Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Większość nowoczesnych procesorów GPU zawiera wiele niezależnych aparatów, które zapewniają wyspecjalizowane funkcje. Wiele z nich ma co najmniej jeden dedykowany aparat kopiowania i aparat obliczeniowy, zwykle różni się od aparatu 3D. Każdy z tych aparatów może wykonywać polecenia równolegle ze sobą. Funkcja Direct3D 12 zapewnia precyzyjny dostęp do aparatów 3D, obliczeń i kopiowania przy użyciu kolejek i list poleceń.
Aparaty procesora GPU
Na poniższym diagramie przedstawiono wątki procesora CPU tytułu, z których każdy wypełnia co najmniej jedną kolejkę kopiowania, obliczeń i 3D. Kolejka 3D może obsługiwać wszystkie trzy aparaty procesora GPU; kolejka obliczeniowa może obsługiwać aparaty obliczeniowe i aparaty kopiowania; i kolejka kopiowania po prostu aparat kopiowania.
Ponieważ różne wątki wypełniają kolejki, nie może istnieć prosta gwarancja kolejności wykonywania, dlatego potrzeba mechanizmów synchronizacji — gdy tytuł ich wymaga.

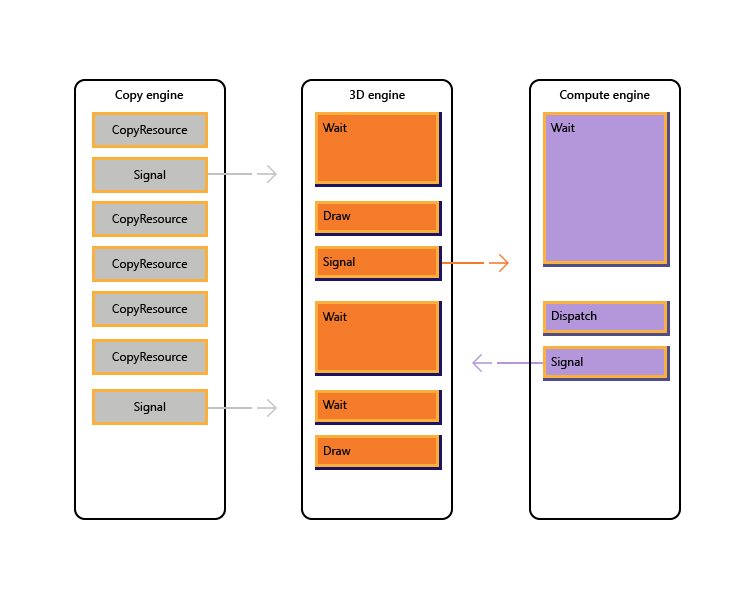
Na poniższej ilustracji przedstawiono, jak tytuł może planować pracę w wielu aparatach GPU, w tym synchronizację między aparatami w razie potrzeby: pokazuje obciążenia poszczególnych aparatów z zależnościami między aparatami. W tym przykładzie aparat kopiowania najpierw kopiuje pewną geometrię niezbędną do renderowania. Aparat 3D czeka na ukończenie tych kopii i renderuje wstępne przejście przez geometrię. Jest to następnie używane przez aparat obliczeniowy. Wyniki aparatu obliczeniowego Dispatch, wraz z kilkoma operacjami kopiowania tekstur na silniku kopiowania, są używane przez aparat 3D na potrzeby ostatniego wywołania Draw.
Poniższy pseudo-kod ilustruje, jak tytuł może przesyłać takie obciążenie.
// Get per-engine contexts. Note that multiple queues may be exposed
// per engine, however that design is not reflected here.
copyEngine = device->GetCopyEngineContext();
renderEngine = device->GetRenderEngineContext();
computeEngine = device->GetComputeEngineContext();
copyEngine->CopyResource(geometry, ...); // copy geometry
copyEngine->Signal(copyFence, 101);
copyEngine->CopyResource(tex1, ...); // copy textures
copyEngine->CopyResource(tex2, ...); // copy more textures
copyEngine->CopyResource(tex3, ...); // copy more textures
copyEngine->CopyResource(tex4, ...); // copy more textures
copyEngine->Signal(copyFence, 102);
renderEngine->Wait(copyFence, 101); // geometry copied
renderEngine->Draw(); // pre-pass using geometry only into rt1
renderEngine->Signal(renderFence, 201);
computeEngine->Wait(renderFence, 201); // prepass completed
computeEngine->Dispatch(); // lighting calculations on pre-pass (using rt1 as SRV)
computeEngine->Signal(computeFence, 301);
renderEngine->Wait(computeFence, 301); // lighting calculated into buf1
renderEngine->Wait(copyFence, 102); // textures copied
renderEngine->Draw(); // final render using buf1 as SRV, and tex[1-4] SRVs
Poniższy pseudokod ilustruje synchronizację między aparatami kopiowania i 3D w celu osiągnięcia alokacji pamięci podobnej do sterty za pośrednictwem buforu pierścieniowego. Tytuły mają elastyczność wyboru właściwej równowagi między maksymalizacją równoległości (za pośrednictwem dużego buforu) a zmniejszeniem zużycia pamięci i opóźnieniami (za pośrednictwem małego buforu).
device->CreateBuffer(&ringCB);
for(int i=1;i++){
if(i > length) copyEngine->Wait(fence1, i - length);
copyEngine->Map(ringCB, value%length, WRITE, pData); // copy new data
copyEngine->Signal(fence2, i);
renderEngine->Wait(fence2, i);
renderEngine->Draw(); // draw using copied data
renderEngine->Signal(fence1, i);
}
// example for length = 3:
// copyEngine->Map();
// copyEngine->Signal(fence2, 1); // fence2 = 1
// copyEngine->Map();
// copyEngine->Signal(fence2, 2); // fence2 = 2
// copyEngine->Map();
// copyEngine->Signal(fence2, 3); // fence2 = 3
// copy engine has exhausted the ring buffer, so must wait for render to consume it
// copyEngine->Wait(fence1, 1); // fence1 == 0, wait
// renderEngine->Wait(fence2, 1); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 1); // fence1 = 1, copy engine now unblocked
// renderEngine->Wait(fence2, 2); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 2); // fence1 = 2
// renderEngine->Wait(fence2, 3); // fence2 == 3, pass
// renderEngine->Draw();
// renderEngine->Signal(fence1, 3); // fence1 = 3
// now render engine is starved, and so must wait for the copy engine
// renderEngine->Wait(fence2, 4); // fence2 == 3, wait
Scenariusze z wieloma aparatami
Funkcja Direct3D 12 pozwala uniknąć przypadkowego braku wydajności spowodowanego nieoczekiwanymi opóźnieniami synchronizacji. Umożliwia również wprowadzenie synchronizacji na wyższym poziomie, na którym można określić wymaganą synchronizację z większą pewnością. Drugim problemem, który dotyczy wielu aparatów, jest zwiększenie czytelności kosztownych operacji, które obejmują przejścia między 3D i wideo, które były tradycyjnie kosztowne z powodu synchronizacji między wieloma kontekstami jądra.
W szczególności następujące scenariusze można rozwiązać za pomocą funkcji Direct3D 12.
- Asynchroniczna i niska priorytet pracy procesora GPU. Umożliwia to współbieżne wykonywanie pracy procesora GPU o niskim priorytcie i niepodzielnych operacji, które umożliwiają jednemu wątkowi procesora GPU korzystanie z wyników innego niezsynchronizowanego wątku bez blokowania.
- Praca obliczeniowa o wysokim priorytcie. W przypadku obliczeń w tle można przerwać renderowanie 3D, aby wykonać niewielką ilość pracy obliczeniowej o wysokim priorytcie. Wyniki tej pracy można uzyskać wcześnie na potrzeby dodatkowego przetwarzania procesora CPU.
- Praca obliczeniowa w tle. Oddzielna kolejka o niskim priorytcie dla obciążeń obliczeniowych umożliwia aplikacji wykorzystanie wolnych cykli procesora GPU do wykonywania obliczeń w tle bez negatywnego wpływu na podstawowe zadania renderowania (lub innych). Zadania w tle mogą obejmować dekompresację zasobów lub aktualizowanie symulacji lub struktur przyspieszania. Zadania w tle powinny być synchronizowane rzadko (około raz na ramkę), aby uniknąć wstrzymania lub spowolnienia pracy na pierwszym planie.
- Przesyłanie strumieniowe i przekazywanie danych. Oddzielna kolejka kopiowania zastępuje pojęcia D3D11 dotyczące początkowych danych i aktualizowania zasobów. Mimo że aplikacja jest odpowiedzialna za więcej szczegółów w modelu Direct3D 12, ta odpowiedzialność wiąże się z mocą. Aplikacja może kontrolować ilość pamięci systemowej poświęconej buforowaniu danych przekazywania. Aplikacja może wybrać, kiedy i jak (procesor CPU a procesor GPU, blokowanie i nieblokowanie) do synchronizacji i może śledzić postęp i kontrolować ilość pracy w kolejce.
- Zwiększona równoległość. Aplikacje mogą używać bardziej szczegółowych kolejek dla obciążeń w tle (np. dekodowania wideo), gdy mają oddzielne kolejki dla pracy na pierwszym planie.
W wersji Direct3D 12 pojęcie kolejki poleceń to reprezentacja interfejsu API w przybliżeniu szeregowej sekwencji pracy przesłanej przez aplikację. Bariery i inne techniki umożliwiają wykonanie tej pracy w potoku lub poza kolejnością, ale aplikacja widzi tylko jedną oś czasu ukończenia. Odpowiada to bezpośredniemu kontekstowi w D3D11.
Interfejsy API synchronizacji
Urządzenia i kolejki
Urządzenie Direct3D 12 ma metody tworzenia i pobierania kolejek poleceń różnych typów i priorytetów. Większość aplikacji powinna używać domyślnych kolejek poleceń, ponieważ umożliwiają one współużytkowane użycie przez inne składniki. Aplikacje z dodatkowymi wymaganiami współbieżności mogą tworzyć dodatkowe kolejki. Kolejki są określane przez typ listy poleceń, z którego korzystają.
Zapoznaj się z następującymi metodami tworzenia ID3D12Device.
- CreateCommandQueue : tworzy kolejkę poleceń na podstawie informacji w strukturze 12_COMMAND_QUEUE_DESCDirect3D.
- CreateCommandList : tworzy listę poleceń typu Direct3D 12_COMMAND_LIST_TYPE.
- CreateFence : tworzy ogrodzenie, zwracając uwagi na flagi w Direct3D 12_FENCE_FLAGS. Ogrodzenia służą do synchronizowania kolejek.
Kolejki wszystkich typów (3D, obliczeń i kopiowania) współużytkują ten sam interfejs i są oparte na liście poleceń.
Zapoznaj się z następującymi metodami ID3D12CommandQueue.
- ExecuteCommandLists : przesyła tablicę list poleceń do wykonania. Każda lista poleceń zdefiniowana przez ID3D12CommandList.
- Signal : ustawia wartość ogrodzenia, gdy kolejka (uruchomiona na procesorze GPU) osiągnie określony punkt.
- Wait : kolejka czeka, aż określone ogrodzenie osiągnie określoną wartość.
Należy pamiętać, że pakiety nie są używane przez żadne kolejki i dlatego tego typu nie można użyć do utworzenia kolejki.
Ogrodzenia
Interfejs API z wieloma aparatami udostępnia jawne interfejsy API do tworzenia i synchronizowania przy użyciu ogrodzeń. Ogrodzenie to konstrukcja synchronizacji kontrolowana przez wartość UINT64. Wartości ogrodzenia są ustawiane przez aplikację. Operacja sygnału modyfikuje wartość ogrodzenia i bloki operacji oczekiwania do momentu osiągnięcia żądanej wartości lub większej przez ogrodzenie. Zdarzenie może zostać wyzwolone, gdy ogrodzenie osiągnie określoną wartość.
Zapoznaj się z metodami interfejsu ID3D12Fence.
- getCompletedValue : zwraca bieżącą wartość ogrodzenia.
- SetEventOnCompletion : powoduje wyzwolenie zdarzenia, gdy ogrodzenie osiągnie daną wartość.
- signal : ustawia ogrodzenie na daną wartość.
Ogrodzenia umożliwiają dostęp procesora CPU do bieżącej wartości ogrodzenia oraz oczekiwania i sygnały procesora CPU.
Metoda Signal w interfejsie ID3D12Fence aktualizuje ogrodzenie po stronie procesora CPU. Ta aktualizacja jest wykonywana natychmiast. Metoda Signal na ID3D12CommandQueu e aktualizuje ogrodzenie po stronie procesora GPU. Ta aktualizacja jest wykonywana po zakończeniu wszystkich innych operacji w kolejce poleceń.
Wszystkie węzły w konfiguracji z wieloma aparatami mogą odczytywać i reagować na wszelkie ogrodzenia osiągające odpowiednią wartość.
Aplikacje ustawiają własne wartości ogrodzenia, dobrym punktem wyjścia może być zwiększenie ogrodzenia raz na ramę.
Ogrodzenie może być zwound. Oznacza to, że wartość ogrodzenia nie musi mieć wyłącznie przyrostu. Jeśli operacja Signal jest w kolejce dwóch różnych kolejek poleceń lub jeśli dwa wątki procesora CPU są wywoływane Signal na ogrodzeniu, może być wyścig, aby określić, który Signal zostanie ukończony ostatnio, a tym samym wartość ogrodzenia jest wartością ogrodzenia, która pozostanie. Jeśli ogrodzenie zostanie ponownie wyświetlone, wszelkie nowe oczekiwania (w tym SetEventOnCompletion żądania) zostaną porównane z nową niższą wartością ogrodzenia, a zatem może nie być spełnione, nawet jeśli wartość ogrodzenia była wcześniej wystarczająco wysoka, aby je spełnić. Jeśli wystąpi wyścig, między wartością, która spełni zaległe oczekiwanie, a niższą wartością, która nie będzie, oczekiwania będzie spełniony, niezależnie od tego, która wartość pozostanie później.
Interfejsy API ogrodzenia zapewniają zaawansowane funkcje synchronizacji, ale mogą potencjalnie utrudnić debugowanie problemów. Zaleca się, aby każde ogrodzenie było używane tylko do wskazywania postępu na jednej osi czasu, aby zapobiec wyścigom między sygnalizatorami.
Kopiowanie i obliczanie list poleceń
Wszystkie trzy typy listy poleceń używają interfejsu ID3D12GraphicsCommandList, jednak tylko podzbiór metod jest obsługiwany w przypadku kopiowania i obliczeń.
Listy poleceń kopiowania i obliczeń mogą używać następujących metod.
Listy poleceń obliczeniowych mogą również używać następujących metod.
- ClearState
- ClearUnorderedAccessViewFloat
- ClearUnorderedAccessViewUint
- OdrzućResource
- Dispatch
- ExecuteIndirect
- SetComputeRoot32BitConstant
- SetComputeRoot32BitConstants
- SetComputeRootConstantBufferView
- SetComputeRootDescriptorTable
- SetComputeRootShaderResourceView
- SetComputeRootSignature
- SetComputeRootUnorderedAccessView
- SetDescriptorHeaps
- SetPipelineState
- SetPredication
- EndQuery
Listy poleceń obliczeniowych muszą ustawić wartość PSO obliczeniową podczas wywoływania SetPipelineState.
Nie można używać pakietów z listami poleceń lub kolejkami obliczeniowymi ani kopiami.
Przykład obliczeń potokowych i grafiki
W tym przykładzie pokazano, jak można użyć synchronizacji ogrodzenia w celu utworzenia potoku pracy obliczeniowej w kolejce (przywołyszonej przez pComputeQueue), który jest używany przez pracę grafiki w kolejce pGraphicsQueue. Praca obliczeniowa i grafiki jest potokowana przy użyciu kolejki grafiki zużywających wynik pracy obliczeniowej z kilku ramek z powrotem, a zdarzenie procesora CPU jest używane do ograniczania całkowitej liczby pracy w kolejce.
void PipelinedComputeGraphics()
{
const UINT CpuLatency = 3;
const UINT ComputeGraphicsLatency = 2;
HANDLE handle = CreateEvent(nullptr, FALSE, FALSE, nullptr);
UINT64 FrameNumber = 0;
while (1)
{
if (FrameNumber > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsFence,
FrameNumber - ComputeGraphicsLatency);
}
if (FrameNumber > CpuLatency)
{
pComputeFence->SetEventOnFenceCompletion(
FrameNumber - CpuLatency,
handle);
WaitForSingleObject(handle, INFINITE);
}
++FrameNumber;
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumber);
if (FrameNumber > ComputeGraphicsLatency)
{
UINT GraphicsFrameNumber = FrameNumber - ComputeGraphicsLatency;
pGraphicsQueue->Wait(pComputeFence, GraphicsFrameNumber);
pGraphicsQueue->ExecuteCommandLists(1, &pGraphicsCommandList);
pGraphicsQueue->Signal(pGraphicsFence, GraphicsFrameNumber);
}
}
}
Aby obsługiwać to potokowanie, musi istnieć bufor ComputeGraphicsLatency+1 różnych kopii danych przekazywanych z kolejki obliczeniowej do kolejki grafiki. Listy poleceń muszą używać widoków UAV i pośredniego do odczytu i zapisu z odpowiedniej "wersji" danych w buforze. Kolejka obliczeniowa musi czekać, aż kolejka grafiki zakończy odczytywanie danych z ramki N, zanim będzie mogła zapisywać ramkę N+ComputeGraphicsLatency.
Należy pamiętać, że ilość kolejki obliczeniowej działała względem procesora CPU nie zależy bezpośrednio od wymaganej ilości buforowania, jednak kolejkowanie pracy procesora GPU poza ilością dostępnego miejsca w buforze jest mniej cenne.
Alternatywnym mechanizmem uniknięcia pośrednicości byłoby utworzenie wielu list poleceń odpowiadających każdej z "zmienionych" wersji danych. W następnym przykładzie użyto tej techniki podczas rozszerzania poprzedniego przykładu w celu umożliwienia bardziej asynchronicznego uruchamiania kolejek obliczeniowych i graficznych.
Przykład obliczeń asynchronicznych i grafiki
W następnym przykładzie grafiki mogą być renderowane asynchronicznie z kolejki obliczeniowej. Nadal istnieje stała ilość buforowanych danych między dwoma etapami, jednak teraz praca graficzna jest kontynuowana niezależnie i używa najbardziej up-to- data wyniku etapu obliczeniowego znanego na procesorze, gdy praca grafiki jest kolejkowana. Byłoby to przydatne, jeśli praca grafiki była aktualizowana przez inne źródło, na przykład dane wejściowe użytkownika. Musi istnieć wiele list poleceń, aby umożliwić ComputeGraphicsLatency ramek pracy grafiki w locie naraz, a funkcja UpdateGraphicsCommandList reprezentuje aktualizowanie listy poleceń, aby uwzględnić najnowsze dane wejściowe i odczytać z danych obliczeniowych z odpowiedniego buforu.
Kolejka obliczeniowa musi nadal czekać na zakończenie kolejki grafiki z potoku, ale wprowadzono trzecie ogrodzenie (pGraphicsComputeFence), aby można było śledzić postęp pracy obliczeniowej odczytu grafiki w porównaniu z postępem grafiki. Odzwierciedla to fakt, że teraz kolejne ramki graficzne mogą odczytywać z tego samego wyniku obliczeniowego lub pominąć wynik obliczeniowy. Wydajniejszy, ale nieco bardziej skomplikowany projekt będzie używać tylko pojedynczego ogrodzenia graficznego i przechowywać mapowanie ramek obliczeniowych używanych przez każdą ramkę graficzną.
void AsyncPipelinedComputeGraphics()
{
const UINT CpuLatency{ 3 };
const UINT ComputeGraphicsLatency{ 2 };
// The compute fence is at index 0; the graphics fence is at index 1.
ID3D12Fence* rgpFences[]{ pComputeFence, pGraphicsFence };
HANDLE handles[2];
handles[0] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
handles[1] = CreateEvent(nullptr, FALSE, TRUE, nullptr);
UINT FrameNumbers[]{ 0, 0 };
ID3D12GraphicsCommandList* rgpGraphicsCommandLists[CpuLatency];
CreateGraphicsCommandLists(ARRAYSIZE(rgpGraphicsCommandLists),
rgpGraphicsCommandLists);
// Graphics needs to wait for the first compute frame to complete; this is the
// only wait that the graphics queue will perform.
pGraphicsQueue->Wait(pComputeFence, 1);
while (true)
{
for (auto i = 0; i < 2; ++i)
{
if (FrameNumbers[i] > CpuLatency)
{
rgpFences[i]->SetEventOnCompletion(
FrameNumbers[i] - CpuLatency,
handles[i]);
}
else
{
::SetEvent(handles[i]);
}
}
auto WaitResult = ::WaitForMultipleObjects(2, handles, FALSE, INFINITE);
if (WaitResult > WAIT_OBJECT_0 + 1) continue;
auto Stage = WaitResult - WAIT_OBJECT_0;
++FrameNumbers[Stage];
switch (Stage)
{
case 0:
{
if (FrameNumbers[Stage] > ComputeGraphicsLatency)
{
pComputeQueue->Wait(pGraphicsComputeFence,
FrameNumbers[Stage] - ComputeGraphicsLatency);
}
pComputeQueue->ExecuteCommandLists(1, &pComputeCommandList);
pComputeQueue->Signal(pComputeFence, FrameNumbers[Stage]);
break;
}
case 1:
{
// Recall that the GPU queue started with a wait for pComputeFence, 1
UINT64 CompletedComputeFrames = min(1,
pComputeFence->GetCompletedValue());
UINT64 PipeBufferIndex =
(CompletedComputeFrames - 1) % ComputeGraphicsLatency;
UINT64 CommandListIndex = (FrameNumbers[Stage] - 1) % CpuLatency;
// Update graphics command list based on CPU input and using the appropriate
// buffer index for data produced by compute.
UpdateGraphicsCommandList(PipeBufferIndex,
rgpGraphicsCommandLists[CommandListIndex]);
// Signal *before* new rendering to indicate what compute work
// the graphics queue is DONE with
pGraphicsQueue->Signal(pGraphicsComputeFence, CompletedComputeFrames - 1);
pGraphicsQueue->ExecuteCommandLists(1,
rgpGraphicsCommandLists + CommandListIndex);
pGraphicsQueue->Signal(pGraphicsFence, FrameNumbers[Stage]);
break;
}
}
}
}
Dostęp do zasobów z wieloma kolejkami
Aby uzyskać dostęp do zasobu w więcej niż jednej kolejce, aplikacja musi być zgodna z następującymi regułami.
Dostęp do zasobów (zapoznaj się z 12_RESOURCE_STATESDirect3D ) jest określany przez klasę typu kolejki, która nie jest obiektem kolejki. Istnieją dwie klasy typów kolejki: Kolejka obliczeniowa/3D jest jedną klasą typu, Copy jest drugą klasą typów. Dlatego zasób, który ma barierę dla stanu NON_PIXEL_SHADER_RESOURCE w jednej kolejce 3D, może być używany w tym stanie w dowolnej kolejce 3D lub w kolejce obliczeniowej, z zastrzeżeniem wymagań synchronizacji, które wymagają serializacji większości zapisów. Stany zasobów współdzielone między dwiema klasami typów (COPY_SOURCE i COPY_DEST) są traktowane jako różne stany dla każdej klasy typów. Tak więc, jeśli zasób przechodzi do COPY_DEST w kolejce kopiowania, nie jest dostępny jako miejsce docelowe kopiowania z kolejek 3D lub Compute i odwrotnie.
Podsumowanie.
- Kolejka "object" to dowolna pojedyncza kolejka.
- Kolejka "type" to jeden z następujących trzech: Obliczenia, 3D i Kopiowanie.
- Kolejka "klasa typu" jest jedną z następujących dwóch: Obliczenia/3D i Kopiowanie.
Flagi COPY (COPY_DEST i COPY_SOURCE) używane jako stany początkowe reprezentują stany w klasie typu 3D/Compute. Aby początkowo używać zasobu w kolejce kopiowania, powinien on rozpoczynać się w stanie COMMON. Stan COMMON może być używany dla wszystkich użycia w kolejce kopiowania przy użyciu niejawnych przejść stanu.
Mimo że stan zasobu jest współużytkowany we wszystkich kolejkach obliczeniowych i 3D, nie może zapisywać w zasobie jednocześnie w różnych kolejkach. "Jednocześnie" oznacza, że niezsynchronizowane, niezsynchronizowane wykonywanie nie jest możliwe na niektórych sprzętach. Obowiązują następujące reguły.
- Tylko jedna kolejka może zapisywać w zasobie jednocześnie.
- Wiele kolejek może odczytywać z zasobu, o ile nie odczytują bajtów modyfikowanych przez składnik zapisywania (odczyt bajtów zapisywanych jednocześnie generuje niezdefiniowane wyniki).
- Ogrodzenie musi być używane do synchronizacji po zapisie, zanim inna kolejka będzie mogła odczytać zapisane bajty lub uzyskać dostęp do zapisu.
wsteczne, które są prezentowane, muszą być w stanie 12_RESOURCE_STATE_COMMON Direct3D.
Tematy pokrewne
przewodnik programowania Direct3D 12
Używanie barier zasobów do synchronizowania stanów zasobów w Direct3D 12
zarządzanie pamięcią w Direct3D 12