator segmentu | Liczba | Procent | Rejon | ScaleUnit | Identyfikator wdrożenia | Punkt śledzenia | ServiceHost |
|---|---|---|---|---|---|---|---|
| 0 | 639 | 65.7407407407407 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | e7f60c5d-4944-42b3-922a-92e98a8e7dec | |
| 1 | 642 | 66.0493827160494 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | ||
| 2 | 324 | 33.3333333333333 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | 0 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 3 | 315 | 32.4074074074074 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | 16108 | e7f60c5d-4944-42b3-922a-92e98a8e7dec |
| 4 | 328 | 33.7448559670782 | 0 | ||||
| 5 | 94 | 9.67078189300411 | scus | su5 | 9dbd1b161d5b4779a73cf19a7836ebd6 | ||
| 6 | 82 | 8.43621399176955 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | ||
| 7 | 68 | 6.99588477366255 | scus | su3 | 90d3d2fc7ecc430c9621ece335651a01 | ||
| 8 | 167 | 17.1810699588477 | scus | ||||
| 9 | 55 | 5,65843621399177 | Uze | su4 | be1d6d7ac9574cbc9a22cb8eee20f16fc | ||
| 10 | 92 | 9.46502057613169 | 10007007 | ||||
| 11 | 90 | 9,25925925925926 | 10007006 | ||||
| 12 | 57 | 5.8641975308642 | 00000000-0000-0000-0000-000000000000 |
Koszyk implementuje algorytm "Apriori" na potrzeby analizy zestawów elementów. Wyodrębnia wszystkie segmenty, których pokrycie zestawu rekordów przekracza próg (domyślnie 5%). Widać, że więcej segmentów zostało wyodrębnionych z podobnymi segmentami, takimi jak segmenty 0, 1 lub 2, 3.
Obie wtyczki są wydajne i łatwe w użyciu. Ich ograniczenie polega na tym, że klasteruje pojedynczy zestaw rekordów w sposób nienadzorowany bez etykiet. Nie jest jasne, czy wyodrębnione wzorce scharakteryzują wybrany zestaw rekordów, nietypowe rekordy lub globalny zestaw rekordów.
Klastrowanie różnicy między dwoma zestawami rekordów
Wtyczka diffpatterns() przezwycięża ograniczenia autocluster i basket.
Diffpatterns przyjmuje dwa zestawy rekordów i wyodrębnia główne segmenty, które są różne. Jeden zestaw zwykle zawiera nietypowy zestaw rekordów, który jest badany. Jeden z nich jest analizowany przez autocluster i basket. Drugi zestaw zawiera zestaw rekordów referencyjnych, punkt odniesienia.
W poniższym zapytaniu diffpatterns znajduje interesujące klastry w ciągu dwóch minut trwania szczytu, które różnią się od klastrów w odniesieniu do wartości bazowej. Czas bazowy jest definiowany jako osiem minut przed godziną 15:00, w momencie rozpoczęcia skoku. Rozszerzysz kolumnę binarną (AB) i określ, czy określony rekord należy do punktu odniesienia, czy też do nietypowego zestawu.
Diffpatterns implementuje algorytm uczenia nadzorowanego, w którym dwie etykiety klas zostały wygenerowane przez anomalię w porównaniu z flagą punktu odniesienia (AB).
let min_peak_t=datetime(2016-08-23 15:00);
let max_peak_t=datetime(2016-08-23 15:02);
let min_baseline_t=datetime(2016-08-23 14:50);
let max_baseline_t=datetime(2016-08-23 14:58); // Leave a gap between the baseline and the spike to avoid the transition zone.
let splitime=(max_baseline_t+min_peak_t)/2.0;
demo_clustering1
| where (PreciseTimeStamp between(min_baseline_t..max_baseline_t)) or
(PreciseTimeStamp between(min_peak_t..max_peak_t))
| extend AB=iff(PreciseTimeStamp > splitime, 'Anomaly', 'Baseline')
| evaluate diffpatterns(AB, 'Anomaly', 'Baseline')
| Identyfikator segmentu | CountA | LiczbaB | PercentA | Procent | RóżnicaProcentowaAB | Rejon | ScaleUnit | Identyfikator wdrożenia | Punkt śledzenia |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 639 | dwadzieścia jeden | 65.74 | 1,7 | 64.04 | Eau | su7 | b5d1d4df547d4a04ac15885617edba57 | |
| 1 | 167 | 544 | 17.18 | 44.16 | 26.97 | scus | |||
| 2 | 92 | 356 | 9.47 | 28.9 | 19.43 | 10007007 | |||
| 3 | 90 | 336 | 9.26 | 27.27 | 18.01 | 10007006 | |||
| 4 | 82 | 318 | 8.44 | 25,81 | 17.38 | ncus | su1 | e24ef436e02b4823ac5d5b1465a9401e | |
| 5 | 55 | 252 | 5.66 | 20.45 | 14.8 | Uze | su4 | be1d6d7ac9574cbc9a22cb8eee20f16fc | |
| 6 | 57 | 204 | 5.86 | 16.56 | 10.69 |
Najbardziej dominującym segmentem jest ten sam segment, który został wyodrębniony przez autocluster. Pokrycie w anomalnym dwuminutowym oknie wynosi również 65,74%. Jednak jego pokrycie w ośmiominutowym oknie punktu odniesienia wynosi tylko 1,7%. Różnica wynosi 64,04%. Ta różnica wydaje się być związana z nietypowym wzrostem. Aby zweryfikować to założenie, następujące zapytanie dzieli oryginalny wykres na rekordy należące do tego problematycznego segmentu i rekordy z innych segmentów.
let min_t = toscalar(demo_clustering1 | summarize min(PreciseTimeStamp));
let max_t = toscalar(demo_clustering1 | summarize max(PreciseTimeStamp));
demo_clustering1
| extend seg = iff(Region == "eau" and ScaleUnit == "su7" and DeploymentId == "b5d1d4df547d4a04ac15885617edba57"
and ServiceHost == "e7f60c5d-4944-42b3-922a-92e98a8e7dec", "Problem", "Normal")
| make-series num=count() on PreciseTimeStamp from min_t to max_t step 10m by seg
| render timechart
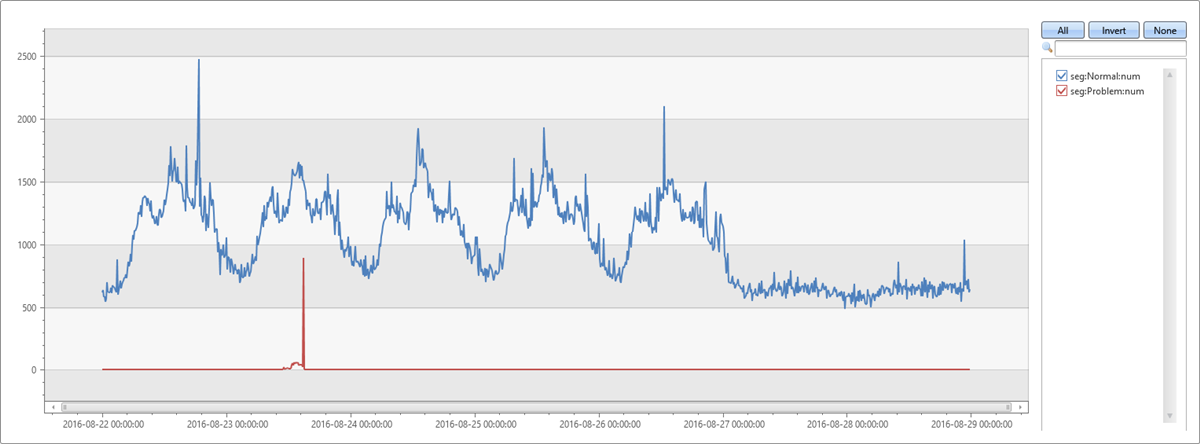
Ten wykres pozwala nam zobaczyć, że wzrost we wtorek po południu był spowodowany wyjątkami z tego konkretnego segmentu, wykrytymi za pomocą wtyczki diffpatterns.
Podsumowanie
Wtyczki usługi Machine Learning są przydatne w wielu scenariuszach.
autocluster i basket implementują algorytm uczenia nienadzorowanego i są łatwe w użyciu.
Diffpatterns implementuje algorytm uczenia nadzorowanego i, choć bardziej złożony, jest bardziej efektywny do wyodrębniania segmentów różnicowania dla Analizy Przyczyn Pierwotnych.
Te wtyczki są używane interaktywnie w scenariuszach ad hoc i w automatycznych usługach monitorowania niemal w czasie rzeczywistym. Po wykryciu anomalii szeregów czasowych następuje proces diagnostyki. Proces jest wysoce zoptymalizowany pod kątem spełnienia niezbędnych standardów wydajności.