Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Uwaga / Notatka
W celu zwiększenia funkcjonalności można również używać biblioteki PyTorch z językiem DirectML w systemie Windows.
Na poprzednim etapie tego samouczka zainstalowano narzędzie PyTorch na maszynie. Teraz użyjemy go do skonfigurowania kodu z danymi, których użyjemy do utworzenia modelu.
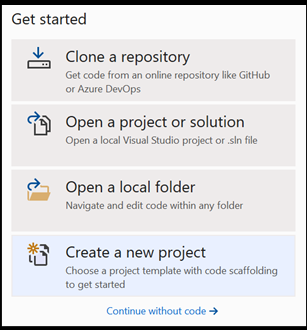
Otwórz nowy projekt w programie Visual Studio.
- Otwórz program Visual Studio i wybierz pozycję
create a new project.
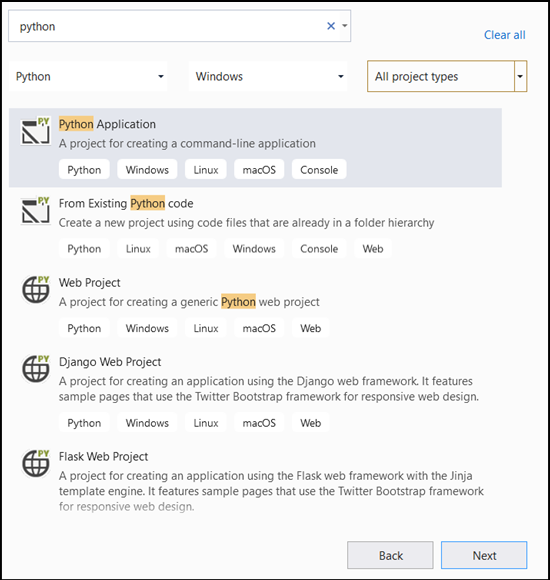
- Na pasku wyszukiwania wpisz
Pythoni wybierz jakoPython Applicationszablon projektu.
- W oknie konfiguracji:
- Nadaj projektowi nazwę. Tutaj nazywamy to PyTorchTraining.
- Wybierz lokalizację projektu.
- Jeśli używasz programu VS2019, upewnij się, że
Create directory for solutionjest zaznaczone. - Jeśli używasz VS 2017, upewnij się, że
Place solution and project in the same directorynie jest zaznaczone.
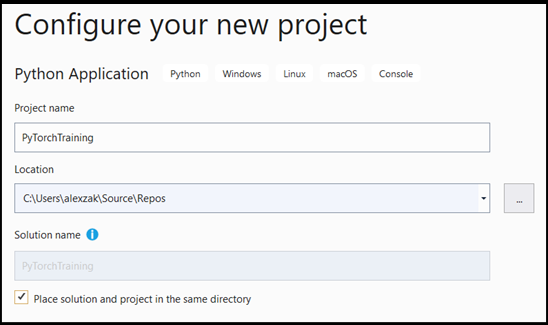
Naciśnij create , aby utworzyć projekt.
Tworzenie interpretera języka Python
Teraz musisz zdefiniować nowy interpreter języka Python. Musi to obejmować ostatnio zainstalowany pakiet PyTorch.
- Przejdź do zaznaczenia interpretera i wybierz pozycję
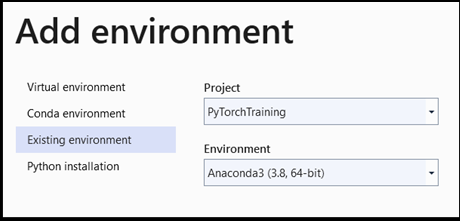
Add environment:
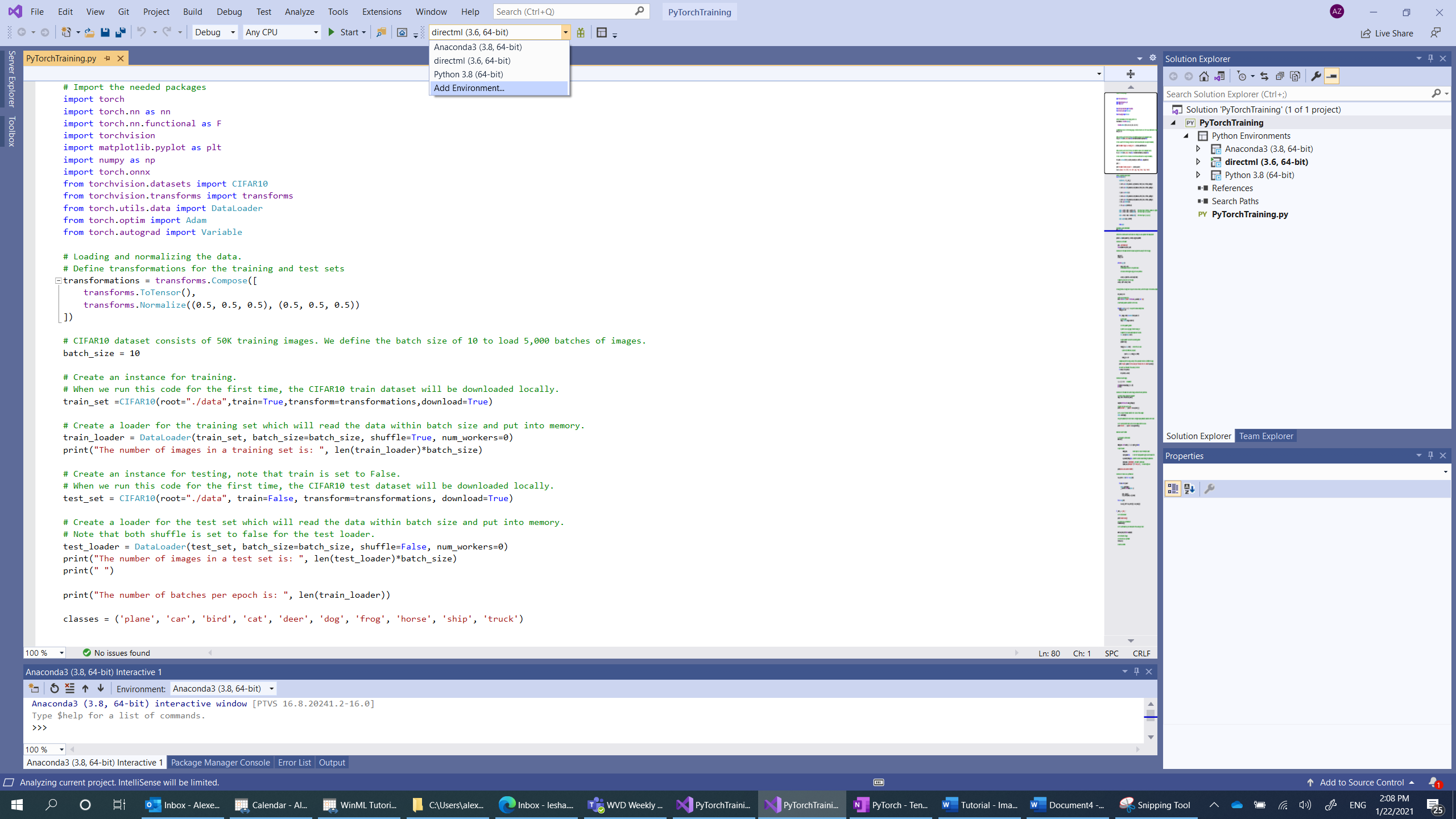
-
Add environmentW oknie wybierz pozycjęExisting environment, a następnie wybierz pozycjęAnaconda3 (3.6, 64-bit). Obejmuje to pakiet PyTorch.
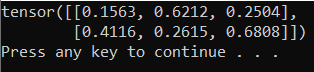
Aby przetestować nowy interpreter języka Python i pakiet PyTorch, wprowadź następujący kod do PyTorchTraining.py pliku:
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
Dane wyjściowe powinny być losowym tensorem 5x3 podobnym do poniższego.
Uwaga / Notatka
Chcesz dowiedzieć się więcej? Odwiedź oficjalną stronę internetową PyTorch.
Ładowanie zestawu danych
Do załadowania danych użyjesz klasy PyTorch torchvision .
Biblioteka Torchvision zawiera kilka popularnych zestawów danych, takich jak Imagenet, CIFAR10, MNIST itp., architektury modeli i typowe przekształcenia obrazów na potrzeby przetwarzania obrazów. To sprawia, że ładowanie danych w narzędziu PyTorch jest dość łatwe.
CIFAR10
W tym miejscu użyjemy zestawu danych CIFAR10 do skompilowania i wytrenowania modelu klasyfikacji obrazów. CIFAR10 jest powszechnie używanym zestawem danych do badań uczenia maszynowego. Składa się z 50 000 obrazów treningowych i 10 000 obrazów testowych. Wszystkie z nich mają rozmiar 3x32x32, co oznacza 3-kanałowe obrazy kolorów 32x32 pikseli w rozmiarze.
Obrazy są podzielone na 10 klas: "samolot" (0), "samochód" (1), "ptak" (2), "kot" (3) , "jelenie" (4), "pies" (5), "żaba" (6), "koń" (7), "statek" (8), "ciężarówka" (9).
Wykonasz trzy kroki, aby załadować i odczytać zestaw danych CIFAR10 w narzędziu PyTorch:
- Zdefiniuj przekształcenia, które mają zostać zastosowane do obrazu: aby wytrenować model, należy przekształcić obrazy w tensory znormalizowanego zakresu [-1,1].
- Utwórz wystąpienie dostępnego zestawu danych i załaduj zestaw danych: aby załadować dane, użyjesz
torch.utils.data.Datasetklasy — klasy abstrakcyjnej do reprezentowania zestawu danych. Zestaw danych zostanie pobrany lokalnie tylko przy pierwszym uruchomieniu kodu. - Uzyskaj dostęp do danych przy użyciu modułu DataLoader. Aby uzyskać dostęp do danych i umieścić je w pamięci, użyjesz
torch.utils.data.DataLoaderklasy . Moduł DataLoader w narzędziu PyTorch opakowuje zestaw danych i zapewnia dostęp do danych bazowych. Ten wrapper będzie przechowywać partie obrazów zgodnie z określonym rozmiarem partii.
Te trzy kroki będą powtarzane zarówno dla zestawów treningowych, jak i testowych.
- Otwórz plik
PyTorchTraining.py filew programie Visual Studio i dodaj następujący kod. Realizuje trzy wymienione wyżej kroki dla zbiorów danych treningowych i testowych z zestawu danych CIFAR10.
from torchvision.datasets import CIFAR10
from torchvision.transforms import transforms
from torch.utils.data import DataLoader
# Loading and normalizing the data.
# Define transformations for the training and test sets
transformations = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# CIFAR10 dataset consists of 50K training images. We define the batch size of 10 to load 5,000 batches of images.
batch_size = 10
number_of_labels = 10
# Create an instance for training.
# When we run this code for the first time, the CIFAR10 train dataset will be downloaded locally.
train_set =CIFAR10(root="./data",train=True,transform=transformations,download=True)
# Create a loader for the training set which will read the data within batch size and put into memory.
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0)
print("The number of images in a training set is: ", len(train_loader)*batch_size)
# Create an instance for testing, note that train is set to False.
# When we run this code for the first time, the CIFAR10 test dataset will be downloaded locally.
test_set = CIFAR10(root="./data", train=False, transform=transformations, download=True)
# Create a loader for the test set which will read the data within batch size and put into memory.
# Note that each shuffle is set to false for the test loader.
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=0)
print("The number of images in a test set is: ", len(test_loader)*batch_size)
print("The number of batches per epoch is: ", len(train_loader))
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
Przy pierwszym uruchomieniu tego kodu zestaw danych CIFAR10 zostanie pobrany na urządzenie.

Dalsze kroki
Gdy dane będą gotowe do użycia, nadszedł czas, aby wytrenować nasz model PyTorch