Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Użyj usługi Azure Synapse Link, aby połączyć dane usługi Microsoft Dataverse z usługą Azure Synapse Analytics, aby eksplorować dane i skracać czas analizy. W tym artykule przedstawiono sposób uruchamiania potoków usługi Azure Synapse lub usługi Azure Data Factory w celu kopiowania danych z usługi Azure Data Lake Storage Gen2 do usługi Azure SQL Database z włączoną funkcją aktualizacji przyrostowych w usłudze Azure Synapse Link.
Uwaga / Notatka
Usługa Azure Synapse Link dla Microsoft Dataverse była wcześniej znana jako Eksportowanie do Data Lake. Nazwa usługi została zmieniona, obowiązująca od maja 2021 r., i będzie nadal eksportować dane do usługi Azure Data Lake, a także usługi Azure Synapse Analytics. Ten szablon jest przykładem kodu. Zachęcamy do użycia tego szablonu jako wytycznych, aby przetestować funkcjonalność pobierania danych z usługi Azure Data Lake Storage Gen2 do usługi Azure SQL Database za pomocą udostępnionego potoku.
Wymagania wstępne
- Usługa Azure Synapse Link dla usługi Dataverse. W tym przewodniku założono, że spełniono już wymagania wstępne dotyczące tworzenia usługi Azure Synapse Link z usługą Azure Data Lake. Więcej informacji: Wymagania wstępne dotyczące usługi Azure Synapse Link dla usługi Dataverse w usłudze Azure Data Lake
- Utwórz obszar roboczy usługi Azure Synapse Workspace lub usługę Azure Data Factory w ramach tego samego dzierżawcy usługi Microsoft Entra co dzierżawca usługi Power Apps.
- Utwórz usługę Azure Synapse Link dla usługi Dataverse z włączoną przyrostową aktualizacją folderów w celu ustawienia interwału czasu. Więcej informacji: Wykonywanie zapytań i analizowanie aktualizacji przyrostowych
- Dostawca Microsoft.EventGrid musi być zarejestrowany dla wyzwalacza. Więcej informacji: Azure Portal. Uwaga: Jeśli używasz tej funkcji w usłudze Azure Synapse Analytics, upewnij się, że subskrypcja jest również zarejestrowana u dostawcy zasobów usługi Data Factory. W przeciwnym razie zostanie wyświetlony błąd z informacją, że tworzenie subskrypcji zdarzeń nie powiodło się.
- Utwórz bazę danych Azure SQL Database z włączoną właściwością Zezwalaj usługom i zasobom platformy Azure na dostęp do tej właściwości serwera . Więcej informacji: Co należy wiedzieć podczas konfigurowania usługi Azure SQL Database (PaaS)?
- Tworzenie i konfigurowanie środowiska Azure Integration Runtime. Więcej informacji: Tworzenie środowiska Azure Integration Runtime — Azure Data Factory i Azure Synapse
Ważne
Użycie tego szablonu może wiązać się z dodatkowymi kosztami. Te koszty są związane z użyciem Azure Data Factory lub obszaru roboczego Synapse i są naliczane co miesiąc. Koszt korzystania z potoków w dużej mierze zależy od czasu aktualizacji i ilości danych. Aby zaplanować i zarządzać kosztem korzystania z tej funkcji, należy przejść do tematu: Monitorowanie kosztów na poziomie potoku przy użyciu analizy kosztów
Ważne jest, aby wziąć pod uwagę te dodatkowe koszty podczas podejmowania decyzji o użyciu tego szablonu, ponieważ nie są one opcjonalne i muszą być wypłacane, aby nadal korzystać z tej funkcji.
Korzystanie z szablonu rozwiązania
- Przejdź do witryny Azure Portal i otwórz obszar roboczy usługi Azure Synapse.
- Wybierz pozycję Integruj>Przeglądaj galerię.
- Wybierz Kopiuj dane usługi Dataverse do usługi Azure SQL przy użyciu usługi Synapse Link z galerii integracji.
Konfigurowanie szablonu rozwiązania
Utwórz połączoną usługę z usługą Azure Data Lake Storage Gen2, która jest połączona z usługą Dataverse przy użyciu odpowiedniego typu uwierzytelniania. W tym celu wybierz pozycję Testuj połączenie, aby zweryfikować łączność, a następnie wybierz pozycję Utwórz.
Podobnie jak w poprzednich krokach, utwórz połączoną usługę z usługą Azure SQL Database, w której będą synchronizowane dane usługi Dataverse.
Po skonfigurowaniu danych wejściowych wybierz pozycję Użyj tego szablonu.

Teraz można dodać wyzwalacz, aby zautomatyzować ten potok, dzięki czemu potok może zawsze przetwarzać pliki, gdy aktualizacje przyrostowe są wykonywane okresowo. Przejdź do obszaru Zarządzanie>wyzwalaczem i utwórz wyzwalacz przy użyciu następujących właściwości:
- Nazwa: wprowadź nazwę wyzwalacza, na przykład triggerModelJson.
- Typ: Zdarzenia przechowywania.
- Subskrypcja platformy Azure: wybierz subskrypcję z usługą Azure Data Lake Storage Gen2.
- Nazwa konta magazynu: wybierz magazyn zawierający dane usługi Dataverse.
- Nazwa kontenera: wybierz kontener utworzony przez usługę Azure Synapse Link.
- Ścieżka obiektu blob kończy się na: /model.json
- Zdarzenie: Utworzony Blob.
- Zignoruj puste obiekty blob: Tak.
- Wyzwalacz uruchomienia: Włącz wyzwalacz uruchomienia podczas tworzenia.
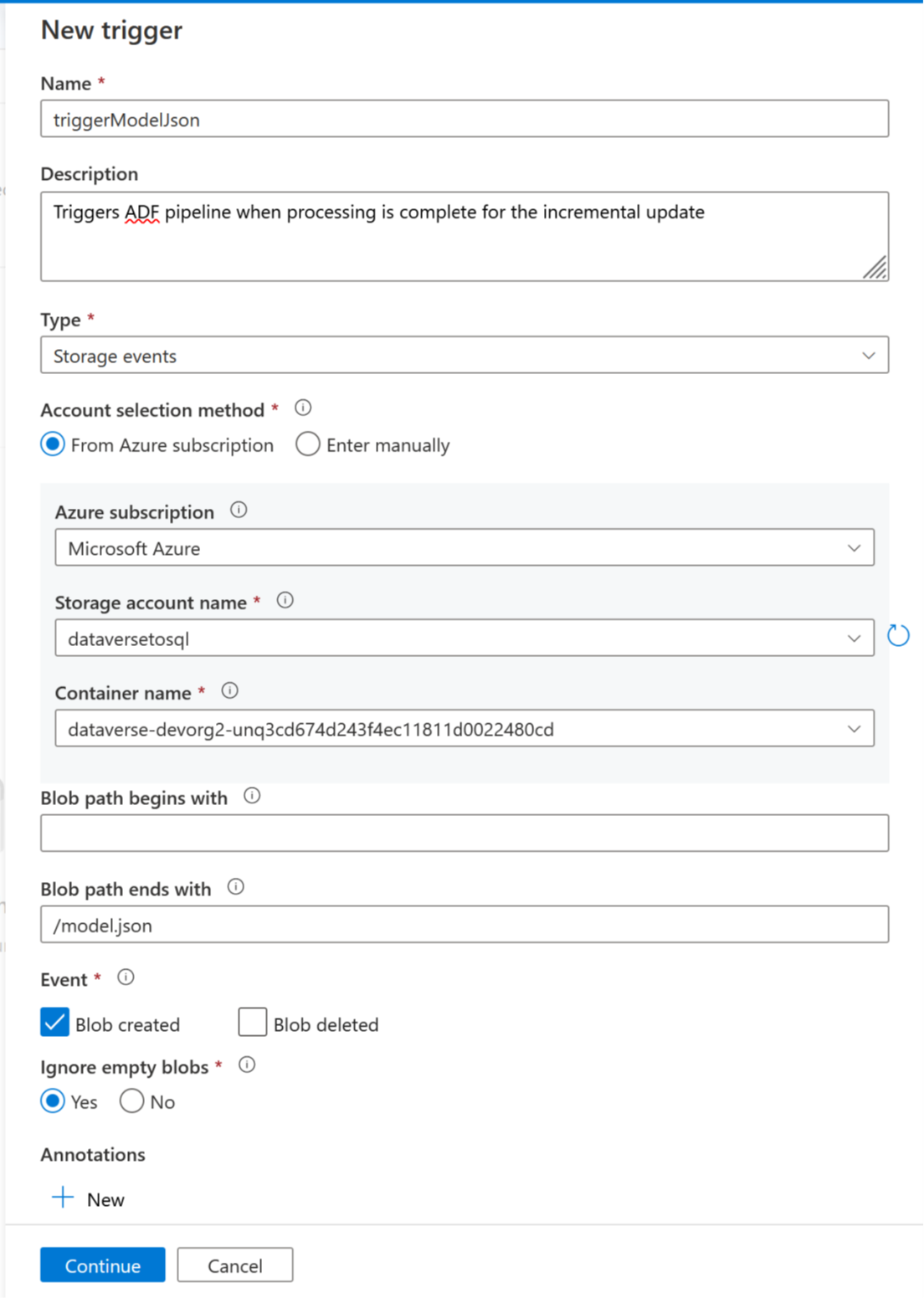
Wybierz pozycję Kontynuuj , aby przejść do następnego ekranu.
Na następnym ekranie wyzwalacz weryfikuje pasujące pliki. Wybierz przycisk OK , aby utworzyć wyzwalacz.
Skojarz wyzwalacz z potoku. Przejdź do zaimportowanego wcześniej potoku, a następnie wybierz Dodaj wyzwalacz>Nowy/Edytuj.

Wybierz wyzwalacz we wcześniejszym kroku, a następnie wybierz pozycję Kontynuuj , aby przejść do następnego ekranu, na którym wyzwalacz weryfikuje pasujące pliki.
Wybierz pozycję Kontynuuj , aby przejść do następnego ekranu.
W sekcji Trigger Run Parameter (Parametr przebiegu wyzwalacza ) wprowadź poniższe parametry, a następnie wybierz przycisk OK.
-
Kontener:
@split(triggerBody().folderPath,'/')[0] -
Folder:
@split(triggerBody().folderPath,'/')[1]
-
Kontener:
Po skonfigurowaniu powiązania wyzwalacza z potokiem wybierz pozycję Zweryfikuj wszystkie.
Po pomyślnym zakończeniu walidacji wybierz pozycję Opublikuj wszystko.

Wybierz pozycję Publikuj, aby opublikować wszystkie zmiany.



Dodawanie filtru subskrypcji zdarzeń
Aby upewnić się, że wyzwalacz jest uruchamiany tylko po zakończeniu tworzenia model.json, należy zaktualizować zaawansowane filtry dla subskrypcji zdarzeń wyzwalacza. Zdarzenie jest rejestrowane na koncie magazynu przy pierwszym uruchomieniu wyzwalacza.
Po zakończeniu przebiegu wyzwalacza przejdź do konta magazynu >Wydarzenia>Subskrypcje zdarzeń.
Wybierz zdarzenie zarejestrowane dla wyzwalacza model.json.

Wybierz kartę Filtry , a następnie wybierz pozycję Dodaj nowy filtr.

Utwórz filtr:
- Klucz: temat
- Operator: ciąg nie kończy się na
- Wartość: /blobs/model.json
Usuń parametr CopyBlob z tablicy data.apiValue .
Wybierz pozycję Zapisz , aby wdrożyć dodatkowy filtr.
