Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise all-in-one para empresas. O Microsoft Fabric aborda tudo, desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Neste tutorial, você pode usar o portal do Azure para criar um Data Factory. Em seguida, você usará a ferramenta Copiar Dados para criar um pipeline que copia dados do Armazenamento de Blobs do Azure para um Banco de Dados SQL.
Observação
Se você for novo no Azure Data Factory, consulte Introdução ao Azure Data Factory.
Neste tutorial, você executa as seguintes etapas:
- Criar um data factory.
- Usar a ferramenta Copy Data para criar um pipeline.
- Monitore as execuções de pipeline e de atividade.
Pré-requisitos
- Assinatura do Azure: se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
- Conta do Armazenamento do Microsoft Azure: use o Armazenamento de Blobs como o armazenamento de dados de origem. Se você não tiver uma conta de Armazenamento do Azure, confira as instruções em Criar uma conta de armazenamento.
- Banco de Dados SQL do Azure: use um banco de dados SQL como o armazenamento de dados do coletor. Se você não tiver um Banco de Dados SQL, consulte as instruções em Criar um Banco de Dados SQL.
Preparar o banco de dados SQL
Permitir que os serviços do Azure acessem o SQL Server lógico do Banco de Dados SQL do Azure.
Verifique se a configuração Permitir que os serviços e recursos do Azure acessem esse servidor está habilitada para o servidor que está executando o Banco de Dados SQL. Essa configuração permite que o Data Factory grave dados em sua instância de banco de dados. Para verificar e ativar essa configuração, vá para SQL Server lógico > Segurança > Firewalls e redes virtuais > e defina a opção Permitir que serviços e recursos do Azure acessem este servidor como ativado.
Observação
A opção de permitir que os serviços e recursos do Azure acessem esse servidor permite o acesso de rede ao SQL Server de qualquer recurso do Azure, não apenas aqueles em sua assinatura. Pode não ser apropriado para todos os ambientes, mas é apropriado para este tutorial limitado. Para obter mais informações, consulte as regras de Firewall do SQL Server do Azure. Em vez disso, você pode usar pontos de extremidade privados para se conectar aos serviços de PaaS do Azure sem usar IPs públicos.
Criar um blob e uma tabela SQL
Prepare o Armazenamento de Blobs e o Banco de Dados SQL para o tutorial executando estas etapas.
Criar um blob de origem
Inicie o Bloco de Notas. Copie o seguinte texto e salve-o em um arquivo chamado inputEmp.txt em seu disco:
FirstName|LastName John|Doe Jane|DoeCrie um contêiner chamado adfv2tutorial e carregue o arquivo inputEmp.txt no contêiner. Você pode usar o portal do Azure ou várias ferramentas, como o Gerenciador de Armazenamento do Azure , para executar essas tarefas.
Criar uma tabela do SQL de coletor
Use o seguinte script do SQL para criar uma tabela chamada
dbo.empno Banco de Dados SQL:CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);
Criar uma data factory
No menu superior, selecione Criar um recurso>Análises>Data Factory:

Na página Novo data factory, em Nome, insira ADFTutorialDataFactory.
O nome da fábrica de dados deve ser globalmente exclusivo. Você deve ver a seguinte mensagem de erro:

Se você receber uma mensagem de erro sobre o valor do nome, insira um nome diferente para o data factory. Por exemplo, use o nome yournameADFTutorialDataFactory. Para obter as regras de nomenclatura para artefatos do Data Factory, consulte as regras de nomenclatura do Data Factory.
Selecione a assinatura do Azure onde criar a nova fábrica de dados.
Para o Grupo de Recursos, siga uma das seguintes etapas:
a. Selecione Usar existente e selecione um grupo de recursos existente na lista suspensa.
b. Selecione Criar novo e insira o nome de um grupo de recursos.
Para saber mais sobre grupos de recursos, consulte Usar grupos de recursos para gerenciar seus recursos do Azure.
Na versão, selecione V2 para a versão.
No localização, selecione o local da fábrica de dados. Somente os locais com suporte são exibidos na lista suspensa. Os armazenamentos de dados (por exemplo, Armazenamento do Azure e Banco de Dados SQL) e os serviços de computação (por exemplo, Azure HDInsight) usados pelo seu data factory podem estar em outros locais e regiões.
Selecione Criar.
Após a conclusão da criação, a home page do Data Factory será exibida.

Para iniciar a interface do usuário do Azure Data Factory em uma guia separada, selecione Abrir no painel Abrir o Azure Data Factory Studio.
Use a ferramenta Copy Data para criar um pipeline
Na home page do Azure Data Factory, selecione o bloco Ingestão para iniciar a ferramenta Copiar Dados.

Na página Propriedades da ferramenta Copiar Dados, escolha a tarefa de cópia interna emTipo de tarefa e selecione Avançar.
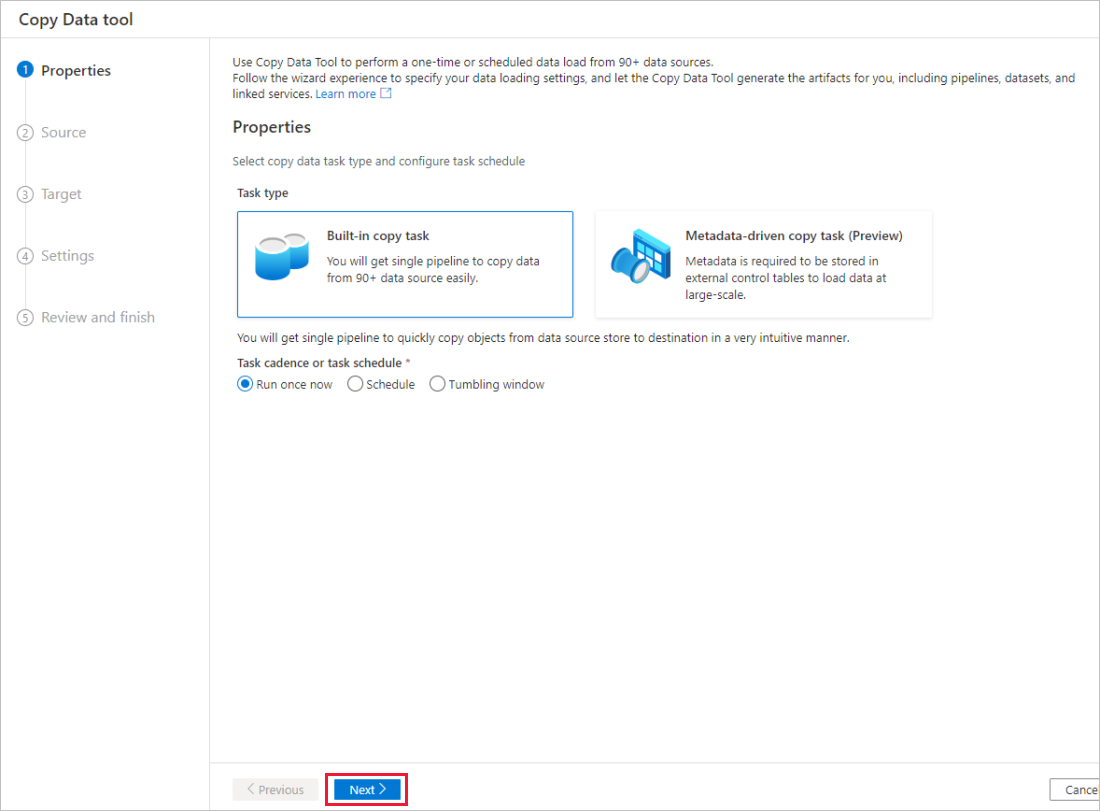
Na página armazenamento de dados de origem , conclua as seguintes etapas:
a. Selecione + Criar nova conexão para adicionar uma conexão.
b. Selecione Armazenamento de Blobs do Azure na galeria e, em seguida, selecione Continuar.
c. Na página Nova conexão (Armazenamento de Blobs do Azure), selecione sua assinatura do Azure na lista de Assinatura do Azure, depois selecione sua conta de armazenamento na lista Nome da conta de armazenamento. Teste a conexão e selecione Criar.
d. Selecione o serviço vinculado recém-criado como origem no bloco Conexão .
e. Na seção Arquivo ou pasta , selecione Procurar para navegar até a pasta adfv2tutorial , selecione o arquivo inputEmp.txt e, em seguida, selecione OK.
f. Selecione Avançar para ir para a próxima etapa.
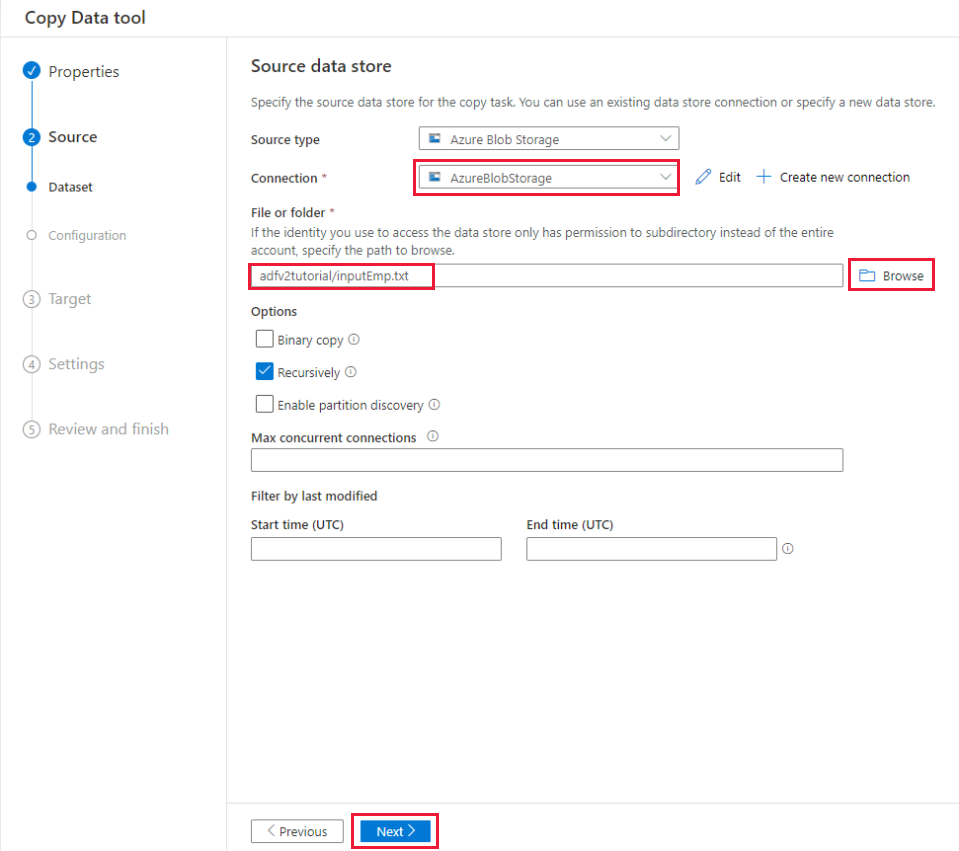
Na página Configurações de formato de arquivo, habilite a caixa de seleção da primeira linha como cabeçalho. Observe que a ferramenta detecta automaticamente os delimitadores de coluna e linha e você pode visualizar dados e exibir o esquema dos dados de entrada selecionando o botão Visualizar dados nesta página. Em seguida, selecione Avançar.

Na página De armazenamento de dados de destino , conclua as seguintes etapas:
a. Selecione + Criar nova conexão para adicionar uma conexão.
b. Selecione o Banco de Dados SQL do Azure na galeria e selecione Continuar.
c. Na página Nova conexão (Banco de Dados SQL do Azure), selecione sua assinatura do Azure, o nome do servidor e o nome do banco de dados na lista suspensa. Em seguida, selecione a autenticação SQL no tipo autenticação, especifique o nome de usuário e a senha. Teste a conexão e selecione Criar.
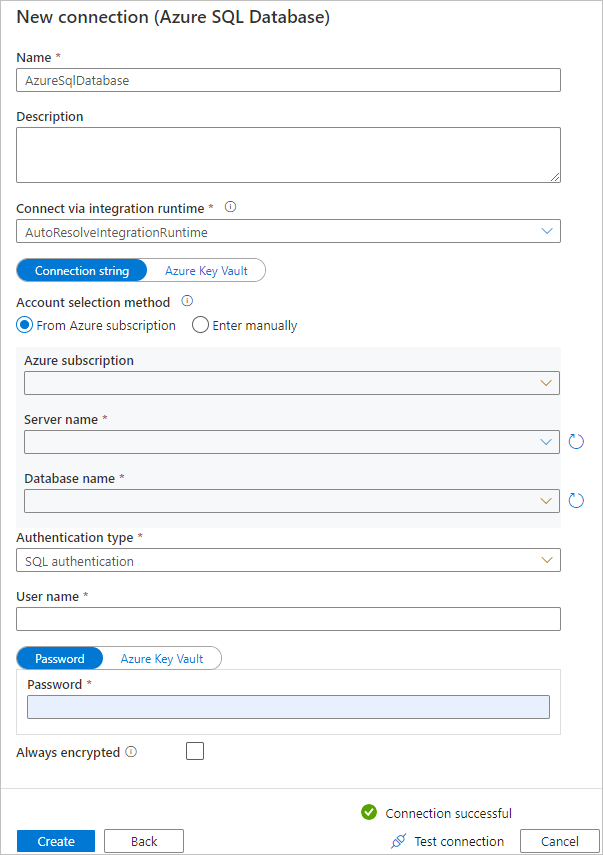
d. Selecione o serviço vinculado recém-criado como destino, depois selecione Avançar.
Na página Armazenamento de dados de destino , selecione Usar tabela existente e selecione a
dbo.emptabela. Em seguida, selecione Avançar.Na página mapeamento de coluna, observe que a segunda e a terceira colunas do arquivo de entrada são mapeadas para as colunas FirstName e LastName da tabela emp. Ajuste o mapeamento para verificar se não há erro e selecione Avançar.
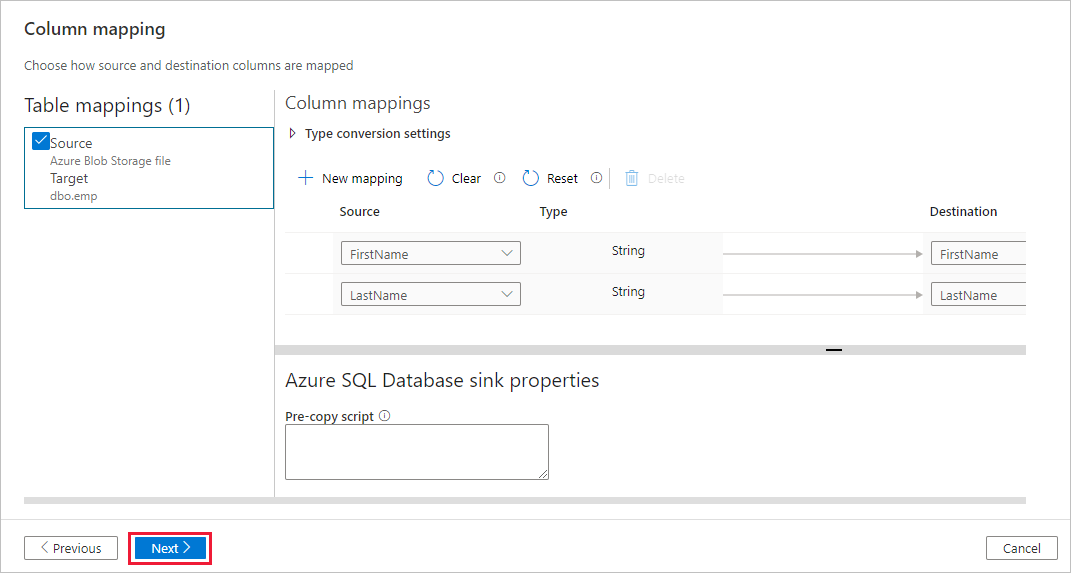
Na página Configurações, no nome da tarefa, insiraCopyFromBlobToSqlPipeline e selecione Avançar.
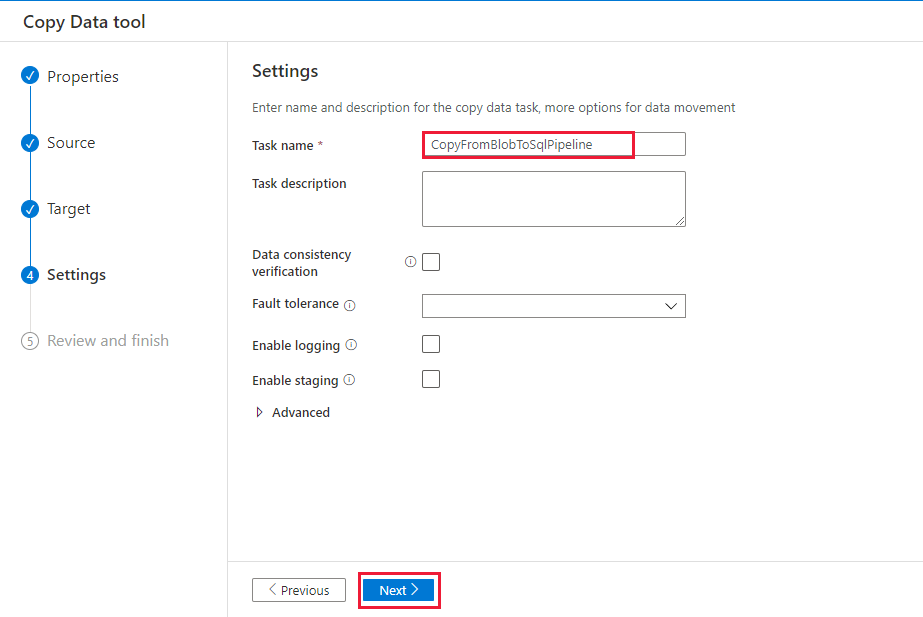
Na página Resumo , examine as configurações e selecione Avançar.
Na página Implantação, selecione Monitorar para monitorar o pipeline (tarefa).
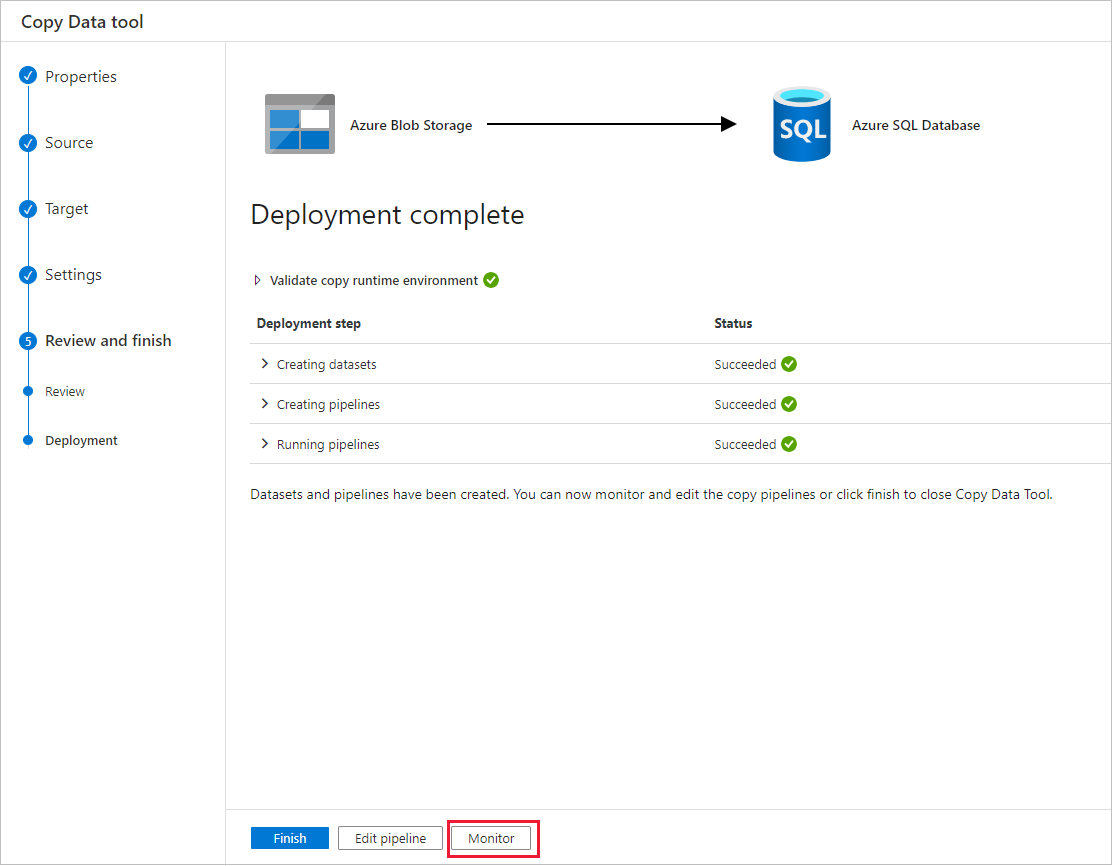
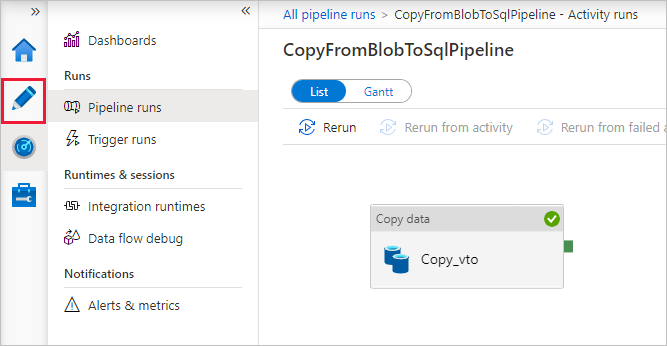
Na página Execuções de pipeline, selecione Atualizar para atualizar a lista. Selecione o link no nome do pipeline para exibir os detalhes da execução da atividade ou executar novamente o pipeline.

Na página "Execuções de atividade", selecione o link Detalhes (ícone de óculos) na coluna Nome da atividade para obter mais detalhes sobre a operação de cópia. Para voltar à exibição “Execuções de pipeline”, selecione o link Todas as execuções de pipeline no menu de navegação estrutural. Para atualizar o modo de exibição, selecione Atualizar.

Verifique se os dados estão inseridos na tabela dbo.emp no Banco de Dados SQL.
Selecione a guia Autor à esquerda para alternar para o modo de editor. É possível atualizar os serviços vinculados, os conjuntos de dados e os pipelines criados com a ferramenta usando o editor. Para obter detalhes sobre como editar essas entidades na interface do usuário do Data Factory, consulte a versão do portal do Azure deste tutorial.
Conteúdo relacionado
O pipeline desta amostra copia dados do Armazenamento de Blobs para um Banco de Dados SQL. Você aprendeu a:
- Criar um data factory.
- Usar a ferramenta Copy Data para criar um pipeline.
- Monitore as execuções de pipeline e de atividade.
Avance para o tutorial a seguir para saber mais sobre como copiar dados do local para a nuvem: