Note
Tworzenie wszystkich danych przygotowywania dla funkcji sztucznej inteligencji nie jest dostępne zarówno w usłudze Power BI, jak i programie Power BI Desktop. Użycie tych funkcji jest dostępne wszędzie, gdzie istnieje Copilot.
Funkcje narzędzi
Jakie funkcje usługi Power BI mają dzisiaj, aby ułatwić przygotowanie moich danych do rozwiązania Copilot?
Obecnie usługa Power BI oferuje cztery główne funkcje narzędzi umożliwiające skonfigurowanie modelu tak, aby był gotowy do przetwarzania języka naturalnego:
- Schemat danych sztucznej inteligencji: umożliwia wybranie podzbioru schematu dla użycia rozwiązania Copilot.
- Zweryfikowane odpowiedzi: skonfigurowana odpowiedź ustawiona przez autora modelu, która jest weryfikowana pod kątem dokładności i niezawodności. Autorzy mogą ustawić określone wizualizacje dla copilot do użycia w zweryfikowanej odpowiedzi, gdy użytkownik zadaje pytanie należące do przypisanej kategorii.
- Instrukcje dotyczące sztucznej inteligencji: instrukcje, które można ustawić na modelu, aby zapewnić więcej kontekstu danych w modelu, przewodnik pomocy dla Copilot, aby zrozumieć, kiedy należy skoncentrować się na danych i pomóc zrozumieć niektóre mapowania, których użytkownicy języka mogą używać podczas interakcji z Copilot.
- Opisy: Opisy ustawione dla tabel i kolumn, aby uzyskać więcej szczegółów na temat kontekstu danych. Opisy są używane tylko w wyrażeniach analizy danych (DAX) q zapytań i funkcji wyszukiwania Copilot.
W jakiej kolejności należy zaimplementować funkcje narzędzi copilot usługi Power BI?
Aby uzyskać największą wartość z usługi Power BI Copilot, zalecamy zaimplementowanie jej funkcji narzędzi w następującej kolejności:
Zdefiniuj schemat danych sztucznej inteligencji.
Zacznij od wybrania określonych tabel, pól i miar Copilot powinien odwoływać się podczas odpowiadania na pytania dotyczące danych.
Podczas tworzenia modelu można uwzględnić elementy, które nie są istotne dla zapytań użytkowników końcowych. Zawężenie schematu pomaga Copilot skupić się na najbardziej znaczących częściach modelu, zmniejszając niejednoznaczność — szczególnie w przypadku dużych zestawów danych z nakładającymi się lub podobnie nazwanymi polami.
Oto przykład sposobu, w jaki schemat danych sztucznej inteligencji może pomóc Copilot skupić się na odpowiednich danych.
Gdy cały schemat jest używany, copilot nie zawsze jest jasne w intencji użytkownika, gdy mówią o sprzedaży. W tym przypadku Copilot zwrócił GPM lub marżę zysku brutto, wiarygodną interpretację sprzedaży, ale nie metrykę, która jest zwykle używana przez ten zespół do analizowania sprzedaży.
Autor modelu przechodzi do przygotowywania danych dla sztucznej inteligencji i usuwa miarę Total GPM z dołączania do schematu przekazanego do Copilot.
Teraz, gdy użytkownik zadaje to samo pytanie, Copilot ma większą jasność co do tego, skąd uzyskać odpowiedź i poprawnie interpretuje sprzedaż zgodnie z definicją i miarami przez ten zespół.

Utwórz zweryfikowane odpowiedzi.
Skonfiguruj zweryfikowane odpowiedzi dotyczące typowych lub zniuansowanych pytań, które mogą zadawać użytkownicy.
W tym celu wybierz wizualizację i wybierz pozycję "Utwórz zweryfikowaną odpowiedź". Następnie dodaj frazy wyzwalacza, które odzwierciedlają, jak użytkownicy mogą wypowiedzieć swoje pytania. Gdy użytkownicy wprowadzają pasujące lub podobne frazy w aplikacji Copilot, zwraca zaufaną wizualizację — zapewniając spójne, wysokiej jakości odpowiedzi w raportach.
W poniższym przykładzie przedstawiono korzyść ze zweryfikowanej odpowiedzi. Użytkownik prosi o sprzedaż według obszaru. Copilot interpretuje obszar jako obszar produktu i zwraca listę produktów i ich sprzedaży. Jednak użytkownik szukał sprzedaży według regionu lub lokalizacji.
Autor modelu ustawia zweryfikowaną odpowiedź przy użyciu wizualizacji zawierającej sprzedaż według regionów. Po wybraniu opcji ustawienia zweryfikowanej odpowiedzi na wizualizację autor modelu zawiera frazy wyzwalacza, które po wyświetleniu monitu przez użytkownika powinny zwrócić tę konkretną odpowiedź wizualną.
Teraz, gdy użytkownik, co to są sprzedaż według obszaru, zweryfikowana odpowiedź, zatwierdzona przez autora modelu, jest zwracana przez Copilot.

Dodaj instrukcje dotyczące sztucznej inteligencji.
Po zdefiniowaniu schematu i zweryfikowanych odpowiedzi skorzystaj z instrukcji sztucznej inteligencji, aby kierować zachowaniem Copilota na poziomie modelu.
Instrukcje pomagają wyjaśnić logikę biznesową, mapować terminologię użytkownika na pola modelu i kierować Copilot na sposób interpretowania lub analizowania określonych typów danych. Są one pomocne w dostarczaniu kontekstu Copilot nie wywnioskowałby samodzielnie.
W poniższym przykładzie pokazano, jak można użyć instrukcji sztucznej inteligencji, aby zapewnić więcej kontekstu copilotowi. Użytkownik poprosił o sprzedaż w zajętym sezonie 2012. Zajęty sezon to dobrze zdefiniowana, często używana fraza w tej organizacji. Jednak semantyczny model nie wskazuje na ten termin w dowolnym miejscu. Autor modelu ustawia instrukcję, że zajęty sezon jest zdefiniowany jako czerwiec-sierpień.
Teraz, gdy użytkownik ponownie zadaje pytanie dotyczące sprzedaży w zajętym sezonie, Copilot rozumie ten zdefiniowany termin i może dostarczyć odpowiedź.
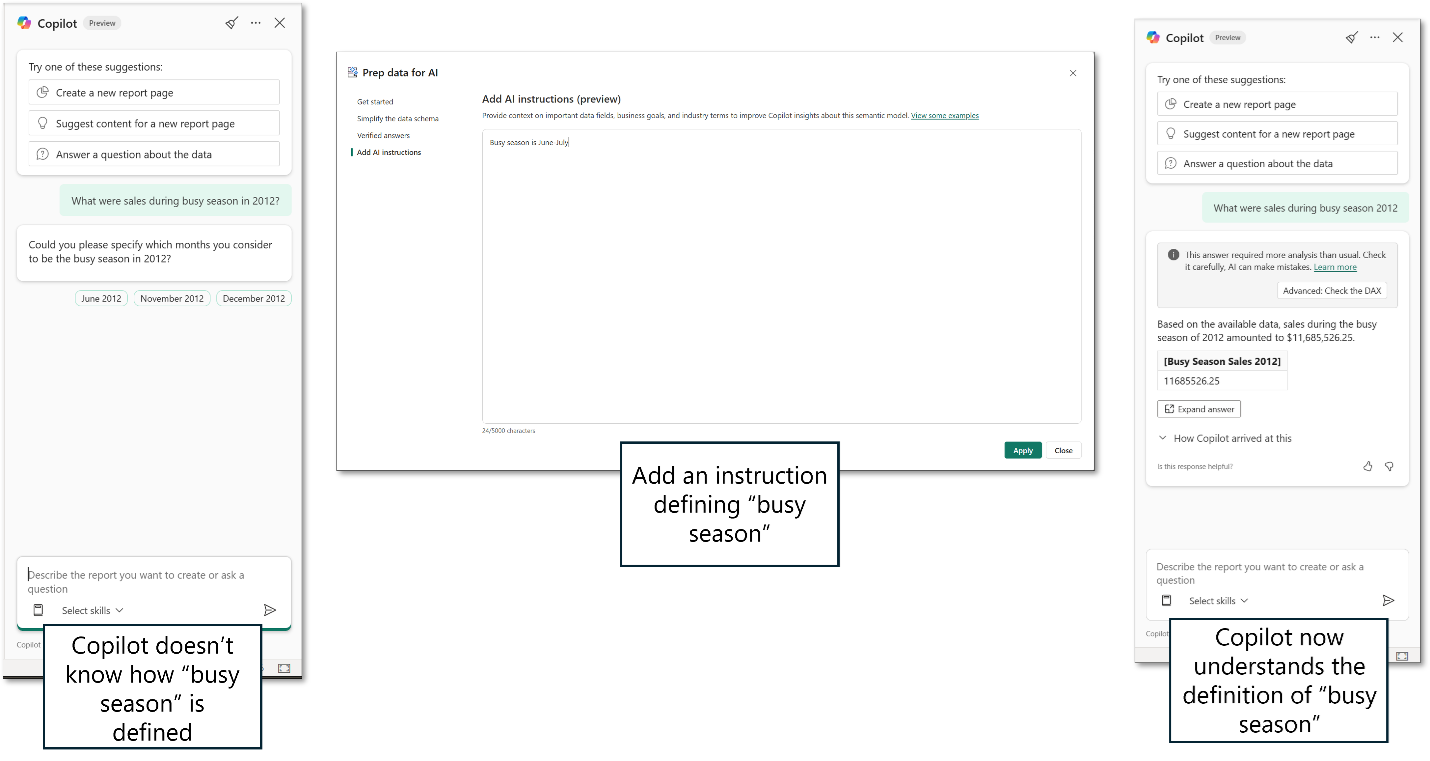
Dodaj opisy do tabel i kolumn.
Opisy zawierają dodatkowe metadane, których copilot może użyć do zrozumienia modelu.
Chociaż opisy mają obecnie wpływ tylko na niektóre zachowania Copilot, będą odgrywać większą rolę w przyszłych możliwościach. Dodanie ich pomaga teraz stworzyć silną podstawę dla długoterminowego sukcesu w interakcjach z językiem naturalnym w usłudze Power BI.



Czy mogę utworzyć narzędzia w raporcie zamiast modelu?
Obecnie funkcje narzędzi i konfiguracji są dostępne tylko w modelu. Konfigurowanie różnych raportów utworzonych na podstawie tego samego modelu nie jest jeszcze obsługiwane. Schemat, zweryfikowane odpowiedzi, instrukcje i opisy są ustawiane na modelu semantycznym, ale nie w raporcie.
Które możliwości copilot mają wpływ na przygotowanie moich danych do Copilot?
Zapoznaj się z następującą tabelą:
| Capability | Schemat danych sztucznej inteligencji | Zweryfikowane odpowiedzi | Instrukcje dotyczące sztucznej inteligencji | Descriptions |
|---|---|---|---|---|
| Pobieranie podsumowania mojego raportu | No | No | Yes | No |
| Zadaj pytanie dotyczące wizualizacji w moim raporcie | No | Yes | Yes | No |
| Zadaj pytanie dotyczące mojego modelu semantycznego | Yes | Yes | Yes | No |
| Tworzenie strony raportu | No | No | Yes | No |
| Search | No | Yes | No | Yes |
| Zapytanie języka DAX | No | No | Yes | Yes |
Znajomość funkcji do użycia
Próbuję uzyskać Copilot, aby wybrać odpowiednie pole. Której funkcji należy używać?
Zdefiniuj schemat danych sztucznej inteligencji.
Usuń wszystkie tabele, kolumny lub pola, które są nieistotne dla potrzeb użytkowników. Pomaga to copilot skupić się na najbardziej odpowiednich częściach modelu, zapewniając, że wybiera odpowiednie pola podczas odpowiadania na zapytania.
Użyj zweryfikowanych odpowiedzi dla wizualizacji w raportach.
Jeśli odpowiedź na pytanie może pochodzić z wizualizacji w raporcie, utwórz zweryfikowaną odpowiedź. Dzięki temu, gdy użytkownicy zadają pytania z określonymi frazami wyzwalaczy, funkcja Copilot stale zwraca poprawną wizualizację.
Dostosowywanie instrukcji dotyczących określonych pól.
Po ustawieniu schematu i zweryfikowanych odpowiedzi możesz użyć instrukcji sztucznej inteligencji, aby poprowadzić Copilot podczas wybierania określonych pól. Zalecamy stosowanie instrukcji dotyczących dostrajania szczegółowego i zaawansowanych scenariuszy po ustawieniu innych funkcji przygotowywania danych sztucznej inteligencji. Korzystając z tej sekwencji kroków, upewnij się, że copilot zwraca najbardziej dokładne i kontekstowe wyniki dla użytkowników, kierując się strukturą modelu i zdefiniowanymi instrukcjami.
Próbuję uzyskać Copilot, aby zrozumieć termin, którego używam. Której funkcji należy używać?
Jeśli masz termin Copilot ma trudności z zrozumieniem, że zawsze ma ten sam prawidłowy element do odwołania w modelu, możesz podać alternatywną nazwę za pomocą instrukcji sztucznej inteligencji.
Jeśli na przykład twój zespół wywołuje osoby, które sprzedają produkty "bliżej", najlepszą opcją byłoby podanie odwołania w instrukcjach sztucznej inteligencji przez ustawienie "sprzedawców", aby było również znane jako "bliżej".
Próbuję uzyskać Copilot, aby zrozumieć warunki z warunkami lub grupami. Której funkcji należy używać?
Jeśli twój zespół używa określonych terminów, które nie są dokładnym dopasowaniem 1:1 z tabelami/polami w modelu, użycie instrukcji sztucznej inteligencji pomaga wyjaśnić różne elementy z określonymi warunkami lub grupami.
Na przykład zespół sprzedaży może sklasyfikować "osoby o wysokiej wykonawców" jako każdy, kto sprzedaje ponad 100% swoich celów w danym miesiącu. Następnie można podać następujące instrukcje dla Copilot:
Wysoka wykonawca oznacza sprzedawcę, który spełnia 100% lub więcej z miesięcznego celu.
Teraz, gdy użytkownik "Kto był wysokimi wykonawcami w zeszłym miesiącu?" Copilot rozumie definicję tego, co oznacza wysoki wskaźnik w zespole i organizacji.
Innym przykładem może być to, jak zespół klasyfikuje różne sezony. Na przykład Jan-May mogą być przywołyane w zespole jako wolny sezon, czerwiec do września może być zajęty sezonem, a październik do grudnia może być sezonem standardowym.
W ramach instrukcji dotyczących sztucznej inteligencji można ustawić następujące ustawienia:
- Powolny sezon oznacza od stycznia do maja.
- Zajęty sezon oznacza czerwiec do września.
- Sezon standardowy oznacza październik do grudnia.
Teraz, gdy użytkownik "Jaka była łączna sprzedaż za zajęty sezon w zeszłym roku?" Copilot rozumie, jaki przedział czasu użytkownik oznacza przez zajęty sezon.
Próbuję uzyskać Copilot, aby zwrócić prawidłową odpowiedź na najczęściej zadawane pytania. Której funkcji należy używać?
Użytkownicy raportu i danych prawdopodobnie mają często zadawane pytania. Najlepszym sposobem rozwiązania tego problemu jest zastosowanie zweryfikowanych odpowiedzi do modelu. Zastosuj zweryfikowaną odpowiedź, wybierając wizualizację i ustawienie wyzwalając frazy, które użytkownik o temat, zwraca informacje przy użyciu przypisanej wizualizacji.
Na przykład użytkownicy raportu i modelu często zadają pytania "Jaki produkt miał najwyższą sprzedaż w zeszłym tygodniu" dotyczące łącznej i kwoty sprzedaży. Ustawienie zweryfikowanej odpowiedzi pomaga Copilot zrozumieć, skąd uzyskać odpowiednie informacje i pomaga w tworzeniu zaufania autorów i konsumentów przy użyciu podanej odpowiedzi.
Próbuję uzyskać copilot zwrócić różne odpowiedzi na podstawie domen lub grup użytkowników. Której funkcji należy używać?
Możliwości istniejące obecnie są ograniczone do szerokiego użycia. Tworzenie słownika opartego na różnych grupach nie jest obecnie obsługiwane. Jeśli na przykład użycie dla inżynierów oznacza "liczbę kliknięć" i użycie do menedżera produktu oznacza "płacenie klientom w danym miesiącu", definiowanie "użycia" w modelu na dwa różne sposoby nie może być obecnie obsługiwane.
Przygotowywanie danych dla sztucznej inteligencji
Otrzymuję błąd z informacją: "Copilot jest obecnie synchronizowany z modelem danych". Co to oznacza?
Aby copilot był w stanie jak najlepiej wykonać, ważne jest, aby Copilot mógł zrozumieć podstawowe dane w modelu semantycznym. Jednym ze sposobów, w jaki usługa Power BI Copilot próbuje zrozumieć dane bazowe, jest indeksowanie modelu semantycznego w celu dokładnego wyszukiwania odpowiednich wartości do dopasowania. Dzięki temu copilot skutecznie odpowiada na pytania na podstawie monitu użytkownika.
Rozważmy zestaw danych turystyki hawajskiej. Aby odpowiedzieć na takie pytania: "Jak pogoda miała wpływ na wizyty turystyczne na Maui?" Copilot musi zrozumieć, że Maui jest wartością wystąpienia w modelu semantycznym w kolumnie Nazwa wyspy tabeli Island .
Aby zapewnić copilot możliwość efektywnego wyszukiwania tych wartości wystąpień, model semantyczny jest indeksowany, gdy pytania i odpowiedzi są ponownie indeksowane po wykryciu zmian w modelu przez usługę Power BI.
Częstotliwość indeksowania modelu
Indeksowanie jest wykonywane dla wszystkich modeli z włączonym ustawieniem pytań i pytań.
Note
Ustawienie Q&A jest domyślnie włączone dla modeli importu . Więcej szczegółów tego ustawienia można znaleźć w dokumentacji ustawień pytań i pytań.
Ponowne indeksowanie występuje, gdy odbywa się jedna z następujących akcji:
- W przypadku modeli importu :
- Model został opublikowany/ponownie opublikowany w usłudze.
- Model został odświeżony za pomocą ręcznego lub zaplanowanego odświeżania, a w ciągu ostatnich 14 dni użyto narzędzia Copilot/Q&A.
- W przypadku modeli Direct Query i Direct Lake :
- Model został opublikowany/ponownie opublikowany w usłudze.
- Indeks jest starszy niż 24 godziny, a w ciągu ostatnich 14 dni użyto narzędzia Copilot/Q&A.
Poniższy komunikat w aplikacji Copilot wskazuje, że model jest obecnie w trakcie indeksowania. Komunikat powinien zostać automatycznie rozwiązany po zakończeniu indeksowania.

Note
Ten błąd nie oznacza, że copilot nie jest dostępny dla użytkowników. Ten komunikat wskazuje, że wszystkie nowe wartości wystąpień dodane lub zmienione w modelu mogą nie odzwierciedlać odpowiedzi Copilot do momentu zakończenia działania indeksowania.
Metodologia indeksowania
Kolumny tekstowe w modelu semantycznym to jedyne kolumny, które są indeksowane. Kolumny ukryte w schemacie sztucznej inteligencji za pośrednictwem funkcji przygotowywania danych dla sztucznej inteligencji nie są indeksowane.
Indeksowane są maksymalnie pięć milionów wartości wystąpień z kolumnami, przy czym najmniejsza kardynalność jest najpierw indeksowana. Kardynalność kolumny jest określana DISTINCTCOUNT dla modeli importu i COLUMNSTATISTICS modeli zapytań bezpośrednich. W przypadku źródeł COLUMNSTATISTICS zapytań bezpośrednich funkcja używa APPROXIMATEDISTINCTCOUNT funkcji dla bazowych źródeł danych, które obsługują je, aby efektywnie określić przybliżone kardynały kolumn. Aby jeszcze bardziej zapobiec przeciążeniu systemu bazowego dla modeli zapytań bezpośrednich z napływem zapytań z powodu indeksowania, wyniki COLUMNSTATISTICS są buforowane, a statystyki są ponownie obliczane co siedem dni. W trakcie procesu indeksowania, jeśli wartość 5 milionów wystąpień zostanie przekroczona z indeksowaniem następnej kolumny, indeksowanie kolumny zostanie całkowicie pominięte.
Jeśli osiągnięto limit indeksowania, Copilot nadal odpowiada, ale na podstawie utworzonego indeksu, który nie zawiera wszystkich wartości wystąpień. Użytkownicy widzą następujące ostrzeżenie, gdy model semantyczny, o których mowa, osiągnie limit indeksowania.

Znane ograniczenia
- Indeksowanie ma górny limit pięciu milionów wartości wystąpień lub 1000 jednostek modelu (tabel/kolumn) dla dużych modeli semantycznych.
- Wartości tekstowe 100+ znaków nie są indeksowane.
- Modele zapytań bezpośrednich indeksuje tylko kolumny dla źródeł danych, które obsługują
APPROXIMATEDISTINCTCOUNT. - Indeksowanie modeli Direct Query i Direct Lake odbywa się raz w okresie 24-godzinnym, chyba że model zostanie ponownie opublikowany.