Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
- dokładne profilowanie Direct3D jest trudne
- Jak dokładnie profilować sekwencję renderowania Direct3D
- profilowanie zmian stanu Direct3D
- Podsumowanie
- Załącznik
Gdy masz funkcjonalną aplikację Microsoft Direct3D i chcesz zwiększyć jej wydajność, zazwyczaj używasz gotowego narzędzia profilowania lub niestandardowej techniki pomiaru, aby zmierzyć czas potrzebny na wykonanie co najmniej jednego wywołania interfejsu programowania aplikacji (API). Jeśli to zrobiłeś, ale otrzymujesz wyniki pomiaru czasu, które różnią się między kolejnymi sekwencjami renderowania, lub stawiasz hipotezy, które nie pokrywają się z rzeczywistymi wynikami eksperymentu, poniższe informacje mogą pomóc ci zrozumieć, dlaczego.
Podane tutaj informacje są oparte na założeniu, że masz wiedzę i doświadczenie z następującymi elementami:
- Programowanie w języku C/C++
- Programowanie interfejsu API Direct3D
- Mierzenie czasów działania interfejsu API
- Karta wideo i sterownik oprogramowania
- Możliwe niewytłumaczalne wyniki z poprzedniego doświadczenia profilowania
Dokładne profilowanie direct3D jest trudne
Profiler raportuje ilość czasu spędzonego w każdym wywołaniu interfejsu API. Ma to na celu poprawę wydajności poprzez znalezienie i dostrajanie punktów aktywnych. Istnieją różne rodzaje profilatorów i technik profilowania.
- Profiler próbkowania siedzi bezczynnie przez większą część czasu, budząc się w określonych odstępach czasu w celu próbkowania (lub rejestrowania) wykonywanych funkcji. Zwraca wartość procentową czasu spędzonego w każdym wywołaniu. Ogólnie rzecz biorąc, profiler próbkowania nie jest bardzo inwazyjny dla aplikacji i ma minimalny wpływ na obciążenie aplikacji.
- Profiler instrumentujący mierzy rzeczywisty czas wykonania wywołania. Wymaga kompilowania ograniczników uruchamiania i zatrzymywania w aplikacji. Profiler instrumentujący jest stosunkowo bardziej inwazyjny dla aplikacji niż profiler próbkowania.
- Można również użyć niestandardowej techniki profilowania z czasomierzem o wysokiej wydajności. Daje to wyniki bardzo podobne do profilera instrumentacji.
Używany typ profilera lub techniki profilowania jest tylko częścią wyzwania generowania dokładnych pomiarów.
Profilowanie daje odpowiedzi, które ułatwiają budżetowanie wydajności. Załóżmy na przykład, że wiesz, że wywołanie interfejsu API wynosi średnio tysiąc cykli zegarowych do wykonania. Możesz wyciągać wnioski dotyczące wydajności, takie jak:
- Procesor CPU 2 GHz (który spędza 50 procent czasu renderowania) jest ograniczony do wywoływania tego interfejsu API 1 milion razy na sekundę.
- Aby osiągnąć 30 klatek na sekundę, nie można wywołać tego API więcej niż 33 000 razy na klatkę.
- Można renderować tylko 3,3K obiektów na klatkę (przy założeniu 10 wywołań interfejsu API dla każdej sekwencji renderowania obiektu).
Innymi słowy, jeśli miałbyś wystarczający czas na wywołanie interfejsu API, mógłbyś odpowiedzieć na pytanie dotyczące budżetowania, takie jak liczba prymitywów, które mogą być renderowane w sposób interaktywny. Jednak surowe liczby zwrócone przez profilera instrumentującego nie będą precyzyjnie odpowiadać na pytania dotyczące budżetowania. Dzieje się tak dlatego, że potok renderowania ma złożone problemy projektowe, takie jak liczba elementów, które muszą wykonywać zadania, liczba procesorów kontrolujących przepływ pracy między elementami oraz strategie optymalizacyjne zaimplementowane w środowisku uruchomieniowym i sterowniku, które mają na celu zwiększenie wydajności potoku.
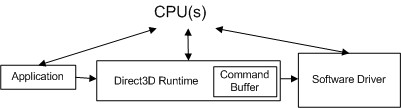
Każde wywołanie interfejsu API przechodzi przez kilka składników
Każde wywołanie jest przetwarzane przez kilka składników w drodze z aplikacji do karty wideo. Rozważmy na przykład następującą sekwencję renderowania zawierającą dwa wywołania rysowania jednego trójkąta:
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
Na poniższym diagramie koncepcyjnym przedstawiono różne składniki, za pomocą których wywołania muszą być przekazywane.

Aplikacja wywołuje direct3D, który kontroluje scenę, obsługuje interakcje użytkowników i określa sposób renderowania. Cała ta praca jest określona w sekwencji renderowania, która jest wysyłana do środowiska uruchomieniowego przy użyciu wywołań interfejsu API Direct3D. Sekwencja renderowania jest praktycznie niezależna od sprzętu (czyli wywołania interfejsu API są niezależne od sprzętu, ale aplikacja ma wiedzę na temat funkcji, które obsługuje karta wideo).
Środowisko uruchomieniowe konwertuje te wywołania na format niezależny od urządzenia. Środowisko uruchomieniowe obsługuje całą komunikację między aplikacją a sterownikiem, dzięki czemu aplikacja będzie działać na więcej niż jednym zgodnym sprzęcie (w zależności od wymaganych funkcji). Podczas mierzenia wywołania funkcji profiler instrumentujący mierzy czas spędzony w funkcji, a także czas powrotu funkcji. Jednym z ograniczeń profilera instrumentowania jest to, że może nie zawierać czasu, przez jaki sterownik wysyła wynikową pracę do karty wideo, ani czas, przez który karta wideo przetworzy pracę. Innymi słowy, gotowy do użycia profiler instrumentujący nie jest w stanie przypisać całej pracy związanej z każdym wywołaniem funkcji.
Sterownik oprogramowania używa specyficznej dla sprzętu wiedzy na temat karty wideo, aby przekonwertować polecenia niezależne od urządzenia do sekwencji poleceń karty wideo. Sterowniki mogą również zoptymalizować sekwencję poleceń wysyłanych do karty wideo, dzięki czemu renderowanie na karcie wideo jest wykonywane wydajnie. Te optymalizacje mogą powodować problemy z profilowaniem, ponieważ ilość pracy wykonanej nie jest tym, co wydaje się być (może być konieczne zrozumienie optymalizacji, aby je uwzględnić). Sterownik zwykle zwraca kontrolę do środowiska uruchomieniowego, zanim karta wideo zakończy przetwarzanie wszystkich poleceń.
Karta wideo wykonuje większość renderowania, łącząc dane z buforów wierzchołków i indeksów, tekstur, informacji o stanie renderowania oraz poleceń graficznych. Po zakończeniu renderowania karty wideo zostanie ukończona praca utworzona na podstawie sekwencji renderowania.
Każde wywołanie interfejsu API Direct3D musi być przetwarzane przez każdy składnik (środowisko uruchomieniowe, sterownik i kartę wideo), aby renderować dowolne elementy.
Istnieje więcej niż jeden procesor kontrolujący składniki
Relacja między tymi składnikami jest jeszcze bardziej złożona, ponieważ aplikacja, środowisko uruchomieniowe i sterownik są kontrolowane przez jeden procesor, a karta wideo jest kontrolowana przez oddzielny procesor. Na poniższym diagramie przedstawiono dwa rodzaje procesorów: centralną jednostkę przetwarzania (CPU) i procesor graficzny (GPU).

Systemy pc mają co najmniej jeden procesor CPU i jeden procesor GPU, ale może mieć więcej niż jeden lub oba. Procesory cpu znajdują się na płycie głównej, a procesory GPU znajdują się na płycie głównej lub na karcie wideo. Szybkość procesora CPU jest określana przez układ zegara na płycie głównej, a szybkość procesora GPU jest określana przez oddzielny układ zegara. Zegar procesora CPU kontroluje szybkość pracy wykonywanej przez aplikację, środowisko uruchomieniowe i sterownik. Aplikacja wysyła pracę do procesora GPU za pośrednictwem środowiska uruchomieniowego i sterownika.
Procesor CPU i procesor GPU zwykle działają z różnymi szybkościami, niezależnie od siebie. GPU może rozpocząć pracę natychmiast po udostępnieniu zadania (przy założeniu, że GPU zakończył przetwarzanie poprzedniego zadania). Praca z procesorem GPU jest wykonywana równolegle z pracą procesora CPU wyróżnioną krzywą linią na powyższej ilustracji. Profiler zwykle mierzy wydajność procesora CPU, a nie procesora GPU. Sprawia to, że profilowanie jest trudne, ponieważ pomiary wykonywane przez profiler instrumentowania obejmują czas procesora CPU, ale mogą nie zawierać czasu procesora GPU.
Procesor GPU służy do odciążania CPU, przenosząc przetwarzanie do jednostki specjalnie zaprojektowanej do pracy z grafiką. Na nowoczesnych kartach wideo GPU zastępuje większość pracy transformacji i oświetlenia w potoku od CPU do GPU. Znacznie zmniejsza to obciążenie procesora CPU, pozostawiając więcej cykli procesora CPU dostępnych na potrzeby innego przetwarzania. Aby dostosować aplikację graficzną pod kątem szczytowej wydajności, należy zmierzyć wydajność procesora CPU i procesora GPU oraz zrównoważyć pracę między dwoma typami procesorów.
Ten dokument nie obejmuje tematów związanych z pomiarem wydajności procesora GPU ani równoważeniem pracy między procesorem CPU a procesorem GPU. Jeśli chcesz lepiej zrozumieć wydajność procesora GPU (lub konkretnej karty wideo), odwiedź witrynę internetową dostawcy, aby uzyskać więcej informacji na temat wydajności procesora GPU. Zamiast tego ten dokument koncentruje się na pracy wykonywanej przez środowisko uruchomieniowe i sterownik przez zmniejszenie pracy procesora GPU do nieznacznej ilości. Jest to częściowo oparte na doświadczeniu, że aplikacje doświadczające problemów z wydajnością są zwykle ograniczone przez procesor CPU.
Optymalizacje środowiska uruchomieniowego i sterowników mogą maskować pomiary API
Środowisko uruchomieniowe ma wbudowaną optymalizację wydajności, która może zdominować pomiar pojedynczego wywołania. Oto przykładowy scenariusz, który demonstruje ten problem. Rozważmy następującą sekwencję renderowania:
BeginScene();
...
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
...
EndScene();
Present();
Przykład 1. Prosta sekwencja renderowania
Patrząc na wyniki dwóch wywołań w sekwencji renderowania, profiler narzędziowy może zwrócić rezultaty podobne do następujących:
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 950,500
Profiler zwraca liczbę cykli procesora CPU wymaganych do przetworzenia pracy skojarzonej z każdym wywołaniem (pamiętaj, że procesor GPU nie jest uwzględniony w tych numerach, ponieważ procesor GPU nie rozpoczął jeszcze pracy nad tymi poleceniami). Ponieważ IDirect3DDevice9::DrawPrimitive wymagała prawie miliona cykli do przetworzenia, można wywnioskować, że nie jest zbyt wydajne. Jednak wkrótce zobaczysz, dlaczego ten wniosek jest niepoprawny i jak można wygenerować wyniki, które mogą być używane do budżetowania.
Mierzenie zmian stanu wymaga starannych sekwencji renderowania
Wszystkie wywołania inne niż IDirect3DDevice9::DrawPrimitive, DrawIndexedPrimitivelub Clear (na przykład SetTexture, SetVertexDeclarationi SetRenderState) generują zmianę stanu. Każda zmiana stanu ustawia stan potokowy, który kontroluje sposób renderowania.
Optymalizacje w środowisku uruchomieniowym i/lub sterowniku zostały zaprojektowane w celu przyspieszenia renderowania przez zmniejszenie wymaganej ilości pracy. Poniżej przedstawiono kilka optymalizacji zmian stanu, które mogą zanieczyszczać średnie profilów:
- Sterownik (lub środowisko uruchomieniowe) może zapisać zmianę stanu jako stan lokalny. Ponieważ sterownik może działać w algorytmie "leniwym" (odpocznienie pracy, dopóki nie jest to absolutnie konieczne), praca związana z pewnymi zmianami stanu może zostać opóźniona.
- Środowisko uruchomieniowe (lub sterownik) może usuwać zmiany stanu przez optymalizację. Przykładem może być usunięcie nadmiarowej zmiany stanu, która wyłącza oświetlenie, ponieważ oświetlenie zostało wcześniej wyłączone.
Nie ma niezawodnego sposobu na przyjrzenie się sekwencji renderowania i stwierdzenie, które zmiany stanu ustawią brudny bit i odroczą pracę, lub po prostu zostaną usunięte przez optymalizację. Nawet jeśli można zidentyfikować zoptymalizowane zmiany stanu w dzisiejszym środowisku uruchomieniowym lub sterowniku, jutro środowisko uruchomieniowe lub sterownik prawdopodobnie zostaną zaktualizowane. Nie wiesz również, jaki był poprzedni stan, więc trudno jest zidentyfikować nadmiarowe zmiany stanu. Jedynym sposobem sprawdzenia kosztów zmiany stanu jest mierzenie sekwencji renderowania, która zawiera zmiany stanu.
Jak widać, komplikacje spowodowane przez posiadanie wielu procesorów, poleceń przetwarzanych przez więcej niż jeden składnik, a optymalizacje wbudowane w składniki sprawiają, że profilowanie jest trudne do przewidzenia. W następnej sekcji zostaną rozwiązane każde z tych wyzwań związanych z profilowaniem. Zostaną wyświetlone przykładowe sekwencje renderowania Direct3D z towarzyszącymi technikami pomiaru. Dzięki tej wiedzy będziesz w stanie wygenerować dokładne, powtarzalne pomiary poszczególnych rozmów.
Jak dokładnie profilować sekwencję renderowania Direct3D
Teraz, gdy niektóre wyzwania związane z profilowaniem zostały wyróżnione, w tej sekcji przedstawiono techniki, które pomogą Ci wygenerować pomiary profilów, które mogą być używane do budżetowania. Dokładne, powtarzalne pomiary profilowania są możliwe, jeśli rozumiesz relację między składnikami kontrolowanymi przez procesor i jak uniknąć optymalizacji wydajności implementowanych przez środowisko uruchomieniowe i sterownik.
Aby rozpocząć, musisz mieć możliwość dokładnego mierzenia czasu wykonywania pojedynczego wywołania interfejsu API.
Wybieranie dokładnego narzędzia pomiaru, takiego jak QueryPerformanceCounter
System operacyjny Microsoft Windows zawiera czasomierz o wysokiej rozdzielczości, który może służyć do mierzenia upływu czasu z dużą precyzją. Bieżącą wartość jednego takiego czasomierza można zwrócić przy użyciu QueryPerformanceCounter. Po wywołaniu QueryPerformanceCounter, aby zwrócić wartości początkową i końcową, różnica między dwiema wartościami może zostać przekonwertowana na rzeczywisty czas, który upłynął (w sekundach) przy użyciu QueryPerformanceCounter.
Zaletą korzystania z QueryPerformanceCounter jest to, że jest ono dostępne w systemie Windows i łatwe w użyciu. Wystarczy otoczyć wywołania QueryPerformanceCounter i zapisać wartości początkowe i końcowe. W związku z tym w tym dokumencie wykaże, jak używać QueryPerformanceCounter do profilowania czasów wykonywania, podobnie jak mierzy to profiler instrumentujący. Oto przykład pokazujący sposób osadzania QueryPerformanceCounter w kodzie źródłowym:
BeginScene();
...
// Start profiling
LARGE_INTEGER start, stop, freq;
QueryPerformanceCounter(&start);
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
QueryPerformanceCounter(&stop);
stop.QuadPart -= start.QuadPart;
QueryPerformanceFrequency(&freq);
// Stop profiling
...
EndScene();
Present();
Przykład 2. Niestandardowa implementacja profilowania przy użyciu technologii QPC
start i stop to dwie duże liczby całkowite, które będą przechowywać wartości początkową i końcową zwracane przez czasomierz o wysokiej wydajności. Zwróć uwagę, że funkcja QueryPerformanceCounter(&start) jest wywoływana tuż przed SetTexture i QueryPerformanceCounter(&stop) jest wywoływana tuż po DrawPrimitive. Po uzyskaniu wartości zatrzymania funkcja QueryPerformanceFrequency jest wywoływana w celu zwrócenia wartości freq, która jest częstotliwością czasomierza o wysokiej rozdzielczości. W tym hipotetycznym przykładzie załóżmy, że uzyskasz następujące wyniki dotyczące uruchamiania, zatrzymywania i freq:
| Zmienna lokalna | Liczba kleszczy |
|---|---|
| początek | 1792998845094 |
| zatrzymać | 1792998845102 |
| częstotliwość | 3579545 |
Możesz przekonwertować te wartości na liczbę cykli potrzebnych do wykonania wywołań interfejsu API w następujący sposób:
# ticks = (stop - start) = 1792998845102 - 1792998845094 = 8 ticks
# cycles = CPU speed * number of ticks / QPF
# 4568 = 2 GHz * 8 / 3,579,545
Innymi słowy, przetwarzanie SetTexture i DrawPrimitive na tym komputerze 2 GHz zajmuje około 4568 cykli zegarowych. Możesz przekonwertować te wartości na rzeczywisty czas wykonywania wszystkich wywołań w następujący sposób:
(stop - start)/ freq = elapsed time
8 ticks / 3,579,545 = 2.2E-6 seconds or between 2 and 3 microseconds.
Użycie funkcji QueryPerformanceCounter wymaga dodania pomiarów rozpoczęcia i zakończenia do sekwencji renderowania oraz użycia funkcji QueryPerformanceFrequency w celu przeliczenia różnicy (liczby znaczników) na liczbę cykli procesora CPU lub rzeczywisty czas. Identyfikowanie techniki pomiaru to dobry początek tworzenia niestandardowej implementacji profilowania. Ale zanim zaczniesz robić pomiary, musisz wiedzieć, jak poradzić sobie z kartą wideo.
Skup się na pomiarach procesora
Jak wspomniano wcześniej, procesor i procesor GPU działają równolegle w celu przetworzenia pracy wygenerowanej przez wywołania interfejsu API. Aplikacja w świecie rzeczywistym wymaga profilowania obu typów procesorów, aby ustalić, czy aplikacja jest ograniczona przez CPU czy GPU. Ponieważ wydajność procesora GPU jest specyficzna dla dostawcy, bardzo trudne byłoby uzyskanie wyników w tym dokumencie, który obejmuje różne dostępne karty wideo.
Zamiast tego ten dokument koncentruje się tylko na profilowaniu pracy wykonywanej przez procesor PRZY użyciu niestandardowej techniki mierzenia środowiska uruchomieniowego i pracy sterownika. Praca z procesorem GPU zostanie zmniejszona do nieistotnej ilości, dzięki czemu wyniki procesora CPU będą bardziej widoczne. Jedną z korzyści tego podejścia jest to, że ta technika daje wyniki w załączniku, które powinieneś być w stanie skorelować ze swoimi pomiarami. Aby zmniejszyć pracę wymaganą przez kartę wideo na nieznaczny poziom, po prostu zmniejsz pracę renderowania do najmniejszej możliwej ilości. Można to osiągnąć przez ograniczenie wywołań rysowania w celu renderowania pojedynczego trójkąta i może być dodatkowo ograniczone, tak aby każdy trójkąt zawierał tylko jeden piksel.
Jednostka miary używana w tym dokumencie do pomiaru pracy procesora CPU będzie liczbą cykli zegara procesora, a nie czasu rzeczywistego. Cykl zegara procesora ma tę zaletę, że jest bardziej przenośny (dla aplikacji ograniczonych przez CPU) niż rzeczywisty czas upływający na maszynach o różnych szybkościach procesora. Można to łatwo przekonwertować na rzeczywisty czas, jeśli jest to konieczne.
Ten dokument nie obejmuje tematów związanych z równoważeniem obciążenia pracy między procesorem CPU i procesorem GPU. Pamiętaj, że celem tego dokumentu nie jest mierzenie ogólnej wydajności aplikacji, ale pokazanie, jak dokładnie mierzyć czas potrzebny środowisku uruchomieniowemu i sterownikowi do przetwarzania wywołań interfejsu API. Dzięki tym dokładnym pomiarom można wykonać zadanie budżetowania procesora CPU, aby zrozumieć niektóre scenariusze wydajności.
Kontrolowanie środowiska uruchomieniowego i optymalizacji sterowników
Po zidentyfikowaniu techniki pomiaru i strategii zmniejszenia pracy procesora GPU następnym krokiem jest zrozumienie środowiska uruchomieniowego i optymalizacji sterowników, które są wykonywane podczas profilowania.
Praca procesora CPU można podzielić na trzy zasobniki: pracę aplikacji, pracę środowiska uruchomieniowego i pracę sterownika. Ignoruj działanie aplikacji, ponieważ jest to pod kontrolą programisty. Z punktu widzenia aplikacji środowisko uruchomieniowe i sterownik są jak czarne pola, ponieważ aplikacja nie ma kontroli nad tym, co zostało w nich zaimplementowane. Kluczem jest zrozumienie technik optymalizacji, które można zaimplementować w środowisku uruchomieniowym i sterowniku. Jeśli nie rozumiesz tych optymalizacji, bardzo łatwo jest przejść do błędnego wniosku o ilość pracy wykonywanej przez procesor w oparciu o pomiary profilu. W szczególności istnieją dwa tematy związane z czymś nazywanym buforem poleceń i jak może wpływać na utrudnianie profilowania. Te tematy są następujące:
- Optymalizacja środowiska uruchomieniowego za pomocą buforu poleceń. Bufor poleceń to optymalizacja środowiska uruchomieniowego, która zmniejsza wpływ przejścia w tryb. Aby kontrolować czas przejścia trybu, zobacz Kontrolowanie buforu poleceń.
- Negowanie efektów czasowych bufora poleceń. Czas trwania przejścia trybu może mieć duży wpływ na pomiary profilowania. Celem tej strategii jest , aby sekwencja renderowania jest duża w porównaniu z przejściem trybu.
Kontrolowanie buforu poleceń
Gdy aplikacja wykonuje wywołanie interfejsu API, środowisko uruchomieniowe konwertuje to wywołanie na format niezależny od urządzenia (które nazwiemy poleceniem) i zapisuje je w buforze poleceń. Bufor poleceń jest dodawany do poniższego diagramu.
Za każdym razem, gdy aplikacja wykonuje kolejne wywołanie interfejsu API, środowisko uruchomieniowe powtarza tę sekwencję i dodaje kolejne polecenie do buforu poleceń. W pewnym momencie środowisko uruchomieniowe opróżnia bufor (wysyłając polecenia do sterownika). W systemie Windows XP opróżnianie buforu poleceń powoduje przejście trybu, ponieważ system operacyjny przełącza się ze środowiska uruchomieniowego (działającego w trybie użytkownika) do sterownika (uruchomionego w trybie jądra), jak pokazano na poniższym diagramie.
- tryb użytkownika — tryb procesora nieuprzywilejowany, który wykonuje kod aplikacji. Aplikacje w trybie użytkownika nie mogą uzyskać dostępu do danych systemowych z wyjątkiem usług systemowych.
- tryb jądra — uprzywilejowany tryb procesora, w którym działa kod wykonawczy oparty na systemie Windows. Sterownik lub wątek działający w trybie jądra ma dostęp do całej pamięci systemowej, bezpośredniego dostępu do sprzętu i instrukcji procesora CPU do wykonywania operacji we/wy ze sprzętem.
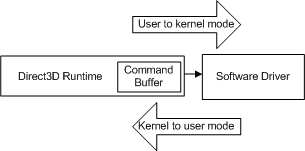
Przejście odbywa się za każdym razem, gdy procesor CPU przełącza się z użytkownika do trybu jądra (i odwrotnie), a liczba cykli, których wymaga, jest duża w porównaniu z pojedynczym wywołaniem interfejsu API. Jeśli środowisko uruchomieniowe wysłało każde wywołanie interfejsu API do sterownika podczas jego wywołania, każde wywołanie interfejsu API spowoduje poniesienie kosztów przejścia w trybie.
Zamiast tego bufor poleceń jest optymalizacją środowiska uruchomieniowego zaprojektowaną w celu zmniejszenia efektywnego kosztu przejścia w tryb. Bufor poleceń kolejkuje wiele poleceń sterownika w ramach przygotowań do jednokrotnego przejścia trybu. Gdy środowisko uruchomieniowe dodaje polecenie do buforu poleceń, kontrolka jest zwracana do aplikacji. Profiler nie ma możliwości poznania, że polecenia sterownika prawdopodobnie jeszcze nie zostały wysłane do sterownika. W związku z tym liczby zwracane przez gotowy profiler instrumentujący są mylące, ponieważ mierzy on pracę w czasie wykonywania, ale nie powiązaną pracę związaną ze sterownikami.
Wyniki profilu bez przejścia trybu
Korzystając z sekwencji renderowania z przykładu 2, poniżej przedstawiono typowe pomiary czasu, które ilustrują skalę przejścia trybu. Zakładając, że SetTexture i DrawPrimitive nie powodują przejścia w tryb, gotowy profiler instrumentacyjny może zwrócić wyniki podobne do następujących:
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 900
Każda z tych liczb to czas potrzebny na dodanie tych wywołań do buforu poleceń przez środowisko uruchomieniowe. Ponieważ nie ma przejścia w tryb, sterownik nie wykonał jeszcze żadnej pracy. Wyniki profilera są dokładne, ale nie mierzą całej pracy, którą sekwencja renderowania ostatecznie zmusi CPU do wykonania.
Wyniki profilowania z przejściem trybu
Teraz przyjrzyj się temu, co się stanie w tym samym przykładzie, gdy nastąpi przejście w trybie. Tym razem załóżmy, że SetTexture i DrawPrimitive powodują przejście trybu. Ponownie, gotowy do użycia profiler instrumentacyjny mógłby zwrócić wyniki podobne do tych:
Number of cycles for SetTexture : 98
Number of cycles for DrawPrimitive : 946,900
Czas mierzony dla SetTexture jest mniej więcej taki sam, jednak dramatyczny wzrost czasu spędzonego w DrawPrimitive wynika z przejściem trybu. Oto, co się dzieje:
- Załóżmy, że bufor poleceń ma miejsce na jedno polecenie przed uruchomieniem sekwencji renderowania.
- SetTexture jest konwertowany na format niezależny od urządzenia i dodawany do buforu poleceń. W tym scenariuszu to wywołanie wypełnia bufor poleceń.
- Środowisko uruchomieniowe próbuje dodać drawPrimitive do buforu poleceń, ale nie może, ponieważ jest pełny. Zamiast tego środowisko uruchomieniowe opróżnia bufor poleceń. Powoduje to przejście do trybu jądra. Załóżmy, że przejście trwa około 5000 cykli. Ten czas zostaje dodany do czasu spędzonego w DrawPrimitive.
- Następnie sterownik przetwarza pracę skojarzoną ze wszystkimi poleceniami, które zostały opróżnione z buforu poleceń. Załóżmy, że czas sterownika do przetwarzania poleceń, które prawie wypełniły bufor poleceń, wynosi około 935 000 cykli. Załóżmy, że praca kierowcy skojarzona z SetTexture wynosi około 2750 cykli. Ten czas jest wliczany do czasu spędzonego w DrawPrimitive.
- Po zakończeniu pracy sterownika przejście w trybie użytkownika zwraca kontrolę do środowiska uruchomieniowego. Bufor poleceń jest teraz pusty. Załóżmy, że przejście trwa około 5000 cykli.
- Sekwencja renderowania kończy się przez przekonwertowanie DrawPrimitive i dodanie go do buforu poleceń. Załóżmy, że zajmuje to około 900 cykli. Ten czas zalicza się do czasu spędzonego w DrawPrimitive.
Podsumowując wyniki, zobaczysz:
DrawPrimitive = kernel-transition + driver work + user-transition + runtime work
DrawPrimitive = 5000 + 935,000 + 2750 + 5000 + 900
DrawPrimitive = 947,950
Podobnie jak pomiar dla DrawPrimitive bez przejścia trybu (900 cykli), pomiar dla DrawPrimitive z przejściem trybu (947 950 cykli) jest dokładny, ale bezużyteczny jeśli chodzi o planowanie obciążenia procesora. Wynik zawiera poprawne działanie środowiska uruchomieniowego, pracę sterownika dla SetTexture, pracę sterownika dla wszystkich poleceń, które poprzedzały SetTexture, oraz dwa przejścia trybów. Jednak w pomiarze brakuje pracy sterownika DrawPrimitive.
Przejście trybu może nastąpić w odpowiedzi na każde wywołanie. Zależy to od tego, co wcześniej znajdowało się w buforze poleceń. Musisz monitorować przejście trybu, aby zrozumieć, ile pracy procesora (związanej z wykonywaniem programów i działaniem sterowników) jest powiązane z każdym wywołaniem. Aby to zrobić, potrzebny jest mechanizm do kontrolowania buforu poleceń oraz synchronizacji przejścia trybu.
Mechanizm zapytań
Mechanizm zapytań w Microsoft Direct3D 9 został zaprojektowany tak, aby umożliwić środowisku uruchomieniowemu wykonywanie zapytań do GPU w celu monitorowania postępu i zwracania pewnych danych z GPU. Podczas profilowania, jeśli praca GPU jest zminimalizowana, aby mieć niewielki wpływ na wydajność, możesz zwrócić stan GPU, aby pomóc zmierzyć pracę sterownika. W końcu praca sterownika jest zakończona, gdy procesor GPU widział polecenia sterownika. Ponadto, mechanizm zapytań można nakłonić do kontrolowania dwóch właściwości bufora poleceń, które są ważne do profilowania: kiedy bufor poleceń się opróżnia i ile pracy znajduje się w buforze poleceń.
Oto ta sama sekwencja renderowania przy użyciu mechanizmu zapytania:
// 1. Create an event query from the current device
IDirect3DQuery9* pEvent;
m_pD3DDevice->CreateQuery(D3DQUERYTYPE_EVENT, &pEvent);
// 2. Add an end marker to the command buffer queue.
pEvent->Issue(D3DISSUE_END);
// 3. Empty the command buffer and wait until the GPU is idle.
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
// 4. Start profiling
LARGE_INTEGER start, stop;
QueryPerformanceCounter(&start);
// 5. Invoke the API calls to be profiled.
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
// 6. Add an end marker to the command buffer queue.
pEvent->Issue(D3DISSUE_END);
// 7. Force the driver to execute the commands from the command buffer.
// Empty the command buffer and wait until the GPU is idle.
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
// 8. End profiling
QueryPerformanceCounter(&stop);
Przykład 3. Używanie zapytania do kontrolowania buforu poleceń
Poniżej przedstawiono bardziej szczegółowe wyjaśnienie każdego z tych wierszy kodu:
- Utwórz zapytanie o zdarzenie, tworząc obiekt zapytania z D3DQUERYTYPE_EVENT.
- Dodaj znacznik zdarzenia zapytania do buforu poleceń, wywołując Problem(D3DISSUE_END). Ten znacznik nakazuje sterownikowi śledzenie, kiedy procesor GPU kończy wykonywanie dowolnych poleceń poprzedzających znacznik.
- Pierwsze wywołanie opróżnia bufor poleceń, ponieważ wywołanie GetData z użyciem D3DGETDATA_FLUSH wymusza opróżnienie bufora poleceń. Każde kolejne wywołanie sprawdza jednostkę GPU, aby sprawdzić, kiedy zakończy przetwarzanie wszystkich poleceń w buforze poleceń. Ta pętla nie zwraca S_OK do momentu, gdy GPU jest bezczynny.
- Przykładowy czas rozpoczęcia.
- Wywoływanie profilowanych wywołań interfejsu API.
- Dodaj drugi znacznik zdarzenia zapytania do buforu poleceń. Ten znacznik będzie używany do śledzenia ukończenia wywołań.
- Pierwsze wywołanie opróżnia bufor poleceń, ponieważ wywołanie funkcji GetData z D3DGETDATA_FLUSH wymusza opróżnienie buforu poleceń. Gdy procesor GPU zakończy przetwarzanie wszystkich zadań buforu poleceń, getData zwraca S_OK, a pętla zostanie zakończona, ponieważ procesor GPU jest bezczynny.
- Przykładowy czas zatrzymania.
Poniżej przedstawiono wyniki mierzone za pomocą parametrów QueryPerformanceCounter i QueryPerformanceFrequency:
| Zmienna lokalna | Liczba kleszczy |
|---|---|
| początek | 1792998845060 |
| zatrzymać | 1792998845090 |
| Freq | 3579545 |
Ponowna konwersja taktów na cykle (na maszynie o częstotliwości 2 GHz).
# ticks = (stop - start) = 1792998845090 - 1792998845060 = 30 ticks
# cycles = CPU speed * number of ticks / QPF
# 16,450 = 2 GHz * 30 / 3,579,545
Oto podział liczby cykli na wywołanie:
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 900
Number of cycles for Issue : 200
Number of cycles for GetData : 16,450
Mechanizm zapytań pozwolił nam kontrolować środowisko uruchomieniowe i mierzoną pracę sterownika. Aby zrozumieć każdą z tych liczb, oto, co dzieje się w odpowiedzi na każde wywołanie interfejsu API, wraz z przybliżonymi czasami:
Pierwsze wywołanie opróżnia bufor poleceń przez wywołanie GetData za pomocą D3DGETDATA_FLUSH. Gdy procesor GPU zakończy przetwarzanie wszystkich zadań buforu poleceń, getData zwraca S_OK, a pętla zostanie zakończona, ponieważ procesor GPU jest bezczynny.
Sekwencja renderowania rozpoczyna się od przekonwertowania SetTexture na format niezależny od urządzenia i dodanie go do buforu poleceń. Załóżmy, że zajmuje to około 100 cykli.
DrawPrimitive jest konwertowany i dodawany do buforu poleceń. Załóżmy, że zajmuje to około 900 cykli.
Zagadnienie wprowadza znacznik zapytania do buforu poleceń. Załóżmy, że zajmuje to około 200 cykli.
GetData powoduje opróżnienie buforu poleceń, co wymusza przejście w tryb jądra. Załóżmy, że zajmuje to około 5000 cykli.
Następnie sterownik przetwarza pracę skojarzona ze wszystkimi czterema wywołaniami. Załóżmy, że czas przetwarzania SetTexture wynosi około 2964 cykli, DrawPrimitive wynosi około 3600 cykli, Problem wynosi około 200 cykli. Więc łączny czas sterownika dla wszystkich czterech poleceń wynosi około 6450 cykli.
Notatka
Kierowca również poświęca trochę czasu na sprawdzenie stanu GPU. Ponieważ praca GPU jest trywialna, powinna już być zakończona. GetData zwróci S_OK w zależności od prawdopodobieństwa, że GPU zakończyło działać.
Po zakończeniu pracy sterownika przejście w trybie użytkownika zwraca kontrolę do środowiska uruchomieniowego. Bufor poleceń jest teraz pusty. Załóżmy, że zajmuje to około 5000 cykli.
Liczby dla GetData obejmują:
GetData = kernel-transition + driver work + user-transition
GetData = 5000 + 6450 + 5000
GetData = 16,450
driver work = SetTexture + DrawPrimitive + Issue =
driver work = 2964 + 3600 + 200 = 6450 cycles
Mechanizm zapytań używany w połączeniu z elementem QueryPerformanceCounter mierzy całą pracę procesora CPU. Odbywa się to przy użyciu kombinacji znaczników zapytania i porównań stanu zapytania. Znaczniki uruchamiania i zatrzymywania zapytań dodane do buforu poleceń służą do kontrolowania ilości pracy w buforze. Czekając na zwrócenie odpowiedniego kodu powrotnego, pomiar rozpoczęcia jest wykonywany tuż przed rozpoczęciem pełnej sekwencji renderowania, a pomiar zatrzymania jest wykonywany tuż po zakończeniu pracy związanej z zawartością bufora poleceń. Dzięki temu można skutecznie monitorować pracę procesora wykonywaną zarówno przez środowisko uruchomieniowe, jak i sterownik.
Teraz, gdy wiesz już o buforze poleceń i jego wpływie na profilowanie, warto wiedzieć, że istnieje kilka innych warunków, które mogą powodować, że środowisko uruchomieniowe opróżnia bufor poleceń. Należy uważać na te elementy w sekwencjach renderowania. Niektóre z tych warunków są w odpowiedzi na wywołania interfejsu API, inne są w odpowiedzi na zmiany zasobów w środowisku uruchomieniowym. Dowolny z następujących warunków spowoduje przejście w tryb:
- Gdy jedna z metod blokady (Lock) jest wywoływana na buforze wierzchołków, buforze indeksów lub teksturze (w określonych warunkach z użyciem określonych flag).
- Gdy zostanie utworzony bufor urządzenia, bufor wierzchołków, bufor indeksu lub tekstura.
- Gdy urządzenie lub bufor wierzchołka, bufor indeksu lub tekstura zostanie zniszczona przez ostatnie wydanie.
- Po wywołaniu ValidateDevice.
- Gdy wywoływany jest Present.
- Gdy bufor polecenia się zapełni.
- Gdy GetData jest wywoływana z D3DGETDATA_FLUSH.
Należy zachować ostrożność, obserwując te warunki w sekwencjach renderowania. Za każdym razem, gdy zostanie dodane przejście trybu, do pomiarów profilowania zostanie dodanych 10 000 cykli pracy sterownika. Ponadto bufor poleceń nie ma statycznego rozmiaru. Środowisko uruchomieniowe może zmienić rozmiar buforu w odpowiedzi na ilość pracy generowanej przez aplikację. Jest to kolejna optymalizacja zależna od sekwencji renderowania.
Należy więc zachować ostrożność przy kontrolowaniu przejść trybów podczas profilowania. Mechanizm zapytań oferuje niezawodną metodę opróżniania buforu poleceń, dzięki czemu można kontrolować czas przejścia trybu, a także ilość pracy, jaką zawiera bufor. Jednak nawet tę technikę można ulepszyć, skracając czas przełączania trybu, aby stał się nieistotny w odniesieniu do zmierzonego wyniku.
Zrób sekwencję renderowania większą w porównaniu z przejściem trybu
W poprzednim przykładzie przełącznik trybu jądra i przełącznik trybu użytkownika zużywają około 10 000 cykli, które nie mają nic wspólnego ze środowiskiem uruchomieniowym i pracą sterownika. Ponieważ przejście w tryb jest wbudowane w system operacyjny, nie można go zmniejszyć do zera. Aby przejście trybu było nieistotne, sekwencja renderowania musi być dostosowana tak, aby praca sterownika i środowiska uruchomieniowego była rzędu wielkości większa niż przełączniki trybu. Możesz spróbować wykonać odejmowanie, aby usunąć przejścia, ale rozłożenie kosztów na znacznie dłuższą sekwencję renderowania jest bardziej niezawodne.
Strategia zmniejszania zmiany trybu do momentu, gdy stanie się nieistotne, polega na dodaniu pętli do sekwencji renderowania. Na przykład przyjrzyjmy się wynikom profilowania, jeśli zostanie dodana pętla, która będzie powtarzać sekwencję renderowania 1500 razy:
// Initialize the array with two textures, same size, same format
IDirect3DTexture* texArray[2];
CreateQuery(D3DQUERYTYPE_EVENT, pEvent);
pEvent->Issue(D3DISSUE_END);
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
LARGE_INTEGER start, stop;
// Now start counting because the video card is ready
QueryPerformanceCounter(&start);
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
SetTexture(taxArray[i%2]);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
pEvent->Issue(D3DISSUE_END);
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
QueryPerformanceCounter(&stop);
Przykład 4. Dodawanie pętli do sekwencji renderowania
Poniżej przedstawiono wyniki mierzone za pomocą parametrów QueryPerformanceCounter i QueryPerformanceFrequency:
| Zmienna lokalna | Liczba Tics |
|---|---|
| początek | 1792998845000 |
| zatrzymać | 1792998847084 |
| Freq | 3579545 |
Użycie metody QueryPerformanceCounter mierzy teraz 2840 znaczników. Konwertowanie znaczników na cykle jest takie samo, jak pokazano już:
# ticks = (stop - start) = 1792998847084 - 1792998845000 = 2840 ticks
# cycles = machine speed * number of ticks / QPF
# 6,900,000 = 2 GHz * 2840 / 3,579,545
Innymi słowy, przetwarzanie 1500 wywołań w pętli renderowania zajmuje około 6,9 miliona cykli na tym komputerze 2 GHz. Z 6,9 miliona cykli, czas przejść pomiędzy trybami wynosi około 10 tysięcy, więc teraz wyniki profilu prawie całkowicie mierzą pracę związaną z SetTexture i DrawPrimitive.
Zwróć uwagę, że przykładowy kod wymaga tablicy dwóch tekstur. Aby uniknąć optymalizacji środowiska uruchomieniowego, która usuwałaby SetTexture, jeśli ustawia ten sam wskaźnik tekstury za każdym razem, gdy jest wywoływany, po prostu użyj tablicy dwóch tekstur. Dzięki temu przy każdym przejściu przez pętlę wskaźnik tekstury ulega zmianie i wykonywana jest pełna praca związana z SetTexture. Upewnij się, że obie tekstury mają ten sam rozmiar i format, aby żaden inny stan nie zmienił się, gdy tekstura się zmieni.
Teraz masz technikę profilowania Direct3D. Opiera się on na liczniku o wysokiej wydajności (QueryPerformanceCounter), aby zarejestrować liczbę taktów, jakie zajmuje procesorowi CPU przetworzenie zadania. Praca jest dokładnie kontrolowana pod względem środowiska uruchomieniowego i pracy sterownika skojarzonego z wywołaniami interfejsu API przy użyciu mechanizmu zapytań. Zapytanie zapewnia dwa środki kontroli: najpierw opróżnić bufor poleceń przed rozpoczęciem sekwencji renderowania, a następnie powrócić po zakończeniu pracy procesora GPU.
Do tej pory w tym dokumencie pokazano, jak profilować sekwencję renderowania. Każda sekwencja renderowania była dość prosta, zawierająca jedno wywołanie DrawPrimitive i wywołanie SetTexture . Zostało to zrobione, aby skoncentrować się na buforze poleceń i używaniu mechanizmu zapytań do kontrolowania go. Oto krótkie podsumowanie sposobu profilowania dowolnej sekwencji renderowania:
- Użyj licznika o wysokiej wydajności, takiego jak QueryPerformanceCounter, aby zmierzyć czas potrzebny do przetworzenia każdego wywołania interfejsu API. Użyj metody QueryPerformanceFrequency i częstotliwości zegara procesora CPU, aby przekonwertować tę wartość na liczbę cykli procesora CPU na wywołanie interfejsu API.
- Zminimalizuj ilość pracy procesora GPU, renderując listy trójkątów, gdzie każdy trójkąt zawiera jeden piksel.
- Użyj mechanizmu zapytania, aby opróżnić bufor poleceń przed sekwencją renderowania. Gwarantuje to, że profilowanie przechwyci poprawną ilość czasu działania i pracy sterownika powiązanej z sekwencją renderowania.
- Kontroluj ilość pracy dodanej do buforu poleceń za pomocą znaczników zdarzeń zapytania. To samo zapytanie wykrywa, kiedy procesor GPU zakończy pracę. Ponieważ praca procesora GPU jest trywialna, jest to praktycznie równoważne z pomiarem po zakończeniu pracy sterownika.
Wszystkie te techniki są używane do profilowania zmian stanu. Zakładając, że przeczytałeś i zrozumiałeś, jak kontrolować bufor poleceń oraz pomyślnie ukończyłeś pomiary linii bazowej na DrawPrimitive, jesteś gotowy, aby dodać zmiany stanu do sekwencji renderowania. Istnieje kilka dodatkowych wyzwań związanych z profilowaniem podczas dodawania zmian stanu do sekwencji renderowania. Jeśli zamierzasz dodać zmiany stanu do sekwencji renderowania, pamiętaj, aby przejść do następnej sekcji.
Profilowanie zmian stanu Direct3D
Direct3D używa wielu stanów renderowania do kontrolowania niemal każdego aspektu pipeline'u. Interfejsy API, które powodują zmiany stanu, obejmują dowolną funkcję lub metodę inną niż wywołania Draw*Primitive.
Zmiany stanu są trudne, ponieważ może nie być w stanie zobaczyć kosztów zmiany stanu bez renderowania. Jest to wynik leniwego algorytmu, który sterownik i procesor GPU używają do odroczenia pracy, dopóki nie będzie to absolutnie konieczne. Ogólnie rzecz biorąc, należy wykonać następujące kroki, aby zmierzyć pojedynczą zmianę stanu:
- Profil DrawPrimitive najpierw.
- Dodaj jedną zmianę stanu do sekwencji renderowania i profiluj nową sekwencję.
- Odejmij różnicę między dwiema sekwencjami, aby uzyskać koszt zmiany stanu.
Oczywiście wszystkie informacje na temat korzystania z mechanizmu zapytań i umieszczania sekwencji renderowania w pętli w celu zniwelowania kosztów przejścia między trybami nadal mają zastosowanie.
Profilowanie prostej zmiany stanu
Rozpoczynając od sekwencji renderowania zawierającej DrawPrimitive, poniżej znajduje się sekwencja kodu do mierzenia kosztów dodania SetTexture:
// Get the start counter value as shown in Example 4
// Initialize a texture array as shown in Example 4
IDirect3DTexture* texArray[2];
// Render sequence loop
for(int i = 0; i < 1500; i++)
{
SetTexture(0, texArray[i%2];
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
// Get the stop counter value as shown in Example 4
Przykład 5: Mierzenie wywołania API pojedynczej zmiany stanu
Zwróć uwagę, że pętla zawiera dwa wywołania SetTexture i DrawPrimitive. Sekwencja renderowania wykonuje się w pętli 1500 razy oraz generuje wyniki podobne do poniższych.
| Zmienna lokalna | Liczba Tics |
|---|---|
| początek | 1792998860000 |
| zatrzymać | 1792998870260 |
| Częstość | 3579545 |
Konwertowanie znaczników na cykle po raz kolejny daje:
# ticks = (stop - start) = 1792998870260 - 1792998860000 = 10,260 ticks
# cycles = machine speed * number of ticks / QPF
5,775,000 = 2 GHz * 10,260 / 3,579,545
Dzielenie według liczby iteracji w pętli daje:
5,775,000 cycles / 1500 iterations = 3850 cycles for one iteration
Każda iteracja pętli zawiera zmianę stanu i wywołanie funkcji rysowania. Odejmowanie wyników z sekwencji renderowania DrawPrimitive pozostawia:
3850 - 1100 = 2750 cycles for SetTexture
Jest to średnia liczba cykli do dodania SetTexture do tej sekwencji renderowania. Tę samą technikę można zastosować do innych zmian stanu.
Dlaczego SetTexture nazywa się prostą zmianą stanu? Ponieważ ustawiony stan jest ograniczony, aby rura wykonywała tę samą ilość pracy za każdym razem, gdy stan jest zmieniany. Ograniczenie obu tekstur do jednolitego rozmiaru i formatu gwarantuje taką samą ilość pracy przy każdym wywołaniu SetTexture.
Profilowanie zmiany stanu wymagającej przełączenia
Istnieją inne zmiany stanu, które powodują zmianę ilości pracy wykonywanej przez potok grafiki dla każdej iteracji pętli renderowania. Na przykład jeśli testowanie z jest włączone, każdy kolor pikseli aktualizuje element docelowy renderowania dopiero po przetestowaniu wartości z nowego piksela względem wartości z dla istniejącego piksela. Jeśli testowanie z jest wyłączone, ten test na piksel nie jest wykonywany, a dane wyjściowe są zapisywane znacznie szybciej. Włączenie lub wyłączenie stanu testu Z znacząco zmienia ilość pracy wykonanej przez CPU i GPU podczas renderowania.
SetRenderState wymaga określonego stanu renderowania i wartości stanu, aby włączyć lub wyłączyć testowanie Z. Określona wartość stanu jest oceniana w czasie wykonywania, aby ustalić, ile pracy jest wymagane. Trudno jest zmierzyć tę zmianę stanu w pętli renderowania i nadal przygotować stan potoku, aby się przełączał. Jedynym rozwiązaniem jest przełączenie zmiany stanu podczas sekwencji renderowania.
Na przykład technika profilowania musi być powtarzana dwa razy w następujący sposób:
- Zacznij od profilowania sekwencji renderowania DrawPrimitive. Nazwij to linią bazową.
- Profilowanie drugiej sekwencji renderowania, która przełącza zmianę stanu. Pętla sekwencji renderowania zawiera:
- Zmiana stanu w celu ustawienia stanu na warunek "false".
- DrawPrimitive tak jak oryginalna sekwencja.
- Zmiana stanu w celu ustawienia go na wartość "true".
- Druga DrawPrimitive, aby wymusić wykonanie drugiej zmiany stanu.
- Znajdź różnicę między dwiema sekwencjami renderowania. Odbywa się to przez:
- Pomnożyj sekwencję DrawPrimitive przez 2, ponieważ w nowej sekwencji istnieją dwa wywołania DrawPrimitive.
- Odejmij wynik nowej sekwencji z oryginalnej sekwencji.
- Podziel wynik przez 2, aby uzyskać średni koszt zarówno fałszywej, jak i prawdziwej zmiany stanu.
W przypadku techniki pętli stosowanej w sekwencji renderowania, koszt zmiany stanu potokowego musi być mierzony przez zmienianie stanu z 'prawda' na 'fałsz' i odwrotnie, dla każdej iteracji w sekwencji renderowania. Znaczenie "true" i "false" tutaj nie jest dosłowne; oznacza to po prostu, że stan musi być ustawiony w przeciwstawnych warunkach. Powoduje to pomiar obu zmian stanu podczas profilowania. Oczywiście wszystkie informacje na temat korzystania z mechanizmu zapytań oraz umieszczania sekwencji renderowania w pętli w celu zmniejszenia kosztów przejścia w tryb nadal mają zastosowanie.
Na przykład przedstawiono tutaj sekwencję kodu do mierzenia kosztów włączania i wyłączania testowania z.
// Get the start counter value as shown in Example 4
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
// Precondition the pipeline state to the "false" condition
SetRenderState(D3DRS_ZENABLE, FALSE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 0)*3, 1);
// Set the pipeline state to the "true" condition
SetRenderState(D3DRS_ZENABLE, TRUE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 1)*3, 1);
}
// Get the stop counter value as shown in Example 4
Przykład 5: Mierzenie zmiany stanu przełączającego się
Pętla przełącza stan, wykonując dwa wywołania SetRenderState. Pierwsze wywołanie SetRenderState wyłącza testowanie z, a drugi SetRenderState umożliwia testowanie z. Po każdym SetRenderState następuje DrawPrimitive, dzięki czemu praca związana ze zmianą stanu jest przetwarzana przez sterownik, zamiast polegać jedynie na ustawieniu zanieczyszczonego bitu w sterowniku.
Te liczby są uzasadnione dla tej sekwencji renderowania:
| Zmienna lokalna | Liczba kleszczy |
|---|---|
| początek | 1792998845000 |
| zatrzymać | 1792998861740 |
| czest | 3579545 |
Przekształcanie taktów na cykle po raz kolejny daje:
# ticks = (stop - start) = 1792998861740 - 1792998845000 = 15,120 ticks
# cycles = machine speed * number of ticks / QPF
9,300,000 = 2 GHz * 16,740 / 3,579,545
Dzielenie według liczby iteracji w pętli daje:
9,300,000 cycles / 1500 iterations = 6200 cycles for one iteration
Każda iteracja pętli zawiera dwa zmiany stanu i dwa wywołania rysowania. Odejmując wywołania rysowania, przy założeniu 1100 cykli, pozostaje:
6200 - 1100 - 1100 = 4000 cycles for both state changes
Jest to średnia liczba cykli dla obu zmian stanu, więc średni czas dla każdej zmiany stanu wynosi:
4000 / 2 = 2000 cycles for each state change
W związku z tym średnia liczba cykli do włączenia lub wyłączenia testowania z wynosi 2000 cykli. Warto zauważyć, że funkcja QueryPerformanceCounter mierzy przez połowę czasu z włączonym trybem Z (z-enable) i przez połowę czasu z wyłączonym trybem Z (z-disable). Ta technika faktycznie mierzy średnią zmian obu stanów. Innymi słowy, mierzysz czas przełączania stanu. Korzystając z tej techniki, nie masz możliwości poznania, czy czasy włączania i wyłączania są równoważne, ponieważ mierzono średnią obu z nich. Niemniej jednak jest to rozsądna liczba do uwzględnienia podczas budżetowania stanu przełączenia, jako że aplikacja powodująca tę zmianę stanu może to zrobić jedynie poprzez przełączanie tego stanu.
Więc teraz możesz zastosować te techniki i profilować wszystkie żądane zmiany stanu, prawda? Nie całkiem. Nadal należy zachować ostrożność w zakresie optymalizacji, które zostały zaprojektowane w celu zmniejszenia ilości pracy, którą należy wykonać. Istnieją dwa typy optymalizacji, o których należy pamiętać podczas projektowania sekwencji renderowania.
Uważaj na optymalizacje dotyczące zmian stanu
W poprzedniej sekcji pokazano, jak profilować oba rodzaje zmian stanu: prostą zmianę stanu, która jest ograniczona do generowania tej samej ilości pracy dla każdej iteracji, oraz zmiana stanu przełączania, która znacząco zmienia ilość wykonanej pracy. Co się stanie, jeśli weźmiesz poprzednią sekwencję renderowania i dodasz do niej kolejną zmianę stanu? Na przykład ten przykład przyjmuje sekwencję renderowania z>-enable i do tego dodaje porównanie funkcji z:
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
// Precondition the pipeline state to the opposite condition
SetRenderState(D3DRS_ZFUNC, D3DCMP_NEVER);
// Precondition the pipeline state to the opposite condition
SetRenderState(D3DRS_ZENABLE, FALSE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 0)*3, 1);
// Now set the state change you want to measure
SetRenderState(D3DRS_ZFUNC, D3DCMP_ALWAYS);
// Now set the state change you want to measure
SetRenderState(D3DRS_ZENABLE, TRUE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 1)*3, 1);
}
Stan funkcji Z ustawia poziom porównania podczas zapisywania do bufora Z (między wartością Z bieżącego piksela a wartością Z piksela w buforze głębokości). D3DCMP_NEVER wyłącza porównanie głębokości, podczas gdy D3DCMP_ALWAYS ustawia porównanie, aby było wykonywane za każdym razem, gdy odbywa się testowanie głębokości.
Profilowanie jednej z tych zmian stanu w sekwencji renderowania za pomocą DrawPrimitive generuje wyniki podobne do następujących:
| Zmiana pojedynczego stanu | Średnia liczba cykli |
|---|---|
| tylko D3DRS_ZENABLE | 2000 |
lub
| Zmiana pojedynczego stanu | Średnia liczba cykli |
|---|---|
| Tylko D3DRS_ZFUNC | 600 |
Jeśli jednak profilujesz zarówno D3DRS_ZENABLE, jak i D3DRS_ZFUNC w tej samej sekwencji renderowania, wyniki będą widoczne w następujący sposób:
| Oba zmiany stanu | Średnia liczba cykli |
|---|---|
| D3DRS_ZENABLE i D3DRS_ZFUNC | 2000 |
Można oczekiwać, że wynikiem będzie suma 2000 i 600 (lub 2600) cykli, ponieważ sterownik wykonuje całą pracę skojarzona z ustawieniem obu stanów renderowania. Zamiast tego średnia wynosi 2000 cykli.
Ten wynik odzwierciedla optymalizację zmian stanu zaimplementowaną w środowisku uruchomieniowym, sterowniku lub procesorze GPU. W tym przypadku sterownik może zobaczyć pierwszy SetRenderState i ustawić stan brudny, który odroczy pracę do późniejszego. Gdy sterownik zobaczy drugi SetRenderState, ten sam stan nieaktualny może być ustawiony ponownie, a ta sama praca jest opóźniona. Po wywołaniu DrawPrimitive zostanie ostatecznie przetworzona praca skojarzona z zanieczyszczonym stanem. Sterownik wykonuje pracę jednorazowo, co oznacza, że dwa pierwsze zmiany stanu są skutecznie konsolidowane przez sterownik. Podobnie zmiany trzeciego i czwartego stanu są skutecznie konsolidowane przez sterownik w jeden stan, gdy jest wywoływana druga DrawPrimitive. Efektem końcowym jest to, że sterownik i GPU przetwarzają pojedynczą zmianę stanu dla każdego wywołania rysowania.
Jest to dobry przykład optymalizacji sterowników zależnych od sekwencji. Kierowca dwukrotnie przełożył pracę, nadając jej stan brudny, a następnie wykonał ją raz, aby ten stan usunąć. Jest to dobry przykład rodzaju poprawy wydajności, która może mieć miejsce, gdy praca jest odroczona, aż do absolutnej potrzeby.
Jak wiesz, które zmiany stanu ustawiają stan brudny wewnętrznie i dlatego odroczysz pracę do późniejszego czasu? Tylko przez testowanie sekwencji renderowania (lub rozmowy z autorami sterowników). Sterowniki są okresowo aktualizowane i ulepszane, więc lista optymalizacji nie jest statyczna. Istnieje tylko jeden sposób, aby mieć pełną pewność, ile kosztuje zmiana stanu w danej sekwencji renderowania na określonym zestawie sprzętu, a to poprzez pomiar.
Uważaj na optymalizacje DrawPrimitive
Oprócz optymalizacji zmian stanu środowisko uruchomieniowe podejmie próbę zoptymalizowania liczby wywołań rysowania, które sterownik musi przetworzyć. Rozważmy na przykład te następujące po sobie wywołania rysowania:
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 3); // Draw 3 primitives, vertices 0 - 8
DrawPrimitive(D3DPT_TRIANGLELIST, 9, 4); // Draw 4 primitives, vertices 9 - 20
Przykład 5a: dwa wywołania rysowania
Ta sekwencja zawiera dwa wywołania rysowania, które środowisko uruchomieniowe skonsoliduje w jedno wywołanie równoważne:
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 7); // Draw 7 primitives, vertices 0 - 20
Przykład 5b: pojedyncze złączone wywołanie rysowania
Środowisko uruchomieniowe połączy oba te wywołania rysowania grafiki w jedno wywołanie, co zmniejsza pracę sterownika o 50 procent, ponieważ sterownik będzie teraz musiał przetworzyć tylko jedno wywołanie rysowania grafiki.
Ogólnie rzecz biorąc, środowisko uruchomieniowe połączy co najmniej dwa kolejne wywołania DrawPrimitive, gdy:
- Typ pierwotny to lista trójkątów (D3DPT_TRIANGLELIST).
- Każde kolejne wywołanie DrawPrimitive musi odwoływać się do kolejnych wierzchołków w buforze wierzchołków.
Podobnie, odpowiednie warunki do łączenia dwóch lub większej liczby następujących po sobie wywołań DrawIndexedPrimitive:
- Typ pierwotny to lista trójkątów (D3DPT_TRIANGLELIST).
- Każde kolejne wywołanie DrawIndexedPrimitive musi odnosić się do kolejnych, następujących po sobie indeksów w buforze indeksu.
- Każde kolejne wywołanie DrawIndexedPrimitive musi używać tej samej wartości dla indeksu BaseVertexIndex.
Aby zapobiec łączeniu podczas profilowania, zmodyfikuj sekwencję renderowania tak, aby typ pierwotny nie był listą trójkątów lub zmodyfikuj sekwencję renderowania, aby nie było następujących po sobie wywołań rysowania używających kolejnych wierzchołków (lub indeksów). Mówiąc dokładniej, środowisko uruchomieniowe będzie również łączyć wywołania rysowania spełniające oba następujące warunki:
- Gdy poprzednie wywołanie jest DrawPrimitive, jeśli następne wywołanie rysowania:
- używa listy trójkątów, i
- określa StartVertex = poprzedni StartVertex + poprzedni PrimitiveCount * 3
- Podczas korzystania z DrawIndexedPrimitive, jeśli następne wywołanie rysowania:
- używa listy trójkątów, AND
- określa StartIndex = poprzedni StartIndex + poprzedni PrimitiveCount * 3, I
- określa BaseVertexIndex = poprzedni BaseVertexIndex
Oto bardziej subtelny przykład łączenia wywołań rysowania, który jest łatwy do przeoczenia podczas profilowania. Załóżmy, że sekwencja renderowania wygląda następująco:
for(int i = 0; i < 1500; i++)
{
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
Przykład 5c: jedna zmiana stanu i jedno wywołanie rysowania
Pętla iteruje przez 1500 trójkątów, ustawiając teksturę i rysując każdy trójkąt. Ta pętla renderowania zajmuje około 2750 cykli dla setTexture i 1100 cykli dla DrawPrimitive, jak pokazano w poprzednich sekcjach. Można intuicyjnie oczekiwać, że przeniesienie SetTexture poza pętlą renderowania powinno zmniejszyć ilość pracy wykonanej przez sterownik o 1500 * 2750 cykli, co jest ilością pracy związanej z wywołaniem SetTexture 1500 razy. Fragment kodu będzie wyglądać następująco:
SetTexture(...); // Set the state outside the loop
for(int i = 0; i < 1500; i++)
{
// SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
Przykład 5d: przykład 5c ze zmianą stanu poza pętlą
Przeniesienie SetTexture poza pętlą renderowania zmniejsza ilość pracy skojarzonej z SetTexture, ponieważ jest wywoływana raz zamiast 1500 razy. Mniej oczywistym efektem pomocniczym jest to, że przetwarzanie dla DrawPrimitive jest również ograniczone z 1500 wywołań do 1, ponieważ spełnione są wszystkie warunki konieczne do łączenia wywołań rysowania. Po przetworzeniu sekwencji renderowania środowisko uruchomieniowe przetworzy 1500 wywołań do jednego wywołania sterownika. Przenosząc ten jeden wiersz kodu, ilość pracy kierowcy została znacznie zmniejszona:
total work done = runtime + driver work
Example 5c: with SetTexture in the loop:
runtime work = 1500 SetTextures + 1500 DrawPrimitives
driver work = 1500 SetTextures + 1500 DrawPrimitives
Example 5d: with SetTexture outside of the loop:
runtime work = 1 SetTexture + 1 DrawPrimitive + 1499 Concatenated DrawPrimitives
driver work = 1 SetTexture + 1 DrawPrimitive
Wyniki te są całkowicie poprawne, ale są bardzo mylące w kontekście pierwotnego pytania. Optymalizacja wywołań rysowania spowodowała znaczne zmniejszenie zakresu pracy sterownika. Jest to typowy problem podczas profilowania niestandardowego. Podczas eliminowania wywołań z sekwencji renderowania należy zachować ostrożność, aby uniknąć łączenia wywołań. W rzeczywistości ten scenariusz jest zaawansowanym przykładem zwiększenia wydajności sterowników możliwej przez tę optymalizację środowiska uruchomieniowego.
Teraz wiesz już, jak mierzyć zmiany stanu. Zacznij od profilowania DrawPrimitive. Następnie dodaj każdą dodatkową zmianę stanu do sekwencji (w niektórych przypadkach dodanie jednego wywołania i w innych przypadkach dodanie dwóch wywołań) i zmierz różnicę między dwiema sekwencjami. Możesz przekonwertować wyniki na znaczniki, cykle czy czas. Podobnie jak mierzenie sekwencji renderowania za pomocą funkcji QueryPerformanceCounter, mierzenie poszczególnych zmian stanu opiera się na mechanizmie zapytania w celu kontrolowania buforu poleceń i umieszczania zmian stanu w pętli w celu zminimalizowania wpływu przejścia trybu. Ta technika mierzy koszt przełączania stanu, ponieważ profiler zwraca średnią włączania i wyłączania stanu.
Dzięki tej funkcji można rozpocząć generowanie dowolnych sekwencji renderowania i dokładne mierzenie skojarzonego środowiska uruchomieniowego i pracy sterownika. Liczby mogą następnie służyć do odpowiadania na pytania dotyczące budżetowania, takie jak "ile dodatkowych takich wywołań" można wykonać w sekwencji renderowania, utrzymując rozsądną liczbę klatek na sekundę, zakładając scenariusze ograniczone przez wydajność CPU.
Streszczenie
W tym dokumencie pokazano, jak kontrolować bufor poleceń, aby poszczególne wywołania mogły być dokładnie profilowane. Dane profilowania można wygenerować w tykach, cyklach lub czasie bezwzględnym. Reprezentują one ilość czasu wykonania i pracy sterownika związanej z każdym wywołaniem interfejsu API.
Zacznij od profilowania wywołania Draw*Primitive w sekwencji renderowania. Pamiętaj, aby:
- Użyj QueryPerformanceCounter, aby zmierzyć liczbę cykli przy każdym wywołaniu interfejsu API. Użyj metody QueryPerformanceFrequency, aby przekonwertować wyniki na cykle lub czas, jeśli chcesz.
- Użyj mechanizmu zapytania, aby opróżnić bufor poleceń przed rozpoczęciem.
- Uwzględnij sekwencję renderowania w pętli, aby zminimalizować wpływ przejścia trybu.
- Użyj mechanizmu zapytań, aby zmierzyć, kiedy procesor GPU zakończył swoją pracę.
- Zwróć uwagę na łączenie środowiska uruchomieniowego, które będzie miało duży wpływ na ilość wykonanej pracy.
Zapewnia to wydajność punktu odniesienia dla DrawPrimitive, co może być używane do rozwijania. Aby przeanalizować jedną zmianę stanu, zastosuj się do następujących dodatkowych wskazówek:
- Dodaj zmianę stanu do znanego profilu sekwencji renderowania nowej sekwencji. Ponieważ testowanie odbywa się w pętli, wymaga to dwukrotnego ustawienia stanu na przeciwległe wartości (takie jak włączanie i wyłączanie na przykład).
- Porównaj różnicę czasu cyklu między dwiema sekwencjami.
- W przypadku zmian stanu, które znacząco zmieniają potok (na przykład SetTexture), odejmij różnicę między dwiema sekwencjami, aby uzyskać czas zmiany stanu.
- W przypadku zmian stanów, które znacząco zmieniają ścieżkę przetwarzania (i dlatego wymagają przełączania stanów, takich jak SetRenderState), oblicz różnicę między sekwencjami renderowania i podziel przez 2. Spowoduje to wygenerowanie średniej liczby cykli dla każdej zmiany stanu.
Należy jednak uważać na optymalizacje, które powodują nieoczekiwane wyniki podczas profilowania. Optymalizacje zmian stanu mogą ustawiać zanieczyszczone stany, co powoduje odroczenie pracy. Może to spowodować, że wyniki profilu nie są tak intuicyjne, jak oczekiwano. Wywołania renderowania, które są łączone, znacznie zmniejszą pracę sterownika, co może prowadzić do błędnych wniosków. Starannie zaplanowane sekwencje renderowania są używane do zapobiegania zmianie stanu i łączeniu wywołań rysowania. Sztuczka polega na zapobieganiu optymalizacjom podczas profilowania, tak aby generowane liczby były rozsądnymi liczbami budżetowania.
Notatka
Duplikowanie tej strategii profilowania w aplikacji bez mechanizmu zapytań jest trudniejsze. Przed direct3D 9 jedynym przewidywalnym sposobem opróżniania buforu poleceń jest zablokowanie aktywnej powierzchni (np. celu renderowania), aż procesor GPU będzie bezczynny. Dzieje się tak, ponieważ blokowanie powierzchni wymusza opróżnienie buforu poleceń przez środowisko uruchomieniowe w przypadku, gdy w buforze istnieją polecenia renderowania, które powinny zaktualizować powierzchnię przed zablokowaniem, oprócz oczekiwania na zakończenie działania procesora GPU. Ta technika jest funkcjonalna, chociaż jest bardziej inwazyjna niż użycie mechanizmu zapytań wprowadzonego w Direct3D 9.
Aneks
Liczby w tej tabeli stanowią zakres szacunkowych wartości dotyczący czasu wykonania i obciążenia sterownika związanych z każdą z tych zmian stanu. Przybliżenia są oparte na rzeczywistych pomiarach wykonanych na sterownikach przy użyciu technik przedstawionych w dokumencie. Te liczby zostały wygenerowane przy użyciu środowiska uruchomieniowego Direct3D 9 i są zależne od sterownika.
Techniki opisane w tym dokumencie są przeznaczone do mierzenia czasu wykonywania i pracy sterownika. Ogólnie rzecz biorąc, niepraktyczne jest zapewnienie wyników zgodnych z wydajnością procesora CPU i procesora GPU w każdej aplikacji, ponieważ wymagałoby to wyczerpującej tablicy sekwencji renderowania. Ponadto szczególnie trudno jest mierzyć wydajność GPU, ponieważ jest ona bardzo zależna od ustawienia stanu w potoku przed sekwencją renderowania. Na przykład włączenie mieszania alfa nie ma wpływu na wymaganą ilość pracy procesora CPU, ale może mieć duży wpływ na ilość pracy wykonywanej przez procesor GPU. W związku z tym techniki w tym dokumencie ograniczają działanie procesora GPU do minimalnej możliwej ilości, ograniczając ilość danych, które należy renderować. Oznacza to, że liczby w tabeli będą najbardziej zgodne z wynikami uzyskanymi z aplikacji, które są ograniczone do procesora CPU (w przeciwieństwie do aplikacji, która jest ograniczona przez procesor GPU).
Zachęcamy do korzystania z przedstawionych technik, aby uwzględnić najważniejsze scenariusze i konfiguracje. Wartości w tabeli mogą służyć do porównywania z wygenerowanymi liczbami. Ponieważ każdy sterownik różni się, jedynym sposobem wygenerowania rzeczywistych liczb, które zobaczysz, jest wygenerowanie wyników profilowania przy użyciu scenariuszy.
| Wywołanie interfejsu API | Średnia liczba cykli |
|---|---|
| SetVertexDeclaration | 6500 - 11250 |
| SetFVF | 6400 - 11200 |
| SetVertexShader | 3000 - 12100 |
| SetPixelShader | 6300 - 7000 |
| WŁĄCZSPECULARNOŚĆ | 1900 - 11200 |
| SetRenderTarget | 6000 - 6250 |
| SetPixelShaderConstant (1 stała) | 1500 - 9000 |
| NORMALIZENORMALS | 2200 - 8100 |
| LightEnable | 1300 - 9000 |
| SetStreamSource | 3700 - 5800 |
| OŚWIETLENIE | 1700 - 7500 |
| ŹRÓDŁO MATERIAŁU DYFUZYJNEGO | 900 - 8300 |
| AMBIENTMATERIALSOURCE | 900 - 8200 |
| COLORVERTEX | 800 - 7800 |
| Ustaw Światło | 2200 - 5100 |
| SetTransform | 3200 - 3750 |
| UstawIndeksy | 900 - 5600 |
| OTACZAJĄCY | 1150 - 4800 |
| UstawTeksturę | 2500 - 3100 |
| SPECULARMATERIALSOURCE | 900 - 4600 |
| EMISSIVEMATERIALSOURCE | 900 - 4500 |
| UstawMateriał | 1000 - 3700 |
| ZENABLE | 700 - 3900 |
| WRAP0 | 1600 - 2700 |
| MINFILTER | 1700 - 2500 |
| MAGFILTER | 1700 - 2400 |
| SetVertexShaderConstant (1 stała) | 1000 - 2700 |
| COLOROP | 1500 - 2100 |
| COLORARG2 | 1300 - 2000 |
| COLORARG1 | 1300 - 1980 |
| CULLMODE | 500 - 2570 |
| WYCINEK | 500 - 2550 |
| DrawIndexedPrimitive | 1200 - 1400 |
| ADRESV | 1090 - 1500 |
| ADRESU | 1070 - 1500 |
| DrawPrimitive | 1050 - 1150 |
| SRGBTEXTURE | 150 - 1500 |
| MASKA WZORNIKA | 570 - 700 |
| STENCILZFAIL | 500 - 800 |
| STENCILREF | 550 - 700 |
| ALFABLENDENABLE | 550 - 700 |
| WZORNIKFUNC | 560 - 680 |
| STENCILWRITEMASK | 520 - 700 |
| BŁĄD SZABLONU | 500 - 750 |
| ZFUNC | 510 - 700 |
| ZWRITEENABLE | 520 - 680 |
| STENCILENABLE | 540 - 650 |
| ETAP SZABLONU | 560 - 630 |
| SRCBLEND | 500 - 685 |
| Tryb_Dwustronnego_Szablonu | 450 - 590 |
| ALFATESTENABLE | 470 - 525 |
| ALPHAREF | 460 - 530 |
| ALPHAFUNC | 450 - 540 |
| DESTBLEND | 475 - 510 |
| KOLORWRITEENABLE | 465 - 515 |
| CCW_STENCILFAIL | 340 - 560 |
| CCW_STENCILPASS | 340 - 545 |
| CCW_STENCILZFAIL | 330 - 495 |
| SCISSORTESTENABLE | 375 - 440 |
| Funkcja CCW_STENCILFUNC (Ustawienia szablonu) | 250 - 480 |
| SetScissorRect | 150 - 340 |
Tematy pokrewne