Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:![]() Program SQL Server w systemie Linux
Program SQL Server w systemie Linux
Ten przewodnik zawiera instrukcje dotyczące tworzenia dwuwęzłowego klastra udostępnionego dysku w trybie failover dla programu SQL Server w systemie Red Hat Enterprise Linux. Warstwa klastrowania jest oparta na dodatku Red Hat Enterprise Linux (RHEL) HA zbudowanym na Pacemaker. Wystąpienie programu SQL Server jest aktywne w jednym węźle lub w drugim.
Uwaga / Notatka
Dostęp do dodatku Red Hat HA i dokumentacji wymaga subskrypcji.
Jak pokazano na poniższym diagramie, pamięć masowa jest przedstawiana dwóm serwerom. Składniki klastrowania — Corosync i Pacemaker — koordynują komunikację i zarządzanie zasobami. Jeden z serwerów ma aktywne połączenie z zasobami magazynu i programem SQL Server. Gdy program Pacemaker wykryje awarię, składniki klastrowania są odpowiedzialne za przeniesienie zasobów do innego węzła.
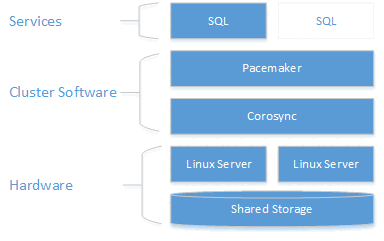
Aby uzyskać więcej informacji na temat konfiguracji klastra, opcji agentów zasobów i zarządzania, odwiedź dokumentację referencyjną systemu RHEL.
W tym momencie integracja programu SQL Server z programem Pacemaker nie jest tak połączona, jak w przypadku usługi WSFC w systemie Windows. W SQL Serverze nie ma wiedzy na temat obecności klastra, cała koordynacja pochodzi z zewnątrz, a usługa jest kontrolowana jako autonomiczne wystąpienie przez program Pacemaker. Również na przykład dynamiczne widoki zarządzania klastrami sys.dm_os_cluster_nodes i sys.dm_os_cluster_properties nie będą zawierać żadnych rekordów.
Aby użyć ciągu połączenia wskazującego nazwę serwera, a nie adres IP, muszą zarejestrować w swoim serwerze DNS adres IP używany do skonfigurowania wirtualnego zasobu IP (zgodnie z opisem w poniższych sekcjach) z wybraną nazwą serwera.
Kolejne sekcje opisują kroki konfigurowania rozwiązania klastra awaryjnego przełączania.
Wymagania wstępne
Do wykonania następującego kompleksowego scenariusza potrzebne są dwie maszyny do wdrożenia klastra dwóch węzłów i innego serwera w celu skonfigurowania serwera NFS. W poniższych krokach opisano sposób konfigurowania tych serwerów.
Ustawianie i konfigurowanie systemu operacyjnego na każdym węźle klastra
Pierwszym krokiem jest skonfigurowanie systemu operacyjnego w węzłach klastra. W tym przewodniku użyj systemu RHEL z prawidłową subskrypcją dodatku wysokiej dostępności.
Instalowanie i konfigurowanie programu SQL Server w każdym węźle klastra
Zainstaluj i skonfiguruj program SQL Server w obu węzłach. Aby uzyskać szczegółowe instrukcje, zobacz Wskazówki dotyczące instalacji programu SQL Server w systemie Linux.
Wyznaczanie jednego węzła jako podstawowego i drugiego jako pomocniczego na potrzeby konfiguracji. Użyj tych terminów, aby śledzić ten przewodnik.
W węźle pomocniczym zatrzymaj i wyłącz program SQL Server.
Poniższy przykład zatrzymuje i wyłącza program SQL Server:
sudo systemctl stop mssql-server sudo systemctl disable mssql-server
Uwaga / Notatka
W czasie instalacji klucz główny serwera jest generowany dla wystąpienia programu SQL Server i umieszczany w katalogu /var/opt/mssql/secrets/machine-key. W systemie Linux program SQL Server zawsze działa jako konto lokalne o nazwie mssql. Ponieważ jest to konto lokalne, jego tożsamość nie jest współdzielona między węzłami. W związku z tym należy skopiować klucz szyfrowania z węzła podstawowego do każdego węzła pomocniczego, aby każde konto lokalne mssql mógł uzyskać dostęp do niego w celu odszyfrowania klucza głównego serwera.
W węźle podstawowym utwórz identyfikator logowania programu SQL Server dla programu Pacemaker i przyznaj uprawnienia logowania do uruchomienia polecenia
sp_server_diagnostics. Narzędzie Pacemaker używa tego konta do sprawdzania, na którym węźle działa program SQL Server.sudo systemctl start mssql-serverPołącz się z bazą danych SQL Server
masterza pomocą kontasai uruchom następujące polecenie:USE [master]; GO CREATE LOGIN [<loginName>] WITH PASSWORD = N'<password>'; ALTER SERVER ROLE [sysadmin] ADD MEMBER [<loginName>];Ostrzeżenie
Hasło powinno być zgodne z domyślnymi zasadami haseł programu SQL Server. Domyślnie hasło musi mieć długość co najmniej ośmiu znaków i zawierać znaki z trzech z następujących czterech zestawów: wielkie litery, małe litery, cyfry podstawowe-10 i symbole. Hasła mogą mieć długość maksymalnie 128 znaków. Używaj haseł, które są tak długie i złożone, jak to możliwe.
Alternatywnie można ustawić uprawnienia na bardziej szczegółowym poziomie. Identyfikator logowania usługi Pacemaker wymaga zapytania o stan kondycji za pomocą
sp_server_diagnostics,setupadminiALTER ANY LINKED SERVER, aby zaktualizować nazwę wystąpienia FCI do nazwy zasobu poprzez uruchomieniesp_dropserverisp_addserver.W węźle podstawowym zatrzymaj i wyłącz program SQL Server.
Skonfiguruj plik hostów dla każdego węzła klastra. Plik hosta musi zawierać adres IP i nazwę każdego węzła klastra.
Sprawdź adres IP dla każdego węzła. Poniższy skrypt przedstawia adres IP bieżącego węzła.
sudo ip addr showUstaw nazwę komputera w każdym węźle. Nadaj każdemu węzłowi unikatową nazwę o 15 znaków lub mniej. Ustaw nazwę komputera, dodając ją do elementu
/etc/hosts. Poniższy skrypt umożliwia edytowanie/etc/hostsza pomocąvi.sudo vi /etc/hostsW poniższym przykładzie pokazano
/etc/hostsz dodatkami dla dwóch węzłów o nazwachsqlfcivm1isqlfcivm2.127.0.0.1 localhost localhost4 localhost4.localdomain4 ::1 localhost localhost6 localhost6.localdomain6 10.128.18.128 sqlfcivm1 10.128.16.77 sqlfcivm2
W następnej sekcji skonfigurujesz magazyn udostępniony i przeniesiesz pliki bazy danych do tego magazynu.
Konfigurowanie udostępnionego magazynu i przenoszenie plików bazy danych
Istnieją różne rozwiązania do zapewniania współdzielonego przechowywania. Ten przewodnik przedstawia konfigurowanie pamięci masowej udostępnionej w systemie NFS. Zalecamy stosowanie najlepszych rozwiązań i używanie protokołu Kerberos do zabezpieczania systemu plików NFS. Aby zapoznać się z przykładem, zobacz RHEL7: Używanie protokołu Kerberos do kontrolowania dostępu do udziałów sieciowych NFS.
Ostrzeżenie
Jeśli nie zabezpieczysz systemu plików NFS, każdy, kto może uzyskać dostęp do sieci i sfałszować adres IP węzła SQL, będzie mógł uzyskać dostęp do plików danych. Zawsze przed użyciem systemu w środowisku produkcyjnym, przeprowadź modelowanie zagrożeń. Inną opcją magazynu jest użycie udziału plików SMB.
Konfigurowanie magazynu udostępnionego z systemem plików NFS
Ważne
Hostowanie plików bazy danych na serwerze NFS w wersji <4 nie jest obsługiwane w tej wersji. Obejmuje to używanie NFS do klastra przełączania awaryjnego dla współdzielonych dysków, a także do baz danych na nieklastrowanych instancjach. Pracujemy nad włączeniem innych wersji serwera NFS w nadchodzących wersjach.
Na serwerze NFS wykonaj następujące kroki:
Zainstaluj
nfs-utilssudo yum -y install nfs-utilsWłączanie i uruchamianie
rpcbindsudo systemctl enable rpcbind && sudo systemctl start rpcbindWłączanie i uruchamianie
nfs-serversudo systemctl enable nfs-server && sudo systemctl start nfs-serverEdytuj
/etc/exports, aby wyeksportować katalog, który chcesz udostępnić. Potrzebujesz jednego wiersza dla każdego żądanego udziału. Przykład:/mnt/nfs 10.8.8.0/24(rw,sync,no_subtree_check,no_root_squash)Eksportowanie udziałów
sudo exportfs -ravSprawdź, czy ścieżki są współużytkowane/eksportowane, uruchamiane z serwera NFS
sudo showmount -eDodawanie wyjątku w programie SELinux
sudo setsebool -P nfs_export_all_rw 1Otwórz zaporę serwera.
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reload
Skonfiguruj wszystkie węzły klastra do połączenia z udostępnionym magazynem NFS
Wykonaj następujące kroki we wszystkich węzłach klastra.
Zainstaluj
nfs-utilssudo yum -y install nfs-utilsOtwieranie zapory na klientach i serwerze NFS
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reloadSprawdź, czy udziały NFS są widoczne na maszynach klienckich
sudo showmount -e <IP OF NFS SERVER>Powtórz te kroki we wszystkich węzłach klastra.
Aby uzyskać więcej informacji na temat korzystania z systemu plików NFS, zobacz następujące zasoby:
- Serwery systemu plików NFS i zapora | Stack Exchange
- Instalowanie woluminu NFS | Przewodnik dla administratorów sieci systemu Linux
- Konfiguracja serwera NFS | Portal klienta usługi Red Hat
Instalowanie katalogu plików bazy danych w celu wskazania magazynu udostępnionego
Tylko w węźle podstawowym zapisz pliki bazy danych w lokalizacji tymczasowej. Poniższy skrypt tworzy nowy katalog tymczasowy, kopiuje pliki bazy danych do nowego katalogu i usuwa stare pliki bazy danych. Ponieważ program SQL Server działa jako użytkownik lokalny
mssql, musisz upewnić się, że po przeniesieniu danych do zamontowanego udziału użytkownik lokalny ma dostęp do odczytu i zapisu udziału.sudo su mssql mkdir /var/opt/mssql/tmp cp /var/opt/mssql/data/* /var/opt/mssql/tmp rm /var/opt/mssql/data/* exitNa wszystkich węzłach klastra edytuj plik
/etc/fstab, aby uwzględnić polecenie mount.<IP OF NFS SERVER>:<shared_storage_path> <database_files_directory_path> nfs timeo=14,intrPoniższy skrypt przedstawia przykład edycji.
10.8.8.0:/mnt/nfs /var/opt/mssql/data nfs timeo=14,intr
Uwaga / Notatka
Jeśli w tym miejscu używasz zasobu systemu plików (FS), nie ma potrzeby zachowywania polecenia instalowania w pliku /etc/fstab. Program Pacemaker zajmie się instalowaniem folderu podczas uruchamiania zasobu klastrowanego fs. Dzięki zastosowaniu mechanizmu blokującego zapewni, że system plików (FS) nigdy nie zostanie zamontowany dwukrotnie.
Uruchom
mount -apolecenie dla systemu, aby zaktualizować zamontowane ścieżki.Skopiuj pliki bazy danych i dziennika, które zapisałeś do
/var/opt/mssql/tmp, na nowo zamontowany udział/var/opt/mssql/data. Ten krok należy wykonać tylko w węźle podstawowym. Upewnij się, że przyznasz użytkownikowi lokalnemumssqluprawnienia do odczytu zapisu.sudo chown mssql /var/opt/mssql/data sudo chgrp mssql /var/opt/mssql/data sudo su mssql cp /var/opt/mssql/tmp/* /var/opt/mssql/data/ rm /var/opt/mssql/tmp/* exitSprawdź, czy program SQL Server rozpoczyna się pomyślnie od nowej ścieżki pliku. Zrób to w każdym węźle. W tym momencie tylko jeden węzeł powinien uruchamiać program SQL Server naraz. Oba te elementy nie mogą być uruchamiane jednocześnie, ponieważ obie będą próbowały uzyskać dostęp do plików danych jednocześnie (aby uniknąć przypadkowego uruchomienia programu SQL Server w obu węzłach, użyj zasobu klastra systemu plików, aby upewnić się, że udział nie jest zainstalowany dwukrotnie przez różne węzły). Następujące polecenia uruchamiają program SQL Server, sprawdzają stan, a następnie zatrzymują program SQL Server.
sudo systemctl start mssql-server sudo systemctl status mssql-server sudo systemctl stop mssql-server
W tym momencie oba wystąpienia programu SQL Server są skonfigurowane do pracy z plikami bazy danych na wspólnej pamięci. Następnym krokiem jest skonfigurowanie programu SQL Server dla programu Pacemaker.
Instalowanie i konfigurowanie programu Pacemaker w każdym węźle klastra
W obu węzłach klastra utwórz plik do przechowywania nazwy użytkownika i hasła programu SQL Server na potrzeby logowania programu Pacemaker. Następujące polecenie tworzy i wypełnia ten plik:
sudo touch /var/opt/mssql/secrets/passwd echo '<loginName>' | sudo tee -a /var/opt/mssql/secrets/passwd echo '<password>' | sudo tee -a /var/opt/mssql/secrets/passwd sudo chown root:root /var/opt/mssql/secrets/passwd sudo chmod 600 /var/opt/mssql/secrets/passwdOstrzeżenie
Hasło powinno być zgodne z domyślnymi zasadami haseł programu SQL Server. Domyślnie hasło musi mieć długość co najmniej ośmiu znaków i zawierać znaki z trzech z następujących czterech zestawów: wielkie litery, małe litery, cyfry podstawowe-10 i symbole. Hasła mogą mieć długość maksymalnie 128 znaków. Używaj haseł, które są tak długie i złożone, jak to możliwe.
Otwórz porty firewalla Pacemaker na obu węzłach klastra. Aby otworzyć te porty przy użyciu
firewalld, uruchom następujące polecenie:sudo firewall-cmd --permanent --add-service=high-availability sudo firewall-cmd --reloadJeśli używasz innej zapory, która nie ma wbudowanej konfiguracji wysokiej dostępności, należy otworzyć następujące porty, aby program Pacemaker mógł komunikować się z innymi węzłami w klastrze:
- TCP: Porty 2224, 3121, 21064
- UDP: Port 5405
Zainstaluj pakiety Pacemaker w każdym węźle.
sudo yum install pacemaker pcs fence-agents-all resource-agentsUstaw hasło dla domyślnego użytkownika, który jest tworzony podczas instalowania pakietów Pacemaker i Corosync. Użyj tego samego hasła w obu węzłach.
sudo passwd haclusterWłącz i uruchom
pcsdusługę oraz program Pacemaker. Umożliwi to węzłom ponowne dołączanie do klastra po ponownym uruchomieniu. Uruchom następujące polecenie w obu węzłach.sudo systemctl enable pcsd sudo systemctl start pcsd sudo systemctl enable pacemakerZainstaluj agenta zasobów FCI dla SQL Server. Uruchom następujące polecenia w obu węzłach.
sudo yum install mssql-server-ha
Konfigurowanie agenta izolacji
Urządzenie STONITH zapewnia agenta ochrony. Konfigurowanie programu Pacemaker w systemie Red Hat Enterprise Linux na platformie Azure zawiera przykład tworzenia urządzenia STONITH dla tego klastra na platformie Azure. Zmodyfikuj instrukcje dotyczące środowiska.
Tworzenie klastra
W jednym z węzłów utwórz klaster.
sudo pcs cluster auth <nodeName1 nodeName2 ...> -u hacluster sudo pcs cluster setup --name <clusterName> <nodeName1 nodeName2 ...> sudo pcs cluster start --allSkonfiguruj zasoby klastra dla zasobów SQL Server, systemu plików, i wirtualnych zasobów IP, a następnie wypchnij konfigurację do klastra. Potrzebne są następujące informacje:
- Nazwa zasobu programu SQL Server: nazwa zasobu klastrowanego programu SQL Server.
- Zmienna nazwa zasobu IP: nazwa zasobu wirtualnego adresu IP.
- Adres IP: adres IP używany przez klientów do nawiązywania połączenia z wystąpieniem klastra programu SQL Server.
- Nazwa zasobu systemu plików: nazwa zasobu systemu plików.
- device: ścieżka udziału NFS
- urządzenie: ścieżka lokalna, która jest instalowana w udziale
-
fstype: Typ udziału plików (czyli
nfs)
Zaktualizuj wartości z następującego skryptu dla danego środowiska. Uruchom polecenie na jednym węźle, aby skonfigurować i uruchomić usługę klastrowaną.
sudo pcs cluster cib cfg sudo pcs -f cfg resource create <sqlServerResourceName> ocf:mssql:fci sudo pcs -f cfg resource create <floatingIPResourceName> ocf:heartbeat:IPaddr2 ip=<ip Address> sudo pcs -f cfg resource create <fileShareResourceName> Filesystem device=<networkPath> directory=<localPath> fstype=<fileShareType> sudo pcs -f cfg constraint colocation add <virtualIPResourceName> <sqlResourceName> sudo pcs -f cfg constraint colocation add <fileShareResourceName> <sqlResourceName> sudo pcs cluster cib-push cfgNa przykład poniższy skrypt tworzy zasób klastrowany programu SQL Server o nazwie
mssqlha, a zmienny zasób IP z adresem10.0.0.99IP . Tworzy również zasób systemu plików i dodaje ograniczenia, dzięki czemu wszystkie zasoby są kolokowane w tym samym węźle co zasób SQL.sudo pcs cluster cib cfg sudo pcs -f cfg resource create mssqlha ocf:mssql:fci sudo pcs -f cfg resource create virtualip ocf:heartbeat:IPaddr2 ip=10.0.0.99 sudo pcs -f cfg resource create fs Filesystem device="10.8.8.0:/mnt/nfs" directory="/var/opt/mssql/data" fstype="nfs" sudo pcs -f cfg constraint colocation add virtualip mssqlha sudo pcs -f cfg constraint colocation add fs mssqlha sudo pcs cluster cib-push cfgPo zastosowaniu konfiguracji program SQL Server zostanie uruchomiony na jednym węźle.
Sprawdź, czy program SQL Server został uruchomiony.
sudo pcs statusPoniższy przykład pokazuje wyniki pomyślnego uruchomienia klastrowanego wystąpienia programu SQL Server przez Pacemaker.
fs (ocf::heartbeat:Filesystem): Started sqlfcivm1 virtualip (ocf::heartbeat:IPaddr2): Started sqlfcivm1 mssqlha (ocf::mssql:fci): Started sqlfcivm1 PCSD Status: sqlfcivm1: Online sqlfcivm2: Online Daemon Status: corosync: active/disabled pacemaker: active/enabled pcsd: active/enabled