Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
WinML Dashboard to narzędzie do wyświetlania, edytowania, konwertowania i weryfikowania modeli uczenia maszynowego dla aparatu wnioskowania Windows ML. Aparat jest wbudowany w system Windows 10 i ocenia wytrenowane modele lokalnie na urządzeniach z systemem Windows przy użyciu optymalizacji sprzętowych dla procesora CPU i GPU, aby umożliwić wnioskowanie o wysokiej wydajności.
Pobieranie narzędzia
Możesz pobrać pulpit nawigacyjny WinML tutaj lub skompilować aplikację ze źródła, postępując zgodnie z poniższymi instrukcjami.
Kompilacja ze źródła
Podczas kompilowania aplikacji ze źródła potrzebne są następujące elementy:
| Wymagania | wersja | Pobierz | Polecenie sprawdzenia |
|---|---|---|---|
| Python3 | 3.4+ | tu | python --version |
| Przędza | najnowszy | tu | yarn --version |
| Node.js | najnowszy | tu | node --version |
| Git | najnowszy | tu | git --version |
| MSBuild | najnowszy | tu | msbuild -version |
| NuGet | najnowszy | tu | nuget help |
Wszystkie sześć wymagań wstępnych musi zostać dodanych do ścieżki środowiska. Należy pamiętać, że programy MSBuild i NuGet zostaną uwzględnione w instalacji programu Visual Studio 2017.
Kroki kompilowania i uruchamiania
Aby uruchomić pulpit nawigacyjny WinML, wykonaj następujące kroki:
- W wierszu polecenia sklonuj repozytorium:
git clone https://github.com/Microsoft/Windows-Machine-Learning - W repozytorium wprowadź następujące informacje, aby uzyskać dostęp do odpowiedniego folderu:
cd Tools/WinMLDashboard - Uruchom
git submodule update --init --recursive, aby zaktualizować Netron. - Uruchom polecenie yarn, aby pobrać zależności.
- Następnie uruchom
yarn electron-prod, aby skompilować i uruchomić aplikację klasyczną, która uruchomi pulpit nawigacyjny.
Wszystkie dostępne polecenia pulpitu nawigacyjnego są widoczne pod adresem package.json.
Przeglądanie i edycja modeli
Pulpit nawigacyjny używa Netron do wyświetlania modeli uczenia maszynowego. Mimo że WinML używa formatu ONNX, przeglądarka Netron obsługuje wyświetlanie kilku różnych formatów struktury.
Wiele razy deweloper może być zmuszony do zaktualizowania niektórych metadanych modelu lub zmodyfikowania węzłów wejściowych i wyjściowych modelu. To narzędzie obsługuje modyfikowanie właściwości modelu, metadanych i węzłów wejściowych/wyjściowych modelu ONNX.
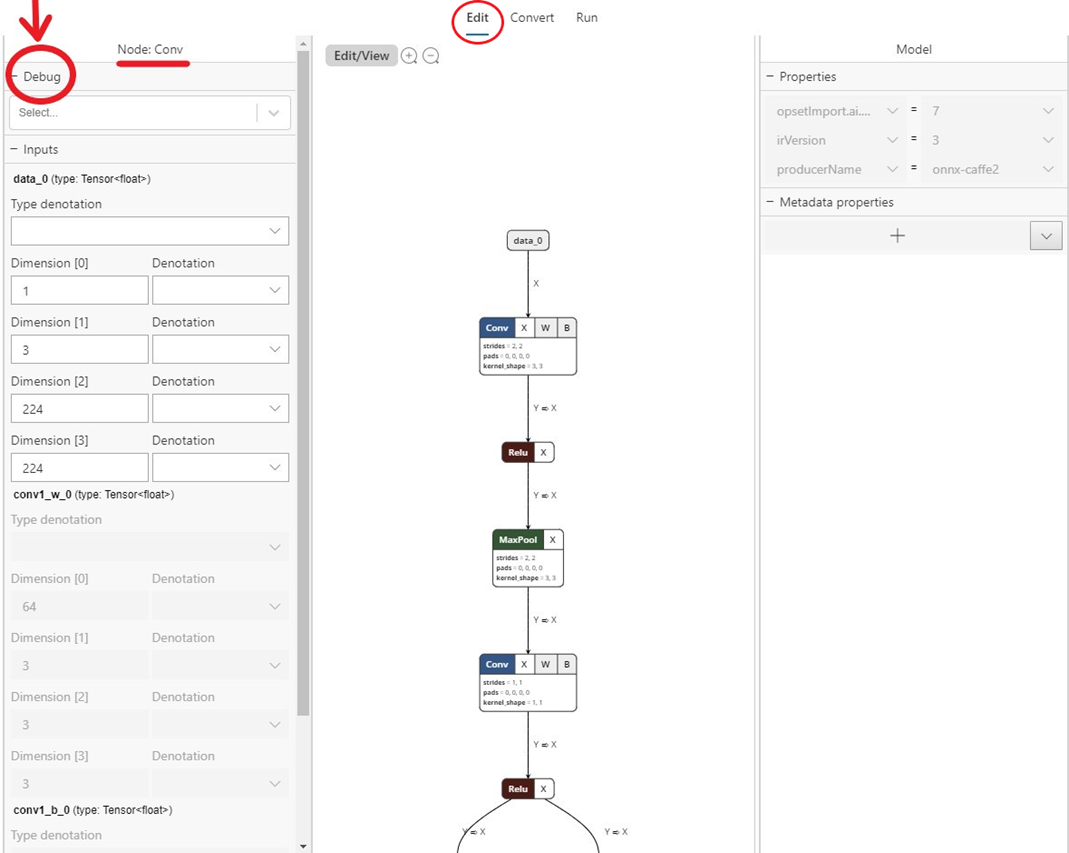
Wybranie zakładki Edit (na środku u góry, jak pokazano na poniższym wycinku) spowoduje przejście do panelu przeglądania i edycji. Lewy panel w panelu umożliwia edycję węzłów wejściowych i wyjściowych modelu, a prawy panel umożliwia edycję właściwości modelu. Środkowa część przedstawia wykres. W tej chwili obsługa edycji jest ograniczona do węzła wejściowego/wyjściowego modelu (a nie węzłów wewnętrznych), właściwości modelu i metadanych modelu.
Przycisk Edit/View przełącza się z trybu edycji do trybu tylko do wyświetlania i odwrotnie.
Tryb tylko do wyświetlania nie pozwala na edycję i włącza natywne funkcje przeglądarki Netron, takie jak możliwość wyświetlania szczegółowych informacji dla każdego węzła.

Konwertowanie modeli
Obecnie dostępnych jest kilka różnych ram do trenowania i oceniania modeli uczenia maszynowego, co utrudnia twórcom aplikacji integrowanie modeli z ich produktem. Windows ML używa formatu modelu uczenia maszynowego ONNX , który umożliwia konwersję z jednego formatu struktury na inny, a ten pulpit nawigacyjny ułatwia konwertowanie modeli z różnych struktur na ONNX.
Karta Konwertuj obsługuje konwertowanie na ONNX z następujących struktur źródłowych:
- Podstawowe uczenie maszynowe firmy Apple
- TensorFlow (podzbiór modeli konwertowanych na ONNX)
- Keras
- Scikit-learn (podzbiór modeli konwertowanych na ONNX)
- Wzmocnienie Xgboost
- Biblioteka LibSVM
Narzędzie umożliwia również walidację przekonwertowanego modelu poprzez ocenę modelu za pomocą wbudowanego aparatu wnioskowania Windows ML przy użyciu danych syntetycznych (domyślnie) lub rzeczywistych danych wejściowych na procesorze CPU lub GPU.

Walidacja modeli
Gdy masz model ONNX, możesz sprawdzić, czy konwersja zakończyła się pomyślnie i czy model można ocenić w aparacie wnioskowania Windows ML. Odbywa się to za pomocą zakładki Run (patrz wycinek poniżej).
Możesz wybrać różne opcje, takie jak procesor (domyślnie) vs GPU, rzeczywiste wejście vs wejście syntetyczne (domyślnie) itp. Wynik oceny modelu jest wyświetlany w oknie konsoli u dołu.
Należy pamiętać, że funkcja sprawdzania poprawności modelu jest dostępna tylko w aktualizacji systemu Windows 10 z października 2018 r. lub nowszej wersji systemu Windows 10, ponieważ narzędzie opiera się na wbudowanym aparacie wnioskowania systemu Windows ML.

Wnioskowanie debugowania
Możesz skorzystać z funkcji debugowania pulpitu nawigacyjnego WinML, aby uzyskać wgląd w sposób przepływu nieprzetworzonych danych przez operatory w modelu. Możesz również zdecydować się na wizualizację tych danych na potrzeby wnioskowania przetwarzania obrazów.
Aby debugować model, wykonaj następujące kroki:
- Przejdź do zakładki
Editi wybierz operatora, dla którego chcesz przechwycić dane pośrednie. Na lewym panelu bocznym pojawiDebugsię menu, w którym możesz wybrać formaty danych pośrednich, które chcesz przechwycić. Dostępne opcje to obecnie text i PNG. Text wyświetli plik tekstowy zawierający wymiary, typ danych i surowe dane tensora wygenerowane przez ten operator. PNG sformatuje te dane do pliku obrazu, który może być przydatny w aplikacjach widzenia komputerowego.
- Przejdź do
Runkarty i wybierz model, który chcesz debugować. - Dla pola
CapturewybierzDebugz listy rozwijanej. - Wybierz obraz wejściowy lub plik csv, który ma zostać dostarczony do modelu podczas wykonywania. Należy pamiętać, że jest to wymagane podczas przechwytywania danych debugowania.
- Wybierz folder wyjściowy, aby wyeksportować dane debugowania.
- Wybierz opcję
Run. Po zakończeniu wykonywania możesz przejść do tego wybranego folderu, aby wyświetlić przechwytywanie debugowania.

Możesz również otworzyć widok debugowania w aplikacji Electron z jedną z następujących opcji:
- Uruchom go za pomocą
flag --dev-tools - Lub wybierz
View -> Toggle Dev Toolsz menu aplikacji - Lub naciśnij
Ctrl + Shift + I.