Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Os jupyter notebooks fornecem um ambiente interativo para explorar, analisar e visualizar dados no data lake do Microsoft Sentinel. Com blocos de anotações, você pode escrever e executar código, documentar seu fluxo de trabalho e exibir resultados— tudo em um só lugar. Isso facilita a exploração de dados, a criação de soluções de análise avançada e o compartilhamento de insights com outras pessoas. Aproveitando o Python e o Apache Spark no Visual Studio Code, os notebooks ajudam você a transformar dados de segurança brutos em inteligência acionável.
Este artigo mostra como explorar e interagir com dados data lake usando notebooks Jupyter no Visual Studio Code.
Pré-requisitos
Conectar ao data lake do Microsoft Sentinel
Para usar notebooks no data lake do Microsoft Sentinel, primeiro você deve integrar-se ao data lake. Se você ainda não se registrou no data lake do Sentinel, consulte Integração ao data lake do Microsoft Sentinel. Se você tiver integrado recentemente ao data lake, pode levar um tempo até que um volume suficiente de dados seja ingerido antes que você possa criar análises significativas usando notebooks.
Permissões
As funções do Microsoft Entra ID fornecem amplo acesso em todos os workspaces no data lake. Como alternativa, você pode conceder acesso a workspaces individuais usando funções RBAC do Azure. Os usuários com permissões RBAC do Azure para workspaces do Microsoft Sentinel podem executar notebooks nesses workspaces na camada do data lake. Para obter mais informações, consulte Funções e permissões no Microsoft Sentinel.
Para criar novas tabelas personalizadas na camada de análise, a identidade gerenciada do data lake deve receber a função colaborador do Log Analytics no workspace do Log Analytics.
Para atribuir a função, siga as etapas abaixo:
- No portal do Azure, navegue até o workspace do Log Analytics ao qual você deseja atribuir a função.
- Selecione Controle de acesso (IAM) no painel de navegação à esquerda.
- Selecione Adicionar atribuição de função.
- Na tabela Função , selecione Colaborador do Log Analytics e selecione Avançar
- Selecione Identidade Gerenciada e selecione Selecionar membros.
- Sua identidade gerenciada do data lake é uma identidade gerenciada atribuída pelo sistema chamada
msg-resources-<guid>. Selecione a identidade gerenciada e selecione Selecionar. - Selecione Examinar e atribuir.
Para obter mais informações sobre como atribuir funções a identidades gerenciadas, consulte Atribuir funções do Azure usando o portal do Azure.
Instalar o Visual Studio Code e a extensão do Microsoft Sentinel
Se você ainda não tiver o Visual Studio Code, baixe e instale o Visual Studio Code para Mac, Linux ou Windows.
A extensão do Microsoft Sentinel para Visual Studio Code (VS Code) é instalada no marketplace de extensões. Para instalar a extensão, siga estas etapas:
- Selecione o Marketplace de Extensões na barra de ferramentas à esquerda.
- Procure Sentinel.
- Selecione a extensão do Microsoft Sentinel e selecione Instalar.
- Depois que a extensão é instalada, o ícone de escudo do Microsoft Sentinel aparece na barra de ferramentas à esquerda.

Instale a extensão do GitHub Copilot no Visual Studio Code e habilite a conclusão de código e sugestões em notebooks.
- Pesquise o GitHub Copilot no Extensions Marketplace e instale-o.
- Após a instalação, entre no GitHub Copilot usando sua conta do GitHub.
Explorar tabelas de níveis do data lake
Depois de instalar a extensão do Microsoft Sentinel, você pode começar a explorar tabelas da camada data lake e criar notebooks Jupyter para analisar os dados.
Entrar na extensão do Microsoft Sentinel
Selecione o ícone de escudo do Microsoft Sentinel na barra de ferramentas à esquerda.
Uma caixa de diálogo é exibida com o seguinte texto: A extensão "Microsoft Sentinel" quer entrar com a Microsoft. Selecione Permitir.

Selecione o nome da sua conta para concluir a entrada.



Exibir trabalhos e tabelas do data lake
Depois que você se conectar, a extensão do Sentinel exibirá uma lista de Tabelas do lake e Trabalhos no painel esquerdo. As tabelas são agrupadas pelo banco de dados e pela categoria. Selecione uma tabela para ver as definições de coluna.
Para obter informações sobre trabalhos, consulte Trabalhos e Agendamento.

Criar um novo notebook
Para criar um novo notebook, use um dos métodos a seguir.
Insira > na caixa de pesquisa ou pressione Ctrl+Shift+P e, em seguida, insira Criar Novo Jupyter Notebook.

Selecione Arquivo > Novo Arquivo e escolha Jupyter Notebook na lista suspensa.

No novo notebook, cole o código a seguir na primeira célula.
from sentinel_lake.providers import MicrosoftSentinelProvider data_provider = MicrosoftSentinelProvider(spark) table_name = "EntraGroups" df = data_provider.read_table(table_name) df.select("displayName", "groupTypes", "mail", "mailNickname", "description", "tenantId").show(100, truncate=False)


O editor fornece preenchimento de código IntelliSense para a classe MicrosoftSentinelProvider e para os nomes de tabelas no data lake.
Selecione o triângulo Executar para executar o código no notebook. Os resultados são exibidos no painel de saída abaixo da célula de código.
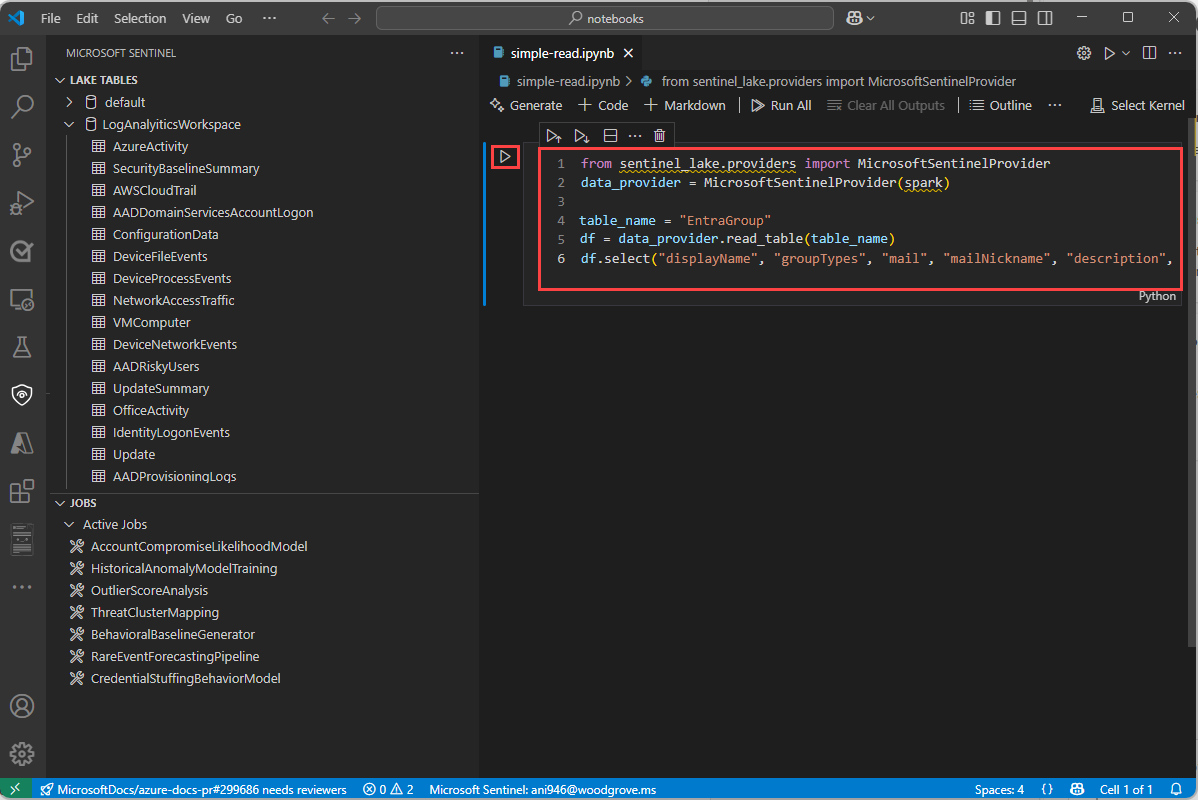
Selecione o Microsoft Sentinel na lista para obter uma lista de pools de runtime.
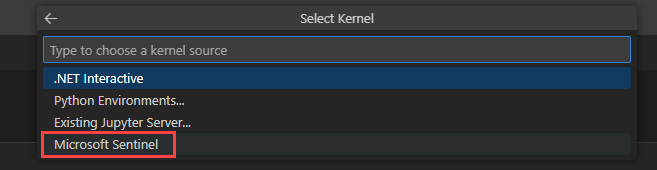
Selecione Médio para executar o notebook no pool de runtime de tamanho médio. Para obter mais informações sobre os diferentes runtimes, consulte Selecionar o runtime apropriado do Microsoft Sentinel.



Observação
Selecionar o kernel inicia a sessão do Spark e executa o código no notebook. Depois de selecionar o pool, pode levar de 3 a 5 minutos para que a sessão seja iniciada. As execuções subsequentes são mais rápidas, pois a sessão já está ativa.
Quando a sessão é iniciada, o código no notebook é executado e os resultados são exibidos no painel de saída abaixo da célula de código, por exemplo: 
Para ver notebooks de exemplo que demonstram como interagir com o data lake do Microsoft Sentinel, consulte Notebooks de exemplo para o data lake do Microsoft Sentinel.
Barra de status
A barra de status na parte inferior do bloco de anotações fornece informações sobre o estado atual do notebook e a sessão do Spark. A barra de status inclui as seguintes informações:
O percentual de utilização do vCore para o pool do Spark selecionado. Passe o mouse sobre a porcentagem para ver o número de vCores usados e o número total de vCores disponíveis no pool. Os percentuais representam o uso atual entre cargas de trabalho interativas e de trabalho da conta conectada.
O status da conexão da sessão do Spark, por exemplo
Connecting,ConnectedouNot Connected.

Definir tempos limite de sessão
Você pode definir o tempo limite da sessão e os avisos de tempo limite para blocos de anotações interativos. Para alterar o tempo limite, selecione o status da conexão na barra de status na parte inferior do notebook. Escolha entre as seguintes opções:
Definir o período de tempo limite da sessão: define o tempo em minutos antes do tempo limite da sessão. O padrão é 30 minutos.
Redefinir período de tempo limite da sessão: redefine o tempo limite da sessão para o valor padrão de 30 minutos.
Definir o período de aviso de tempo limite da sessão: define o tempo em minutos antes do tempo limite em que um aviso é exibido de que a sessão está prestes a atingir o tempo limite. O padrão é 5 minutos.
Redefinir o período de aviso de tempo limite da sessão: redefine o aviso de tempo limite da sessão para o valor padrão de 5 minutos.


Usar o GitHub Copilot em notebooks
Use o GitHub Copilot para ajudá-lo a escrever código em notebooks. O GitHub Copilot fornece sugestões de código e preenchimento automático com base no contexto do código. Para usar o GitHub Copilot, verifique se você tem a extensão do GitHub Copilot instalada no Visual Studio Code.
Copie o código dos Notebooks de exemplo para o data lake do Microsoft Sentinel e salve-o na pasta de notebooks para fornecer contexto ao GitHub Copilot. O GitHub Copilot poderá sugerir conclusões de código com base no contexto do seu notebook.
O exemplo a seguir mostra o GitHub Copilot gerando uma revisão de código.

Classe de Provedor do Microsoft Sentinel
Para se conectar ao data lake do Microsoft Sentinel, use à SentinelLakeProvider classe.
Essa classe faz parte do access_module.data_loader módulo e fornece métodos para interagir com o data lake. Para usar essa classe, importe-a e crie uma instância da classe usando uma spark sessão.
from sentinel_lake.providers import MicrosoftSentinelProvider
data_provider = MicrosoftSentinelProvider(spark)
Para obter mais informações sobre os métodos disponíveis, consulte a referência de classe do Provedor do Microsoft Sentinel.
Selecione o pool de runtime apropriado
Há três pools de runtime disponíveis para executar seus notebooks Jupyter na extensão do Microsoft Sentinel. Cada pool foi projetado para diferentes cargas de trabalho e requisitos de desempenho. A escolha do pool de runtime afeta o desempenho, o custo e o tempo de execução dos trabalhos do Spark.
| Pool de runtime | Casos de uso recomendados | Características |
|---|---|---|
| Pequeno | Desenvolvimento, testagem e análise exploratória leve. Cargas de trabalho pequenas com transformações simples. Eficiência de custo priorizada. |
Adequado para cargas de trabalho pequenas Transformações simples. Custo mais baixo, tempo de execução mais longo. |
| Médio | Trabalhos de ETL com junções, agregações e treinamento de modelo de ML. Cargas de trabalho moderadas com transformações complexas. |
Desempenho aprimorado em relação a Small. Lida com paralelismo e operações moderadas com uso intensivo de memória. |
| Grande | Aprendizado profundo e cargas de trabalho de ML. Embaralhamento extensivo de dados, junções grandes ou processamento em tempo real. Tempo de execução crítico. |
Memória alta e poder de computação. Atrasos mínimos. Melhor para cargas de trabalho grandes, complexas ou sensíveis ao tempo. |
Observação
Quando acessadas pela primeira vez, as opções de kernel podem levar cerca de 30 segundos para serem carregadas.
Depois de selecionar um pool de tempo de execução, pode levar de 3 a 5 minutos para que a sessão seja iniciada.
Exibir mensagens, logs e erros
Os logs de mensagens e as mensagens de erro são exibidos em três áreas no Visual Studio Code.
O painel Saída.
- No painel Saída, selecione Microsoft Sentinel na lista suspensa.
- Selecione Depurar para incluir entradas de log detalhadas.

Mensagens em linha no notebook fornecem comentários e informações sobre a execução de células de código. Essas mensagens incluem atualizações de status de execução, indicadores de progresso e notificações de erro relacionadas ao código na célula anterior
Um pop-up de notificação no canto inferior direito do Visual Studio Code, também conhecido como uma mensagem de notificação do sistema, fornece alertas e atualizações em tempo real sobre o status das operações no notebook e na sessão do Spark. Essas notificações incluem mensagens, avisos e alertas de erro, como conexão bem-sucedida com uma sessão do Spark e avisos de tempo limite.



Trabalhos e agendamento
Você pode agendar trabalhos para execução em horários ou intervalos específicos usando a extensão do Microsoft Sentinel para Visual Studio Code. Os trabalhos permitem automatizar tarefas de processamento de dados para resumir, transformar ou analisar dados no data lake do Microsoft Sentinel. As tarefas também são usadas para processar dados e gravar resultados em tabelas personalizadas na camada do data lake ou na camada de análise. Para obter mais informações sobre como criar e gerenciar trabalhos, consulte Criar e gerenciar trabalhos do Jupyter Notebook.
Parâmetros e limites de serviço para notebooks VS Code
A seção a seguir lista os parâmetros de serviço e os limites do data lake do Microsoft Sentinel ao usar o VS Code Notebooks.
| Categoria | Parâmetro/limite |
|---|---|
| Tabela personalizada na camada de análise | Tabelas personalizadas na camada de análise não podem ser excluídas de um notebook; Use o Log Analytics para excluir essas tabelas. Para obter mais informações, consulte Adicionar ou excluir tabelas e colunas nos Logs do Azure Monitor |
| Tempo limite do soquete da Web do gateway | 2 horas |
| Tempo limite da consulta interativa | 2 horas |
| Tempo limite de inatividade da sessão interativa | 20 minutos |
| Linguagem | Python |
| Tempo limite do trabalho do notebook | 8 horas |
| Trabalhos máximos de notebook simultâneos | 3, os trabalhos subsequentes são enfileirados |
| Máximo de usuários simultâneos em consultas interativas | 8 a 10 no pool grande |
| Hora de inicialização da sessão | A sessão de computação do Spark leva cerca de 5 a 6 minutos para ser iniciada. Você pode exibir o status da sessão na parte inferior do bloco de anotações do VS Code. |
| Bibliotecas com suporte | Somente as bibliotecas do Azure Synapse 3.4 e a biblioteca do provedor do Microsoft Sentinel para funções abstraídas são suportadas para consultar o data lake. Não há suporte para instalações pip ou bibliotecas personalizadas. |
| Limite de UX do VS Code para exibir registros | 100.000 linhas |
Resolução de problemas
A tabela a seguir lista os erros comuns que você pode encontrar ao trabalhar com notebooks, suas causas raiz e ações sugeridas para resolvê-los.
| Categoria de erro | Nome do erro | Código de erro | Mensagem de erro | Ação sugerida |
|---|---|---|---|---|
| DatabaseError | DatabaseNotFound - Banco de dados não encontrado | 2001 | Banco de dados {DatabaseName} não encontrado. | Verifique se o banco de dados existe. Se o banco de dados for novo, aguarde uma atualização de metadados. |
| DatabaseError | AmbiguousDatabaseName | 2002 | Vários bancos de dados (IDs: {DatabaseID1}, {DatabaseID2}, ...) compartilham o nome {DatabaseName}. Forneça uma ID de banco de dados específica. | Especifique uma ID de banco de dados quando vários bancos de dados tiverem o mesmo nome. |
| DatabaseError | DatabaseIdMismatch | 2003 | Banco de dados ({DatabaseName}, ID {DatabaseID}) não encontrado. | Verifique o nome do banco de dados e a ID. Para obter IDs de banco de dados, liste todos os bancos de dados. |
| DatabaseError | ListDatabasesFailure | 2004 | Não é possível buscar bancos de dados. Reinicie a sessão e tente novamente. | Reinicie a sessão e repita a operação após alguns minutos. |
| TableError | TabelaNãoExiste | 2.100 | Tabela {TableName} não encontrada no banco de dados {DatabaseName}. | Verifique se a tabela existe no banco de dados. Se a tabela ou o banco de dados for novo, aguarde alguns minutos e tente novamente. |
| TableError | ProvisioningIncomplete | 2101 | A tabela {TableName} não está pronta. Aguarde alguns minutos antes de tentar novamente. | A tabela está sendo provisionada. Aguarde alguns minutos antes de tentar novamente. |
| TableError | DeltaTableMissing | 2102 | A tabela {TableName} está vazia. Novas tabelas podem levar até algumas horas para estarem prontas. | Pode levar algumas horas para sincronizar totalmente uma tabela de análise no data lake. Para tabelas que estão apenas no data lake, verifique se os dados precisam ser carregados ou restaurados. |
| TableError | TableDoesNotExistForDelete | 2103 | Não é possível excluir a tabela. Tabela {TableName} não encontrada. | Verifique se a tabela existe no banco de dados. Se a tabela ou o banco de dados for novo, aguarde alguns minutos e tente novamente. |
| AuthorizationFailure | MissingSASToken | 2201 | Não é possível acessar a tabela. Reinicie a sessão e tente novamente. | Falha na autorização ao tentar buscar o token de acesso para a tabela. Reinicie a sessão e tente novamente. |
| AuthorizationFailure | InvalidSASToken | 2202 | Não é possível acessar a tabela. Reinicie a sessão e tente novamente. | Falha na autorização ao tentar buscar o token de acesso para a tabela. Reinicie a sessão e tente novamente. |
| AuthorizationFailure | TokenExpired | 2203 | Não é possível acessar a tabela. Reinicie a sessão e tente novamente. | Falha na autorização ao tentar buscar o token de acesso para a tabela. Reinicie a sessão e tente novamente. |
| AuthorizationFailure | TableInsufficientPermissions | 2204 | Acesso necessário para a tabela {TableName} no banco de dados {DatabaseName}. | Contate um administrador para solicitar acesso à tabela ou ao banco de dados (workspace). |
| AuthorizationFailure | InternalTableAccessDenied | 2205 | O acesso à tabela {TableName} é restrito. | Somente tabelas definidas pelo sistema ou pelo usuário podem ser acessadas de um notebook. |
| AuthorizationFailure | FalhaNaAutenticaçãoDaTabela | 2206 | Não é possível salvar dados na tabela. Reinicie a sessão e tente novamente. | Falha na autorização ao tentar salvar dados na tabela. Reinicie a sessão e tente novamente. |
| ErroDeConfiguração | FalhaDeConfiguraçãoDoHadoop | 2301 | Não é possível atualizar a configuração da sessão. Reinicie a sessão e tente novamente. | Esse problema é transitório e pode ser resolvido reiniciando a sessão e tentando novamente. Se esse problema persistir, entre em contato com o suporte. |
| DataError | Falha na Análise de JSON | 2302 | Os metadados da tabela foram corrompidos. Contate o suporte para obter assistência. | Contate o suporte para obter assistência. Forneça sua ID de locatário, o nome da tabela e o nome do banco de dados. |
| TableSchemaError | TableSchemaMismatch | 2401 | Coluna não encontrada na tabela de destino. Alinhe o esquema DataFrame e a tabela de destino ou use o modo de substituição. | Atualize o esquema DataFrame para corresponder à tabela no banco de dados de destino. Você também pode substituir a tabela inteiramente no modo de sobrescrever. |
| TableSchemaError | MissingRequiredColumns | 2402 | A coluna {ColumnName} está ausente do DataFrame. Verifique o esquema DataFrame e alinhe-o com a tabela de destino. | Atualize o esquema DataFrame para corresponder à tabela no banco de dados de destino. Você também pode substituir a tabela inteiramente no modo de sobrescrever. |
| TableSchemaError | AlteraçãoDoTipoDeColunaNãoPermitida | 2403 | Não é possível alterar o tipo de dados da coluna {ColumnName}. | Uma alteração de tipo de dados não é permitida para a coluna. Verifique as colunas existentes na tabela de destino e alinhe todos os tipos de dados no DataFrame. |
| TableSchemaError | ColumnNullabilityChangeNotAllowed | 2404 | Não é possível alterar a nulidade da coluna {ColumnName}. | Não é possível atualizar as configurações de nulidade da coluna. Verifique a tabela de destino e alinhe as configurações com o DataFrame. |
| IngestionError | FolderCreationFailure | 2501 | Não é possível criar armazenamento para a tabela {TableName}. | Esse problema é transitório e pode ser resolvido reiniciando a sessão e tentando novamente. Se esse problema persistir, entre em contato com o suporte. |
| IngestionError | FalhaNaSolicitaçãoDeSubtarefa | 2502 | Não é possível criar um processo de ingestão para a tabela {TableName}. | Esse problema é transitório e pode ser resolvido reiniciando a sessão e tentando novamente. Se esse problema persistir, entre em contato com o suporte. |
| IngestionError | FalhaNaCriaçãoDeSubTarefa | 2503 | Não é possível criar um processo de ingestão para a tabela {TableName}. | Esse problema é transitório e pode ser resolvido reiniciando a sessão e tentando novamente. Se esse problema persistir, entre em contato com o suporte. |
| InputError | ModoDeEscritaInválido | 2601 | Modo de gravação inválido. Use adicionar ou sobrescrever. | Especifique um modo de gravação válido (acrescentar ou substituir) antes de salvar o DataFrame. |
| InputError | PartitioningNotAllowed | 2602 | Não é possível particionar tabelas de análise. | Remova qualquer particionamento para todas as colunas em tabelas de análise. |
| InputError | MissingTableSuffixLake | 2603 | Nome da tabela personalizada inválido. Todos os nomes de tabelas personalizadas no data lake devem terminar com _SPRK. | Adicione _SPRK como um sufixo ao nome da tabela antes de escrevê-lo no data lake. |
| InputError | MissingTableSuffixLA | 2604 | Nome da tabela personalizada inválido. Todos os nomes de tabelas de análise personalizada devem terminar com _SPRK_CL. | Adicione _SPRK_CL como um sufixo ao nome da tabela antes de escrevê-lo no armazenamento de análise. |
| Erro Desconhecido | Erro Interno do Servidor | 2901 | Algo deu errado. Reinicie a sessão e tente novamente. | Esse problema é transitório e pode ser resolvido reiniciando a sessão e tentando novamente. Se esse problema persistir, entre em contato com o suporte. |
Conteúdo relacionado
- Criar e gerenciar trabalhos de notebook
- Notebooks de exemplo para o data lake do Microsoft Sentinel
- Referência de Classe do Provedor Microsoft Sentinel
- Visão geral do data lake do Microsoft Sentinel
- Funções e permissões do Data Lake do Microsoft Sentinel.