Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Integrowanie rozpoznawania mowy i zamiany tekstu na mowę (znanej również jako TTS lub synteza mowy) bezpośrednio w środowisko użytkownika aplikacji.
Rozpoznawanie mowy Rozpoznawanie mowy konwertuje wyrazy wypowiadane przez użytkownika na tekst dla danych wejściowych formularza, w przypadku dyktowania tekstu, w celu określenia akcji lub polecenia oraz wykonywania zadań. Obsługiwane są zarówno wstępnie zdefiniowane gramatyki dyktowania bez tekstu, jak i wyszukiwania w Internecie oraz niestandardowe gramatyki utworzone przy użyciu specyfikacji gramatyki rozpoznawania mowy (SRGS) w wersji 1.0.
TTS TTS używa aparatu syntezy mowy (głos) do konwertowania ciągu tekstowego na słowa mówione. Ciąg wejściowy może być podstawowym, niesformatowanym tekstem lub bardziej złożonym językiem znaczników syntezy mowy (SSML). SSML zapewnia standardowy sposób kontrolowania cech wyjścia mowy, takich jak wymowa, głośność, wysokość, tempo, prędkość oraz nacisk.
Inne składniki związane z mową:Cortana w aplikacjach systemu Windows używa dostosowanych poleceń głosowych (mówionych lub wpisanych) w celu uruchomienia aplikacji na pierwszym planie (aplikacja koncentruje się, tak jakby została uruchomiona z menu Start) lub uaktywniła się jako usługa w tle (Cortana zachowuje fokus, ale zapewnia wyniki z aplikacji). Zobacz Interakcje Cortany w aplikacjach systemu Windows.
Projekt interakcji z mową
Zaprojektowana i zaimplementowana przemyślanie mowa może być niezawodnym i przyjemnym sposobem interakcji z aplikacją, uzupełnieniem lub nawet zastępowania klawiatury, myszy, dotyku i gestów.
Te wytyczne i zalecenia opisują, jak najlepiej zintegrować zarówno rozpoznawanie mowy, jak i TTS ze środowiskiem interakcji aplikacji.
Jeśli rozważasz obsługę interakcji mowy w aplikacji:
- Jakie akcje można wykonać za pośrednictwem mowy? Czy użytkownik może przechodzić między stronami, wywoływać polecenia lub wprowadzać dane jako pola tekstowe, krótkie notatki lub długie komunikaty?
- Czy wprowadzanie mowy jest dobrym rozwiązaniem do ukończenia zadania?
- Jak użytkownik wie, kiedy wejście głosowe jest dostępne?
- Czy aplikacja zawsze nasłuchuje, czy użytkownik musi podjąć akcję, aby aplikacja wchodziła w tryb nasłuchiwania?
- Jakie frazy inicjują akcję lub zachowanie? Czy frazy i akcje muszą być wyliczane na ekranie?
- Czy wymagane są ekrany monitu, potwierdzenia, uściślania lub TTS?
- Jakie jest okno dialogowe interakcji między aplikacją a użytkownikiem?
- Czy wymagane jest niestandardowe lub ograniczone słownictwo (takie jak medycyna, nauka lub ustawienia regionalne) dla kontekstu aplikacji?
- Czy łączność sieciowa jest wymagana?
Wprowadzanie tekstu
Mowa na tekst może obejmować zakres od krótkiej formy (pojedynczego słowa lub frazy) do długiej formy (ciągłego dyktowania). Krótkie dane wejściowe formularza muszą być krótsze niż 10 sekund długości, podczas gdy długa sesja wprowadzania formularza może trwać do dwóch minut. (Długie dane wejściowe formularza można ponownie uruchomić bez interwencji użytkownika, aby zapewnić wrażenie ciągłego dyktowania).
Należy podać wizualną wskazówkę, aby wskazać, że rozpoznawanie mowy jest obsługiwane i dostępne dla użytkownika oraz czy użytkownik musi go włączyć. Na przykład przycisk na pasku poleceń z symbolem mikrofonu (zobacz Paski poleceń) może służyć do wyświetlania zarówno dostępności, jak i stanu.
Prześlij bieżącą opinię dotyczącą rozpoznawania, aby zminimalizować wszelkie widoczne braki odpowiedzi podczas wykonywania rozpoznawania.
Zezwalaj użytkownikom na poprawianie tekstu rozpoznawania przy użyciu wprowadzania klawiatury, monitów uściślania, sugestii lub dodatkowego rozpoznawania mowy.
Zatrzymaj rozpoznawanie, jeśli dane wejściowe są wykrywane z urządzenia innego niż rozpoznawanie mowy, takie jak dotyk lub klawiatura. Prawdopodobnie oznacza to, że użytkownik przeniósł się do innego zadania, takiego jak poprawianie tekstu rozpoznawania lub interakcja z innymi polami formularza.
Określ czas, po którym brak danych wejściowych mowy oznacza, że rozpoznawanie się zakończyło. Nie uruchamiaj automatycznie funkcji rozpoznawania po upływie tego czasu, ponieważ zwykle oznacza to, że użytkownik przestał angażować się w aplikację.
Wyłącz cały interfejs użytkownika ciągłego rozpoznawania i zakończ sesję rozpoznawania, jeśli połączenie sieciowe jest niedostępne. Ciągłe rozpoznawanie wymaga połączenia sieciowego.
Komendanta
Wprowadzanie mowy może inicjować akcje, wywoływać polecenia i wykonywać zadania.
Jeśli miejsce zezwala, rozważ wyświetlenie obsługiwanych odpowiedzi dla bieżącego kontekstu aplikacji z przykładami prawidłowych danych wejściowych. Zmniejsza to potencjalne reakcje, które aplikacja musi przetworzyć, a także eliminuje zamieszanie dla użytkownika.
Spróbuj formułować swoje pytania tak, aby uzyskać jak najbardziej konkretną odpowiedź. Na przykład "Co chcesz zrobić dzisiaj?" jest bardzo otwarty i wymaga bardzo dużej definicji gramatycznej ze względu na to, jak zróżnicowane mogą być odpowiedzi. Alternatywnie: "Czy chcesz grać lub słuchać muzyki?" ogranicza odpowiedź na jedną z dwóch prawidłowych odpowiedzi z odpowiednio małą definicją gramatyczną. Mała gramatyka jest znacznie łatwiejsza do tworzenia i powoduje znacznie dokładniejsze wyniki rozpoznawania.
Zażądaj potwierdzenia od użytkownika, gdy zaufanie do rozpoznawania mowy jest niskie. Jeśli intencja użytkownika jest niejasna, lepiej uzyskać wyjaśnienie niż zainicjować niezamierzoną akcję.
Należy podać wizualną wskazówkę, aby wskazać, że rozpoznawanie mowy jest obsługiwane i dostępne dla użytkownika oraz czy użytkownik musi go włączyć. Na przykład przycisk paska poleceń z ikoną mikrofonu (zobacz Wytyczne dla pasków poleceń) może być użyty do prezentowania zarówno dostępności, jak i statusu.
Jeśli przełącznik rozpoznawania mowy jest zwykle poza widokiem, rozważ wyświetlenie wskaźnika stanu w obszarze zawartości aplikacji.
Jeśli rozpoznawanie jest inicjowane przez użytkownika, rozważ użycie wbudowanego środowiska rozpoznawania w celu zapewnienia spójności. Wbudowane środowisko zawiera dostosowywalne ekrany z monitami, przykładami, uściślaniem, potwierdzeniami i błędami.
Ekrany różnią się w zależności od określonych ograniczeń:
Wstępnie zdefiniowana gramatyka (dyktowanie lub wyszukiwanie w Internecie)
- Ekran Nasłuchiwania.
- Ekran Myślenie .
- Ekran 'Słyszałem, co mówisz' lub ekran błędu.
Lista wyrazów lub fraz lub pliku gramatycznego SRGS
- Ekran Nasłuchiwania.
- Ekran "Czy powiedziałeś", jeśli to, co użytkownik powiedział, może być interpretowane jako więcej niż jeden możliwy wynik.
- Ekran 'Słyszałem, co mówisz' lub ekran błędu.
Na ekranie Nasłuchiwanie można wykonywać następujące czynności:
- Dostosuj tekst nagłówka.
- Podaj przykładowy tekst tego, co użytkownik może powiedzieć.
- Określ, czy wyświetlany jest ekran Usłyszałem, jak mówisz.
- Odczytaj rozpoznany ciąg dla użytkownika na ekranie Usłyszane słowa.
Oto przykład wbudowanego procesu rozpoznawania mowy, który używa ograniczenia zdefiniowanego przez SRGS. W tym przykładzie rozpoznawanie mowy zakończy się pomyślnie.
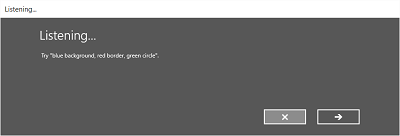

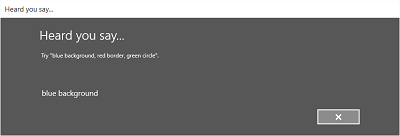
Zawsze nasłuchiwanie
Aplikacja może nasłuchiwać i rozpoznawać dane wejściowe mowy natychmiast po uruchomieniu aplikacji bez interwencji użytkownika.
Należy dostosować ograniczenia gramatyczne na podstawie kontekstu aplikacji. Dzięki temu środowisko rozpoznawania mowy jest bardzo ukierunkowane i istotne dla bieżącego zadania oraz minimalizuje błędy.
"Co mogę powiedzieć?"
Po włączeniu wprowadzania mowy ważne jest, aby ułatwić użytkownikom odkrywanie, co dokładnie można zrozumieć i jakie akcje można wykonać.
Jeśli rozpoznawanie mowy jest włączone przez użytkownika, rozważ użycie paska poleceń lub polecenia menu, aby wyświetlić wszystkie wyrazy i frazy obsługiwane w bieżącym kontekście.
Jeśli rozpoznawanie mowy jest zawsze włączone, rozważ dodanie frazy "Co mogę powiedzieć?" do każdej strony. Gdy użytkownik wpisze tę frazę, wyświetl wszystkie wyrazy i frazy obsługiwane w bieżącym kontekście. Użycie tej frazy umożliwia użytkownikom spójne odnajdywanie możliwości mowy w całym systemie.
Błędy rozpoznawania
Rozpoznawanie mowy zakończy się niepowodzeniem. Błędy występują, gdy jakość dźwięku jest niska, gdy rozpoznana jest tylko część frazy lub gdy w ogóle nie wykryto żadnych danych wejściowych.
Poradź sobie z błędem w uprzejmy sposób, pomóż użytkownikowi zrozumieć, dlaczego rozpoznawanie się nie powiodło, i jak można się z tym uporać.
Aplikacja powinna poinformować użytkownika, że nie został zrozumiany i że musi spróbować ponownie.
Rozważ podanie przykładów co najmniej jednej lub więcej obsługiwanych fraz. Użytkownik prawdopodobnie powtórzy sugerowaną frazę, co zwiększa powodzenie rozpoznawania.
Należy wyświetlić listę potencjalnych dopasowań, z których użytkownik może wybierać. Może to być o wiele bardziej wydajne niż ponowne przejście przez proces rozpoznawania.
Zawsze należy obsługiwać alternatywne typy danych wejściowych, co jest szczególnie przydatne w przypadku obsługi powtarzających się błędów rozpoznawania. Możesz na przykład zasugerować użytkownikowi, aby spróbował użyć klawiatury lub skorzystać z ekranu dotykowego albo myszy, aby wybrać z listy potencjalnych dopasowań.
Użyj wbudowanego środowiska rozpoznawania mowy, ponieważ zawiera ekrany informujące użytkownika, że rozpoznawanie nie powiodło się i umożliwia użytkownikowi podjęcie kolejnej próby rozpoznawania.
Posłuchaj i postaraj się rozwiązać problemy we wejściu audio. Rozpoznawanie mowy może wykrywać problemy z jakością dźwięku, które mogą niekorzystnie wpływać na dokładność rozpoznawania mowy. Możesz użyć informacji dostarczonych przez rozpoznawanie mowy, aby poinformować użytkownika o problemie i pozwolić im podjąć działania naprawcze, jeśli to możliwe. Jeśli na przykład ustawienie głośności w mikrofonie jest zbyt niskie, możesz poprosić użytkownika o głośniejsze wypowiadanie lub zwiększenie głośności.
Constraints
Ograniczenia lub gramatyki definiują wypowiedziane słowa i frazy, które mogą być dopasowane przez rozpoznawanie mowy. Możesz określić jedną ze wstępnie zdefiniowanych gramatyki usługi internetowej lub utworzyć niestandardową gramatykę zainstalowaną w aplikacji.
Wstępnie zdefiniowane gramatyki
Predefiniowane dyktowanie i gramatyki wyszukiwania internetowego zapewniają rozpoznawanie mowy dla aplikacji bez konieczności tworzenia gramatyki. W przypadku korzystania z tych gramatyk rozpoznawanie mowy jest wykonywane przez zdalną usługę internetową, a wyniki są zwracane do urządzenia
- Domyślna gramatyka dyktowania tekstu może rozpoznawać większość wyrazów i fraz, które użytkownik może powiedzieć w określonym języku i jest zoptymalizowany pod kątem rozpoznawania krótkich fraz. Dyktowanie bez tekstu jest przydatne, gdy nie chcesz ograniczać rodzajów rzeczy, które użytkownik może powiedzieć. Typowe zastosowania obejmują tworzenie notatek lub dyktowanie zawartości komunikatu.
- Gramatyka wyszukiwania w Internecie, taka jak gramatyka dyktowania, zawiera dużą liczbę słów i fraz, które użytkownik może powiedzieć. Jest ona jednak zoptymalizowana pod kątem rozpoznawania terminów, których użytkownicy zazwyczaj używają podczas wyszukiwania w Internecie.
Uwaga / Notatka
Ponieważ wstępnie zdefiniowane gramatyki dyktowania i wyszukiwania w sieci mogą być duże i działają online (nie na urządzeniu), wydajność może być wolniejsza niż w przypadku niestandardowej gramatyki zainstalowanej na urządzeniu.
Te wstępnie zdefiniowane gramatyki mogą służyć do rozpoznawania do 10 sekund danych wejściowych mowy i nie wymagają nakładu pracy podczas tworzenia. Jednak wymagają one połączenia z siecią.
Niestandardowe gramatyki
Niestandardowa gramatyka została zaprojektowana i utworzona przez Ciebie i zainstalowana razem z aplikacją. Rozpoznawanie mowy przy użyciu niestandardowego ograniczenia jest wykonywane na urządzeniu.
Ograniczenia listy programowej zapewniają lekkie podejście do tworzenia prostych gramatyk przy użyciu listy wyrazów lub fraz. Ograniczenie listy dobrze sprawdza się w przypadku rozpoznawania krótkich, odrębnych fraz. Jawne określanie wszystkich wyrazów w gramatyce zwiększa również dokładność rozpoznawania, ponieważ aparat rozpoznawania mowy musi przetwarzać mowę tylko w celu potwierdzenia dopasowania. Lista może być również aktualizowana programowo.
Gramatyka SRGS jest dokumentem statycznym, który w przeciwieństwie do ograniczenia listy programowej używa formatu XML zdefiniowanego przez SRGS w wersji 1.0. Gramatyka SRGS zapewnia największą kontrolę nad środowiskiem rozpoznawania mowy, umożliwiając przechwytywanie wielu semantycznych znaczeń w jednym rozpoznawaniu.
Poniżej przedstawiono kilka wskazówek dotyczących tworzenia gramatyki SRGS:
- Zachowaj każdą gramatykę małą. Gramatyki, które zawierają mniej fraz, zwykle zapewniają dokładniejsze rozpoznawanie niż większe gramatyki zawierające wiele fraz. Lepiej jest mieć kilka mniejszych gramatyki dla określonych scenariuszy niż mieć jedną gramatykę dla całej aplikacji.
- Poinformuj użytkowników, co należy powiedzieć dla każdego kontekstu aplikacji, i włącz i wyłącz gramatyki zgodnie z potrzebami.
- Projektuj każdą gramatykę, aby użytkownicy mogli wyrażać polecenia na różne sposoby. Na przykład możesz użyć reguły GARBAGE , aby dopasować dane wejściowe mowy, których gramatyka nie definiuje. Dzięki temu użytkownicy mogą mówić dodatkowe słowa, które nie mają znaczenia dla aplikacji. Na przykład "daj mi", "i", "eeee", "może", itd.
- Użyj elementu sapi:subset , aby ułatwić dopasowanie danych wejściowych mowy. Jest to rozszerzenie firmy Microsoft do specyfikacji SRGS, które pomaga dopasować frazy częściowe.
- Staraj się unikać definiowania fraz w gramatyce, które zawierają tylko jedną sylaable. Rozpoznawanie wydaje się być bardziej dokładne w przypadku fraz zawierających co najmniej dwie sylaby.
- Unikaj używania fraz, które brzmią podobnie. Na przykład frazy takie jak "hello", "bellow" i "fellow" mogą mylić aparat rozpoznawania i powodować niską dokładność rozpoznawania.
Uwaga / Notatka
Jakiego typu ograniczenia używasz, zależy od złożoności środowiska rozpoznawania, które chcesz utworzyć. Każda z opcji może być najlepszym wyborem dla określonego zadania rozpoznawania i można znaleźć użycie dla wszystkich typów ograniczeń w aplikacji.
Wymowa niestandardowa
Jeśli aplikacja zawiera specjalistyczne słownictwo z niezwykłymi lub fikcyjnymi słowami lub słowami o nietypowej wymowie, może być w stanie poprawić wydajność rozpoznawania tych słów, definiując wymowę niestandardową.
Aby uzyskać małą listę wyrazów i fraz lub listę rzadko używanych wyrazów i fraz, można utworzyć niestandardowe wymowy w gramatyce SRGS. Aby uzyskać więcej informacji, zobacz token, element .
W przypadku większych list wyrazów i fraz lub często używanych wyrazów i fraz można utworzyć oddzielne dokumenty leksykonu wymowy. Aby uzyskać więcej informacji, zobacz About Lexicons and Phonetic Alphabets (Informacje o leksykonach i alfabetach fonetycznych ).
Testing
Przetestuj dokładność rozpoznawania mowy i dowolny pomocniczy interfejs użytkownika z docelowymi odbiorcami aplikacji. Jest to najlepszy sposób na określenie skuteczności środowiska interakcji mowy w aplikacji. Czy na przykład użytkownicy uzyskują słabe wyniki rozpoznawania, ponieważ aplikacja nie nasłuchuje typowej frazy?
Zmodyfikuj gramatykę, aby obsługiwać tę frazę, lub udostępnić użytkownikom listę obsługiwanych fraz. Jeśli już podasz listę obsługiwanych fraz, upewnij się, że można je łatwo odnaleźć.
Zamiana tekstu na mowę (TTS)
Usługa TTS generuje dane wyjściowe mowy na podstawie zwykłego tekstu lub SSML.
Staraj się zaprojektować monity, które są uprzejme i zachęcające.
Zastanów się, czy należy odczytać długie ciągi tekstu. To jedna rzecz, aby słuchać wiadomości SMS, ale całkiem innej, aby słuchać długiej listy wyników wyszukiwania, które są trudne do zapamiętania.
Należy podać kontrolki multimediów, aby umożliwić użytkownikom wstrzymanie lub zatrzymanie usługi TTS.
Należy słuchać wszystkich ciągów TTS, aby upewnić się, że są one zrozumiałe i brzmią naturalnie.
- Łączenie nietypowej sekwencji słów bądź wymienianie numerów części lub interpunkcji może spowodować, że fraza stanie się niezrozumiała.
- Mowa może brzmieć nienaturalne, gdy prosodia lub kadencja różni się od tego, w jaki sposób prelegent natywny powiedziałby frazę.
Oba problemy można rozwiązać przy użyciu języka SSML zamiast zwykłego tekstu jako danych wejściowych syntetyzatora mowy. Aby uzyskać więcej informacji na temat języka SSML, zobacz Używanie języka SSML do kontrolowania syntetyzowanej mowy i dokumentacji języka znaczników syntezy mowy.
Inne artykuły w tej sekcji
| Temat | Description |
|---|---|
| Rozpoznawanie mowy | Rozpoznawanie mowy umożliwia podawanie danych wejściowych, określanie akcji lub polecenia i wykonywanie zadań. |
| Określanie języka rozpoznawania mowy | Dowiedz się, jak wybrać zainstalowany język do użycia na potrzeby rozpoznawania mowy. |
| Definiowanie ograniczeń rozpoznawania niestandardowego | Dowiedz się, jak definiować i używać ograniczeń niestandardowych do rozpoznawania mowy. |
| Włączanie ciągłego dyktowania | Dowiedz się, jak rejestrować i rozpoznawać długie, ciągłe dyktowane dane mowy. |
| Zarządzanie problemami z wejściem audio | Dowiedz się, jak zarządzać problemami związanymi z dokładnością rozpoznawania mowy w wyniku jakości wejścia audio. |
| Ustawianie limitów czasu rozpoznawania mowy | Ustaw, jak długo rozpoznawanie mowy ignoruje milczenie lub nierozpoznawalne dźwięki (babble) i kontynuuje nasłuchiwanie danych wejściowych mowy. |
Powiązane artykuły
Próbki
Współpracuj z nami na GitHub
Źródło tej treści można znaleźć na GitHubie, gdzie można także tworzyć i przeglądać problemy oraz pull requesty. Więcej informacji znajdziesz w naszym przewodniku dla współautorów.

Windows developer