Jak używać GitHub Actions do tworzenia procesów systemu ciągłej integracji?
Pamiętaj, że Twoim celem jest zautomatyzowanie procesu kompilowania i publikowania kodu, dzięki czemu funkcje są aktualizowane za każdym razem, gdy deweloper dodaje zmianę do bazy kodu.
Aby zaimplementować ten proces, dowiesz się, jak wykonywać następujące czynności:
- Utwórz przepływ pracy na podstawie szablonu.
- Unikaj duplikowania przy użyciu przepływów pracy wielokrotnego użytku.
- Przetestuj pod kątem wielu obiektów docelowych.
- Oddzielne zadania kompilacji i testowania.
Tworzenie przepływu pracy na podstawie szablonu
Aby utworzyć przepływ pracy, często należy rozpocząć korzystanie z szablonu. Szablon zawiera typowe zadania i kroki wstępnie skonfigurowane dla określonego typu implementowanej automatyzacji. Jeśli nie znasz przepływów pracy, zadań i kroków, zapoznaj się z modułem Automatyzowanie zadań programistycznych przy użyciu funkcji GitHub Actions .
Na stronie głównej repozytorium GitHub wybierz pozycję Akcje, a następnie wybierz pozycję Nowy przepływ pracy.
Na stronie Wybieranie przepływu pracy możesz wybrać spośród wielu typów szablonów. Przykładem jest szablon Node.js. SzablonNode.js instaluje Node.js i wszystkie zależności, kompiluje kod źródłowy i uruchamia testy dla różnych wersji Node.js. Innym przykładem jest szablon pakietu języka Python , który instaluje język Python i jego zależności, a następnie uruchamia testy, w tym lint, w wielu wersjach języka Python.
Aby rozpocząć od szablonu przepływu pracy Node.js, w polu wyszukiwania wprowadź Node.js.
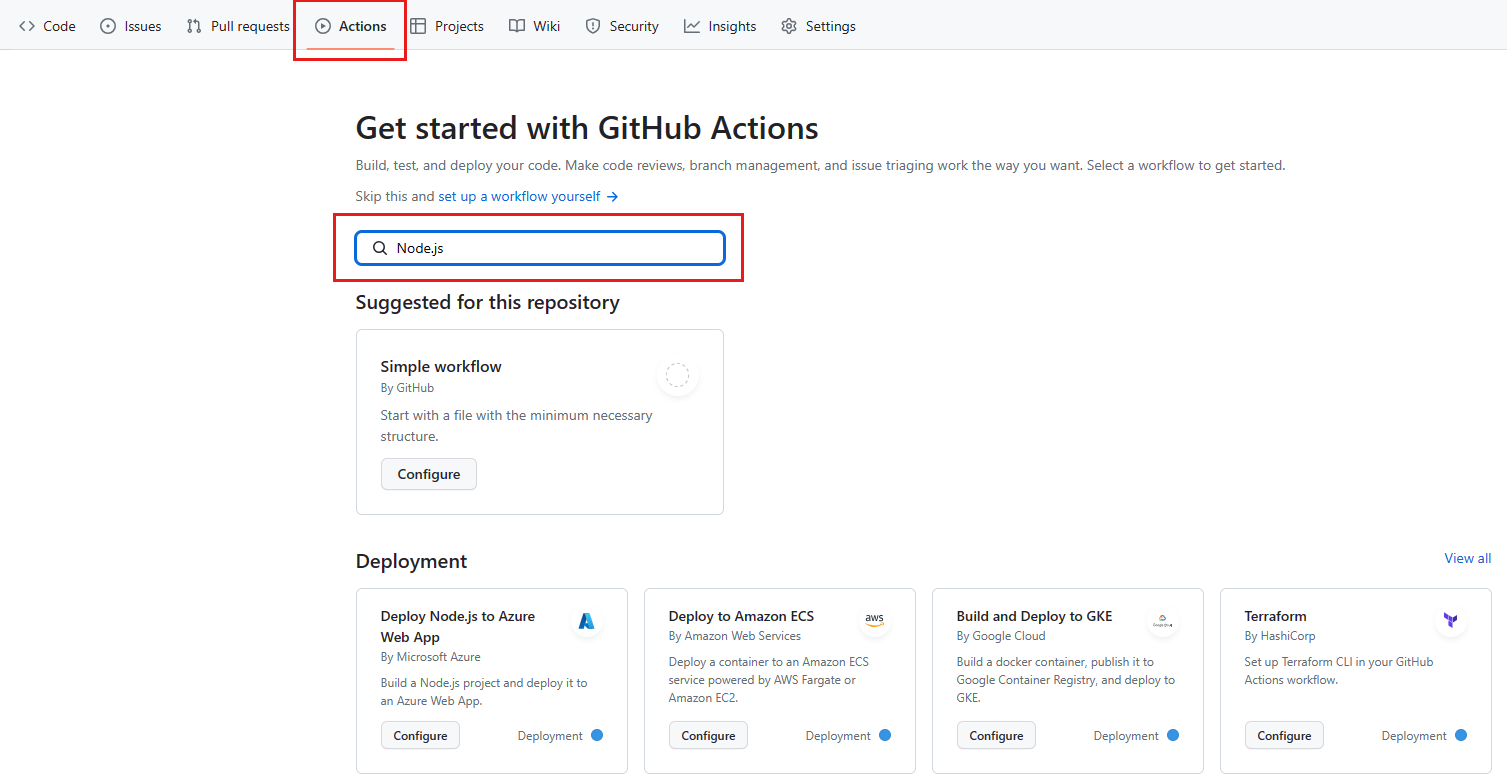
W wynikach wyszukiwania w okienku Node.js wybierz pozycję Konfiguruj.
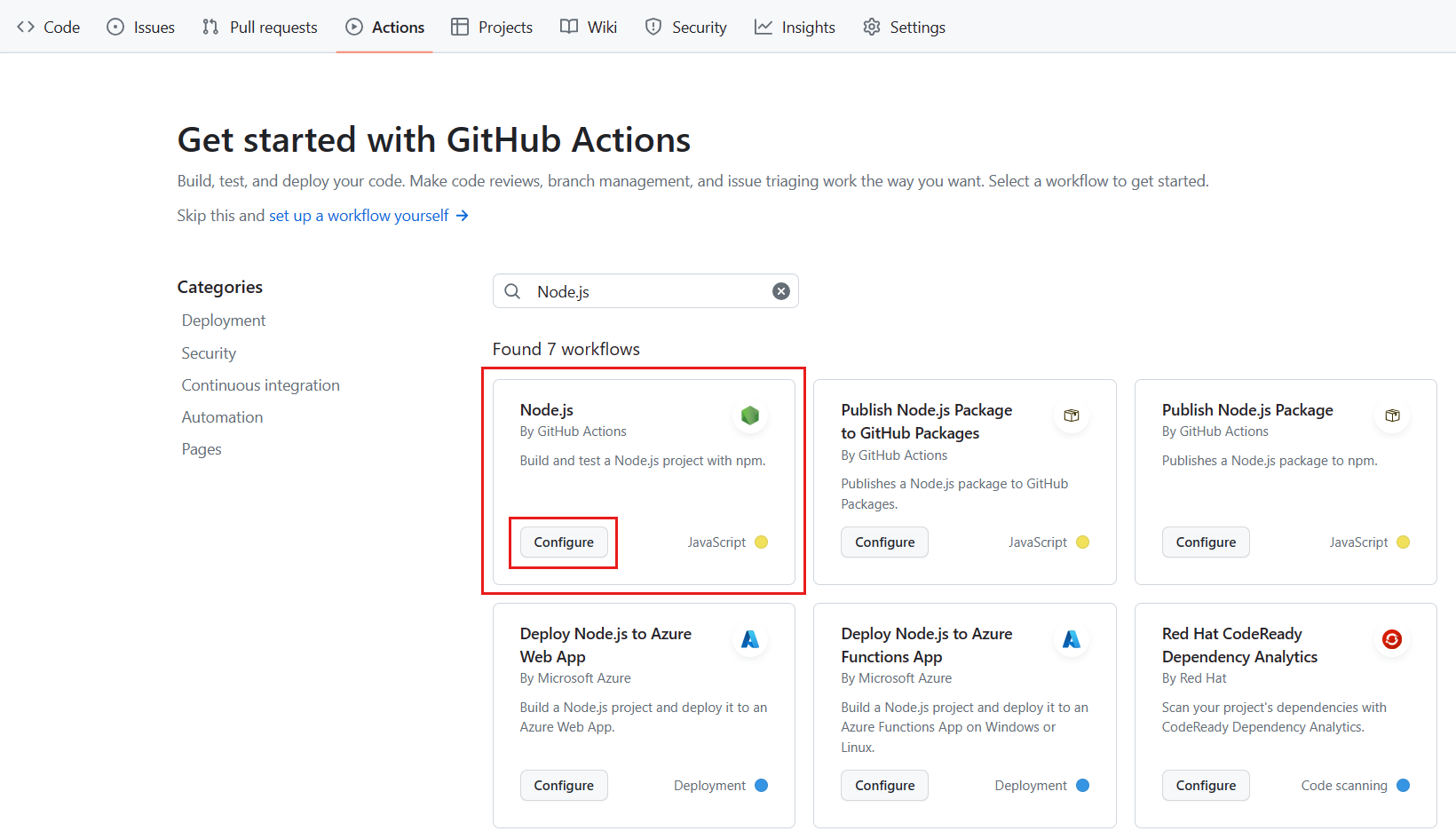
Plik node.js.yml projektu jest tworzony na podstawie szablonu:
name: Node.js CI
on:
push:
branches: [ "main" ]
pull_request:
branches: [ "main" ]
jobs:
build:
runs-on: ubuntu-latest
strategy:
matrix:
node-version: [14.x, 16.x, 18.x]
steps:
- uses: actions/checkout@v3
- name: Use Node.js ${{ matrix.node-version }}
uses: actions/setup-node@v3
with:
node-version: ${{ matrix.node-version }}
cache: 'npm'
- run: npm ci
- run: npm run build --if-present
- run: npm test
Jak pokazano w atrybucie on, ten przykładowy przepływ pracy jest uruchamiany w reakcji na wprowadzenie zmian do repozytorium lub po utworzeniu żądania zmiany względem gałęzi głównej.
Ten przepływ pracy uruchamia jedno zadanie wskazane przez job atrybut .
Atrybut runs-on określa, że dla systemu operacyjnego przepływ pracy jest uruchamiany w ubuntu-latest. Atrybut node-version określa, że istnieją trzy kompilacje, po jednym dla Node.js w wersji 14.x, 16.x i 18.x. Atrybut matrix został szczegółowo opisany w dalszej części modułu.
W atrybucie jobs kroki używają akcji actions/checkout@v3, aby pobrać kod z repozytorium do maszyny wirtualnej (VM) i akcji actions/setup-node@v3, aby skonfigurować poprawną wersję Node.js. Należy określić, że chcesz przetestować trzy wersje Node.js przy użyciu atrybutu ${{ matrix.node-version }} . Ten atrybut odwołuje się do zdefiniowanej wcześniej macierzy. Atrybut cache określa menedżera pakietów do buforowania w katalogu domyślnym.
Ostatnia część tego kroku wykonuje polecenia, których projekty Node.js używają. Polecenie npm ci instaluje zależności z package-lock.json pliku.
npm run build --if-present uruchamia skrypt kompilacji, jeśli istnieje.
npm test uruchamia platformę testowania. Ten szablon zawiera zarówno kroki kompilacji, jak i testu w tym samym zadaniu.
Aby dowiedzieć się więcej na temat narzędzia npm, zapoznaj się z dokumentacją narzędzia npm:
- instalacji narzędzia npm
- uruchamiania narzędzia npm
- npm test
Zespół deweloperów może korzystać z używania przepływów pracy wielokrotnego użytku w celu usprawnienia i standaryzacji powtarzających się kroków automatyzacji. Korzystając z przepływów pracy wielokrotnego użytku, można zmniejszyć nadmiarowość, zwiększyć łatwość konserwacji i zapewnić spójność w potokach ciągłej integracji/ciągłego wdrażania (CI/CD).
Unikaj duplikowania przy użyciu przepływów pracy wielokrotnego użytku
W miarę zwiększania skali i rozwoju projektów zespoły często widzą te same kroki powtarzane w wielu plikach przepływu pracy. Te kroki mogą obejmować wyewidencjonowanie kodu, instalację zależności, testowanie i wdrażanie. Tego rodzaju duplikaty nie tylko zaśmiecają bazę kodu, ale także zwiększają czas konserwacji, gdy wymagane są zmiany kodu. Przepływy pracy wielokrotnego użytku rozwiązują ten problem, umożliwiając definiowanie logiki automatyzacji raz, a następnie wywoływanie logiki z innych przepływów pracy.
Przepływy pracy do ponownego użycia to specjalne przepływy pracy GitHub Actions, które mogą być wywoływane przez inne przepływy pracy, podobnie jak funkcje w programowaniu. Można je tworzyć w celu udostępniania powtarzanych logiki, takich jak kroki kompilacji, procedury testowania lub strategie wdrażania. Po utworzeniu przepływu pracy wielokrotnego użytku możesz odwoływać się do niego z dowolnego innego przepływu pracy w tym samym repozytorium, a nawet w różnych repozytoriach.
Dlaczego warto używać przepływów pracy wielokrotnego użytku?
Są to zalety korzystania z przepływów pracy wielokrotnego użytku:
- Spójność. Zespoły mogą przestrzegać tych samych standardów automatyzacji we wszystkich projektach.
- Sprawność. Zamiast kopiować i wklejać kroki, wystarczy wskazać przepływ pracy wielokrotnego użytku.
- Łatwiejsze aktualizacje. W przypadku zmiany procesu, takiego jak dodanie kroku testu, należy zaktualizować go w jednej lokalizacji. Następnie wszystkie przepływy pracy, które automatycznie wykorzystują korzyści z przepływu pracy.
- Skalowalność. Przepływy pracy wielokrotnego użytku są idealne dla zespołów platformy lub DevOps, które zarządzają wieloma usługami.
Następnie dowiesz się, jak używać przepływów pracy wielokrotnego użytku do ulepszania projektów.
Implementowanie przepływów pracy wielokrotnego użytku
Aby użyć przepływów pracy wielokrotnego użytku:
- W folderze repozytorium utwórz przepływ pracy wielokrotnego użytku. Plik zawiera kroki automatyzacji, które chcesz udostępnić, takie jak typowe kroki związane z testowaniem, kompilowaniem i wdrażaniem.
- Jawnie włącz przepływ pracy do wielokrotnego użytku, konfigurując go za pomocą zdarzenia
workflow_call. - W głównych przepływach pracy (przepływy wywołujące) odwołaj się do tego pliku wielokrotnego użytku i podaj wymagane dane wejściowe lub sekrety.
Aby zilustrować zalety przepływów pracy wielokrotnego użytku, rozważmy następujący rzeczywisty scenariusz.
Przykład
Załóżmy, że Twoja organizacja ma 10 mikrousług. Wszystkie 10 mikrousług wymaga tych samych kroków:
- Uruchamianie testów
- Kod narzędzia lint
- Wdrażanie w określonym środowisku
Bez przepływów pracy wielokrotnego użytku, każde repozytorium powiela tę samą logikę w wielu plikach przepływu pracy, co prowadzi do powtarzających się kroków i utrudnionej konserwacji.
Jeśli używasz przepływów pracy wielokrotnego użytku:
- Proces można zdefiniować raz w pliku centralnym (na przykład w
ci-standard.ymlpliku ). - Ten plik jest wywoływany z przepływu pracy każdej mikrousługi, przekazując zmienne, takie jak środowisko lub nazwa aplikacji.
Jeśli zostanie dodany nowy krok zabezpieczeń lub narzędzie, takie jak skanowanie pod kątem luk w zabezpieczeniach, należy dodać go tylko raz w przepływie pracy wielokrotnego użytku. Wszystkie 10 mikrousług natychmiast zaczynają korzystać ze zaktualizowanego procesu. Nie trzeba modyfikować 10 mikrousług.
Dzięki zrozumieniu, jak działają przepływy pracy wielokrotnego użycia i jakie są ich korzyści, możesz przyjąć najlepsze praktyki w celu maksymalizacji ich skuteczności oraz zapewnienia bezproblemowej integracji z potokami CI/CD.
Najlepsze rozwiązania
- Ucentralizuj swoje wielokrotnego użytku przepływy pracy w jednym repozytorium, jeśli planujesz udostępniać je zespołom.
- Użyj gałęzi lub tagów do wersjonowania swoich przepływów pracy (na przykład użyj
@v1), aby łatwo wycofać zmiany, jeśli to konieczne. - Dokumentuj dane wejściowe i tajemnice wyraźnie. Procesy wielokrotnego użytku często korzystają z danych wejściowych i tajemnic. Zespoły muszą wiedzieć, jakich informacji użyć.
- Jeśli musisz ponownie użyć tylko kilku kroków, połącz przepływy pracy wielokrotnego użytku z akcjami złożonymi zamiast tworzyć pełny przepływ pracy.
Przepływy pracy wielokrotnego użytku to zaawansowany sposób wymuszania spójności, zmniejszania duplikowania i skalowania praktyk DevOps w dowolnym zespole inżynieryjnym. Niezależnie od tego, czy zarządzasz pojedynczym repozytorium, mikrousługami, czy bibliotekami typu open source, przepływy pracy wielokrotnego użytku mogą uprościć automatyzację, dzięki czemu ciągła integracja/ciągłe wdrażanie jest szybsze, czystsze i łatwiejsze do zarządzania.
Dostosowywanie szablonów przepływów pracy
Na początku tego modułu rozważałeś scenariusz, w którym należy skonfigurować CI (ciągłą integrację) dla swojego zespołu deweloperów. Szablon Node.js to doskonały początek, ale chcesz dostosować go tak, aby lepiej odpowiadał wymaganiom zespołu. Chcesz kierować do różnych wersji Node.js i różnych systemów operacyjnych. Chcesz również, aby kroki kompilacji i testowania byłyby oddzielnymi zadaniami.
Oto przykład dostosowanego przepływu pracy:
strategy:
matrix:
os: [ubuntu-latest, windows-latest]
node-version: [16.x, 18.x]
W tym przykładzie skonfigurujesz macierz kompilacji do testowania w wielu systemach operacyjnych i wersjach językowych. Ta macierz produkuje cztery wersje, każda z nich odpowiada jednemu z systemów operacyjnych sparowanemu z każdą wersją Node.js.
Cztery kompilacje i ich testy generują dużą ilość danych dziennika. Może być trudno to wszystko uporządkować. W poniższym przykładzie przenosisz krok testowy do dedykowanego zadania testowego. To zadanie testuje wiele celów. Oddzielenie kroków kompilacji i testowania ułatwia pracę z danymi dziennika.
test:
runs-on: ${{ matrix.os }}
strategy:
matrix:
os: [ubuntu-latest, windows-latest]
node-version: [16.x, 18.x]
steps:
- uses: actions/checkout@v3
- name: Use Node.js ${{ matrix.node-version }}
uses: actions/setup-node@v3
with:
node-version: ${{ matrix.node-version }}
- name: npm install, and test
run: |
npm install
npm test
env:
CI: true